


文章作者:周兆靖
DL Workbench 深度學(xué)習(xí)工作臺(tái)
是 OpenVINO軟件棧中非常重量級(jí)的一個(gè)工具
涉及到的內(nèi)容和操作比較多
決定還是另起一篇來(lái)介紹!
1.概述介紹
如果您對(duì)深度學(xué)習(xí)感興趣,DL Workbench 提供了更為直觀的學(xué)習(xí)平臺(tái):帶您了解什么是神經(jīng)網(wǎng)絡(luò),神經(jīng)網(wǎng)絡(luò)是如何工作的,以及如何檢查它們的架構(gòu)。您可以在開(kāi)發(fā)產(chǎn)品之前,學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)的分析和優(yōu)化網(wǎng)絡(luò)的基礎(chǔ)知識(shí),以及熟悉 OpenVINO生態(tài)系統(tǒng)及其主要組件。如果您是資深的 AI 工程師,DL Workbench 將為您提供一個(gè)方便的 web 界面,以實(shí)時(shí)優(yōu)化您的模型并可以為您的產(chǎn)品落地進(jìn)行加速。
DL Workbench 可以很方便地測(cè)量和分析模型性能,同時(shí)在實(shí)驗(yàn)中調(diào)整模型以提高性能,最終分析模型的拓?fù)浣Y(jié)構(gòu)并產(chǎn)生可視化輸出。DL Workbench 的工作流程如下圖所示:
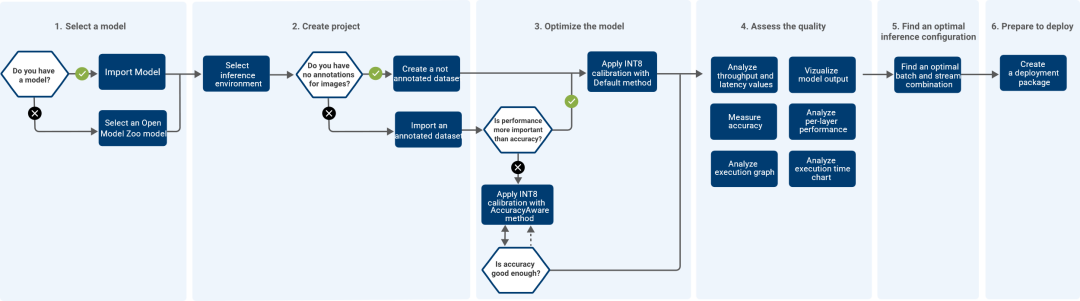
圖1-1 DL Workbench 的工作流程
英特爾提供了兩種運(yùn)行 DL workbench(DLWB)環(huán)境。基于本地硬件的 DLWB 環(huán)境,訪問(wèn)的算力僅限本地現(xiàn)有的算力資源;基于 IntelDeveloper Cloud 的 DLWB 提供了豐富的算力選項(xiàng)用于模型的橫向?qū)Ρ群头治觯瑫r(shí)提供了類似本地化的用戶操作體驗(yàn)。
IntelDeveloper Cloud 平臺(tái)上運(yùn)行 DLWB 方法:
