 如何通過一個簡單的方法來解鎖大型語言模型的推理能力?
如何通過一個簡單的方法來解鎖大型語言模型的推理能力?
一、概述
近來NLP領域由于語言模型的發展取得了顛覆性的進展,擴大語言模型的規模帶來了一系列的性能提升,然而單單是擴大模型規模對于一些具有挑戰性的任務來說是不夠的,比如算術、常識、符號推理任務(arithmetic, commonsense, symbolic reasoning)。本文探討了如何通過一個簡單的方法來解鎖大型語言模型的推理能力,這個方法由兩個想法驅動。第一個想法是算術推理的技術能夠從生成自然語言解釋(rationale)中獲益。先前的工作通過從頭開始訓練或微調預訓練模型,以及采用形式語言的神經-符號方法來使模型能夠生成自然語言的中間步驟。第二個想法是利用大型語言模型實現上下文中的少數樣本學習(few-shot learning),即通過提示(prompting)提供少量輸入-輸出示例,而不是為每個新任務微調單獨的語言模型。這種方法在一系列簡單問答任務上取得了成功。
然而,這兩種方法都存在局限性。對于添加解釋的訓練和微調方法,創建大量高質量解釋的成本很高,遠比傳統機器學習中使用的簡單輸入-輸出對復雜得多。而傳統的少數樣本提示方法在需要推理能力的任務上表現不佳,且隨著語言模型規模的增加,性能提升有限。為了克服這些局限性,作者將這兩個想法相結合,提出了一種稱為“思維鏈提示”(chain-of-thought prompting)的方法。在這種方法中,模型接收到的提示包含三個部分:輸入、思維鏈和輸出。思維鏈是一系列自然語言中的中間推理步驟,它們導致最終輸出。
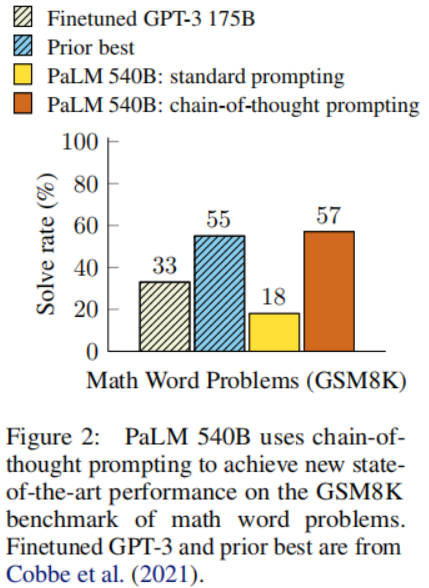
本文通過在算術、常識和符號推理基準任務上的實證評估表明,思維鏈提示在性能上優于標準提示,有時甚至達到令人驚嘆的程度。例如,在GSM8K數學問題基準測試中,PaLM 540B模型使用思維鏈提示大幅度優于標準提示(如下圖),達到了新的SOTA水平。提示方法的重要性在于它不需要大量訓練數據集,并且單個模型檢查點可以執行多個任務而不會失去通用性。這項工作強調了大型語言模型如何通過少量自然語言任務數據來學習(例如通過大型訓練數據集自動學習輸入和輸出的潛在模式)。
實驗
二、方法
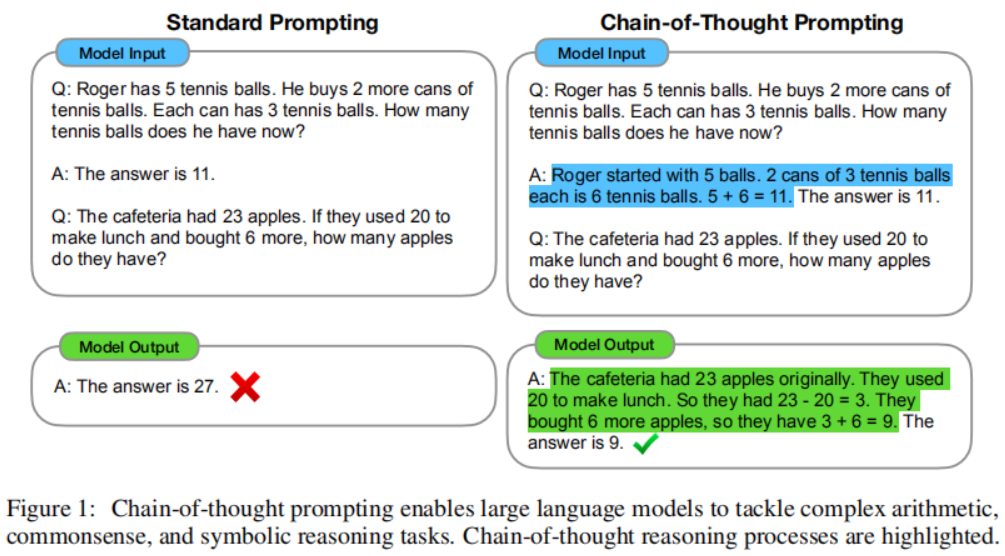
當人們解決這類問題時,通常會將問題分解成中間步驟,逐個解決,最后給出答案。本文的目標是賦予語言模型生成類似思維鏈的能力,即一個連貫的中間推理步驟序列,引導模型找到問題的最終答案。作者表明,如果在少數樣本提示中提供思維鏈推理的示例,足夠大的語言模型可以生成思維鏈。下圖展示了一個模型在解決數學問題時產生的思維鏈示例。在這種情況下,思維鏈類似于一個解決方案,但作者仍選擇稱其為思維鏈,以更好地捕捉模擬逐步解決問題的思維過程的概念。
