") AI芯片發(fā)展歷史及最新趨勢
AI芯片發(fā)展歷史及最新趨勢
想要玩邊緣智慧(Edge Artificial Intelligence, Edge AI)前我們首先要先認(rèn)識什么是類神經(jīng)網(wǎng)絡(luò)(Neural Network, NN)、深度學(xué)習(xí)(Deep Learning, DL)及為什么需要使用AI芯片,而AI芯片又有那些常見分類及未來可能發(fā)展方向。接下來就逐一為大家介紹不同類型的AI芯片用途及優(yōu)缺點(diǎn)。
1. 什么是神經(jīng)網(wǎng)絡(luò)?
人工智能自1950年發(fā)展至今已經(jīng)過多次起伏,從最簡單的「符號邏輯」開始,歷經(jīng)「專家系統(tǒng)」、「機(jī)器學(xué)習(xí)」、「數(shù)據(jù)采礦」等多個時(shí)期。直到2012年Alex Krizhevsky和其導(dǎo)師Geoffrey Hinton推出基于類神經(jīng)網(wǎng)絡(luò)擴(kuò)展出來的「卷積神經(jīng)網(wǎng)絡(luò)」(Convolutional Neural Network, CNN) 「AlexNet」,以超出第二名10%正確率的優(yōu)異成績贏得ImageNet大賽后,「深度學(xué)習(xí)」(DeepLearning, DL) 架構(gòu)正式開啟新一波的AI浪朝。
此后持續(xù)衍生出各種不同的網(wǎng)絡(luò)架構(gòu),如能處理像聲音、文章、感測信號這類和時(shí)間相關(guān)的「循環(huán)神經(jīng)網(wǎng)絡(luò)」(Recurrent Neural Network, RNN) ,或者能自動生成影像、風(fēng)格轉(zhuǎn)移(StyleTransfer)的「生成對抗網(wǎng)絡(luò)」(Generative Adversarial Network, GAN) 等一系列網(wǎng)絡(luò)架構(gòu)。
這些網(wǎng)絡(luò)(或稱模型)都有一個特色,就是有大量的神經(jīng)元(Neural)、神經(jīng)連結(jié)權(quán)重(Weights)、層數(shù)(Layers)及復(fù)雜的網(wǎng)絡(luò)結(jié)構(gòu)(Network Architecture)。而其中最主要的運(yùn)算方式就是矩陣(Matrix)計(jì)算,若再拆解成更小元素,即為 y = a * x + b ,又可稱為「乘積累加運(yùn)算」(Multiply–accumulate, MAC) 。
一個小型模型少則數(shù)千個神經(jīng)元、數(shù)萬個權(quán)重值,多則可能數(shù)十萬個神經(jīng)元、數(shù)十億個權(quán)重值。以常見手寫數(shù)字(0-9)辨識小型CNN模型LeNet5為例(如Fig.1所示),它約有6萬多個權(quán)重,當(dāng)模型推論(Inference)一次得到答案時(shí),約需經(jīng)過42萬多次MAC運(yùn)算。而像大型的VGG16模型則有1.38億個權(quán)重,推論一次則約有150多億次MAC計(jì)算。
一般來說模型的初始權(quán)重值通常都不太理想,所以根據(jù)推論后得到的答案,必須再反向修正所有權(quán)重值,使其更接近正確答案。但通常一次是很難到位的,所以要反復(fù)修正直到難以再調(diào)整出更接近正確答案為止,而這個過程就稱為「模型訓(xùn)練」(Model Training) 。
