 如何提高深度神經網絡的表現性能
如何提高深度神經網絡的表現性能
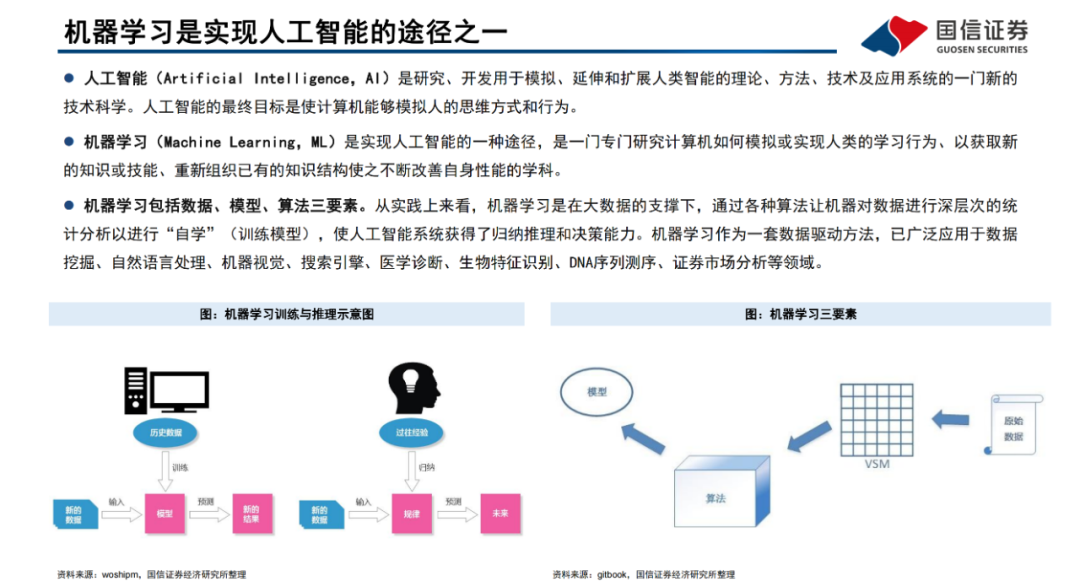
機器學習是一門專門研究計算機如何模擬或實現人類的學習行為、以獲取新的知識或技能、重新組織已有的知識結構使之不斷改善自身性能的學科,廣泛應用于數據挖掘、計算機視覺、自然語言處理等領域。深度學習是機器學習的子集,主要由人工神經網絡組成。與傳統算法及中小型神經網絡相比,大規模的神經網絡及海量的數據支撐將有效提高深度神經網絡的表現性能。
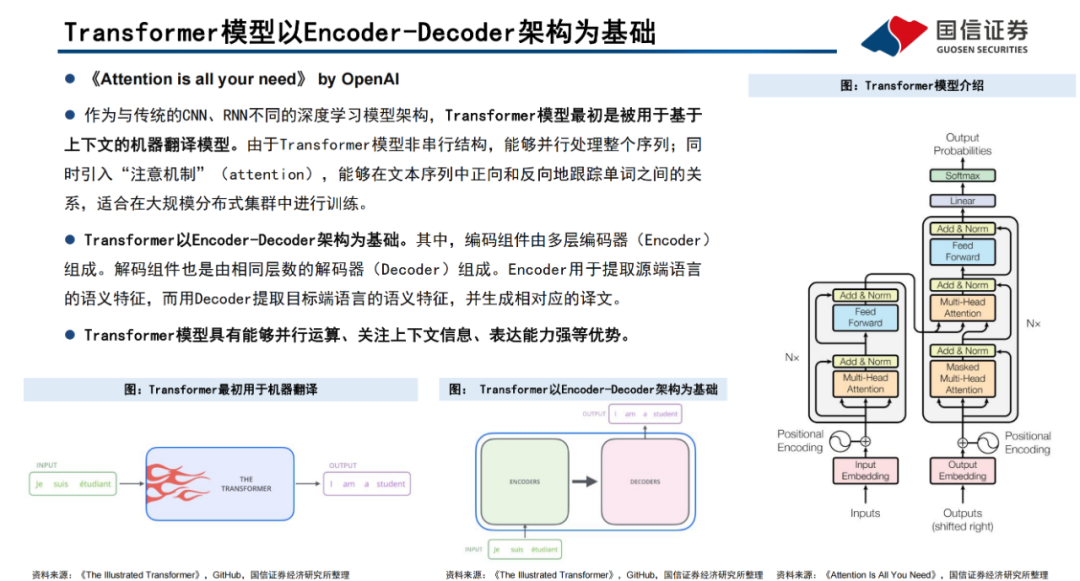
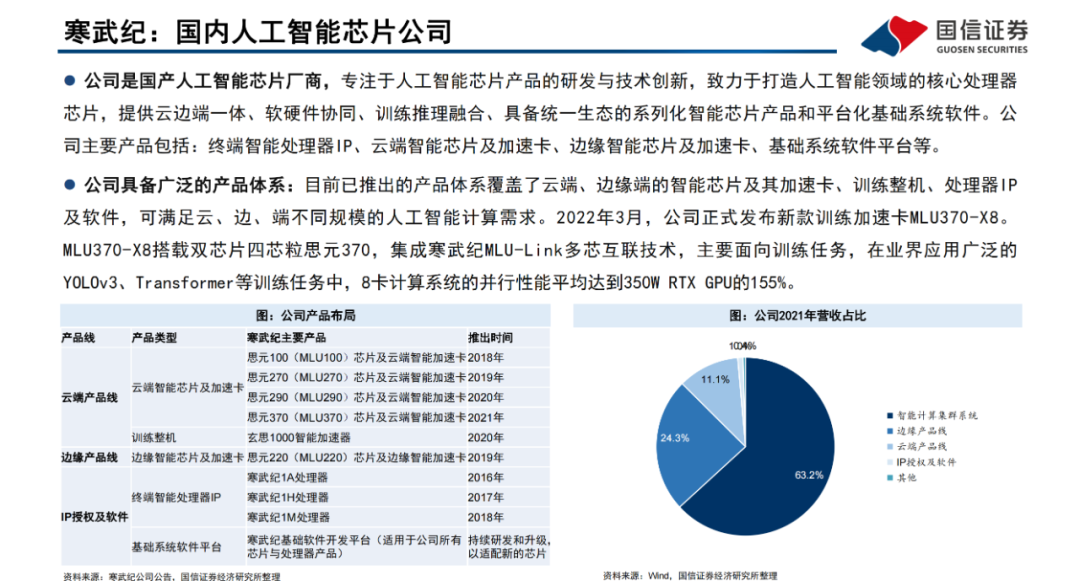
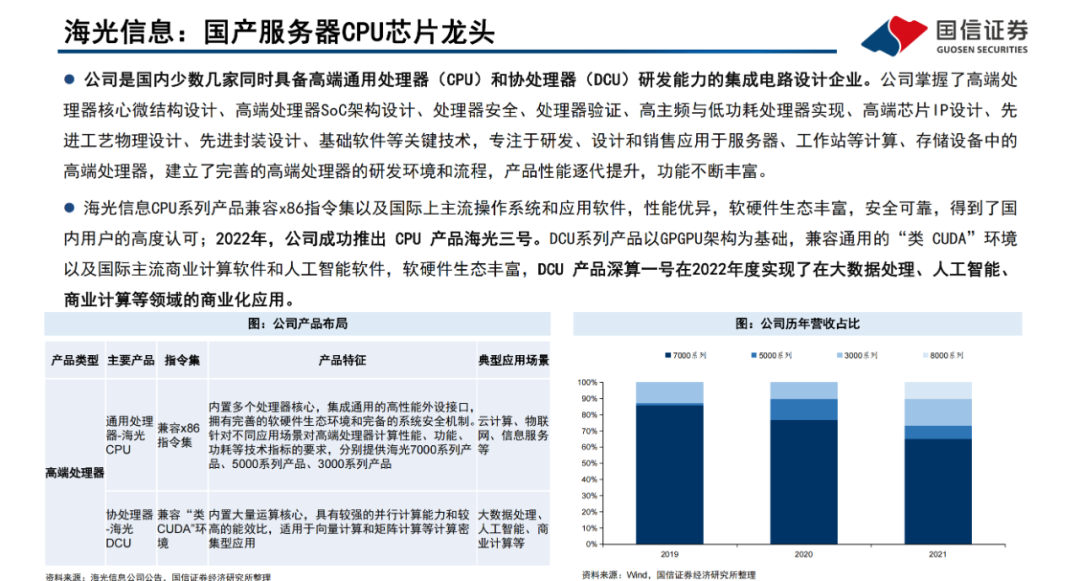