思維鏈示例
思維鏈提示作為促進語言模型推理的方法具有以下幾個有吸引力的特性:
①原則上,思維鏈允許模型將多步問題分解為中間步驟,這意味著可以為需要更多推理步驟的問題分配額外的計算能力。 ②思維鏈為模型的行為提供了一個可解釋的窗口,提示模型如何得出特定答案,并為發現推理路徑中的錯誤提供調試機會(盡管完全描述支持答案的模型計算仍然是一個開放性問題)。 ③思維鏈推理可用于諸如數學問題、常識推理和符號操作等任務,并且原則上適用于任何人類可以通過語言解決的任務。 ④最后,通過在少數樣本提示的示例中包含思維鏈序列,可以輕松地在足夠大的現成語言模型中引出思維鏈推理。
本文在算術、常識、符號推理任務上進行了實驗,實驗中不同數據集的思維鏈提示示例如下:

示例
三、算術推理
實驗設置
這部分首先考慮了類似于圖1所示的數學問題,用以衡量語言模型的算術推理能力。盡管對人類來說很簡單,但算術推理是一個讓語言模型常常感到困難的任務。令人驚訝的是,當將思維鏈提示應用于具有540B參數的語言模型時,在幾個任務上與特定任務的微調模型表現相當,甚至在具有挑戰性的GSM8K基準測試上實現了新的SOTA水平。
Benchmarks
我們考慮了以下五個數學問題benchmark數據集:
①GSM8K數學問題基準測試; ②SVAMP數據集,包含不同結構的數學問題; ③ASDiv數據集,包含多樣化的數學問題; ④AQuA數據集,包含代數問題; ⑤MAWPS基準測試。
Standard prompting(標準提示)
作為baseline,我們采用GPT-3論文中的標準few-shot prompting,其中語言模型在為測試時示例輸出預測之前獲得了輸入-輸出對的上下文示例。示例以問題和答案的形式呈現。如圖1(左)所示,模型直接給出答案。
Chain-of-thought prompting(思維鏈提示)
我們提出的方法是用問題的關聯答案的思維鏈來增強few-shot prompting中的每個示例,如圖1(右)所示。由于大多數數據集僅有一個評估分割,我們手動編寫了一組包含思維鏈提示的八個少數樣本示例——圖1(右)顯示了一個思維鏈示例。這些特定示例沒有經過提示工程。為了研究這種形式的思維鏈提示是否可以成功引導成功解答一系列數學問題,我們使用了這八個思維鏈示例,適用于除AQuA之外的所有基準測試,因為AQuA是多項選擇而非自由回答。對于AQuA,我們使用了來自訓練集的四個示例和解決方案
語言模型
我們評估了五個大型語言模型。
①GPT-3,我們使用了text-ada-001、text-babbage-001、text-curie-001和text-davinci-002,它們可能對應于具有350M、1.3B、6.7B和175B參數的InstructGPT模型。 ②LaMDA,它有422M、2B、8B、68B和137B參數的模型。 ③PaLM,具有8B、62B和540B參數的模型。 ④UL2 20B。 ⑤Codex。