通常這樣修正的次數(shù)會隨著數(shù)據(jù)集(Dataset)的大小、權(quán)重的數(shù)量及網(wǎng)絡(luò)結(jié)構(gòu)的復(fù)雜度,可能少則要幾千次,多則要幾萬次、甚至更多次數(shù)才能收斂到滿意的結(jié)果。由此得知訓(xùn)練模型所需的計(jì)算量有多么巨量了。
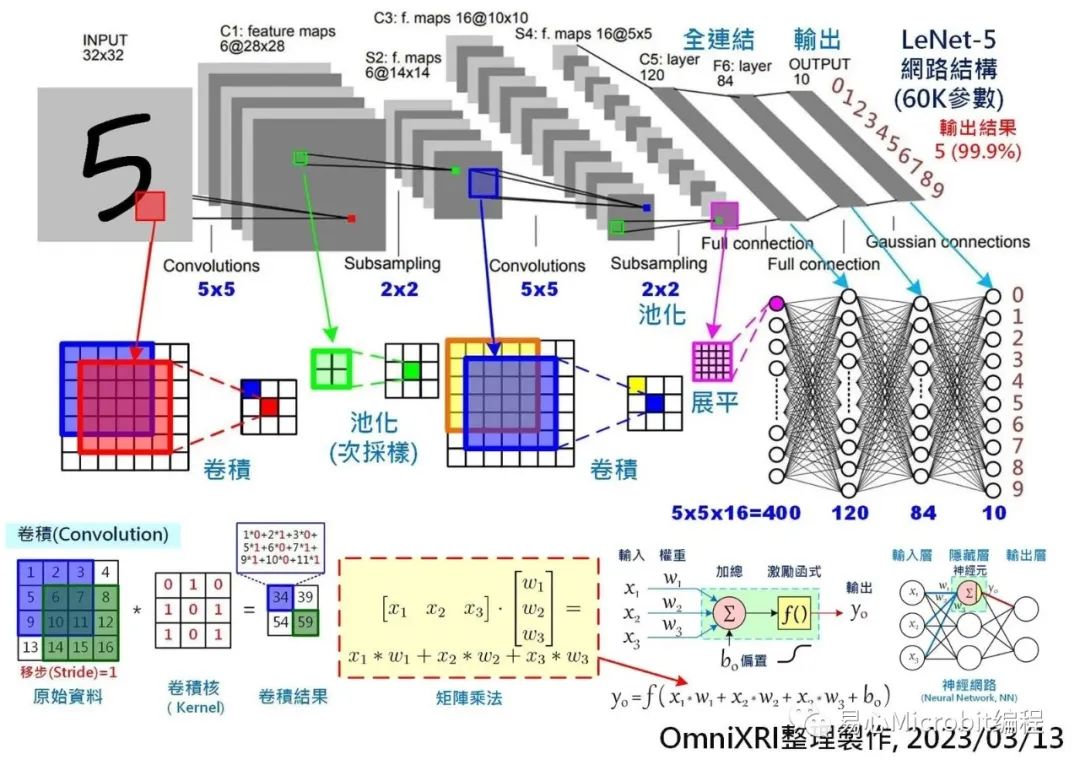
Fig. 1 手寫數(shù)字辨識LeNet-5卷積神經(jīng)網(wǎng)絡(luò)模型及卷積、矩陣乘法示意圖。
2. AI芯片類型
為了解決如此龐大且性質(zhì)單一的計(jì)算量,于是就有了硬件加速計(jì)算的需求,通常會將此類硬件稱呼為「AI芯片」(AI Chip) 或者「深度學(xué)習(xí)加速器」(Deep Learning Accelerator, DLA) 或者稱為 「神經(jīng)網(wǎng)絡(luò)處理單元」(NeuralNetwork Processing Unit, NPU) 。
在AI芯片領(lǐng)域中主要分為訓(xùn)練用及推論用。前者重點(diǎn)在效能,所以功耗及成本就不太計(jì)較。而后者會依不同應(yīng)用場合會有高效能、高推論精度、低功耗、低內(nèi)存空間、低成本等不同需求。尤其在Edge AI上更強(qiáng)調(diào)低功耗、低記體體空間及低成本需求,而效能表現(xiàn)通常就只能遷就不同硬件表現(xiàn)。
近幾年手機(jī)成長迅速,有很多芯片為了整體表現(xiàn),因此整合了很多功能在同一顆芯片上稱為SoC (System on Chip),包含CPU, DSP, GPU, NPU及像影音編譯碼的功能等。而FPGA的開發(fā)板也有反過來不過全部都自己設(shè)計(jì),而把常用的CPU, DSP, AISC等整合進(jìn)來,讓使用者能更專心開發(fā)自己所需的特殊功能,包含AI等應(yīng)用。
2.1 中央處理單元(CPU)
不論是像Arduino、小型IoT裝置使用的單芯片(Micro-controller / Micro Controll Unit, MCU),如STM,Microchip, ESP32, Pi Pico, Arm Cortex-M, RISC-V等,或者是像樹莓派、手機(jī)使用的微處理器(MicroProcessing Unit, MPU),如Arm Cortex-A系列、Qualcomm Snapdragon系列等,甚至是桌機(jī)、筆電常用的主芯片,如Intel, AMD x86系列等,都會有負(fù)責(zé)運(yùn)算的中央處理單元(Central Processing Unit, CPU)。
CPU可運(yùn)行各種形式的AI模型,不限矩陣運(yùn)算類型,彈性極高,但一次只能執(zhí)行一道運(yùn)算指令,如一個乘法或一個加法或一個乘加指令,效能極低。若搭配單指令流多數(shù)據(jù)流(Single Instruction Multiple Data, SIMD)指令集,如INTEL的AVX、ARM的NEON、RISC-V的P擴(kuò)充指令集,則可將32/64/128/256/512bit拆分成8/16/32 bit的運(yùn)算,如此便能提高4~64倍的運(yùn)算效能。另外亦可透過提高工作頻率頻率(MHz)或增加核心數(shù)來增加指令周期。
