 深度剖析SQL中的Grouping Sets語句1
深度剖析SQL中的Grouping Sets語句1
前言
SQL 中 Group By 語句大家都很熟悉, 根據指定的規則對數據進行分組 ,常常和聚合函數一起使用。
比如,考慮有表 dealer,表中數據如下:
| id (Int) | city (String) | car_model (String) | quantity (Int) |
|---|---|---|---|
| 100 | Fremont | Honda Civic | 10 |
| 100 | Fremont | Honda Accord | 15 |
| 100 | Fremont | Honda CRV | 7 |
| 200 | Dublin | Honda Civic | 20 |
| 200 | Dublin | Honda Accord | 10 |
| 200 | Dublin | Honda CRV | 3 |
| 300 | San Jose | Honda Civic | 5 |
| 300 | San Jose | Honda Accord | 8 |
如果執行 SQL 語句 SELECT id, sum(quantity) FROM dealer GROUP BY id ORDER BY id,會得到如下結果:
+---+-------------+
| id|sum(quantity)|
+---+-------------+
|100| 32|
|200| 33|
|300| 13|
+---+-------------+
上述 SQL 語句的意思就是對數據按 id 列進行分組,然后在每個分組內對 quantity 列進行求和。
Group By 語句除了上面的簡單用法之外,還有更高級的用法,常見的是 Grouping Sets、RollUp 和 Cube,它們在 OLAP 時比較常用。其中,RollUp 和 Cube 都是以 Grouping Sets 為基礎實現的,因此,弄懂了 Grouping Sets,也就理解了 RollUp 和 Cube 。
本文首先簡單介紹 Grouping Sets 的用法,然后以 Spark SQL 作為切入點,深入解析 Grouping Sets 的實現機制。
Spark SQL 是 Apache Spark 大數據處理框架的一個子模塊,用來處理結構化信息。它可以將 SQL 語句翻譯多個任務在 Spark 集群上執行, 允許用戶直接通過 SQL 來處理數據 ,大大提升了易用性。
Grouping Sets 簡介
Spark SQL 官方文檔中 SQL Syntax 一節對 Grouping Sets 語句的描述如下:
Groups the rows for each grouping set specified after GROUPING SETS. (... 一些舉例) This clause is a shorthand for a
UNION ALLwhere each leg of theUNION ALLoperator performs aggregation of each grouping set specified in theGROUPING SETSclause. (... 一些舉例)
也即,Grouping Sets 語句的作用是指定幾個 grouping set 作為 Group By 的分組規則,然后再將結果聯合在一起。它的效果和, 先分別對這些 grouping set 進行 Group By 分組之后,再通過 Union All 將結果聯合起來 ,是一樣的。
比如,對于 dealer 表,Group By Grouping Sets ((city, car_model), (city), (car_model), ()) 和 Union All((Group By city, car_model), (Group By city), (Group By car_model), 全局聚合) 的效果是相同的:
先看 Grouping Sets 版的執行結果:
spark-sql> SELECT city, car_model, sum(quantity) AS sum FROM dealer
> GROUP BY GROUPING SETS ((city, car_model), (city), (car_model), ())
> ORDER BY city, car_model;
+--------+------------+---+
| city| car_model|sum|
+--------+------------+---+
| null| null| 78|
| null|Honda Accord| 33|
| null| Honda CRV| 10|
| null| Honda Civic| 35|
| Dublin| null| 33|
| Dublin|Honda Accord| 10|
| Dublin| Honda CRV| 3|
| Dublin| Honda Civic| 20|
| Fremont| null| 32|
| Fremont|Honda Accord| 15|
| Fremont| Honda CRV| 7|
| Fremont| Honda Civic| 10|
|San Jose| null| 13|
|San Jose|Honda Accord| 8|
|San Jose| Honda Civic| 5|
+--------+------------+---+
再看 Union All 版的執行結果:
spark-sql> (SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY city, car_model) UNION ALL
> (SELECT city, NULL as car_model, sum(quantity) AS sum FROM dealer GROUP BY city) UNION ALL
> (SELECT NULL as city, car_model, sum(quantity) AS sum FROM dealer GROUP BY car_model) UNION ALL
> (SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer)
> ORDER BY city, car_model;
+--------+------------+---+
| city| car_model|sum|
+--------+------------+---+
| null| null| 78|
| null|Honda Accord| 33|
| null| Honda CRV| 10|
| null| Honda Civic| 35|
| Dublin| null| 33|
| Dublin|Honda Accord| 10|
| Dublin| Honda CRV| 3|
| Dublin| Honda Civic| 20|
| Fremont| null| 32|
| Fremont|Honda Accord| 15|
| Fremont| Honda CRV| 7|
| Fremont| Honda Civic| 10|
|San Jose| null| 13|
|San Jose|Honda Accord| 8|
|San Jose| Honda Civic| 5|
+--------+------------+---+
兩版的查詢結果完全一樣。
Grouping Sets 的執行計劃
從執行結果上看,Grouping Sets 版本和 Union All 版本的 SQL 是等價的,但 Grouping Sets 版本更加簡潔。
那么,Grouping Sets 僅僅只是 Union All 的一個縮寫,或者語法糖嗎 ?
