 生成視頻如此簡單,給句提示就行,還能在線試玩
生成視頻如此簡單,給句提示就行,還能在線試玩
動動嘴皮子就能生成視頻的新研究來了。
你輸入文字,讓 AI 來生成視頻,這種想法在以前只出現在人們的想象中,現在,隨著技術的發展,這種功能已經實現了。 近年來,生成式人工智能在計算機視覺領域引起巨大的關注。隨著擴散模型的出現,從文本 Prompt 生成高質量圖像,即文本到圖像的合成,已經變得非常流行和成功。 最近的研究試圖通過在視頻領域復用文本到圖像擴散模型,將其成功擴展到文本到視頻生成和編輯的任務。雖然這樣的方法取得了可喜的成果,但大部分方法需要使用大量標記數據進行大量訓練,這可能對許多用戶來講太過昂貴。 為了使視頻生成更加廉價,Jay Zhangjie Wu 等人去年提出的 Tune-A-Video 引入了一種機制,可以將 Stable Diffusion (SD) 模型應用到視頻領域。只需要調整一個視頻,從而讓訓練工作量大大減少。雖然這比以前的方法效率提升很多,但仍需要進行優化。此外,Tune-A-Video 的生成能力僅限于 text-guided 的視頻編輯應用,而從頭開始合成視頻仍然超出了它的能力范圍。 本文中,來自 Picsart AI Resarch (PAIR) 、得克薩斯大學奧斯汀分校等機構的研究者在 zero-shot 以及無需訓練的情況下,在文本到視頻合成的新問題方向上向前邁進了一步,即無需任何優化或微調的情況下根據文本提示生成視頻。

論文地址:https://arxiv.org/pdf/2303.13439.pdf
項目地址:https://github.com/Picsart-AI-Research/Text2Video-Zero
試用地址:https://huggingface.co/spaces/PAIR/Text2Video-Zero
下面我們看看效果如何。例如一只熊貓在沖浪;一只熊在時代廣場上跳舞:

該研究還能根據目標生成動作:

此外,還能進行邊緣檢測:

本文提出的方法的一個關鍵概念是修改預訓練的文本到圖像模型(例如 Stable Diffusion),通過時間一致的生成來豐富它。通過建立在已經訓練好的文本到圖像模型的基礎上,本文的方法利用它們出色的圖像生成質量,增強了它們在視頻領域的適用性,而無需進行額外的訓練。 為了加強時間一致性,本文提出兩個創新修改:(1)首先用運動信息豐富生成幀的潛在編碼,以保持全局場景和背景時間一致;(2) 然后使用跨幀注意力機制來保留整個序列中前景對象的上下文、外觀和身份。實驗表明,這些簡單的修改可以生成高質量和時間一致的視頻(如圖 1 所示)。

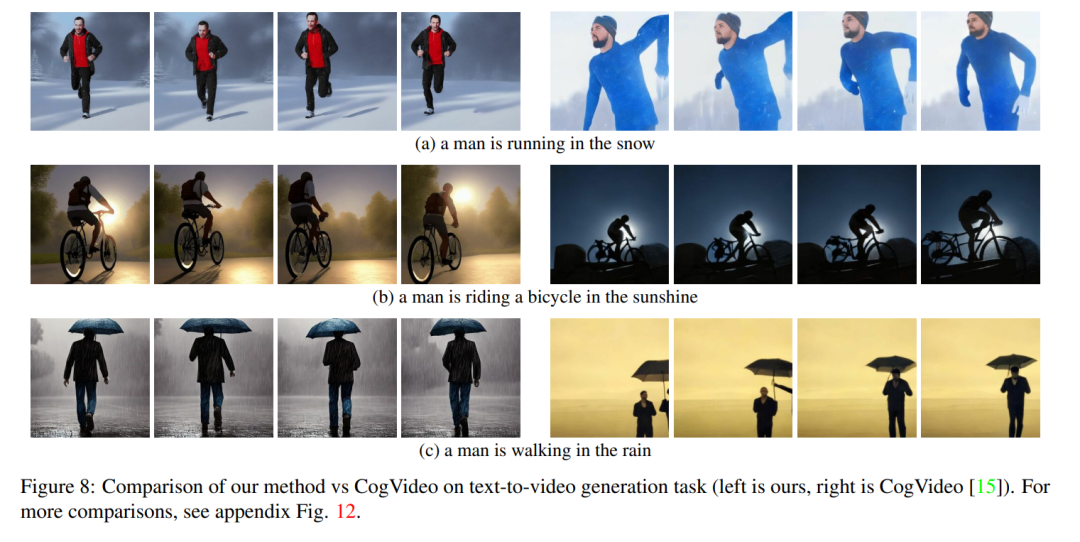
盡管其他人的工作是在大規模視頻數據上進行訓練,但本文的方法實現了相似甚至有時更好的性能(如圖 8、9 所示)。