我們通過貪婪解碼從模型中采樣(盡管后續工作顯示,通過在許多采樣生成中采取多數最終答案,可以改進思維鏈提示)。對于LaMDA,我們報告了五個隨機種子的平均結果,每個種子具有不同的隨機洗牌順序的示例。由于LaMDA實驗在不同種子之間沒有顯示出較大的方差,為節省計算資源,我們對所有其他模型報告了單個示例順序的結果。
結果
算術推理
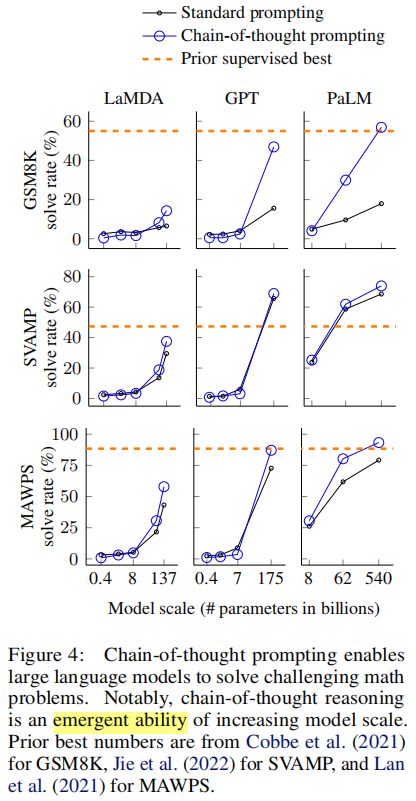
思維鏈提示的最優結果匯總在上圖中。實驗的結果主要反映出三個關鍵要點。
首先,上圖顯示,思維鏈提示是模型規模的一種涌現能力(emergent ability)。也就是說,對于小型模型,思維鏈提示不會對性能產生積極影響,只有在與大約100B參數的模型一起使用時,才能產生性能提升。我們發現,較小規模的模型產生了流暢但不合邏輯的思維鏈,導致性能低于標準提示。
其次,對于更復雜的問題,思維鏈提示的性能提升更大。例如,對于GSM8K(baseline性能最低的數據集),最大的GPT和PaLM模型的性能提高了一倍多。另一方面,對于SingleOp(MAWPS中最簡單的子集,只需要一個步驟就可以解決),性能改進要么是負面的,要么非常小。
第三,通過GPT-3 175B和PaLM 540B的思維鏈提示,與之前的最佳實踐相比,表現相當不錯,后者通常在帶標簽的訓練數據集上對特定任務的模型進行微調。上圖顯示了PaLM 540B如何使用思維鏈提示在GSM8K、SVAMP和MAWPS上實現新的SOTA(請注意,標準提示已經超過了SVAMP的之前最佳記錄)。在另外兩個數據集AQuA和ASDiv上,PaLM使用思維鏈提示的方法達到了距離最佳水平2%以內。
為了更好地了解為什么思維鏈提示起作用,我們手動檢查了LaMDA 137B在GSM8K上生成的思維鏈。在50個隨機樣本中,模型給出了正確的最終答案,除了兩個恰好得到正確答案的樣本外,所有生成的思維鏈都是邏輯和數學上正確的。我們還隨機檢查了50個模型給出錯誤答案的樣本。總結一下這個分析,46%的思維鏈幾乎是正確的,只有一些小錯誤(計算錯誤、符號映射錯誤或缺少一個推理步驟),另外54%的思維鏈在語義理解或連貫性方面存在重大錯誤。為了更好地了解為什么規模化改善了思維鏈推理能力,我們對PaLM 62B犯的錯誤以及將其擴展到PaLM 540B是否修復了這些錯誤進行了類似的分析。總結來說,將PaLM擴展到540B能修復62B模型中的大部分缺失一步和語義理解錯誤。
這些結果表明,通過引入思維鏈提示,我們可以顯著提高大型語言模型在解決數學問題方面的性能,特別是在處理更復雜數學問題時。盡管較小的模型在生成思維鏈時可能會產生不合邏輯的結果,但隨著模型規模的增加,這種方法在很大程度上提高了解決問題的準確性和邏輯性。