為了進一步探究 Grouping Sets 的底層實現是否和 Union All 是一致的,我們可以來看下兩者的執行計劃。
首先,我們通過 explain extended 來查看 Union All 版本的 Optimized Logical Plan :
spark-sql> explain extended (SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY city, car_model) UNION ALL (SELECT city, NULL as car_model, sum(quantity) AS sum FROM dealer GROUP BY city) UNION ALL (SELECT NULL as city, car_model, sum(quantity) AS sum FROM dealer GROUP BY car_model) UNION ALL (SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer) ORDER BY city, car_model;
== Parsed Logical Plan ==
...
== Analyzed Logical Plan ==
...
== Optimized Logical Plan ==
Sort [city#93 ASC NULLS FIRST, car_model#94 ASC NULLS FIRST], true
+- Union false, false
:- Aggregate [city#93, car_model#94], [city#93, car_model#94, sum(quantity#95) AS sum#79L]
: +- Project [city#93, car_model#94, quantity#95]
: +- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#92, city#93, car_model#94, quantity#95], Partition Cols: []]
:- Aggregate [city#97], [city#97, null AS car_model#112, sum(quantity#99) AS sum#81L]
: +- Project [city#97, quantity#99]
: +- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#96, city#97, car_model#98, quantity#99], Partition Cols: []]
:- Aggregate [car_model#102], [null AS city#113, car_model#102, sum(quantity#103) AS sum#83L]
: +- Project [car_model#102, quantity#103]
: +- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#100, city#101, car_model#102, quantity#103], Partition Cols: []]
+- Aggregate [null AS city#114, null AS car_model#115, sum(quantity#107) AS sum#86L]
+- Project [quantity#107]
+- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#104, city#105, car_model#106, quantity#107], Partition Cols: []]
== Physical Plan ==
...
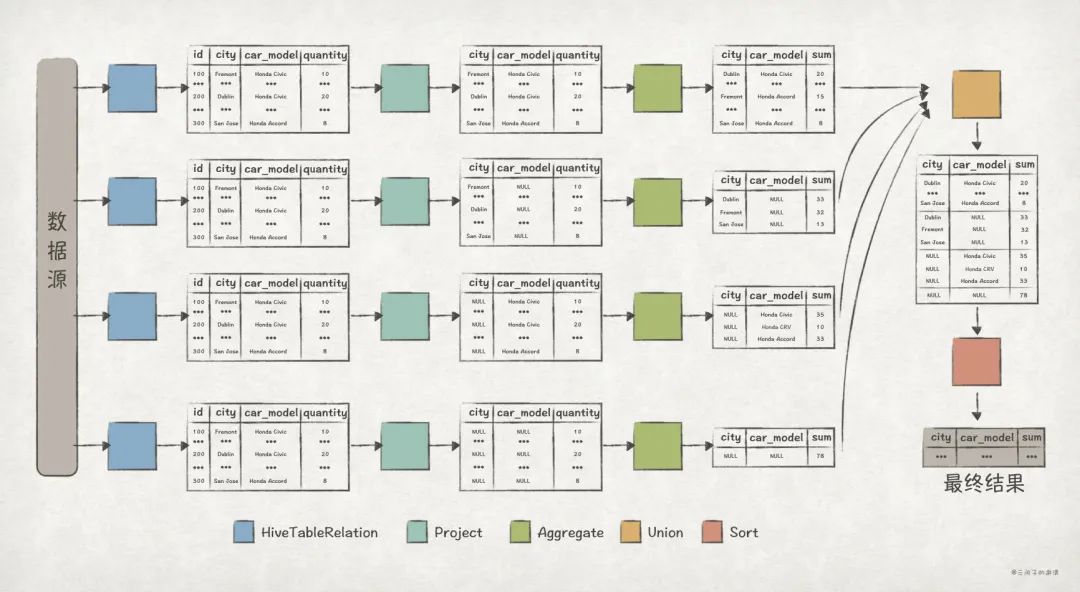
從上述的 Optimized Logical Plan 可以清晰地看出 Union All 版本的執行邏輯:
- 執行每個子查詢語句,計算得出查詢結果。其中,每個查詢語句的邏輯是這樣的:
- 在 HiveTableRelation 節點對