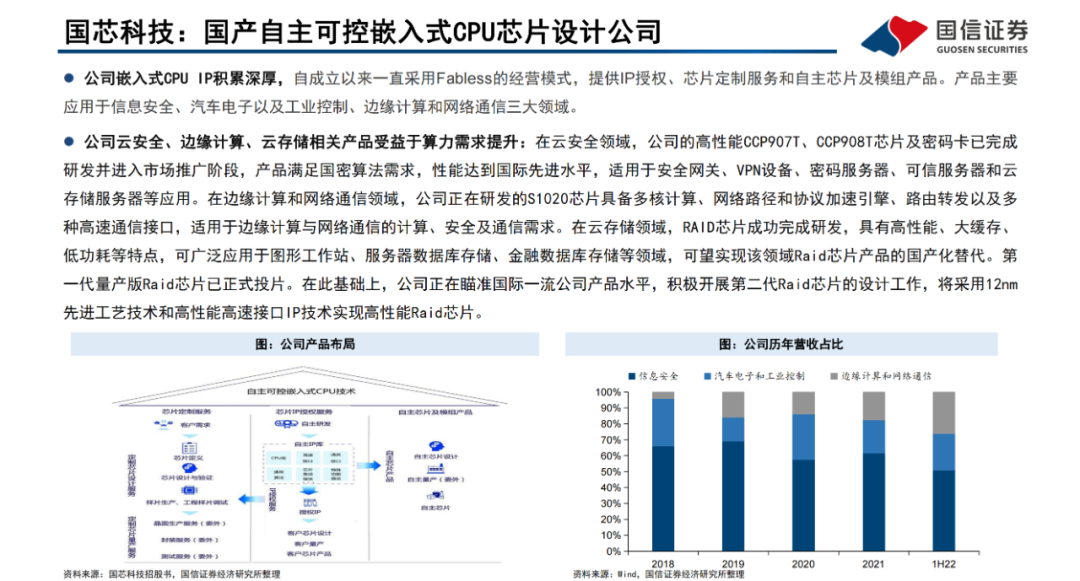
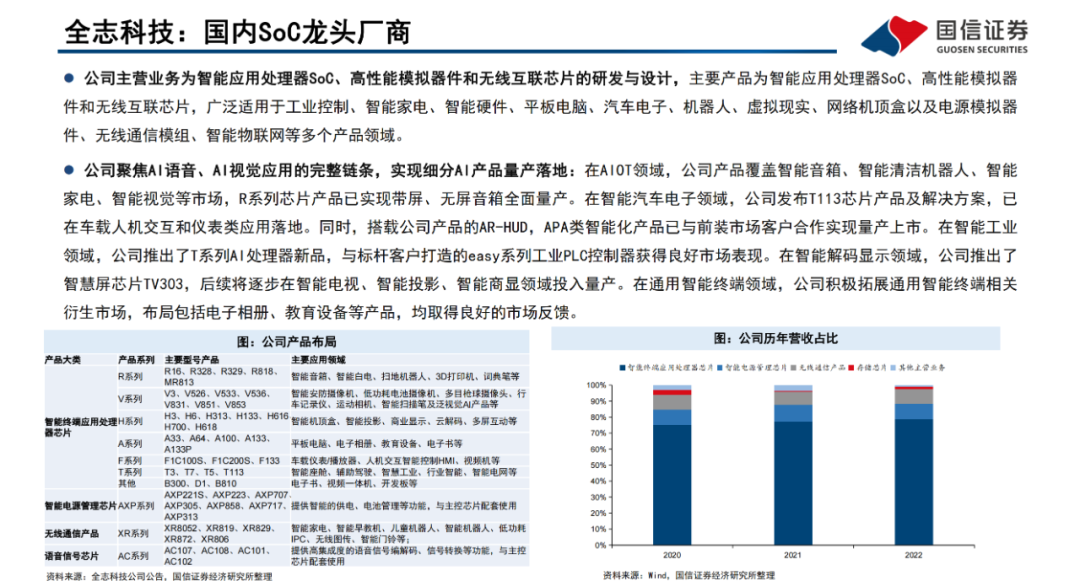
Transformer模型是一種非串行的神經網絡架構,最初被用于執行基于上下文的機器翻譯任務。Transformer模型以Encoder-Decoder架構為基礎,能夠并行處理整個文本序列,同時引入“注意機制”(Attention),使其能夠在文本序列中正向和反向地跟蹤單詞之間的關系,適合在大規模分布式集群中進行訓練,因此具有能夠并行運算、關注上下文信息、表達能力強等優勢。Transformer模型以詞嵌入向量疊加位置編碼作為輸入,使得輸入序列具有位置上的關聯信息。