在MCU / MPU尚未有MAC及SIMD指令集前,當(dāng)遇到需要對數(shù)字聲音或影像進(jìn)行時(shí)間域轉(zhuǎn)頻率域計(jì)算如快速傅立葉變換(Fast Fourier Transform, FFT),常會遇到大量定點(diǎn)數(shù)或浮點(diǎn)數(shù)的的矩陣計(jì)算,此時(shí)就需要專用數(shù)字信號處理器(Digital Signal Processor, DSP)來加速計(jì)算。
此類處理器在AI專用芯片未出現(xiàn)前,亦有很多被拿來當(dāng)成浮點(diǎn)數(shù)矩陣加速計(jì)算使用,如Qualcomm Hexagon, Tensilica Xtensa, Arc EM9D等系列。它在開發(fā)上彈性頗高,價(jià)格居中,但僅適用于矩陣計(jì)算類的應(yīng)用,在MCU / MPU開始加入MAC、SIMD指令集及GPU技術(shù)大量普及后,逐漸被取代,目前大多只有少數(shù)獨(dú)立存在,大多依附于中大型微處理器中,或者整合至小型MCU芯片中代替NPU的工作。
2.3 圖形處理器(GPU)
圖形處理器(Graphics Processing Unit, GPU)是用于處理計(jì)算機(jī)上數(shù)字繪圖用的專用芯片,而其中最主要的功能就是在處理矩陣運(yùn)算,因此它能將CPU一次只能處理一個MAC的計(jì)算變成一次處理數(shù)百到數(shù)萬個MAC來加速運(yùn)算,同時(shí)可以分散CPU的計(jì)算負(fù)荷。早期有些科學(xué)家發(fā)現(xiàn)其特性,因此開發(fā)出GPGPU (General Purpose computing on Graphics Processing Units)函式庫來加速科學(xué)運(yùn)算。
2012年AlexNet透過GPU來加速訓(xùn)練深度學(xué)習(xí)模型,從此開啟GPU即為AI芯片代名詞的時(shí)代。目前主流GPU供貨商包括Nvidia (GeForce, Quadro, Tesla, Tegra系列) , Intel (內(nèi)顯HD, Iris及外顯Arc系列), Arm(Mali系列)等。
由于GPU原本是用于計(jì)算機(jī)繪圖,有大量電路、處理時(shí)間、耗能是用來處理繪圖程序,因此后續(xù)許多AI芯片的設(shè)計(jì)理念就是保留計(jì)算部份而去除繪圖處理部份,來提升芯片面積的有效率。目前使用GPU開發(fā)的彈性尚佳,但不適用于非大量矩陣計(jì)算的模型及算法。
另外為了容納更高的計(jì)算平行度,一次能處理更多的乘加運(yùn)算,因此芯片的制程也隨之越來越小(從數(shù)百nm到數(shù)nm)、晶體數(shù)量和芯片單價(jià)也越來越高,較適合大模型訓(xùn)練及高速推論用。
2.4 現(xiàn)場可程序化邏輯門陣列(FPGA)
一般開發(fā)如影像分類、聲音辨識、對象偵測、影像分割等AI專用型應(yīng)用甚至是MCU / MPU等通用型應(yīng)用芯片前,為確保投入像臺積電等晶圓代工廠生產(chǎn)前沒有電路及計(jì)算功能的問題,通常除了會使用軟件進(jìn)行仿真分析外,亦會使用FPGA (Field Programmable Gate Array)來進(jìn)行硬件驗(yàn)證。常見的供貨商有Xilinx(已被AMD收購)、Altera(已被Intel收購)、Lattice等。