dealer表進行全表掃描。 - 在 Project 節點選出與查詢語句結果相關的列,比如對于子查詢語句
SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer,只需保留quantity列即可。 - 在 Aggregate 節點完成
quantity列對聚合運算。在上述的 Plan 中,Aggregate 后面緊跟的就是用來分組的列,比如Aggregate [city#902]就表示根據city列來進行分組。
- 在 HiveTableRelation 節點對
- 在 Union 節點完成對每個子查詢結果的聯合。
- 最后,在 Sort 節點完成對數據的排序,上述 Plan 中
Sort [city#93 ASC NULLS FIRST, car_model#94 ASC NULLS FIRST]就表示根據city和car_model列進行升序排序。
接下來,我們通過 explain extended 來查看 Grouping Sets 版本的 Optimized Logical Plan:
spark-sql> explain extended SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY GROUPING SETS ((city, car_model), (city), (car_model), ()) ORDER BY city, car_model;
== Parsed Logical Plan ==
...
== Analyzed Logical Plan ==
...
== Optimized Logical Plan ==
Sort [city#138 ASC NULLS FIRST, car_model#139 ASC NULLS FIRST], true
+- Aggregate [city#138, car_model#139, spark_grouping_id#137L], [city#138, car_model#139, sum(quantity#133) AS sum#124L]
+- Expand [[quantity#133, city#131, car_model#132, 0], [quantity#133, city#131, null, 1], [quantity#133, null, car_model#132, 2], [quantity#133, null, null, 3]], [quantity#133, city#138, car_model#139, spark_grouping_id#137L]
+- Project [quantity#133, city#131, car_model#132]
+- HiveTableRelation [`default`.`dealer`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [id#130, city#131, car_model#132, quantity#133], Partition Cols: []]
== Physical Plan ==
...
從 Optimized Logical Plan 來看,Grouping Sets 版本要簡潔很多!具體的執行邏輯是這樣的:
- 在 HiveTableRelation 節點對
dealer表進行全表掃描。 - 在 Project 節點選出與查詢語句結果相關的列。
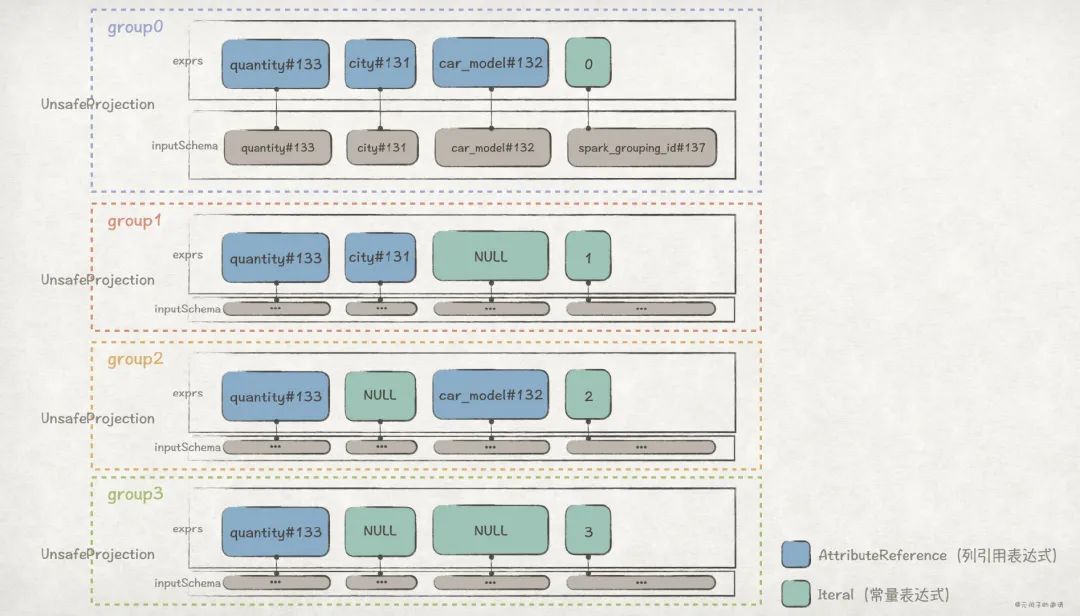
- 接下來的 Expand 節點是關鍵,數據經過該節點后,多出了
spark_grouping_id列。從 Plan 中可以看出來,Expand 節點包含了Grouping Sets里的各個 grouping set 信息,比如[quantity#133, city#131, null, 1]對應的就是(city)這一 grouping set。而且,每個 grouping set 對應的spark_grouping_id列的值都是固定的,比如(city)對應的spark_grouping_id為1。 - 在 Aggregate 節點完成
