 強化學習推進人工智能應用發展
強化學習推進人工智能應用發展
前言
幾年前,那些能夠感知環境、探測重要細節(忽視其它部分)且使用這些細節來完成任務的技術應用似乎只存在于科幻小說里。然而在2020年,我們看到不少技術的突飛猛進不僅上了頭條新聞,也成為我們日常生活的組成部分:智能語音助手能夠解讀并對人類語音的細微差別作出回應;相較于醫生使用的影像檢測,醫療應用能夠更準確地預測癌癥;無人駕駛車輛甚至能夠在動態環境中行駛。
三類機器學習之一的強化學習,正在驅動這些技術進步。一般原則促使計算機通過識別其所在環境的關鍵特性來作出最佳決定,而這項技能直到最近才成為可能。強化學習(RL)、人工神經網絡(ANN) 和深度學習(DL) 既展示了人工智能應用全新的潛力, 也體現了其達到人類水平的難度。
機器學習的方法
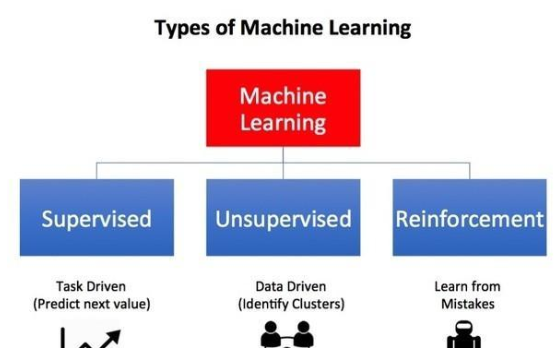
機器學習是人工智能的一個子集,它促使計算機從實例和經驗中學習。在機器學習的三個種類中,針對在相對容易預測的環境中解決明確界定的問題,監督學習和無監督學習或許是最廣為人知的方式。
監督學習方法 (SL) 用來解決有標記輸入數據的問題。監督學習算法嘗試通過對這些已知實例模式和關聯的學習,對未知實例進行正確處理。一個經典的例子就是圖像識別。附加人工注解的圖像被用來分析訓練模型數據,從而準確分類新捕捉的圖像。
無監督學習方法 (UL) 在無標記的數據集中推斷隱藏的結構或關系。一般來說這樣的學習方法不用過多的事先準備工作,而更具描繪性和解釋性的特征。它通常用來為受監督的方法做鋪墊。常見的例子是在交易數據中識別不同的客戶群,以便稍后規劃并開展有針對性的營銷活動。
機器學習的第三個方法是強化學習 (RL)。這也是目前在頭條新聞中大家看到的最復雜且類似于人的應用。深度學習是一種能夠通過獎勵和懲罰評估個體行動及加權輸入變量的機器學習,目的是在此基礎上規劃未來行動。RL努力最大化獎勵, 最小化懲罰, 并沒有被明確告知如何解決問題。它并非僅限于解決特定的問題或限制特別的環境,而是聚焦于那些能夠基于來自動態環境中的復雜數據選擇最優決策的機器。
強化學習
強化學習的基本理念是以接近人類(或任何足夠聰明的生物)處理的方式模型化學習,即用已具備的技能和工具試圖達成一個特定的目標(和獎勵相關),但無清晰的指令如何解決問題。舉個簡單的例子:機器人可以把手張開和握緊來把球放進盒子里。要想做到這一點,它必須學習如何抓住球,把手臂移動到合適的位置,再讓球落下。這項訓練需要多次迭代和重啟實驗;機器人獲得的唯一反饋是它的行為是否成功,從而調試動作直到目標達成。
這和監督學習形成了鮮明的對比, 因為SL需要很多的例子(比如一組龐大且多樣的貓的已標記圖像)來以多種維度描述問題本身。只有這樣,算法才能學習到底哪些特征 (比如形狀或顏色)和最佳決定的作出有關。回到之前所舉的機器人例子,同樣,它需要準確且謹慎地描述過程的每一個步驟, 比如把手放到哪兒,施加多少壓力等等。對于低變量的實例來說,做到這種程度的細節是可能的,但如果變量有差,就必須重新學習。球稍大點,機器人就可能犯錯。
在現實應用里,輸入、輸出和訓練數據的方程式出人意料的復雜。例如,無人駕駛車輛要處理大量幾乎實時的傳感器數據。錯過任何一個環境的細微差別都會造成不可想象的后果,因此風險很大。這就是為什么當創造訓練實例或指令在某一個環境中難以負擔或不可能時,強化學習是在這種背景下作決策的首選工具。
強化學習的子類型
和其它的機器學習方法一樣,強化學習有不同的子類型為未來鋪平道路(圖表 1 -下方)。尤其是特征學習 (FL) 讓系統能夠識別輸入數據的不同細節。人工神經網絡 (ANN) 和深度學習 (DL) 為高級解析、處理和學習提供了必要的框架,并使深度強化學習 (DRL) 得以實現。