Run DL Workbench in Intel DevCloud
https://docs.openvino.ai/latest/workbench_docs_Workbench_DG_Start_DL_Workbench_in_DevCloud.html
(復(fù)制鏈接到瀏覽器打開(kāi))
本地硬件運(yùn)行 DLWB 的方法:
Run DL Workbench on Local System
https://docs.openvino.ai/latest/workbench_docs_Workbench_DG_Run_Locally.html
(復(fù)制鏈接到瀏覽器打開(kāi))
接下來(lái)我們?cè)?Intel Developer Cloud 平臺(tái)來(lái)運(yùn)行 DLWB,無(wú)需安裝,直接運(yùn)行。
2. 啟動(dòng)DL Workbench
在 Intel Developer Cloud 平臺(tái)上啟動(dòng) DL Workbench 的步驟如下:
1打開(kāi) Work with Intel Distribution of OpenVINO Toolkit 頁(yè)面:
https://www.intel.com/content/www/us/en/developer/tools/devcloud/edge/overview.html
(復(fù)制鏈接到瀏覽器打開(kāi))
劃到頁(yè)面下半部分,點(diǎn)擊 Deep Learning Workbench:
https://www.intel.com/content/www/us/en/developer/tools/devcloud/edge/build/overview.html
(復(fù)制鏈接到瀏覽器打開(kāi))
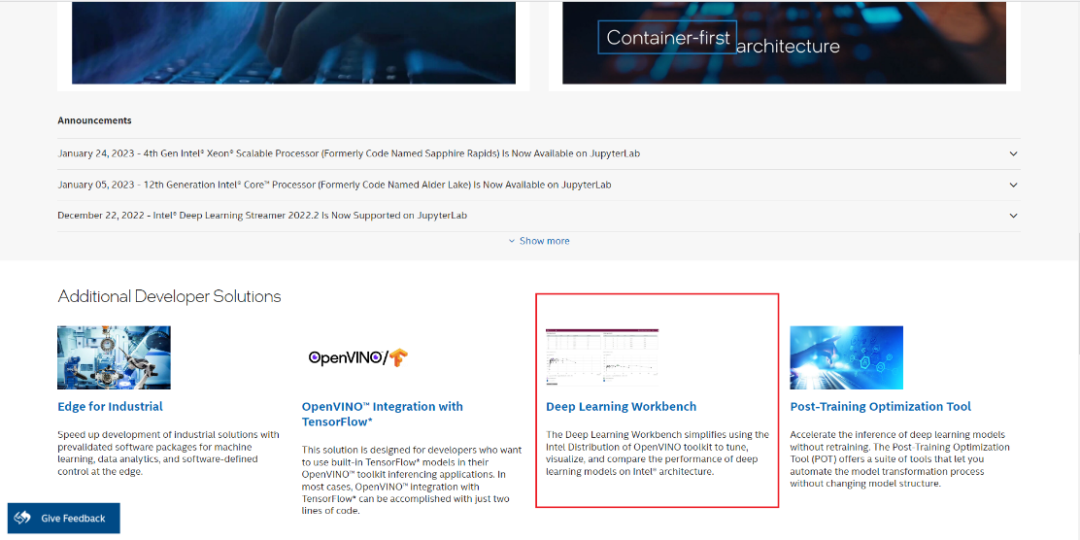
圖2-1 DL Workbench啟動(dòng)一
