 技術速遞 | 論文分享《Holistic Evaluation of Language Models》
技術速遞 | 論文分享《Holistic Evaluation of Language Models》
1. 在所有被評估的模型中,InstructGPT davinci v2(175B)在準確率,魯棒性,公平性三方面上表現最好。論文主要聚焦的是國外大公司的語言大模型,而國內的知名大模型,如華為的Pangu系列以及百度的文心系列,論文并沒有給出相關的測評數據。下圖展示了各模型間在各種NLP任務中頭對頭勝率(Head-to-head win rate)的情況。可以看到,出自OpenAI的InstructGPT davinci v2在絕大多數任務中都可以擊敗其他模型。最近的大火的ChatGPT誕生于這篇論文之后,因此這篇論文沒有對ChatGPT的測評,但ChatGPT是InstructGPT的升級版,相信ChatGPT可以取得同樣優異的成績。在下圖中,準確率的綜合第二名由微軟的TNLG獲得,第三名由初創公司Anthropic獲得。同時我們也可以看到,要想在準確率額上獲得55%及以上的勝率,需要至少50B的大小,可見大模型是趨勢所向。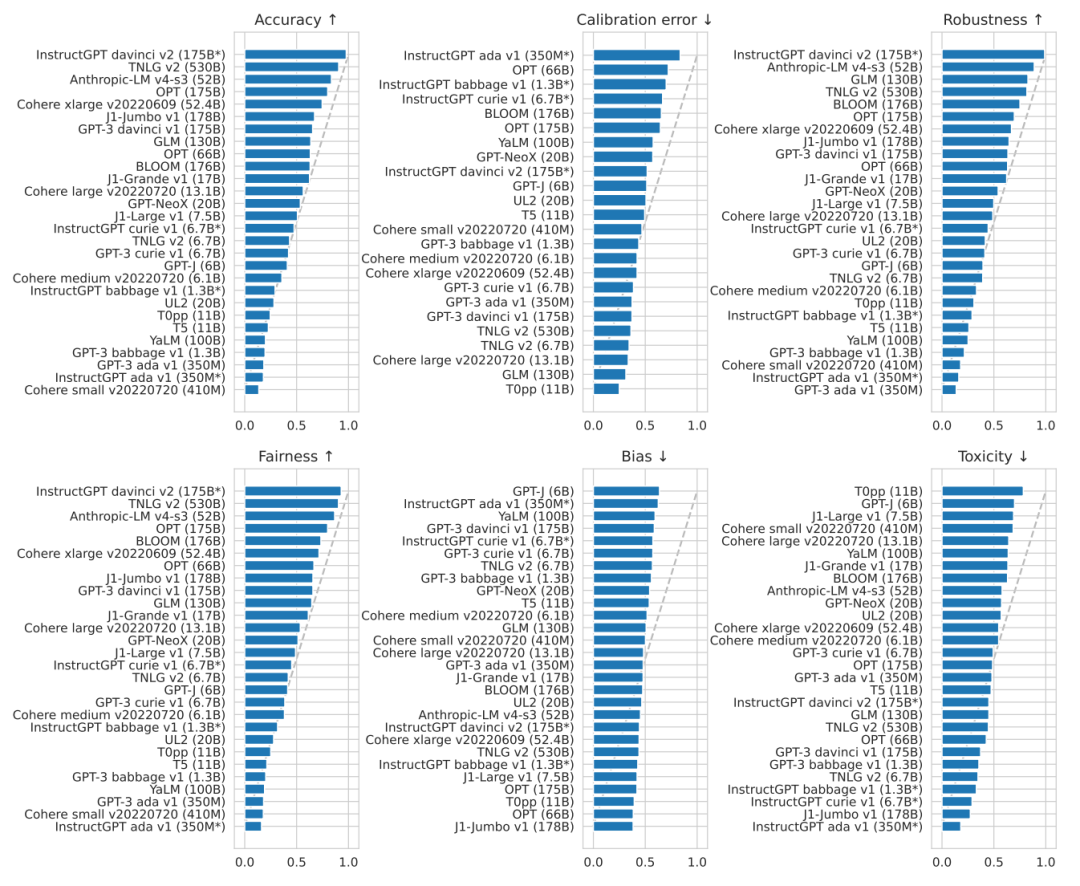
2. 由于硬件、架構、部署模式的區別,不同模型的準確率和效率之間沒有強相關性。而準確率與魯棒性(Robustness)、公平性(Fairness)之間有一定的正相關關系(如下圖所示)。
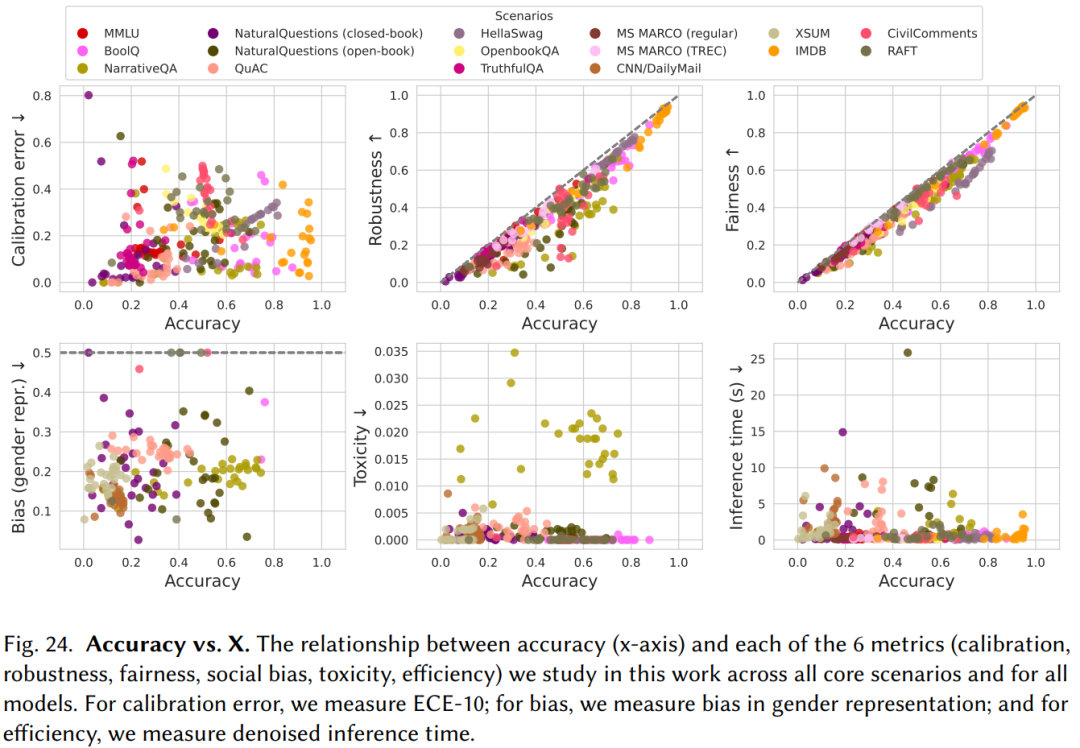
如今,大模型的參數規模都非常巨大。GPT-3具有1750億個參數,部署這樣一個大模型,無論在成本上還是工程上都是極大的挑戰。同時,由于需要開放API給用戶使用,OpenAI還需要考慮GPT-3的推理速度。文章的測試結果顯示,GPT-3的推理速度并沒有顯著地比參數更少地模型慢,可能是在硬件、架構和部署模式上都有一定地優勢,足以彌補參數規模上的劣勢。