特征學習
特征學習(也被稱為表示學習)是一種機器學習技術,讓機器能夠識別輸入數據的特征和獨立組成部分,而這些信息通常無法在算法中體現。比如,在一輛無人駕駛汽車里,環境是由不同的攝像頭、雷達和傳感器所感知的。即使有眾多信息幫助你決定下一步怎么走,相關的信息其實少之又少。比如,天空的顏色通常無關緊要,而紅綠燈的顏色則息息相關。 一只鳥飛過的速度和一個路人走到路邊的速度都無關痛癢。
具有體現這種程度的輸入功能的能力究竟為何如此重要? 用于訓練目的的數據集在模型的準確性上扮演著關鍵的角色:訓練數據越多越好,尤其是數據集里具備差異性大且特征清晰的實例。也就是說,正是那些輸入數據中獨一無二的獨立特征幫助計算機彌補已學和未學內容之間的差距,從而在任何情境下保證百分之百的準確性和連貫性。對差異因素的識別能力也有助于避免可能被忽視的特征和異常點, 因為隨著時間的推移,這將大幅減少數據的數量。
人工神經網絡和深度學習
變數大的應用需要一個穩健且可擴展的框架。尤其在監督學習領域,受到高度關注的一種學習方法要數深度學習了。與強化學習的原則相結合,我們稱之為深度強化學習。
人工神經網絡 (Artificial Neural Networks, ANN) 的最初設想要追溯到上世紀六十年代,籠統地建立在類似于網絡的人類大腦神經結構的基礎之上。ANN由一個龐大的人類神經原網絡所組成,這些神經原叫做感知器,能夠接受輸入信號,權衡輸入的不同特征,然后將信號導入網絡中,直到抵達輸出信號端。
網絡的屬性由神經原的數量、其連接的強度和數量及激活上限來定義。輸入信號必須具有此強度才能被傳送。ANN擁有包含多種輸入層和輸出層的可升級結構,使用中間“隱藏"層把輸入轉化成輸出層可使用的內容。深度學習的專用名詞正是來自于由大量接連層級的神經原網絡,因此是“深度的”。
為什么它被視為在復雜的輸入數據和動態的環境中創造最佳答案的最合適方法呢?答案就在它的學習方式:反向傳播。對于任何已給的訓練信號,比如描述向量坐標或一張圖像的顏色值,網絡會先檢查已生成的輸出正確與否,然后對權重稍作調整以實現想要的結果。經過足夠的訓練迭代,網絡不僅穩定性增加,而且能夠識別之前未知的情況。
人工神經網絡、深度學習和強化學習的局限性
由于人工神經網絡和深度學習有能力體現特征并在動態環境中得出最佳答案,因此他們的潛力不可估量。即便如此,它們的技能卻指向更多的挑戰,也呈現出與模仿人類智慧中的某些方面仍然存在的差距。
需要百萬千萬個節點、連接和訓練迭代
模塊化相關問題要求人工神經網絡具備足夠數量的節點和連接來處理(分析和存儲)百萬千萬計的變量。現代計算機直到最近才能夠做到這一點。同樣,訓練環路的數量可多達十億百億,且隨著環境變量的大小呈指數增長。強化學習的首次重大突破出現在像圍棋這樣的游戲中并非偶然,一個叫做阿爾法的圍棋機器人(AlphaGo)擊敗了人類最棒的職業圍棋選手:游戲的規則和目標非常明確,因此很容易讓人工智能通過和自己對戰快速模擬多輪游戲。下一步革命性的突破要數超級瑪麗或星際爭霸這樣的電子游戲。雖然行動和結果之間的關系更加復雜,但環境的局限性讓快速模擬多次迭代成為可能。
像無人駕駛這樣的現實問題的屬性則完全不同。制定安全到達目的地的這類高級任務本身難度并不高。然而環境的多樣性要求模擬必須更加成熟,才能更有效地學習實際問題。歸根結底,模擬駕駛最終還必須被現實駕駛所替代,以通盤考慮到所有其它無法被模塊化的因素,同時在與人類水平相當的駕駛表現目標實現以前,密切監控必不可少。舉例來說,2020年,自動駕駛汽車研發公司Waymo在一份新聞發布稿中提到,它們的汽車要想和人類一爭高下,還需要累計一千四百年的駕駛經驗。這和我們只花幾周時間練習就能上路相比簡直不可想象。那么為何強化學習無法做到這一點呢?還是這并非不可能……?