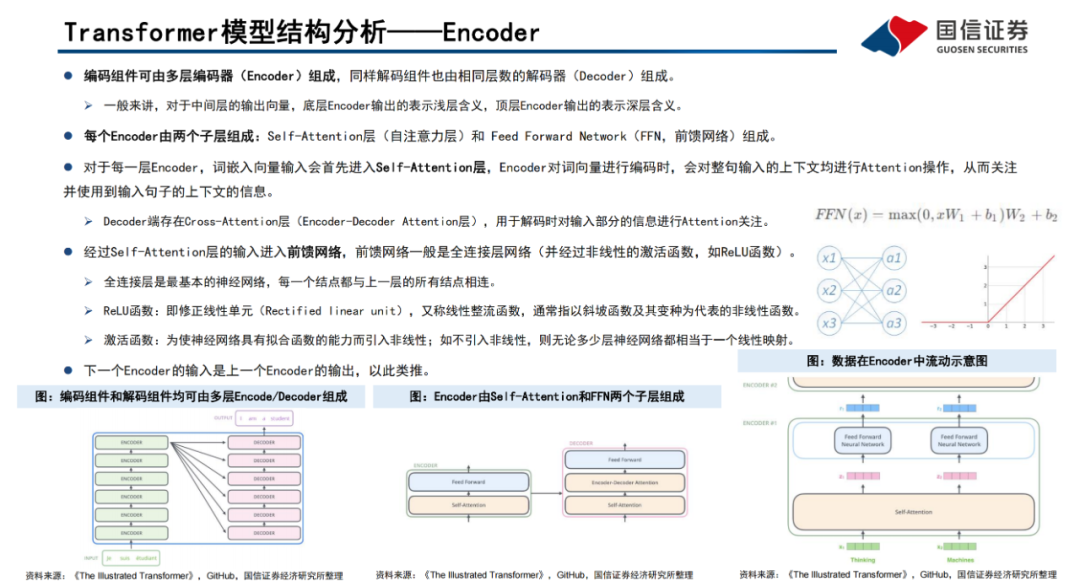
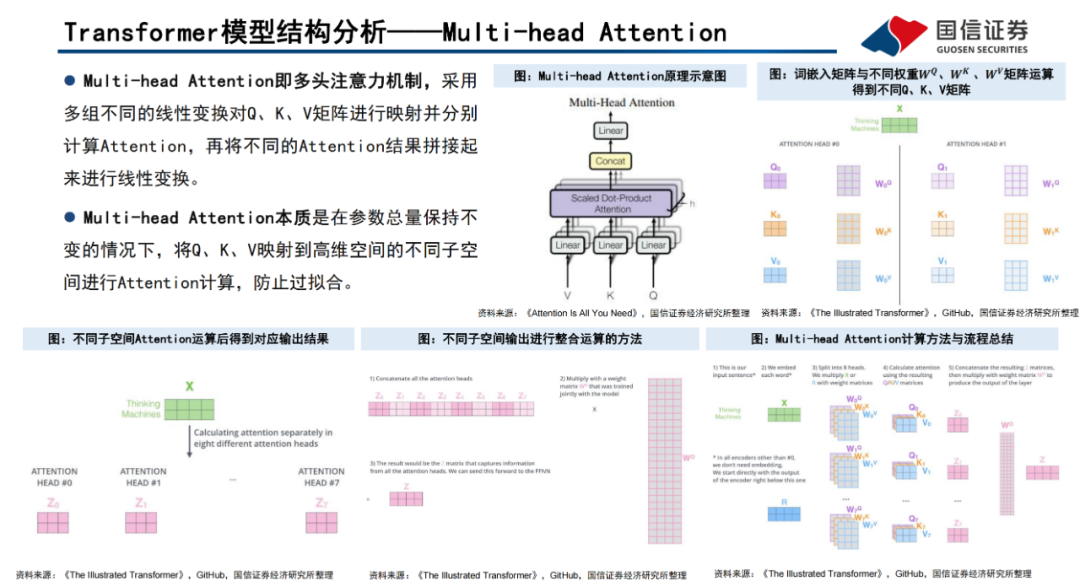
編碼器(Encoder)由Self-Attention(自注意力層)和 Feed Forward Network(前饋網絡)兩個子層組成,Attention使得模型不僅關注當前位置的詞語,同時能夠關注上下文的詞語。
解碼器(Decoder)通過Encoder-DecoderAttention層,用于解碼時對于輸入端編碼信息的關注;利用掩碼(Mask)機制,對序列中每一位置根據之前位置的輸出結果循環解碼得到當前位置的輸出結果。
以GPT-3為例,GPT-3參數量達1750億個,訓練樣本token數達3000億個。