 尋找開源100G NIC Corundum中的隱藏BUG
尋找開源100G NIC Corundum中的隱藏BUG
差不多整整三年前,即2020年5月12日時,我們分享了一篇有關100G開源網卡的文章《業界第一個真正意義上開源100 Gbps NIC Corundum介紹》。隨后又陸陸續續分享了多次有關Corundum上板測試及仿真環境搭建的文章:《揭秘:普通電腦換上Xilinx Alveo U50 100G網卡傳文件會有多快?》,《開源100 Gbps NIC Corundum環境搭建介紹(一)》和《開源100 Gbps NIC Corundum環境搭建介紹(二)仿真及工程恢復》。三年來,學術界發表了多篇依據該開源架構的論文,工業界也在該開源架構的基礎上開發多種產品。我們在使用該開源項目的過程中,發現了該開源工程中也存在不少的問題,本著開源的精神,本文就把發現Corundum中部分問題的過程以及問題解決思路分享給大家,希望能夠給大家帶來幫助。本文作者是李釗同學,前面提到本公眾號有關Corundum環境搭建文章的作者也是李釗。
Corundum是一個基于FPGA的開源NIC原型平臺,用于高達100Gbps及更高的網絡接口開發。Corundum平臺包括一些用于實現實時,高線速操作的核心功能,包括:高性能數據路徑,10G/25G/100G以太網MAC,PCIe gen3,自定義PCIe DMA引擎以及本機高精確的IEEE 1588 PTP時間戳。
背景
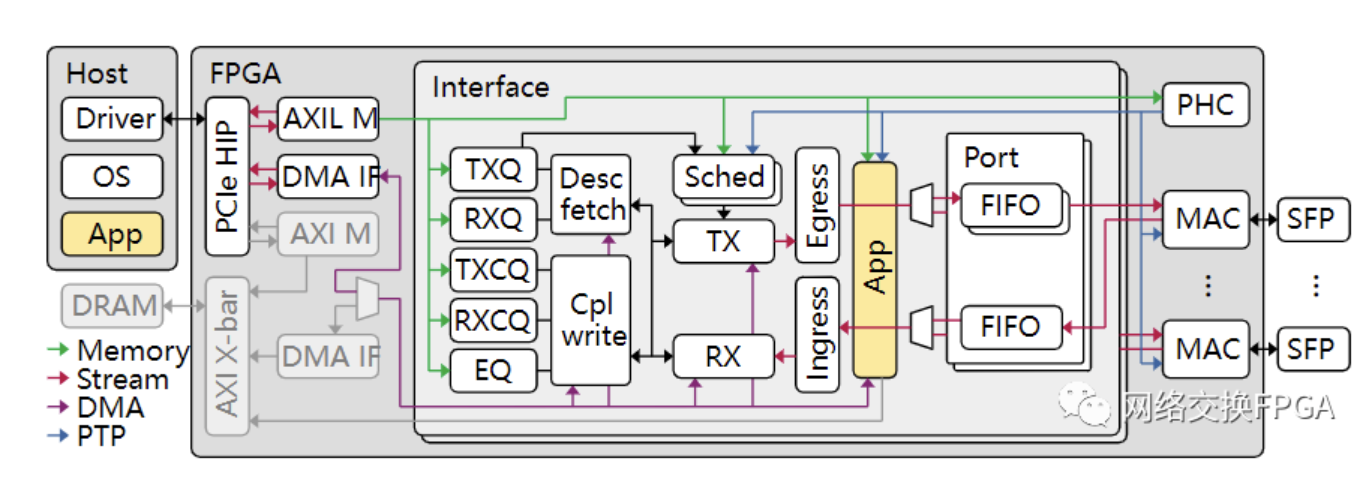
我們基于Corundum這個靈活且強大的平臺開發了一款網絡加速器。如圖所示,我們的設計(位于APP黃色部分)需要和原生數據流量共用一套DMA IF和主機HOST進行通信。紫色數據路徑為用于DMA操作的自定義分段內存接口,連接著Corundum的高性能DMA引擎和分段存儲器。
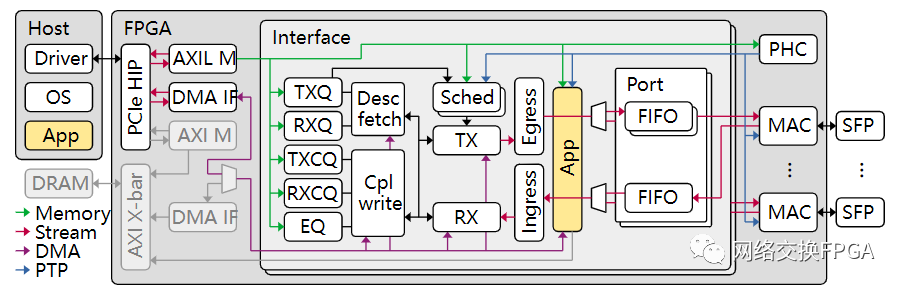
在我們的設計中,需要頻繁的進行DMA讀寫操作。DMA操作大致有兩種類型,一種是小數據包的DMA,長度在16B-64B之間,內容為硬件和主機通信的描述符,存放于Desc fetch和Cpl write模塊內的描述符分段存儲器;一種是大數據包的DMA,長度大于1kB,內容為傳輸數據,存放于APP下的數據分段存儲器。
我們的設計通過了大量仿真,確認開發設計功能無誤,隨后開始上板測試。
問題
我們的PCIe鏈路速率gen3 * 8,PCIe理論帶寬為64G。在上板時出現了很奇怪的現象。