與抽象和推理相關的技能
人類能夠快速學習如何玩游戲或開車的一個重要原因是,我們通過抽象化和推理來學習。通過這種學習方式,駕駛員能夠以不同的角度或在不同的情境下想象紅綠燈是什么樣子,這依賴于人類與生俱來的空間意識。我們也可以在路上看見并判斷與以往看到的顏色不同的汽車,從觀察和經驗中得出結論。
而這些功能直到最近才在人工神經網絡中得以探索。即便不同的網絡層級能夠捕捉輸入數據的不同維度,例如 形狀和顏色,網絡還是只能處理那些訓練數據里明確容納的特征。假設人工智能的受訓時間是白天,那么模型將很難應付夜晚的各種情況。即使應用深度學習,在訓練數據中還是應該考慮到諸如此類的差異,那么來自訓練數據中可接受的偏差程度仍然非常低。
目前我們正在探索很多不同的通過抽象和推斷進行學習的技術,而這些技術甚至顯露了更多的挑戰性和局限性。人工神經網絡失誤的一個著名例子是,有一種計算機視覺系統能夠識別西伯利亞哈士奇犬,而且可信度相較于對于其它犬類的辨識高出很多。實際上,更仔細的分析表明,網絡僅鎖定了幾乎所有哈士奇圖像中出現的雪,而幾乎忽視了狗本身。換句話說,模型并沒有認知地面顏色并非狗的先天特征之一,而這一細節對人類來說卻是微不足道的。
雖然這個例子稍顯牽強,但現實生活中的后果可能會是可怕的。我們不妨再次以無人駕駛車輛為例,雖然事故很少發生,但卻可追根溯源到情境的模糊性。2018年的一場車禍中,推著一輛自行車穿過四車道高速的路人喪生。人類駕駛員可能很容易地避免事故的發生,而人工神經網絡的失誤卻導致了致命的車禍。由于當時的情況并沒有出現在很多小時的訓練中,網絡并沒有執行以“如果你不知道該怎么做,就停車!”為命令的故障切換。因此系統開始陣腳大亂,原因是它實際上缺乏人類智慧的基石。
更糟的是,不懷好意的人可能會鉆人工智能盲點的空子。舉例來說,如果有人在訓練過程中插入經操縱的圖像,那么圖像分類就會被誤導。如果說圖像中細小的變更對人類來說微乎其微,同樣的變更在ANN中則可能以不同的方式被認知和解讀。一個未加注解貼紙的停字牌可能被錯誤地認為其它交通標志。如果這一受訓模型被用在一輛真正的車里,那可能會造成交通事故。 反之,人類駕駛員肯定會毫無問題地認出停字牌。
跨越障礙和局限
這些障礙和其它的局限令我們不禁產生疑問,下一步該怎么走才能驅使人工神經網絡繼續在作出最佳決策上彌補不足? 簡單的答案是:“更多的訓練”。倘若訓練數據的差異性和質量夠高,失誤率就能縮小到模型的準確率是可接受的程度。事實上現今的自動駕駛汽車事故率比人類駕駛員要低,但“令人驚恐失色的事故”的潛在性還是阻礙了其被更為廣泛的公眾所接受。
另一個系統性方法是對所需的背景知識進行明確編碼,并在機器學習過程中可用。比如,由Cycorp創造的知識庫已經存在了很多年,涵蓋了數百萬的概念和關系,也包括了我們之前所說的停字牌的意義。目的是對人類知識以機器可讀的格式進行人工編碼,從而使人工智能不僅僅依賴于訓練數據,還能夠自行作出結論, 且至少以類似人類直覺的方式評估部分未知的情況。
總結
能夠感知環境、認知關鍵的細節并優化決策的技術已經不只存在于科幻小說中。機器學習三種類型之—的強化學習,為我們處理高維變量且與動態環境交互提供了工具和框架。然而,這些解決方案也帶來了新的挑戰,尤其是對于大量神經網絡、全面培訓和通過抽象化處理及推導從而模仿人類學習能力的需要,從而適應新情況。雖然目前人工智能已經取得了長足進展,也日益成為許多實際應用中不可或缺的一部分, 但是離達到人類水平的學習技能還相去甚遠。經歷并體驗中間的過程可能比科幻小說本身更有意思。
審核編輯:郭婷
-
人工智能
+關注
關注
1800文章
48083瀏覽量
242164 -
機器學習
+關注
關注
66文章
8460瀏覽量
133414 -
無人駕駛
+關注
關注
98文章
4108瀏覽量
121588
發布評論請先 登錄
相關推薦
人工智能發展的好與壞
人工智能和機器學習技術在2021年的五個發展趨勢
人工智能芯片是人工智能發展的
人工智能汽車標定方案
《移動終端人工智能技術與應用開發》人工智能的發展與AI技術的進步
機器學習和人工智能有什么區別?
將深度學習和強化學習相結合的深度強化學習DRL
如何深度強化學習 人工智能和深度學習的進階
什么是強化學習?純強化學習有意義嗎?強化學習有什么的致命缺陷?







 工商網監
工商網監
評論