考慮采用精度為32位的單精度浮點數數據來訓練模型及進行谷歌級訪問量推理,假設GPT-3模型每次訓練時間要求在30天完成,對應GPT-3所需運算次數為3.15*10^23FLOPs,所需算力為121.528PFLOPS,以A100PCle芯片為例,訓練階段需要新增A100 GPU芯片1558顆,對應DGX A100服務器195臺。
假設推理階段按谷歌每日搜索量35億次進行估計,則每日GPT-3需推理token數達7.9萬億個,所需運算次數為4.76*10^24FLOPs,所需算力為55EFLOPs,則推理階段需要新增A100 GPU芯片70.6萬顆,對應DGX A100服務器8.8萬臺。

















-
神經網絡
+關注
關注
42文章
4779瀏覽量
101047 -
計算機
+關注
關注
19文章
7534瀏覽量
88451 -
機器學習
+關注
關注
66文章
8438瀏覽量
132928
原文標題:AI大語言模型原理、演進及算力測算
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
詳解深度學習、神經網絡與卷積神經網絡的應用

從AlexNet到MobileNet,帶你入門深度神經網絡
深度神經網絡是什么
如何構建神經網絡?
基于深度神經網絡的激光雷達物體識別系統
卷積神經網絡模型發展及應用
【人工神經網絡基礎】為什么神經網絡選擇了“深度”?
深度學習:神經網絡和函數
什么是神經網絡?什么是卷積神經網絡?
淺析三種主流深度神經網絡
淺析三種主流深度神經網絡






 工商網監
工商網監
評論