 數據集成系統在教育行業中的應用
數據集成系統在教育行業中的應用
一個風雨交加的晚上,領導把我拉到會議室說:老影啊,公司接到一個項目,需要在3個月里完成一個大數據平臺的開發,用于項目的交付,這個任務交給你了,加油搞!此刻的我:搞?搞事情啊~~~。由此我開始了數據平臺的“闖關之路”,遇到的第一個boss就是數據集成系統......
01
什么是數據集成?
百科里的解釋是:把不同來源、格式、特點性質的數據在邏輯上或物理上有機地集中,從而為企業提供全面的數據共享;通俗講就是把分散在各個系統中的各種類型的數據統一匯聚起來,主要體現在一個“集”字。
而數據集成系統就是提供數據集成能力的平臺,是一站式解決異構數據存儲互通,消除數據孤島的同步平臺,為大數據各系統和業務方提供數據集成的高效通道 。
拿現實中的實例類比來說,數據集成就好比把各種糧食通過不同的管道灌輸到一個大糧倉中,這些管道就是數據集成系統,我們可以支持接入各式各樣的糧食,小麥、玉米、大豆等等,同時支持在這些管道中加一些濾網,比如在大豆的管道中加上5mm的濾網,此時從大豆管道過來的糧食只有5mm以下的大豆,這就相當于數據集成系統中的數據過濾功能;這個糧倉相當于集成目的,我們把數據集成進來之后存儲在這里,供其他各方消費。
02
教育為什么要做數據集成?
2.1 數據大爆炸
現在是一個信息大爆炸時代,互聯網的高速發展、迅速普及,讓信息無處不在、無孔不入,每天在我們所生活在的這個世界出現了大量的信息,教育場景下也不例外,隨著各種信息化系統的涌入,信息以空前的速度增長,教育從業者體驗著信息時代便捷的同時,也給他們帶來了問題和“副作用”,從浩如煙海的信息海洋中迅速而準確地獲取他們最需要的信息,變得非常困難。
2.2 數據來源多樣化
隨著《教育信息化2.0行動計劃》的提出,教學過程中的信息化系統越來越多,比如作業系統、考試系統、選課系統、智慧課堂等等,每個系統都會產生大量的數據,存儲在各自的數據庫中,如果系統的服務商不同,可能數據的格式也不一樣,致使教育場景下的數據越來越多,越來越難以管理。
2.3 數據集不同結構
教育場景下的數據集可能是結構化的、半結構化的,甚至非結構化的;比如:考試系統中的數據是結構化的,評價系統中的數據是半結構化的,課堂實錄中的數據是非結構化的;不同結構的數據需要整合成統一的結構才能夠進行統計和分析。
2.4 數據冗余
數據中有很多冗余、錯誤、敏感數據,如果不進行數據清洗,會影響數據分析的效率和結果;在這種情況下需要我們配置統一的標準,對數據進行簡單的處理,以便于后續進行統計分析。
03
數據集成系統對教育的價值是什么?
大數據技術能夠將隱藏于海量數據中的信息和知識挖掘出來,按照科學的教育評價準則,對教學數據進行科學的統計分析,提供有價值的教學質量測評與分析數據,實現對教育活動,教育過程和教育結果的價值評判,為提高教育質量,教育決策以及學校改進日常教學方法提供科學的依據,實現教育管理的智能化,提升教育管理與服務水平。
數據集成系統作為底層基礎支撐性服務,是大數據系統的核心組成部分。通過提供數據集成能力,將教育各部門和來自互聯網的結構化和非結構化的數據進行統一的匯聚接入,存儲到大數據存儲組件,并支持數據的預處理,為大數據系統提供原始數據支撐。
04
數據集成系統怎么做?