每次測試發送小數量級的請求時(<10000次,每次代表一次小數據包的DAM和一次大數據包的DMA),估算PCIe帶寬在25G-35G左右。這種測試情況下不會發生錯誤,測試順利通過。
當測試請求數量進一步增大時(>10萬次),預估PCIe帶寬在35G~40G。此時測試就會發生問題,整個系統癱瘓。
定位
進一步定位問題,主機和FPGA還可以通過MMIO進行寄存器訪問,但是DMA已經完全卡死。
在DMA IF下設置計數器用于統計DMA Read請求的個數和響應:
if(s_axis_read_desc_valid&&s_axis_read_desc_ready)begin dma_read_req_cnt<=?dma_read_req_cnt?+?1'b1; end if(?m_axis_read_desc_status_valid?)?begin ????dma_read_status_cnt?<=?dma_read_status_cnt?+?1'b1; end
上板debug信號,每次測試癱瘓后請求的個數總是大于響應的個數。

在Corundum中,DMA引擎是這樣工作的:
DMA引擎接收來自用戶的DMA Read請求,然后將DMA Read請求轉換為PCIe Non-Posted 類型的mem read請求TLP包,然后等待mem read的Cpld返回報文,解析Cpld報文,將數據通過自定義分段內存接口存儲至各級模塊下的分段存儲器中,存儲完成后將回復DMA Read響應至用戶。
結合對DMA 引擎的理解,可以推測有以下幾個可能導致響應個數不夠
PCIe IP錯誤導致rd tlp或cpld丟失;
DMA引擎因返回cpld攜帶錯誤而丟棄cpld;
DMA引擎因PCIe流控發生不可預知的錯誤,隨機丟棄數據包;
其他原因;
分析原因:
PCIe IP為Xilinx UltraScale+ Integrated Block(PCIE4C) for PCI Express,成熟的商用IP經過了大規模驗證和使用一般不會出現問題,可以暫且排除因素1。
抓取相關的錯誤信號(rx_cpl_tlp_error、status_error_cor、status_error_uncor),結果表明PCIe并未發生可糾正/不可糾正的錯誤類型,表示通信雙方鏈路正常,并沒有因為錯誤而丟棄報文導致響應的數量不夠,可以排除因素2。
首先Corundum是一款100Gbps速率的網卡設計,經過了大量驗證和上板測試;其次測試的PCIe理論帶寬為64Gbps。而此時的測試帶寬35G~40G遠遠不足s設計帶寬或是鏈路帶寬上限,應該不會觸發流控機制。這里因素三也需要被排除。