總之,通過在數學問題上應用思維鏈提示,研究人員觀察到了顯著的性能提升。隨著模型規模的增加,這種方法在解決更復雜數學問題時變得更加有效。此外,通過將思維鏈提示與大型模型結合使用,研究人員能夠實現接近甚至超過之前最佳實踐的性能。這表明,思維鏈提示是一種有前景的方法,可以幫助提高大型語言模型在數學和其他需要多步推理的任務上的性能。
消融實驗
消融實驗
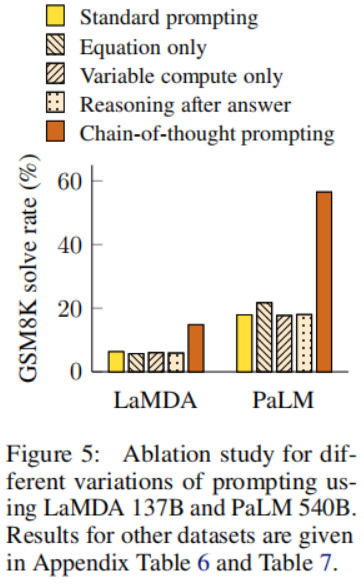
使用思維鏈提示所觀察到的優勢引發了一個自然問題:其他類型的提示是否也能帶來相同的性能提升。上圖展示了一個消融實驗,其中描述了以下三種思維鏈的變體。
Equation only
使用思維鏈提示可能有助于生成要評估的數學公式,所以我們測試了一個變體,在給出答案之前提示模型僅輸出數學公式。上圖顯示,對于GSM8K,僅方程式提示的幫助不大,這意味著GSM8K中問題的語義太具挑戰性,無法在沒有思維鏈自然語言推理步驟的情況下直接轉換成方程式。然而,對于只需要一步或兩步的問題數據集,我們發現僅方程式提示確實提高了性能,因為方程式可以從問題中輕易地得出。
Variable compute only
另一個直觀的想法是,思維鏈允許模型在更難的問題上花費更多的計算量(即中間token)。為了將可變計算量的效果與思維鏈推理分離,我們測試了一種配置,其中模型被提示僅輸出一系列等于解決問題所需方程中字符數量的點(. . .)。這個變體的性能與基線大致相同,這表明可變計算量本身并非思維鏈提示成功的原因,而且通過自然語言表達中間步驟似乎具有實用價值。
Chain of thought after answer
另一個可能的思維鏈提示優勢可能僅僅是這樣的提示允許模型更好地訪問在預訓練期間獲得的相關知識。因此,我們測試了一個替代配置,其中在給出答案之后再給出思維鏈提示,以分離模型是否真的依賴生成的思維鏈來給出最終答案。這種變體的性能與基線大致相同,這表明思維鏈中體現的順序推理對于激活知識之外的原因是有用的。
思維鏈的魯棒性
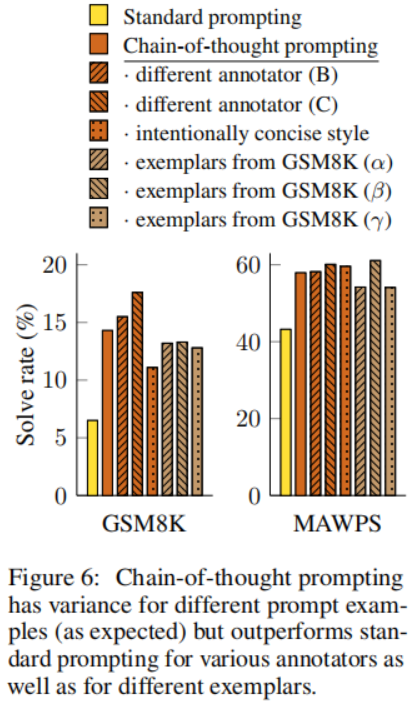
魯棒性研究
對示例的敏感性是提示方法的一個關鍵考慮因素——例如,改變少量示例的排列可能導致 GPT-3 在 SST-2 上的準確率從接近隨機(54.3%)到接近最先進水平(93.4%)。在這最后一個小節中,我們評估了由不同注釋者編寫的思維鏈的魯棒性。除了以上使用 Annotator A 編寫的思維鏈的結果外,本文的另外兩位合作者(Annotator B 和 Annotator C)還獨立為相同的少量示例編寫了思維鏈。Annotator A 還編寫了另一個比原文更簡潔的思維鏈。
上圖顯示了 LaMDA 137B 在 GSM8K 和 MAWPS 上的這些結果。盡管不同思維鏈注釋之間存在差異,如同使用基于示例的提示時所預期的那樣,但所有的思維鏈提示都大幅度優于標準基線。這一結果表明,成功使用思維鏈并不依賴于特定的語言風格。