2運(yùn)行第一個(gè) Cell 里的代碼,之后會(huì)出現(xiàn)“Start Application”,點(diǎn)擊“Start Application”并等待初始化完成,進(jìn)入點(diǎn)擊“Launch DL Workbench”啟動(dòng) DL Workbench( 以下簡(jiǎn)稱 DLWB):
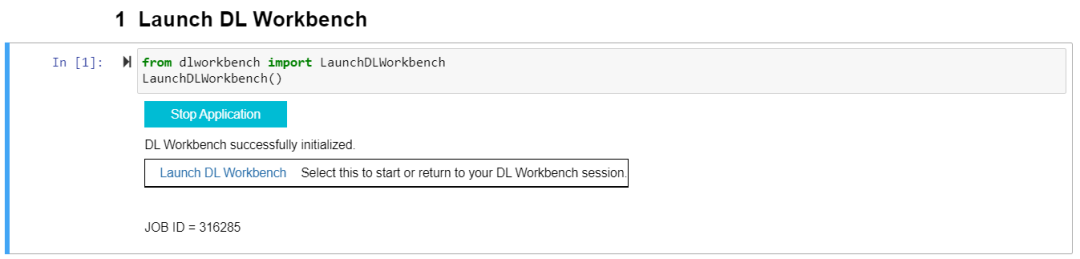
圖2-2 DL Workbench 啟動(dòng)二
3. 使用DL Workbench評(píng)估模型性能
DLWB 的主界面如下圖所示,點(diǎn)擊 “Create Project” 進(jìn)行模型評(píng)估:
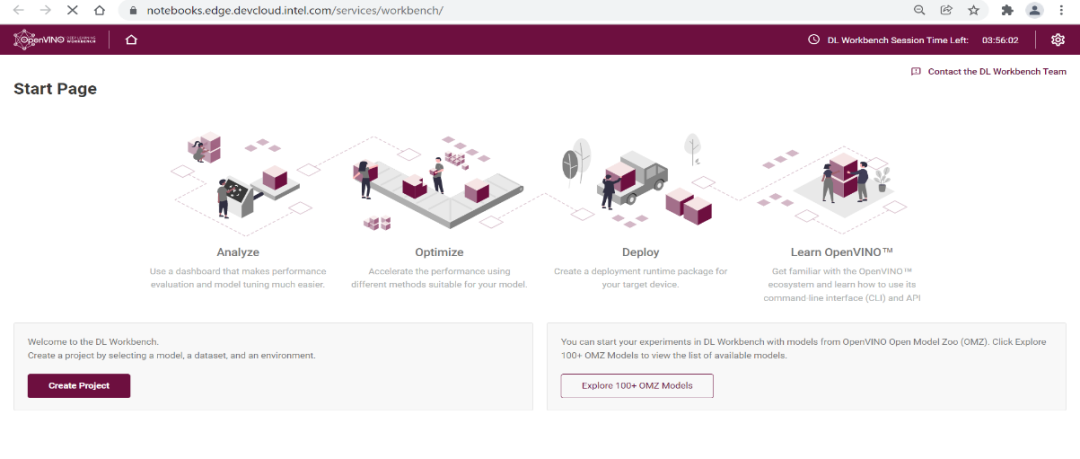
圖3-1 創(chuàng)建 Project
步驟一
模型選擇
首先點(diǎn)擊“import model”,導(dǎo)入需要評(píng)估的模型。Open Model Zoo 是我們提供的一個(gè)在線模型庫(kù),你可以直接從庫(kù)中下載需評(píng)估的模型,當(dāng)然,你也可以上傳你的本地的模型文件,既可以是 IR 格式,也可以是原生的模型格式:
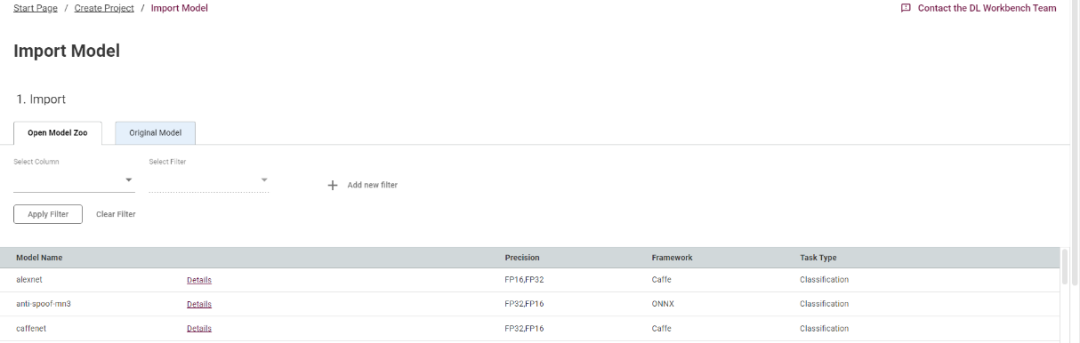
圖3-2 選擇模型
步驟二
設(shè)備選擇
單擊選定模型完成之后,請(qǐng)點(diǎn)擊“Select an Environment”,這里可以選定你部署的設(shè)備節(jié)點(diǎn),Intel DevCloud 平臺(tái)的設(shè)備都可以進(jìn)行實(shí)驗(yàn):
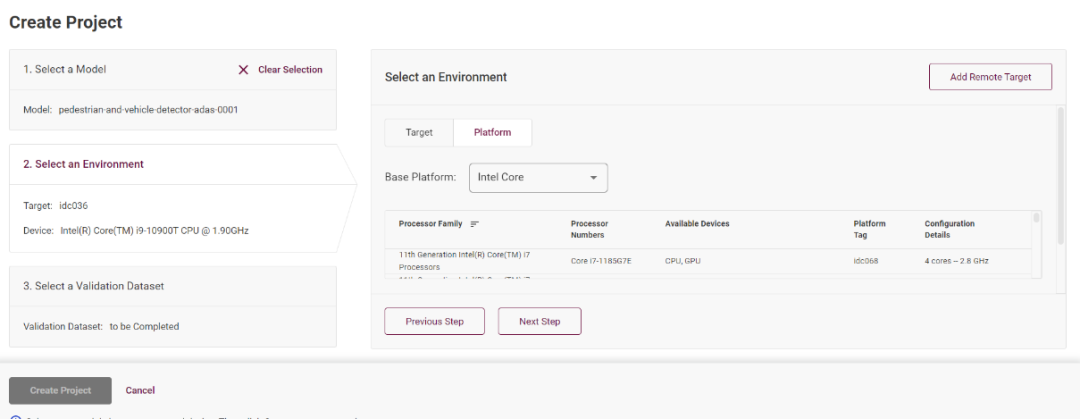
圖3-3 選擇設(shè)備一
你可以在”Device” 下拉菜單里選擇該模型運(yùn)行在 CPU 上還是集成 GPU 上:
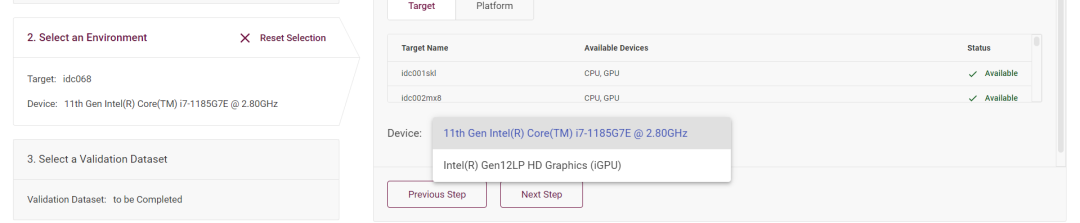
圖3-3 選擇設(shè)備二
步驟三
數(shù)據(jù)集選擇