求助Alex Forencich
最了解自己設計的一定是作者本人。我隨后在Zulip上求助了作者,希望他可以幫我想一想導致此問題其他有可能的因素。
Alex很熱心,對每個問題都會做出回復。

他表示這種問題很難定位,需要精確的定位“案發現場”才有可能定位問題。
我可以確保每次DMA操作的地址和長度都是合理的,并且由于mem read tlp為Non-Posted類型,因此需要等待一定的PCIe鏈路時延才能得到返回報文。這兩項特質決定了很難定位至發生錯誤的DMA操作,無法恢復到錯誤發生的那一時刻。
他告訴了我一種定位的手段:
設置足夠深的ILA緩沖,用計數器擴展以檢測掛起:基本上,在每個周期遞增,但如果計數一致或有響應,則重置;然后將該計數器輸入ILA;并觸發各種計數器值。注意:觸發器位置靠近緩沖器末端。
基于此思路,我做出了以下設置:
設置ILA深度至8192,并且調整每次DMA Read的長度為4K,確保能夠在ILA深度內抓到完整的DMA操作。
dma_read_cycle_cnt作為需要觸發的計數/時器,沒收到一個DMA Read請求開始隨時鐘周期自增,收到DMA Read請求響應清零;dma_read_cycle_max_cnt用來記錄正常情況下Non-Posted完成的最大計數值。將觸發條件設置為dma_read_cycle_cnt > dma_read_cycle_max_cnt,這樣就可以觸發到模塊出錯的時刻。調整dma_read_cycle_max_cnt觸發條件,逐步逼近出錯時刻。
if(m_axis_read_desc_status_valid)begin dma_read_cycle_cnt<=?32'b0; end?else?if(s_axis_read_desc_valid?&&?s_axis_read_desc_ready)begin ????dma_read_cycle_cnt?<=?32'b1; end?else?if(dma_read_cycle_cnt?>=1'b1)begin dma_read_cycle_cnt<=?dma_read_cycle_cnt?+?1'b1; end?else?begin ????dma_read_cycle_cnt?<=?dma_read_cycle_cnt; end if(m_axis_read_desc_status_valid?&&?(dma_read_cycle_cnt[23:0]?>dma_read_cycle_max_cnt))begin dma_read_cycle_max_cnt<=?dma_read_cycle_cnt; end?else?begin ????dma_read_cycle_max_cnt?<=?dma_read_cycle_max_cnt; end