為了證實成功的思維鏈提示適用于其他示例集,我們還使用從 GSM8K 訓練集中隨機抽取的三組八個示例進行實驗,這是一個獨立的來源(這個數據集中的示例已經包括了類似思維鏈的推理步驟)。上圖顯示,這些提示的表現與我們手動編寫的示例相當,也大大優于標準提示。
除了對注釋者、獨立編寫的思維鏈、不同示例和各種語言模型的魯棒性外,我們還發現,對于算術推理的思維鏈提示在不同的示例順序和不同數量的示例方面也具有魯棒性。
四、常識推理與符號推理
除了算術推理任務外,本文還測試了思維鏈提示在常識推理與符號推理任務上的性能。對于常識推理任務,我們選擇了五個涵蓋各種常識推理類型的數據集。「CSQA」提出了關于世界的常識問題,涉及復雜的語義,通常需要先驗知識。「StrategyQA」要求模型推斷出一個多跳策略來回答問題。我們從 BIG-bench 項目中選擇了兩個專門的評估集:「Date Understanding」,涉及從給定的上下文中推斷日期;「Sports Understanding」,涉及判斷與體育相關的句子是合理的還是不合理的。最后,「SayCan」數據集涉及將自然語言指令映射到離散集合中的一系列機器人動作。實驗結果如下:
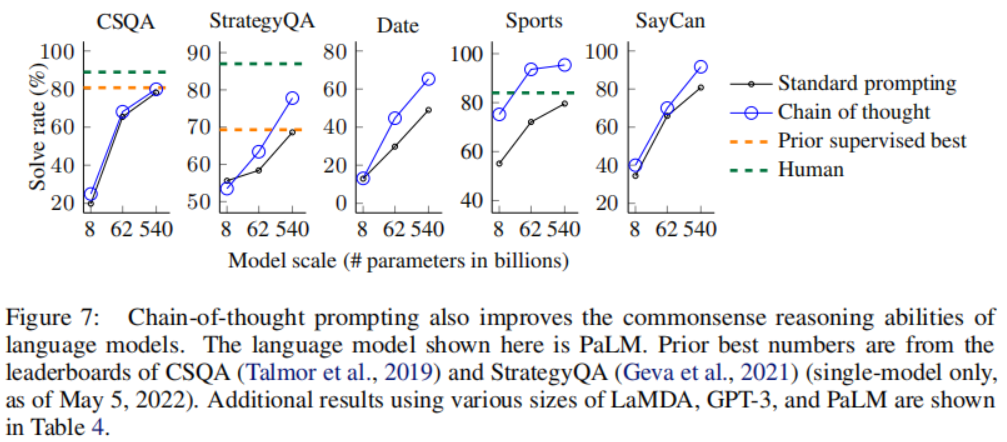
常識推理
符號推理使用以下兩個toy任務:
①最后字母拼接。這個任務要求模型將名稱中單詞的最后字母拼接起來(例如,“Amy Brown” → “yn”)。這是一個比首字母拼接更具挑戰性的版本,語言模型已經可以在沒有思維鏈的情況下執行第一個字母拼接。我們通過從名字人口普查數據([https://namecensus.com/)中隨機連接前一千個名字和姓氏來生成全名。 ②拋硬幣。這個任務要求模型回答在人們翻轉或不翻轉硬幣后,硬幣是否仍然是正面朝上的(例如,“一枚硬幣是正面朝上的。菲比翻轉了硬幣。奧斯瓦爾多沒有翻轉硬幣。硬幣還是正面朝上嗎?”→“不是”)。
由于這些符號推理任務的構造是明確的,對于每個任務,我們考慮一個在域內測試集,其中的示例與訓練/少量示例的步驟相同,以及一個域外(out-of-domain,OOD)測試集,其中評估示例比示例中的步驟多。對于最后字母拼接,模型只能看到兩個單詞的名稱示例,然后在具有3和4個單詞的名稱上執行最后字母拼接。我們對拋硬幣任務中可能的翻轉次數也做同樣的處理。我們的實驗設置使用與前兩節相同的方法和模型。我們再次手動為每個任務的少量示例組合思維鏈。實驗結果如下:
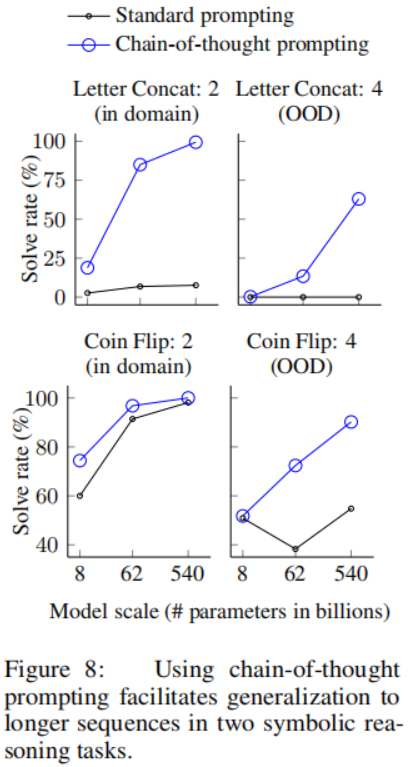
符號推理
五、討論