點(diǎn)擊“Next Step”之后進(jìn)入數(shù)據(jù)集選擇頁(yè)面,點(diǎn)擊“import Dataset”,你可以選擇使用 DLWB 提供的圖像創(chuàng)建一個(gè)數(shù)據(jù)集,或者通過(guò)本地上傳已有的數(shù)據(jù)集,例如 COCO,VOC,ImageNET 等格式的數(shù)據(jù)集:
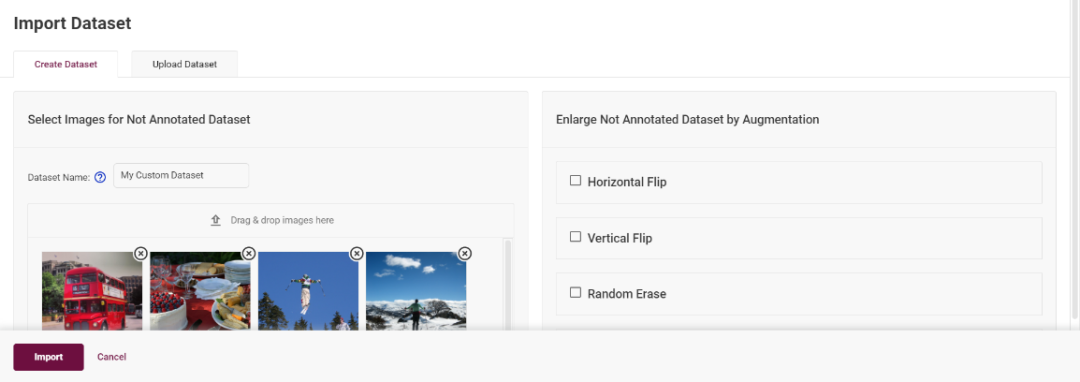
圖3-4 選擇數(shù)據(jù)集
步驟四
推理性能測(cè)試
點(diǎn)擊“Create Project”之后,開(kāi)始運(yùn)行推理,等待推理完成之后,可以直觀的看到模型的 FPS 指標(biāo),以 FPS 值來(lái)判斷這個(gè)模型的性能水平:

圖3-5 推理性能測(cè)試
4. DL Workbench 模型調(diào)試
4.1模型單層運(yùn)行時(shí)間統(tǒng)計(jì)
在模型網(wǎng)絡(luò)分析板塊,DLWB 可以計(jì)算出模型中每一層的消耗時(shí)間,可以以此進(jìn)行網(wǎng)絡(luò)分析,從而決定下一步的優(yōu)化策略。
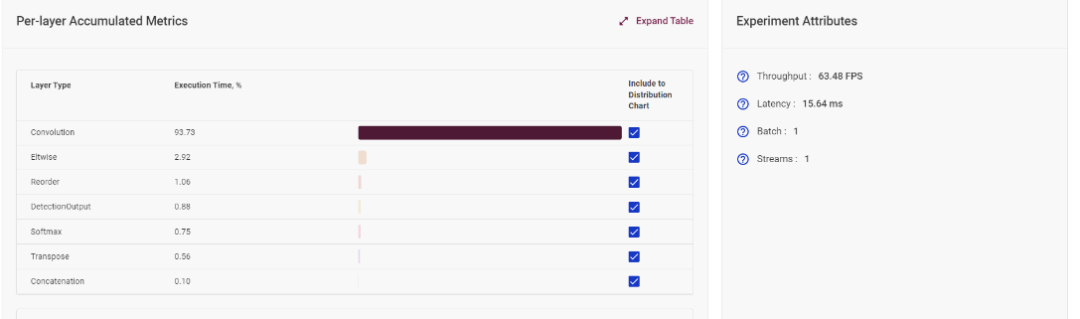
圖4-1 模型單層運(yùn)行時(shí)間統(tǒng)計(jì)
4.2模型層各精度占比統(tǒng)計(jì)
根據(jù)這個(gè)圖表,你可以很直觀的看到該模型層中每種精度的占比情況。若你覺(jué)得你可以降低 FP32 精度層的占比,你可以根據(jù)自己的需求,對(duì)高精度層實(shí)行量化操作,使其精度下降,并確保模型準(zhǔn)確度下降在可接受的范圍內(nèi),這樣可以使得模型推理速度更為快速。
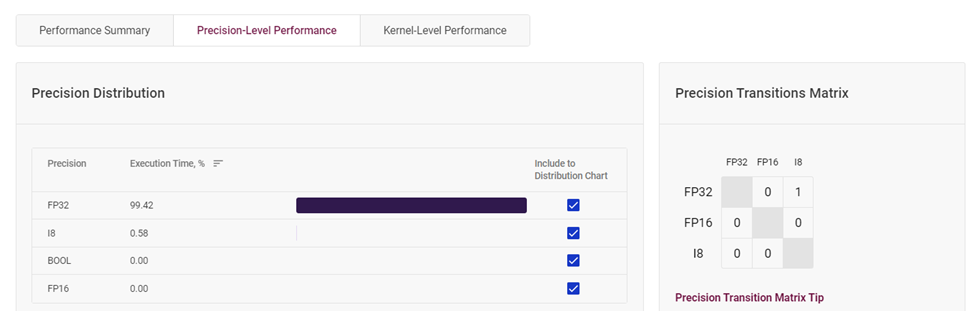
圖4-2 模型層各精度占比統(tǒng)計(jì)
4.3模型網(wǎng)絡(luò)拓?fù)湔故?/strong>