quantity列對聚合運算,其中分組的規則為city, car_model, spark_grouping_id。注意,數據經過 Aggregate 節點后,spark_grouping_id列被刪除了! - 最后,在 Sort 節點完成對數據的排序。

從 Optimized Logical Plan 來看,雖然 Union All 版本和 Grouping Sets 版本的效果一致,但它們的底層實現有著巨大的差別。
其中,Grouping Sets 版本的 Plan 中最關鍵的是 Expand 節點,目前,我們只知道數據經過它之后,多出了 spark_grouping_id 列。而且從最終結果來看,spark_grouping_id只是 Spark SQL 的內部實現細節,對用戶并不體現。那么:
- Expand 的實現邏輯是怎樣的,為什么能達到
Union All的效果? - Expand 節點的輸出數據是怎樣的 ?
spark_grouping_id列的作用是什么 ?
通過 Physical Plan,我們發現 Expand 節點對應的算子名稱也是 Expand:
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Sort [city#138 ASC NULLS FIRST, car_model#139 ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(city#138 ASC NULLS FIRST, car_model#139 ASC NULLS FIRST, 200), ENSURE_REQUIREMENTS, [plan_id=422]
+- HashAggregate(keys=[city#138, car_model#139, spark_grouping_id#137L], functions=[sum(quantity#133)], output=[city#138, car_model#139, sum#124L])
+- Exchange hashpartitioning(city#138, car_model#139, spark_grouping_id#137L, 200), ENSURE_REQUIREMENTS, [plan_id=419]
+- HashAggregate(keys=[city#138, car_model#139, spark_grouping_id#137L], functions=[partial_sum(quantity#133)], output=[city#138, car_model#139, spark_grouping_id#137L, sum#141L])
+- Expand [[quantity#133, city#131, car_model#132, 0], [quantity#133, city#131, null, 1], [quantity#133, null, car_model#132, 2], [quantity#133, null, null, 3]], [quantity#133, city#138, car_model#139, spark_grouping_id#137L]
+- Scan hive default.dealer [quantity#133, city#131, car_model#132], HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#130, city#131, car_model#132, quantity#133], Partition Cols: []]
帶著前面的幾個問題,接下來我們深入 Spark SQL 的 Expand 算子源碼尋找答案。
-
數據
+關注
關注
8文章
7067瀏覽量
89110 -
SQL
+關注
關注
1文章
766瀏覽量
44161 -
函數
+關注
關注
3文章
4333瀏覽量
62691
發布評論請先 登錄
相關推薦
sql語句實例講解

如何使用navicat或PHPMySQLAdmin導入SQL語句
VS中SQL命令語句的詳細資料免費下載

Group By高級用法Groupings Sets語句的功能和底層實現
深度剖析SQL中的Grouping Sets語句2





 工商網監
工商網監
評論