我們已經探討了思維鏈提示作為一種簡單機制來引導大型語言模型進行多步推理行為。首先,我們發現思維鏈提示在算術推理方面大大提高了性能,帶來的改進遠比消融實驗更強大,而且對不同的注釋者、示例和語言模型具有魯棒性。接下來,常識推理實驗強調了思維鏈推理的語言特性使其具有普遍適用性。最后,我們展示了對于符號推理,思維鏈提示有助于在更長的序列長度上進行OOD泛化。在所有實驗中,思維鏈推理只是通過提示現成的語言模型來引導,沒有對語言模型進行微調。
思維鏈推理屬于模型規模的涌現能力,這種能力已經成為研究中的一種普遍主題。對于許多推理任務,標準提示具有平坦的縮放曲線,思維鏈提示導致了陡峭的增長曲線。鏈式思維提示似乎擴大了大型語言模型可以成功執行的任務集——換句話說,我們的工作強調,標準提示只提供了大型語言模型能力的下限。這一觀察可能引發的問題比答案多——例如,隨著模型規模的進一步增加,我們能期望推理能力提高多少?還有哪些提示方法可能擴大語言模型可以解決的任務范圍?
至于局限性,我們首先說明,盡管思維鏈模擬了人類推理者的思維過程,但這并不能回答神經網絡是否真正進行了“推理”,我們將這個問題留給未來研究。其次,雖然在少量示例設置中,用思維鏈手動增強示例的成本很低,但這種注釋成本對于微調來說可能是高昂的(盡管這可以通過合成數據生成或零樣本泛化來克服)。第三,不能保證正確的推理路徑,這可能導致正確和錯誤的答案;改進語言模型的事實生成是未來工作的一個開放方向。最后,思維鏈推理僅在大型模型規模上的出現使其在實際應用中的服務成本變得昂貴;進一步的研究可以探討如何在較小的模型中引入推理。
總之,思維鏈提示為解決多步推理任務提供了一種有效且簡單的方法,僅通過提示現成的語言模型就能實現。然而,這并不意味著思維鏈提示完美無缺,仍然存在一些局限性和未來需要解決的問題。例如,為了進一步提高推理能力,研究人員可能需要探討其他提示方法或改進現有的提示方法。此外,未來的研究可以關注如何在保持計算成本較低的情況下,引入推理能力。
通過本文的研究,我們可以更好地理解大型語言模型在推理任務上的性能,并為未來的研究和應用奠定基礎。鏈式思維提示是一種重要的工具,可以幫助我們更好地利用現有的大型語言模型,在各種任務和場景中取得更好的結果。
審核編輯:劉清
-
機器學習
+關注
關注
66文章
8406瀏覽量
132567 -
MDA
+關注
關注
0文章
13瀏覽量
12221 -
GPT
+關注
關注
0文章
352瀏覽量
15343 -
nlp
+關注
關注
1文章
488瀏覽量
22033
原文標題:思維鏈Prompting促進大型語言模型的推理能力
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

基于CPU的大型語言模型推理實驗

【大規模語言模型:從理論到實踐】- 閱讀體驗
大語言模型:原理與工程時間+小白初識大語言模型
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】揭開大語言模型的面紗

一文速覽大語言模型提示最新進展






 工商網監
工商網監
評論