3. InstructGPT davinci v2(175B)在知識密集型的任務上取得了遠超其他模型的成績,在TruthfulQA數據集上獲得了62.0%的準確率,遠超第二名Anthropic-LM v4-s3 (52B) 36.2%的成績。(TruthfulQA是衡量語言模型在生成問題答案時是否真實的測評數據集。該數據集包括817個問題,涵蓋38個類別,包括健康,法律,金融和政治。作者精心設計了一些人會因為錯誤的先驗知識或誤解而錯誤回答的問題。)與此同時,TNLG v2(530B)在部分知識密集型任務上也有優異的表現。作者認為模型的規模對學習真實的知識起到很大的貢獻,這一點可以從兩個大模型的優異表現中推測得到。
4. 在推理(Reasoning)任務上,Codex davinci v2在代碼生成和文本推理任務上表現都很優異,甚至遠超一些以文本為訓練語料的模型。這一點在數學推理的數據上表現最明顯。在GSM8K數據集上,Codex davinci v2獲得了52.1%的正確率,第二名為InstructGPT davinci v2(175B)的35.0%,且沒有其他模型正確率超過16%。Codex davinci v2主要是用于解決代碼相關的問題,例如代碼生成、代碼總結、注釋生成、代碼修復等,它在文本推理任務上的優秀表現可能是其在代碼數據上訓練的結果,因為代碼是更具有邏輯關系的語言,在這樣的數據集上訓練也許可以提升模型的推理能力。
5. 所有的大模型都對輸入(Prompt)的形式非常敏感。論文主要采用few-shot這種In-context learning的形式增強輸入(Prompt)。