本文的方法不僅限于文本到視頻的合成,還適用于有條件的(見圖 6、5)和專門的視頻生成(見圖 7),以及 instruction-guided 的視頻編輯,可以稱其為由 Instruct-Pix2Pix 驅動的 Video Instruct-Pix2Pix(見圖 9)。



方法簡介 在這篇論文中,本文利用 Stable Diffusion (SD)的文本到圖像合成能力來處理 zero-shot 情況下文本到視頻的任務。由于需要生成視頻而不是圖像,SD 應該在潛在代碼序列上進行操作。樸素的方法是從標準高斯分布獨立采樣 m 個潛在代碼,即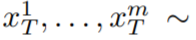 ?N (0, I) ,并應用 DDIM 采樣以獲得相應的張量
?N (0, I) ,并應用 DDIM 采樣以獲得相應的張量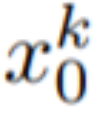 ,其中 k = 1,…,m,然后解碼以獲得生成的視頻序列
,其中 k = 1,…,m,然后解碼以獲得生成的視頻序列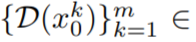
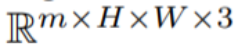
。然而,如圖 10 的第一行所示,這會導致完全隨機的圖像生成,僅共享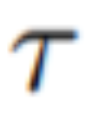 所描述的語義,而不具有物體外觀或運動的一致性。 ?
所描述的語義,而不具有物體外觀或運動的一致性。 ?

為了解決這個問題,本文建議采用以下兩種方法:(i)在潛在編碼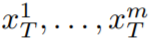 之間引入運動動態,以保持全局場景的時間一致性;(ii)使用跨幀注意力機制來保留前景對象的外觀和身份。下面詳細描述了本文使用的方法的每個組成部分,該方法的概述可以在圖 2 中找到。 ?
之間引入運動動態,以保持全局場景的時間一致性;(ii)使用跨幀注意力機制來保留前景對象的外觀和身份。下面詳細描述了本文使用的方法的每個組成部分,該方法的概述可以在圖 2 中找到。 ?
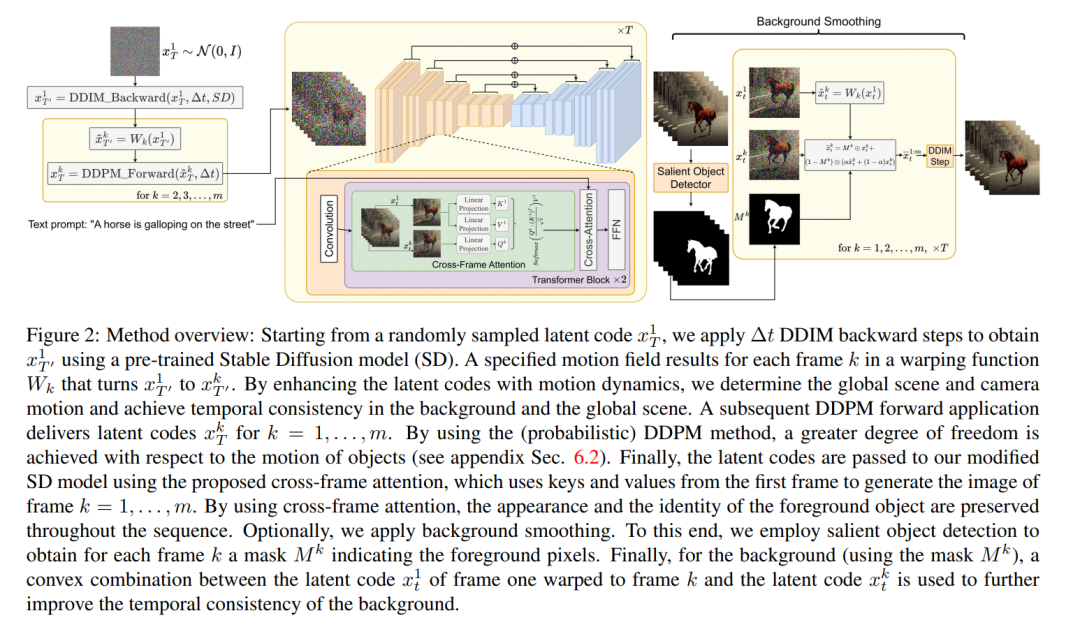
注意,為了簡化符號,本文將整個潛在代碼序列表示為: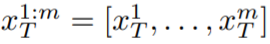 。 ?實驗?定性結果? Text2Video-Zero 的所有應用都表明它成功生成了視頻,其中全局場景和背景具有時間一致性,前景對象的上下文、外觀和身份在整個序列中得到了保持。 ? 在文本轉視頻的情況下,可以觀察到它生成與文本提示良好對齊的高質量視頻(見圖 3)。例如,繪制的熊貓可以自然地在街上行走。同樣,使用額外的邊緣或姿勢指導 (見圖 5、圖 6 和圖 7),生成了與 Prompt 和指導相匹配的高質量視頻,顯示出良好的時間一致性和身份保持。 ?
。 ?實驗?定性結果? Text2Video-Zero 的所有應用都表明它成功生成了視頻,其中全局場景和背景具有時間一致性,前景對象的上下文、外觀和身份在整個序列中得到了保持。 ? 在文本轉視頻的情況下,可以觀察到它生成與文本提示良好對齊的高質量視頻(見圖 3)。例如,繪制的熊貓可以自然地在街上行走。同樣,使用額外的邊緣或姿勢指導 (見圖 5、圖 6 和圖 7),生成了與 Prompt 和指導相匹配的高質量視頻,顯示出良好的時間一致性和身份保持。 ?