同時,在ILA內抓取一些相關的重要信號:基本的握手信號和相關流控信號。
外加統計read tlp的請求數據長度累計和返回cpld的數據長度累計。
定位“案發現場”
按照觸發設置,終于在ILA中捕獲到“案發現場”。
某個時刻,握手信號rx_cpl_tlp_ready不再置1,但rx_cpl_tlp_valid還存在。表明DMA引擎出現了問題,無法再接收返回的cpld報文。

也就是從此刻開始,DMA Read請求的個數在一直增加,但是DMA Read響應的個數卻不再增長。

定位到了出錯時刻,此時便可以對模塊內的重點信號展開分析。
原因分析
前文已經去除掉了面向HOST的種種因素,因此最有可能出問題的地方只能是面向用戶的用于DMA操作的自定義分段內存接口。
這里的分段內存接口是Corundum獨特的體系結構的一種,對于PCIe上的高性能DMA,Corundum使用自定義分段存儲器接口。該接口被分成最大512位的段,并且整體寬度是PCIe硬IP內核的AXI流接口寬度的兩倍。例如,將PCIe Gen 3 x16與PCIe硬核中的512位AXI流接口一起使用的設計將使用1024位分段接口,該接口分成2個段,每個段512位。與使用單個AXI接口相比,該接口提供了改進的“阻抗匹配”,從而消除了DMA引擎中的對齊和互連邏輯中的仲裁,從而消除了背壓,從而提高了PCIe鏈路利用率。具體地說,該接口保證DMA接口可以在每個時鐘周期執行全寬度,未對齊的讀取或寫入。此外,使用簡單的雙端口RAM(專用于在單個方向上移動的流量)消除了讀寫路徑之間的爭用。
在自定義分段內存接口中,使用ram_wr_cmd_sel路由和復用。基于單獨的選擇信號而不是通過地址解碼進行路由的。此功能消除了分配地址的需要,并允許使用可參數化的互連組件,這些組件以最少的配置適當地路由操作。
outputwire[RAM_SEG_COUNT*RAM_SEL_WIDTH-1:0]ram_wr_cmd_sel, outputwire[RAM_SEG_COUNT*RAM_SEG_BE_WIDTH-1:0]ram_wr_cmd_be, outputwire[RAM_SEG_COUNT*RAM_SEG_ADDR_WIDTH-1:0]ram_wr_cmd_addr, outputwire[RAM_SEG_COUNT*RAM_SEG_DATA_WIDTH-1:0]ram_wr_cmd_data, outputwire[RAM_SEG_COUNT-1:0]ram_wr_cmd_valid, inputwire[RAM_SEG_COUNT-1:0]ram_wr_cmd_ready, inputwire[RAM_SEG_COUNT-1:0]ram_wr_done,
DMA Read引擎使用分段內存的寫入接口,將獲取的cpld數據寫入分段存儲器中。使用ram_wr_cmd_sel決定寫入哪個分段存儲器,使用ram_wr_cmd_addr決定寫入分段存儲器的地址,使用ram_wr_done判斷寫入操作完成。
同樣為分段內存接口設置計數器,用于統計分段內存接口的寫入和寫入完成操作。
if(ram_wr_cmd_valid[0]&&ram_wr_cmd_ready[0])begin dpram_wr_cmd_cnt0<=?dpram_wr_cmd_cnt0?+?1'b1; end if(ram_wr_cmd_valid[1]?&&?ram_wr_cmd_ready[1])begin ????dpram_wr_cmd_cnt1?<=?dpram_wr_cmd_cnt1?+?1'b1; end??? if(ram_wr_done[0])begin ????dpram_wr_done_cnt0?<=?dpram_wr_done_cnt0?+?1'b1; end if(ram_wr_done[1])begin ????dpram_wr_done_cnt1?<=?dpram_wr_done_cnt1?+?1'b1; end???
問題就出現在這里:

在“案發時刻”之后,分段內存接口處不再有寫入完成信號ram_wr_done。可以證明問題就出在這里,不再有內存寫入完成信號,導致DMA IF遲遲無法確認數據操作完成,進而導致無法接收新的Cpld報文數據(防止數據覆蓋)。
進一步分析“案發時刻”之前分段內存接口的所有波形,終于在某個時刻找到了異樣。在此時刻,分段存儲器的地址不再是線性增加,發生了跳變,執行完0地址的寫入之后再恢復正常。

與DMA Read操作關聯起來,并且充分考慮到Non-Posted操作的PCIe鏈路時延,從“案發時刻”之前的13次DMA Read刪選出出錯的那一次DMA Read操作。
首先進行了一個4kB的大DMA Read操作;
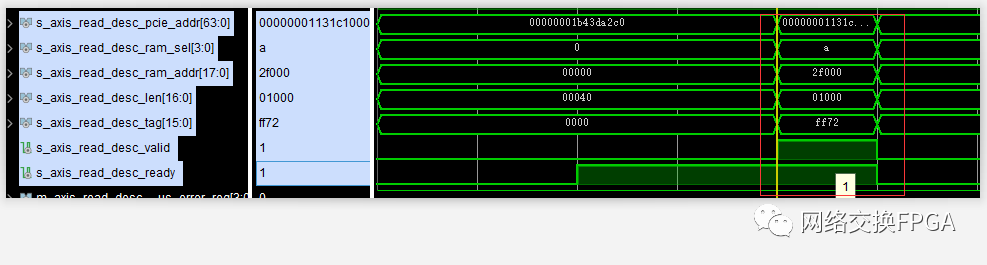
隨后便是一個64B的小DMA Read操作:
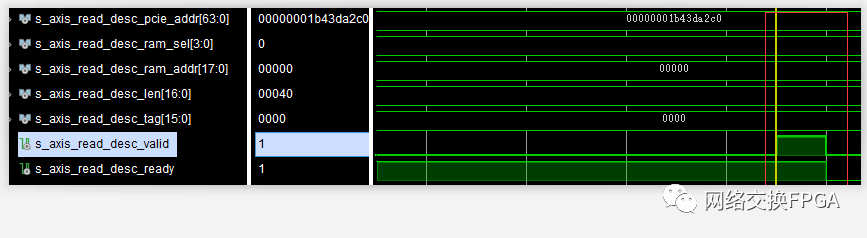