4.1 建設原則
- 數據采集系統針對實際項目中復雜的、異構的數據環境,實現對多種數據源的集成,支持的關系數據庫有Oracle、MySQL、Sqlserver等,支持的文件類型有txt文件、csv文件、excel文件等,支持的接口類型有webservice接口、http接口、socket接口等。
- 對于不同的大數據存儲需求,實現對多種大數據存儲組件的支持,支持的大數據存儲組件包括HDFS、HBase、Hive、Solr、Elasticserach等。
- 針對數據的預處理需求,實現對數據的清洗、轉換、標準化等預處理的支持,并且支持清洗規則、轉換規則的用戶自定義,以及清洗、轉換、導入流程的用戶自定義。
- 在數據采集系統中,各類功能點模塊化、組件化,便于步驟獨立,保證系統內部模塊自治,同時便于多種步驟、方法的組合應用。
- 簡化用戶操作,通過圖形化的配置方式,簡單,靈活,使得用戶無需過分關心數據庫的各種內部細節,而專注于功能。
4.2 數據集成信息框架
數據集成信息流
4.3 功能結構
為了快速實現數據集成系統,滿足后續項目交付,經過和研發大佬的多次溝通,優先實現為業務提供數據集成的能力的數據源管理和集成任務管理。明確了第一版需求,只要包含數據源管理和集成任務管理就可以支持項目交付,因此功能結構設計如下:
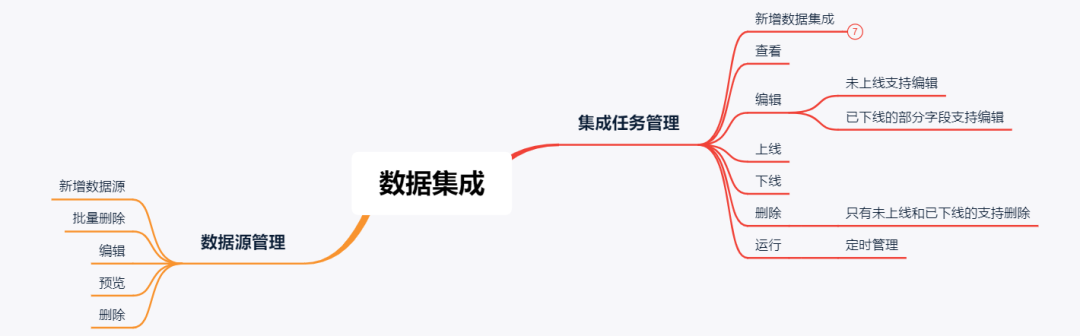
數據集成系統功能結構圖
4.4 建設內容
4.4.1 數據源管理
數據源模塊主要管理平臺支持的數據組件的基礎信息,包含各種數據組件的新增,配置和管理,如關系型數據庫的數據庫IP,端口,訪問信息等。這里大家可以理解為一個中間層,先通過數據抽取組件將各系統數據抽取到這里,以備后續集成任務管理模塊的調用。
- 在這里可以對數據源進行增刪改查
- 前提是需要和數據來源方溝通好,需要提供數據庫ip相關信息
- 下方是頁面示例:
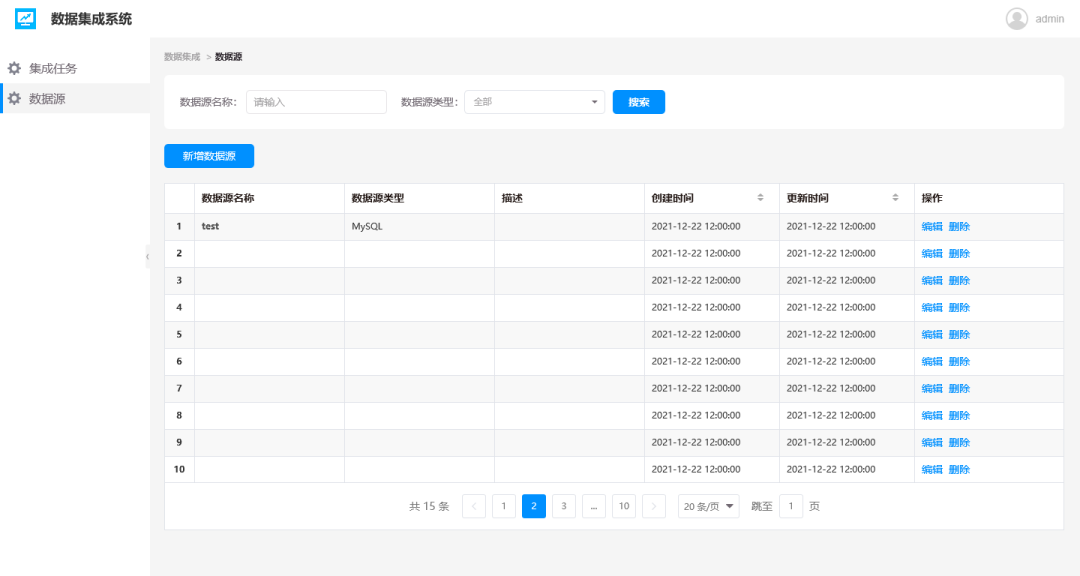
數據源管理列表
4.4.2 集成任務管理
當用戶創建好數據源之后,需要有一個模塊支持用戶創建集成任務,相當于上文中講到的,上游的所有糧食都準備好了,需要我們提供搭建管道的地方,讓用戶把所有的管道搭起來,然后把各種糧食都匯聚到一起。此時集成任務管理模塊誕生了,這個模塊下主要對數據集成的任務進行統一的管理,支持用戶對數據集成任務進行增刪改查.