這個(gè)部分通過(guò)直接展示模型的拓?fù)浣Y(jié)構(gòu)圖和模型的層屬性,讓開(kāi)發(fā)者對(duì)此模型能有一個(gè)更清晰與直觀的認(rèn)識(shí)。
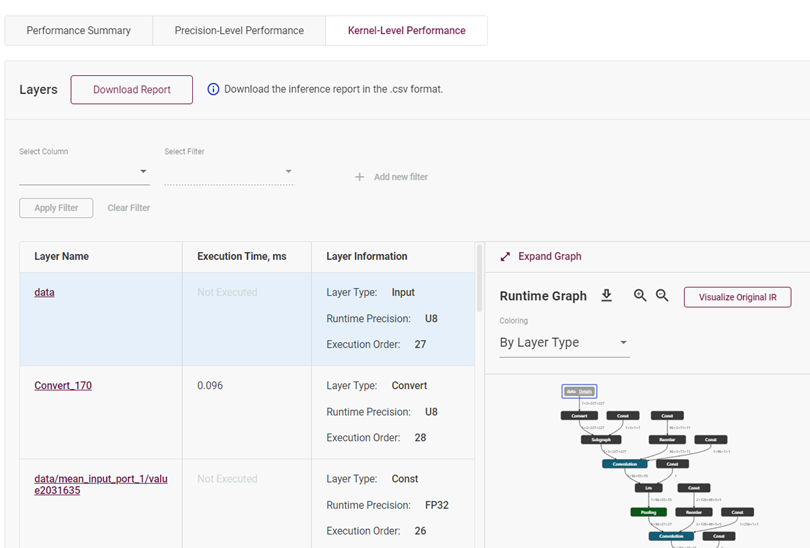
圖4-3 模型網(wǎng)絡(luò)拓?fù)湔故?/p>
4.4模型優(yōu)化建議
下拉頁(yè)面,可以看到 DLWB 會(huì)自動(dòng)針對(duì)你的模型提供性能提升的建議。比如在這個(gè)模型中,它檢測(cè)到該模型有0%的層運(yùn)行在 INT8 整型精度上,所以它建議我們對(duì)模型進(jìn)行 INT8 精度校驗(yàn)。
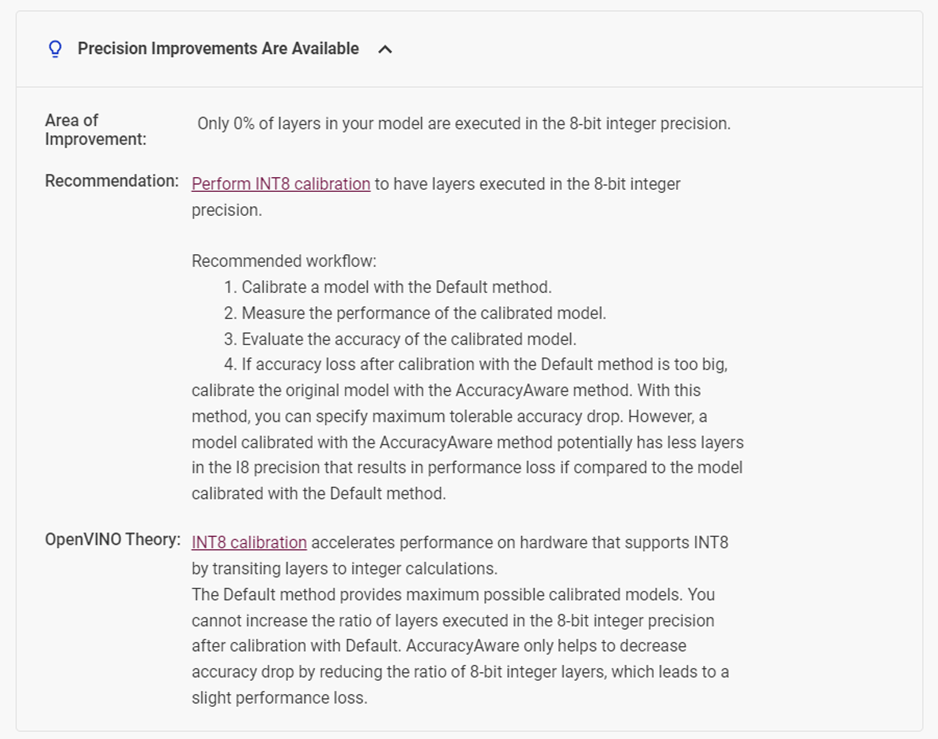
圖4-4 DLWB 對(duì)模型性能提升的優(yōu)化建議
4.5校準(zhǔn)模型成為 INT8 精度模型
在“Perform”選項(xiàng)中,包含了對(duì)于模型優(yōu)化評(píng)估的多種策略。例如,通過(guò)校驗(yàn)?zāi)P蛯訌?FP32 到 INT8 來(lái)優(yōu)化推理性能:優(yōu)化步驟會(huì)將原本 FP32 精度格式的模型層校準(zhǔn)量化成精度為 INT8 的模型層,不用重訓(xùn)練并且可以控制精度下降不超過(guò)1%的范圍。
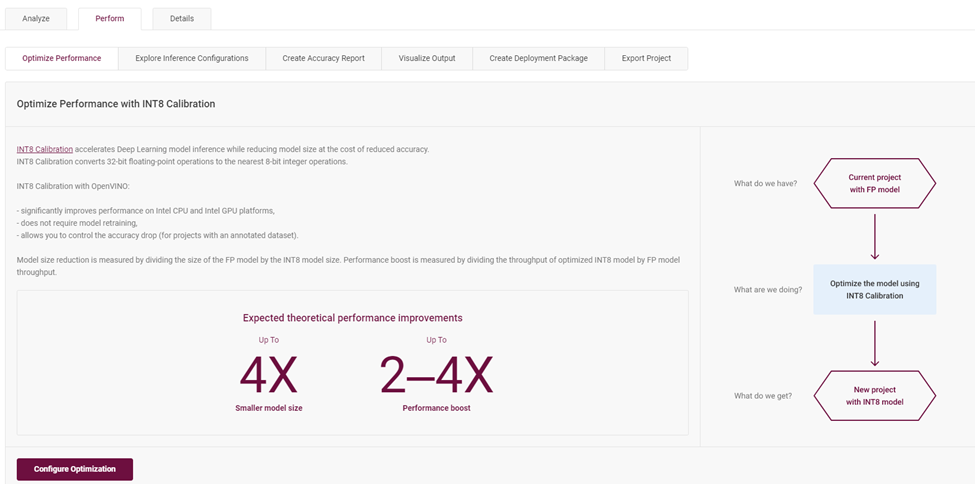
圖4-5 校準(zhǔn)為 INT8 模型層介紹頁(yè)面
選擇默認(rèn)模式,點(diǎn)擊啟動(dòng)優(yōu)化,即可完成低精度優(yōu)化:
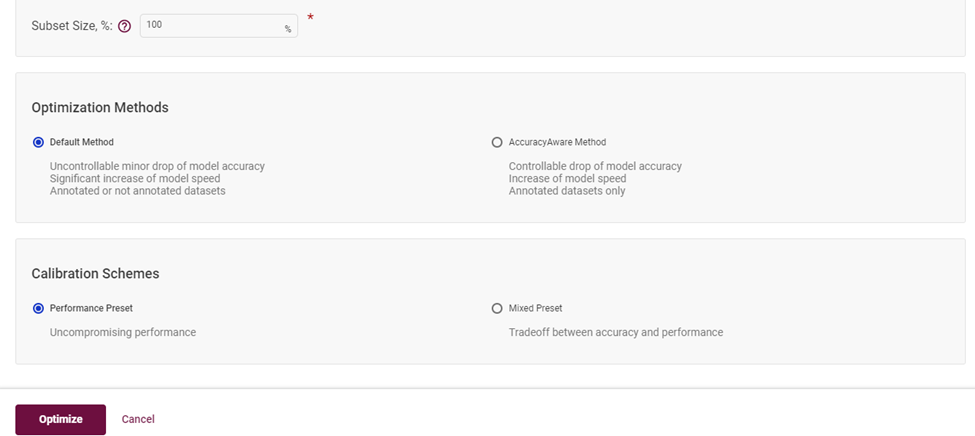
圖4-6 選擇校準(zhǔn)為 INT8 模型層的算法
完成以后,你可以在模型主頁(yè)看到已優(yōu)化的模型和未優(yōu)化的模型,可以看到模型推理吞吐量獲得了巨大的提升:
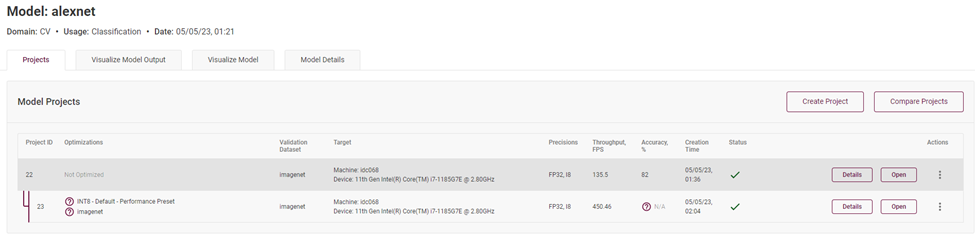
圖4-7 精度為 FP32 精度與 INT8 精度模型的性能對(duì)比