所以按理來說,分段內存應該先執行完4kB的數據寫入操作之后,再進行64B的數據寫入操作。
但抓取到的波形卻顯示數據寫入操作地址發生了跳變,0x5fc -> 0x000 -> 0x5fd。
而這正是觸發測試錯誤的條件:兩次mem rd tlp的cpld碰巧發生了交織,或者說發生了亂序。小數據包的cpld超越了部分大數據包的cpld,先一步通過PCIe鏈路傳送至硬件。這種完成報文之間的亂序恰巧是PCIe協議所允許的,用于保證生產者/消費者模型的正確運轉,防止死鎖的發生。
如果完成報文與之前的完成報文的Transaction ID不同,該報文可以超越之前的完成報文;如果相同,則不能超越。這里恰巧是兩個連續的不同DMA Read操作,Transaction ID的tag必不相同,所以亂序是會發生的。
在仿真中恢復案發現場
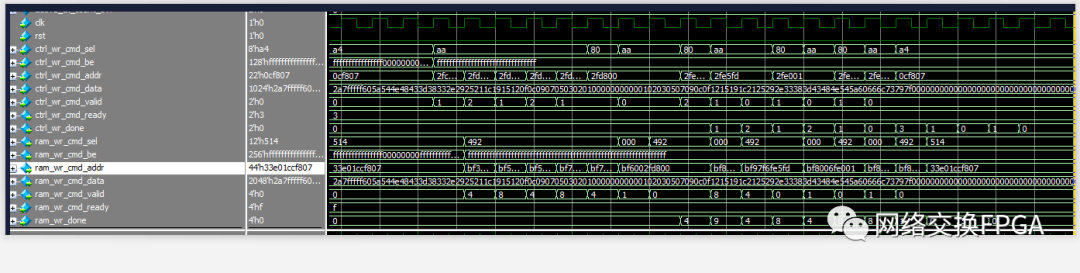
在仿真中,將“案發時刻”前后的波形文件csv導入仿真環境,或者直接使用force-release強制激勵即可恢復案發現場。
通過在仿真中檢查,很快便定位到是最近一級的dma_mux模塊出現了問題,它會在這種情況下丟棄1-2個ram_wr_done。這有可能是每個分段存儲器的寫入路徑時延不同,導致done信號同時到達mux模塊或者是mux模塊因為被占用而無法處理某一個分段存儲器的寫入完成,導致done信號丟失。
修改BUG
隨后詢問了Alex我的想法是否正確:
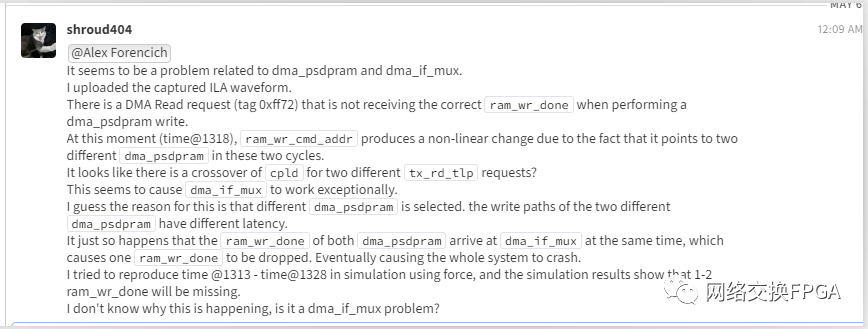
他表示編寫mux時使用fifo和計數器來捕獲所有的done脈沖信號,并按正確的順序轉發,但似乎存在一個bug。
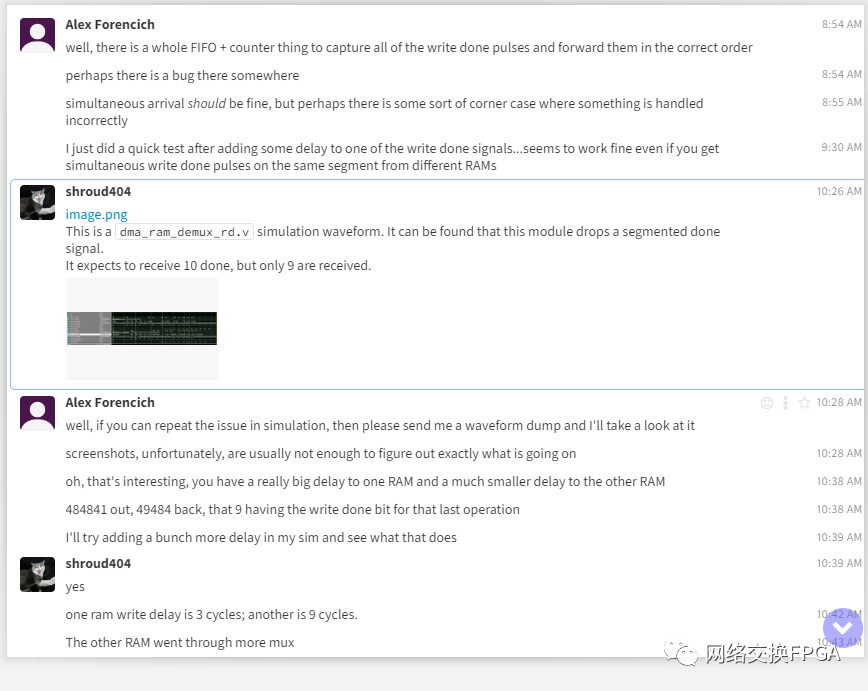
隨后也證明確實是dma_ram_demux_wr這個模塊存在問題:

Alex隨后進行了BUG修改。對輸入dma_ram_demux_wr的完成的done信號加入雙向確認機制,確保不會遺漏任何done信號。
將修改完的代碼進行了仿真測試,隨后也通過了FPGA上板測試。
總結
錯誤的觸發條件:兩次mem rd tlp的cpld發生亂序。小數據包的cpld超越了部分大數據包的cpld,先一步通過PCIe鏈路傳送至硬件。
錯誤原因:dma_ram_demux_wr因為ram_wr_done輸入擁塞而丟失了分段內存接口的寫入完成信號ram_wr_done。
進一步分析:為什么Corundum跑到100G帶寬下都不會出現此問題?