(1)操作列表功能
-
上線:
集成任務完成創建狀態默認為未上線,此時用戶可將集成任務上線,上線為就緒狀態;
-
運行:
上線狀態下的任務支持運行,運行自動調用任務執行組件,開始數據集成;
-
下線:
已上線的任務支持下線;
-
刪除:
未上線和已下線的任務支持刪除;
-
編輯:
未上線和已下線的任務支持編輯。
(2)任務運行
- 集成任務創建好之后,如果需要周期性的拉取數據,這時候需要支持進行例行周期配置,支持用戶配置定時任務;
- 同時支持用戶進行失敗策略、任務執行優先級等相關參數的配置。
4.4.3 新增集成任務
為了方便用戶填寫,支持用戶選擇不同的數據源類型,數據接口類型不同,需要配置的參數信息也不同;但是總體來說數據集成主要分為三步:
-
數據接入:
回答數據從哪來的問題;
-
數據處理:
回答對數據要做什么的問題;
-
數據輸出:回答數據要到哪去的問題。
下方以將第三方數據庫數據集成到hive中為例舉例說明。選擇數據庫之后,頁面進入數據集成任務配置頁,三個步驟依次如下:
(1)數據接入
主要配置數據源相關信息,需要用戶填寫數據源表相關信息:
-
數據源:
數據集群相關信息;
-
數據庫:
源數據存儲數據庫;
-
是否分表:
如果分表存儲需要從多個表抽取數據;
-
表名:
源數據所在表名;
-
數據歸屬產品/系統:
這部分數據在目錄管理系統維護,這里直接引用;
-
數據預覽:
支持用戶對所選表進行預覽,查看數據格式。
(2)數據處理
到在數據集成過程中會對數據進行預處理,考慮到后續的擴展性,這里直接將各種處理步驟提煉為公共組件,支持用戶自定義選擇,第一期可支持:字段映射過濾、賬號匹配、數據脫敏、數據轉換;
為了節省操作,數據處理默認以字段映射過濾開始,自動選擇一項,用戶可直接點擊下一步。
(3)數據輸出
此時的數據經過預處理,已經完成了清洗、轉換的操作,接下來就需要將處理完的數據存下來,以備后續使用。
05
數據集成結束后做什么?
下面以學生畫像的思路和大家簡單聊聊。
通過從各個系統中采集過來的數據,包含但不限于:學生上網數據、網頁瀏覽時長、作業完成數據、作業完成時長、課堂互動數據等等,幫助學校管理者針對學生群體進行標簽化分析。幫助教育管理者從學習,網絡行為,生活等多維度分析學生群體的習慣和特點,為學校實現個性化培養教育提供數據支撐。
-
數據集成
+關注
關注
0文章
53瀏覽量
9185 -
數據集
+關注
關注
4文章
1208瀏覽量
24690 -
大數據
+關注
關注
64文章
8883瀏覽量
137407
發布評論請先 登錄
相關推薦
云脈文檔識別在教育行業中的應用
Banana Pi 攜手東莞金祿電子,發展開源硬件在教育行業的應用
VR虛擬現實軟件開發應用在教育行業有哪些優勢?
AR技術在教育行業的應用
探索AR技術在教育行業的應用,看看AR教育有什么優勢與前景?
人工智能是干嘛的 人工智能在教育中的應用研究
智能語音助手在教育行業的應用與挑戰
投影融合系統在教育領域的應用與發展趨勢

SOLIDWORKS在教育領域的應用
光纖技術在教育中的意義大嗎
訊維通信技術在教育行業的應用案例研究
訊維智能可視化綜合平臺在教育行業的應用與前景
SolidWorks教育版在教學中的具體應用





 工商網監
工商網監
評論