4.6創(chuàng)建模型準(zhǔn)確度報(bào)告
在“Perform”標(biāo)簽下,選擇“Create Accuracy Report”,點(diǎn)擊創(chuàng)建報(bào)告,就可以得到當(dāng)前模型校驗(yàn)當(dāng)前數(shù)據(jù)集獲得的識(shí)別準(zhǔn)確度。
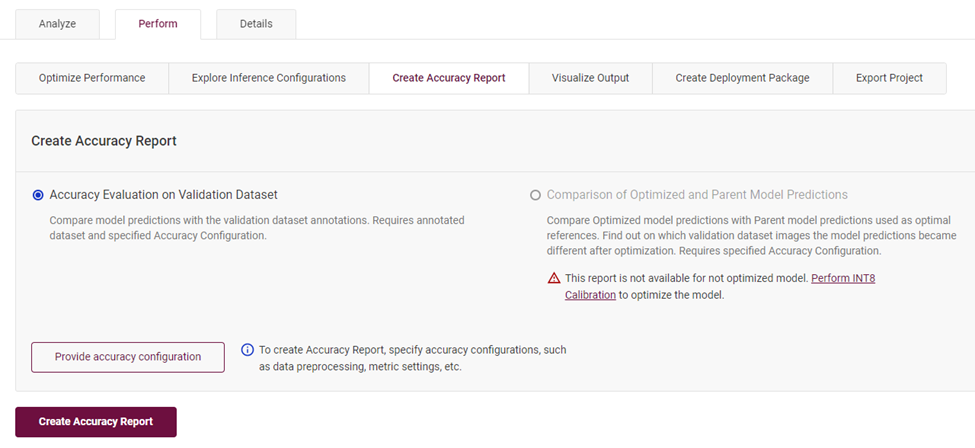
圖4-8 創(chuàng)建模型識(shí)別準(zhǔn)確度報(bào)告
當(dāng)你同時(shí)有 FP32 精度模型和 INT8 精度模型時(shí),你可以通過(guò)準(zhǔn)確度測(cè)算報(bào)告來(lái)獲得詳細(xì)的準(zhǔn)確度信息。標(biāo)注于“Accuracy”一欄中。
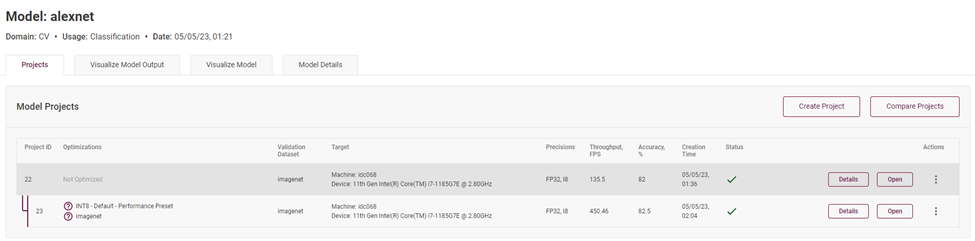
圖4-9 對(duì)比 INT8 模型與 FP32 模型識(shí)別準(zhǔn)確度與推理性能數(shù)據(jù)
最終,我們發(fā)現(xiàn)同樣一個(gè)拓?fù)浣Y(jié)構(gòu)的模型,模型各層主要精度分別為 FP32 和 INT8,實(shí)測(cè) FPS 的數(shù)據(jù)為 FP32 的 135.5FPS,而 INT8 精度的模型高達(dá) 450.46FPS,且前提是在準(zhǔn)確度下降在百分之一的范圍內(nèi)。說(shuō)明低精度推理對(duì)于模型推理計(jì)算的性能提升還是非常可觀的。
4.7設(shè)置多組推理參數(shù),獲取最優(yōu)推理參數(shù)
優(yōu)化策略中也包含了對(duì)于推理參數(shù)的組合設(shè)定,通過(guò)“Group Inference”實(shí)現(xiàn):
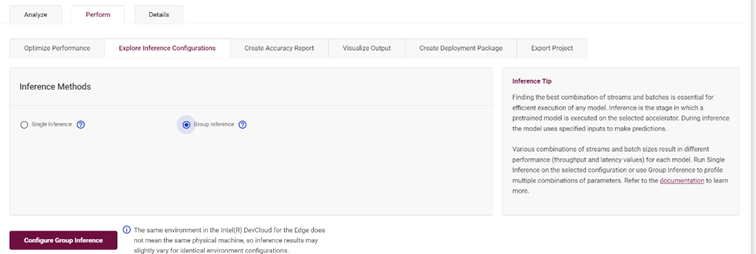
圖4-10 Group Inference 設(shè)置