FPGA除了可以驗(yàn)證IC的功能外,另外由于其超高彈性,所以可以排列組合出超過CPU / DSP / GPU 功能的應(yīng)用,且可以用最精簡的電路來設(shè)計(jì),以達(dá)到最低功耗、最高執(zhí)行效能。但此類型的開發(fā)非常困難,需要非常專業(yè)的工程師才有辦法設(shè)計(jì),且需配合相當(dāng)多的硅智財(cái)(Semiconductor intellectual property core,簡稱IP),因此大型FPGA的單價(jià)及開發(fā)成本是非常高的。
當(dāng)使用FPGA驗(yàn)證后,就可以將特殊應(yīng)用集成電路(Application Specific Integrated Circuit, ASIC)送到晶圓廠及封裝廠加工了。完成后的芯片就可獨(dú)立運(yùn)作,優(yōu)點(diǎn)是可大量生產(chǎn)讓單價(jià)大幅降低,能滿足市場需求,同時(shí)擁有極高的執(zhí)行效能和最低的功耗。但缺點(diǎn)是沒有任何修改彈性,萬一設(shè)計(jì)功能有瑕疵時(shí)就有可能需要全部報(bào)廢。因此當(dāng)沒有明確市場及需求量時(shí),通常會使用如CPU或GPU或CPU+NPU等通用型解決方案來取代。
2.6 神經(jīng)網(wǎng)絡(luò)處理器(NPU, DLA)
「神經(jīng)網(wǎng)絡(luò)處理單元」 (Neural Network Processing Unit, NPU) 或稱「深度學(xué)習(xí)加速器」(Deep Learning Accelerator, DLA) 是專門用于處理深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)運(yùn)算的特殊應(yīng)用集成電路(ASIC)。它較接近GPU的用法,所以可以一次處理很多的乘加運(yùn)算(MAC)。但因?yàn)橹回?fù)責(zé)乘加計(jì)算,無法處理大量數(shù)據(jù)搬移及邏輯性計(jì)算,所以通常必須搭配CPU使用。
大多數(shù)的AI芯片都是屬于這一類型,使用上較有彈性,可適合各式新模型的變化。不過由于NPU的軟硬接口規(guī)格無法統(tǒng)一,因此在開發(fā)上能支持的AI框架(如TensorFlow, TensorFolw Lite, TensoFlow Lite for Micro, PyTorch等)或IDE(如JupyterNotebook, Arduino, OpenMV, 各廠商MCU專屬IDE等)就有很大不同,選用前需考慮自身工程能力。
另外根據(jù)不同應(yīng)用,小型NPU主要用于推論,可以放到MCU / MPU 或手機(jī)中,如Intel (Movidius) Myriad, Arm Ethos U55, Google Coral等,大型NPU則可以放到桌機(jī)、云端服務(wù)器中,如Nvidia GTX / Tesla / A100, Google TPU等。
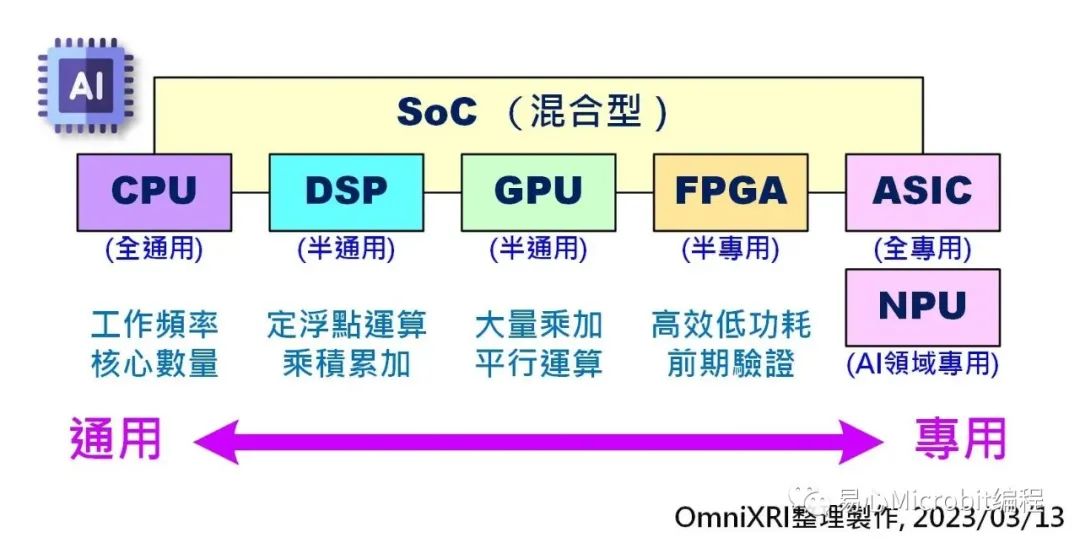
Fig. 2 不同類型AI芯片主要差異。
3. AI芯片最新趨勢