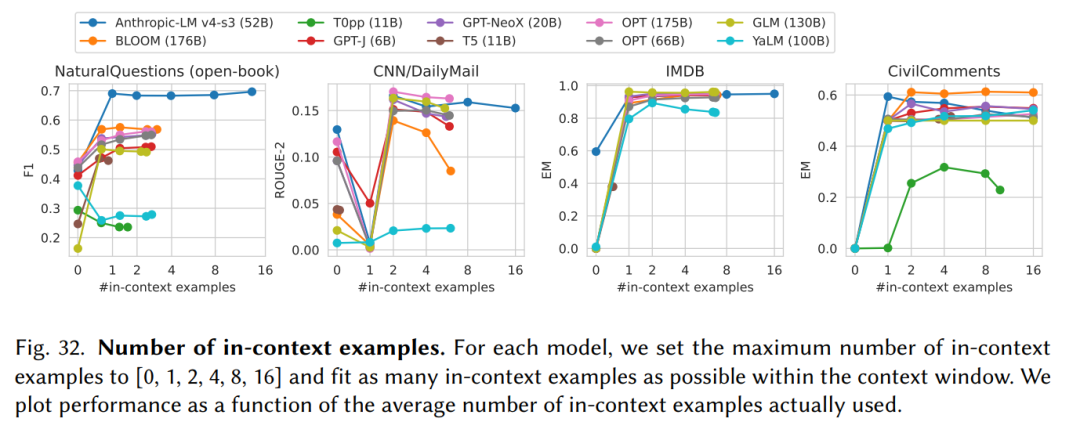
如上圖所示,在不同任務上,in-context examples的數量影響不同,在不同的模型上也是如此。由于有些任務比較簡單,例如二分類的IMDB數據庫,增加in-context examples并不會對結果有明顯的影響。在模型方面,由于window size的限制,過多的in-context examples可能導致剩余的window size不足以生成一個完成答案,因而對生成結果造成負面的影響。
點擊“閱讀原文”,了解更多!
-
華為
+關注
關注
216文章
34471瀏覽量
251990
原文標題:技術速遞 | 論文分享《Holistic Evaluation of Language Models》
文章出處:【微信號:華為DevCloud,微信公眾號:華為DevCloud】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大語言模型開發語言是什么
TMAG6180EVM,TMAG6181EVM Evaluation Module用戶指南

LMK5C33414A Evaluation Module用戶指南
30s高能速遞 | 第三屆 OpenHarmony技術大會精彩搶鮮看

微軟GitHub推出Models服務,賦能AI工程師
GitHub推出GitHub Models服務,賦能開發者智能選擇AI模型
大模型LLM與ChatGPT的技術原理
如何使用Wavetool Evaluation Software軟件在ADPD4100評估板上設置進行多波長監測?
【大語言模型:原理與工程實踐】核心技術綜述
如何在PSoC62 Evaluation kit開發板上運行RT-Thread呢?






 工商網監
工商網監
評論