在此選擇你需要測(cè)試的多個(gè) Stream 數(shù)值,以及 Batch 的數(shù)值,組合推理測(cè)試結(jié)果將會(huì)以圖表的方式展現(xiàn),以幫助你找到該模型的在此設(shè)備上的最佳推理參數(shù):
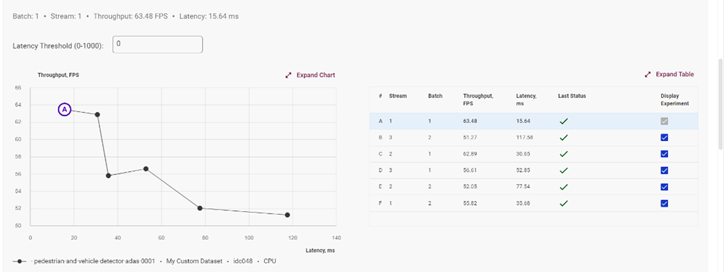
圖4-11 推理測(cè)試結(jié)果展示
4.8橫向/縱向模型性能評(píng)估
完成了單個(gè)模型的性能評(píng)估,可以使用不同的設(shè)備對(duì)此模型進(jìn)行多次深入評(píng)估。
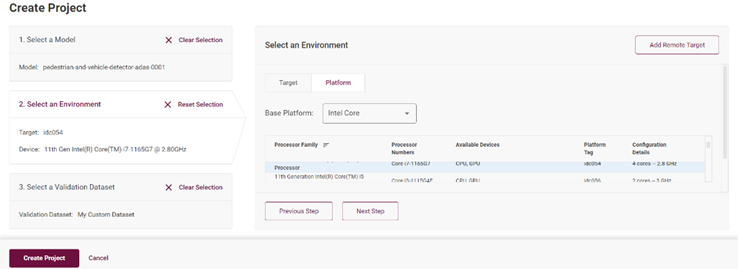
圖4-12 橫向模型性能對(duì)比
由此可知,你可以從橫向(精度格式,batch size,steam)對(duì)模型進(jìn)行評(píng)估,也可以從縱向(不同的設(shè)備,CPU/iGPU)來(lái)比較同一個(gè)模型的性能水平。當(dāng)然也可以在相同的機(jī)器上選擇測(cè)試兩個(gè)不一樣的模型來(lái)評(píng)估兩個(gè)模型的性能優(yōu)劣。
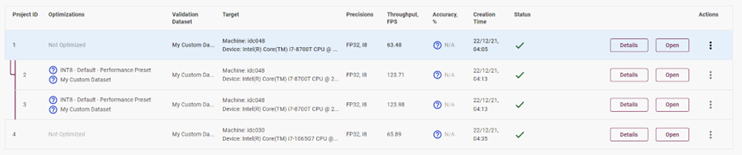
圖4-13 縱向模型性能對(duì)比
5.總結(jié)
DL workbench 工具集成了非常多的功能,方便開(kāi)發(fā)者的調(diào)用。由于篇幅的限制,本篇的介紹并不能全部覆蓋,僅就 DL workbench 功能做分享。更多功能,請(qǐng)登陸Intel Developer Cloud 平臺(tái)來(lái)嘗試吧!
審核編輯:湯梓紅
-
英特爾
+關(guān)注
關(guān)注
61文章
10188瀏覽量
174312 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4812瀏覽量
103226 -
intel
+關(guān)注
關(guān)注
19文章
3494瀏覽量
188237 -
Developer
+關(guān)注
關(guān)注
0文章
26瀏覽量
6560 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5557瀏覽量