目前AI應(yīng)用越來越強(qiáng)大,模型權(quán)重?cái)?shù)量已從數(shù)萬個(如LeNet-5)激增到近一千多億個(如GPT3),傳統(tǒng)NPU、TPU及FPGA的速度已不夠快,功耗也大的驚人,因此近來開始有廠商在開發(fā)新的解決方案,企圖以更接近人腦運(yùn)行方式或者減少在計(jì)算時(shí)權(quán)重大量搬移問題,甚至使用光子進(jìn)行計(jì)算來進(jìn)行改善。以下就簡單介紹幾種常見方案,如Fig. 3所示。
(1) 可重構(gòu)型(Coarse GrainReconfigurable Architecture, CGRA):
可依不同需求以軟件重構(gòu)位寬度、MAC算子結(jié)構(gòu)、矩陣計(jì)算結(jié)構(gòu)、混合精度計(jì)算等。主要代表廠商如下:
?耐能(Kneron)
?Wave Computing
?清微智能
?云天勵飛
?燧原科技
(2) 類腦芯片(Neuromophic神經(jīng)型態(tài)):
主要模擬人類大腦神經(jīng)脈沖計(jì)算方式。有以下幾種方式及代表廠商:
?數(shù)位式:IBM TrueNorth, Intel Loihi, SpiNNaker
?模擬式:Neurogrid, BrainScales, ROLLS
?新材料式:Memristor
(3) 內(nèi)存內(nèi)記算(Compute inMemory, CIM)(也稱為存算一體、存內(nèi)計(jì)算):
主要將內(nèi)存和計(jì)算單元整合在一起,減少計(jì)算時(shí)海量存儲器搬移浪費(fèi)的時(shí)間。主要括下列幾種技術(shù):
?靜態(tài)(晶體管式)隨機(jī)存取內(nèi)存SRAM (揮發(fā)性內(nèi)存)
?磁阻式隨機(jī)存取內(nèi)存MRAM (非揮發(fā)性內(nèi)存)
?可變電阻式隨機(jī)存取內(nèi)存RRAM (非揮發(fā)性內(nèi)存)
(4) 光子芯片:
主要以光子代替電子,以提升指令周期。代表廠商包括:
?Lightmatter
?曦智(Lightelligence)
小結(jié)
歷經(jīng)近十多年的發(fā)展,AI加速芯片不論是在云端服務(wù)器所需要的大型模型訓(xùn)練或是模型高速推論,或者邊緣裝置所需小而美、高性價(jià)比的推論單元,都已有長足的進(jìn)步。相信隨著半導(dǎo)體技術(shù)的提升,未來Edge AI能運(yùn)行的模型大小、復(fù)雜度及所需的功耗都能有更棒的表現(xiàn),能適用的AI應(yīng)用也會更加寬廣。
審核編輯:湯梓紅
-
處理器
+關(guān)注
關(guān)注
68文章
19259瀏覽量
229652 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4771瀏覽量
100714 -
人工智能
+關(guān)注
關(guān)注
1791文章
47183瀏覽量
238253 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8406瀏覽量
132562 -
AI芯片
+關(guān)注
關(guān)注
17文章
1879瀏覽量
34990
原文標(biāo)題:AI芯片發(fā)展歷史及最新趨勢
文章出處:【微信號:易心Microbit編程,微信公眾號:易心Microbit編程】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論