在 Video Instruct-Pix2Pix(見圖 1)的情況下,生成的視頻相對于輸入視頻具有高保真,同時嚴格遵循指令。 與 Baseline 比較 本文將其方法與兩個公開可用的 baseline 進行比較:CogVideo 和 Tune-A-Video。由于 CogVideo 是一種文本到視頻的方法,本文在純文本引導的視頻合成場景中與它進行了比較;使用 Video Instruct-Pix2Pix 與 Tune-A-Video 進行比較。 為了進行定量對比,本文使用 CLIP 分數對模型評估,CLIP 分數表示視頻文本對齊程度。通過隨機獲取 CogVideo 生成的 25 個視頻,并根據本文的方法使用相同的提示合成相應的視頻。本文的方法和 CogVideo 的 CLIP 分數分別為 31.19 和 29.63。因此,本文的方法略優于 CogVideo,盡管后者有 94 億個參數并且需要對視頻進行大規模訓練。 圖 8 展示了本文提出的方法的幾個結果,并提供了與 CogVideo 的定性比較。這兩種方法在整個序列中都顯示出良好的時間一致性,保留了對象的身份以及背景。本文的方法顯示出更好的文本 - 視頻對齊能力。例如,本文的方法在圖 8 (b) 中正確生成了一個人在陽光下騎自行車的視頻,而 CogVideo 將背景設置為月光。同樣在圖 8 (a) 中,本文的方法正確地顯示了一個人在雪地里奔跑,而 CogVideo 生成的視頻中雪地和奔跑的人是看不清楚的。 Video Instruct-Pix2Pix 的定性結果以及與 per-frame Instruct-Pix2Pix 和 Tune-AVideo 在視覺上的比較如圖 9 所示。雖然 Instruct-Pix2Pix 每幀顯示出良好的編輯性能,但它缺乏時間一致性。這在描繪滑雪者的視頻中尤其明顯,視頻中的雪和天空使用不同的樣式和顏色繪制。使用 Video Instruct-Pix2Pix 方法解決了這些問題,從而在整個序列中實現了時間上一致的視頻編輯。 雖然 Tune-A-Video 創建了時間一致的視頻生成,但與本文的方法相比,它與指令指導的一致性較差,難以創建本地編輯,并丟失了輸入序列的細節。當看到圖 9 左側中描繪的舞者視頻的編輯時,這一點變得顯而易見。與 Tune-A-Video 相比,本文的方法將整件衣服畫得更亮,同時更好地保留了背景,例如舞者身后的墻幾乎保持不變。Tune-A-Video 繪制了一堵經過嚴重變形的墻。此外,本文的方法更忠實于輸入細節,例如,與 Tune-A-Video 相比,Video Instruction-Pix2Pix 使用所提供的姿勢繪制舞者(圖 9 左),并顯示輸入視頻中出現的所有滑雪人員(如圖 9 右側的最后一幀所示)。Tune-A-Video 的所有上述弱點也可以在圖 23、24 中觀察到。


審核編輯 :李倩
-
圖像
+關注
關注
2文章
1087瀏覽量
40503 -
模型
+關注
關注
1文章
3268瀏覽量
48929 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
46033
原文標題:生成視頻如此簡單,給句提示就行,還能在線試玩
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
高清端在線視頻聊天插件軟件平臺
[轉載]【試玩】Android系統(安兔兔跑分 和 播放視頻)
【視頻】如何調試LabVIEW生成的EXE程序
【MiCO分享貼】MiCOKit-3288開箱試玩
vivado在線調試
labview生成安裝包不能在win7上運行?
人工智能在視頻應用中的實踐探索,涉及編解碼器、超分辨率等

值得收藏!10種在線免費壓縮視頻的絕佳方案
Vyond推出首款基于提示的腳本和視頻創建器
配電系統智能在線監測

文生視頻Pika 1.0爆火!一句話生成視頻,普通人也能當“導演”






 工商網監
工商網監
評論