122661
原文標(biāo)題:一文了解Intel? Developer Cloud 之DL Workbench深度學(xué)習(xí)工作臺(tái) | 開(kāi)發(fā)者實(shí)戰(zhàn)
文章出處:【微信號(hào):英特爾物聯(lián)網(wǎng),微信公眾號(hào):英特爾物聯(lián)網(wǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
通過(guò)docker下載的DL Workbench,DL Workbench在導(dǎo)入模型時(shí)停止響應(yīng)是怎么回事?
為什么無(wú)法通過(guò)OpenVINO?深度學(xué)習(xí) (DL) 工作臺(tái)優(yōu)化 MYRIAD 導(dǎo)入的模型?
在深度學(xué)習(xí)工作臺(tái)中安裝Python軟件包報(bào)錯(cuò)怎么解決?
在OpenVINO?工具套件的深度學(xué)習(xí)工作臺(tái)中無(wú)法導(dǎo)出INT8模型怎么解決?
如何排除深度學(xué)習(xí)工作臺(tái)上量化OpenVINO?的特定層?
模具工作臺(tái)檢測(cè)應(yīng)用案例
使用SPC5 studio作為工作臺(tái)調(diào)試收到警告
工作臺(tái)生成不完整的源代碼怎么處理?
人工智能之深度強(qiáng)化學(xué)習(xí)DRL的解析
什么是深度學(xué)習(xí)(Deep Learning)?深度學(xué)習(xí)的工作原理詳解
如何借助TigerGraph機(jī)器學(xué)習(xí)工作臺(tái)加速企業(yè)BI
Intel Developer Cloud Telemetry數(shù)據(jù)分析(一)
Intel Developer Cloud之Telemetry數(shù)據(jù)分析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論