Corundum下DMA的自定義分段內存接口拓撲如圖所示:
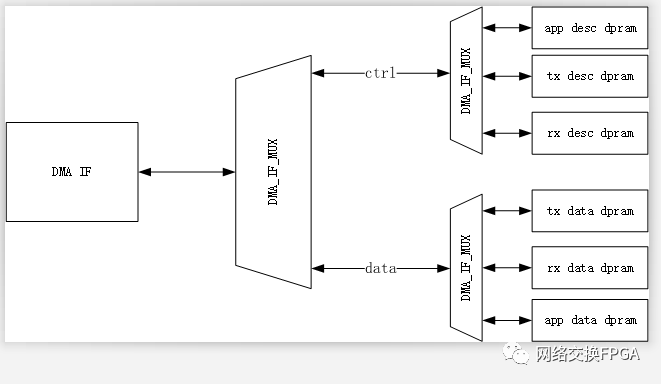
在Corundum的架構下,DMA IF 到所有分段存儲器的寫入路徑延遲是一致的,因此即使發生了cpld亂序,dma_ram_demux_wr也不會因為ram_wr_done輸入擁塞而丟失done個數。
在我們的設計中,在APP下仍會進行若干級的DAM MUX將DMA引擎進一步復用。
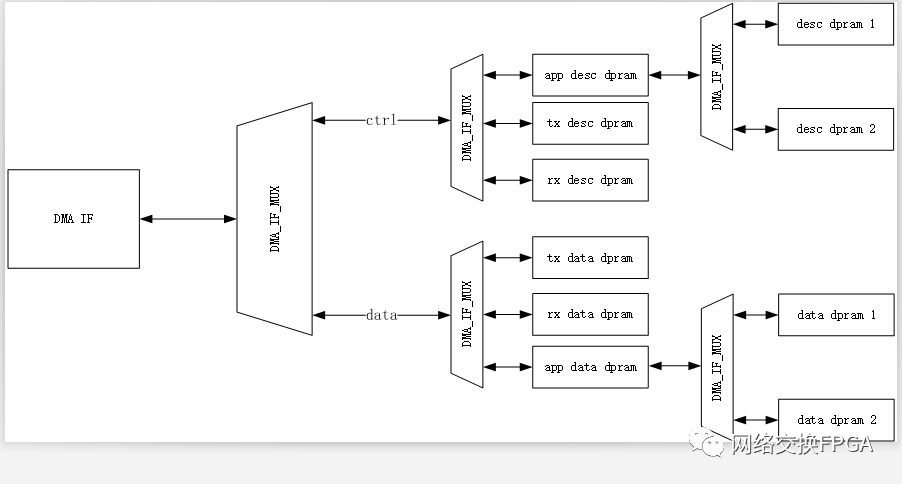
這樣就會導致存在兩個分段存儲器的寫入路徑延遲不一致,進一步導致在dma_ram_demux_wr寫入完成接口處發生爭用導致ram_wr_done丟失。
補充:修改完此BUG之后,每級dma_if_mux會引入一拍額外的時延(用于雙向確認),因此會對DMA引擎的性能造成一定影響。為消除此影響,可以將dma_if_pcie_rd模塊下的參數STATUS_FIFO_ADDR_WIDTH和OUTPUT_FIFO_ADDR_WIDTH由5擴大為6,使用更多資源來抵消額外的時延影響。
審核編輯 :李倩
-
FPGA
+關注
關注
1629文章
21729瀏覽量
603007 -
存儲器
+關注
關注
38文章
7484瀏覽量
163764 -
加速器
+關注
關注
2文章
796瀏覽量
37840
原文標題:【干貨】尋找開源100G NIC Corundum中的隱藏BUG
文章出處:【微信號:gh_cb8502189068,微信公眾號:網絡交換FPGA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
100G光模塊專題:100G光模塊概述、優點和應用
什么是100G光模塊?介紹:100G光模塊標準、參數、優勢
100G AOC有源光纜和100G高速線纜有什么區別?
什么是100G SR4光模塊?100G SR4有哪些特性、優點和應用?
對于100G光模塊,你了解多少?
100G CWDM4光模塊概述
如何實現100G光傳送網?
普通電腦換上Xilinx Alveo U50 100G網卡傳文件會有多快
Opnext的100G CFP模塊技術
100G光模塊主流標準都有哪些
P2100G - 2 X 100GBE PCIE NIC 高性能,功能豐富的NetXtreme?E系列雙端口100G PCIe以太網NIC

開源100 Gbps NIC Corundum環境的搭建
尋找開源100G NIC Corundum中的隱藏BUG






 工商網監
工商網監
評論