 ChatGPT從入門到深入
ChatGPT從入門到深入
ChatGPT從入門到深入(持續更新中)
循環記憶輸入
Recurrent Memory Transformer (RMT)
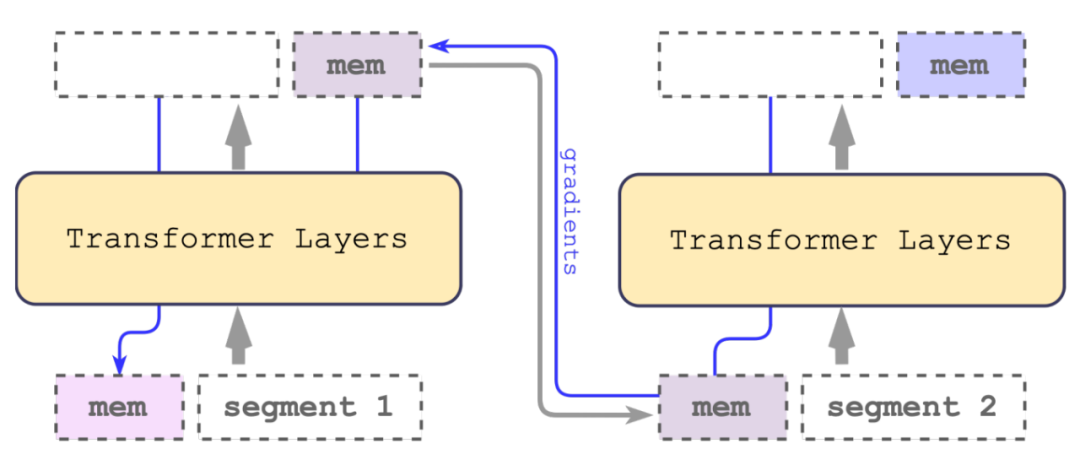
總體思想:將長文本分段之后得到嵌入向量與記憶向量拼接,得到新的記憶向量之后與下一段再循環輸入transformer。
注意:此論文實驗結果在bert-base-cased(encoder-only上進行實驗)
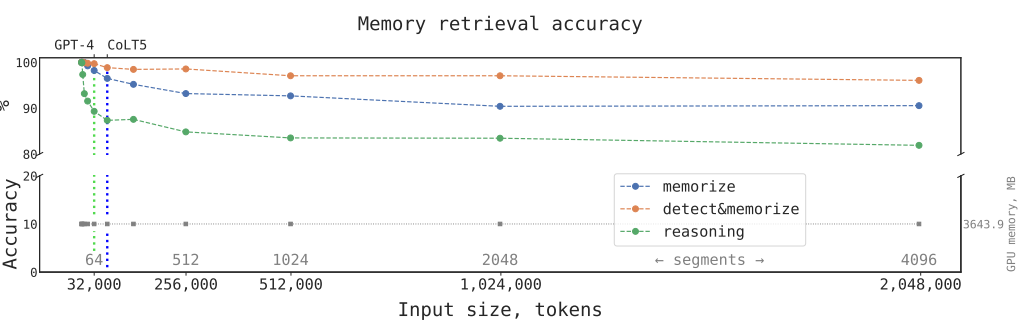
CoLT5達到64K,GPT-4達到32K長度,而RMT在實驗結果中長度加到4096個分段2048000詞匯,效果依然強勁。
用提示詞
Self-Controlled Memory (SCM)
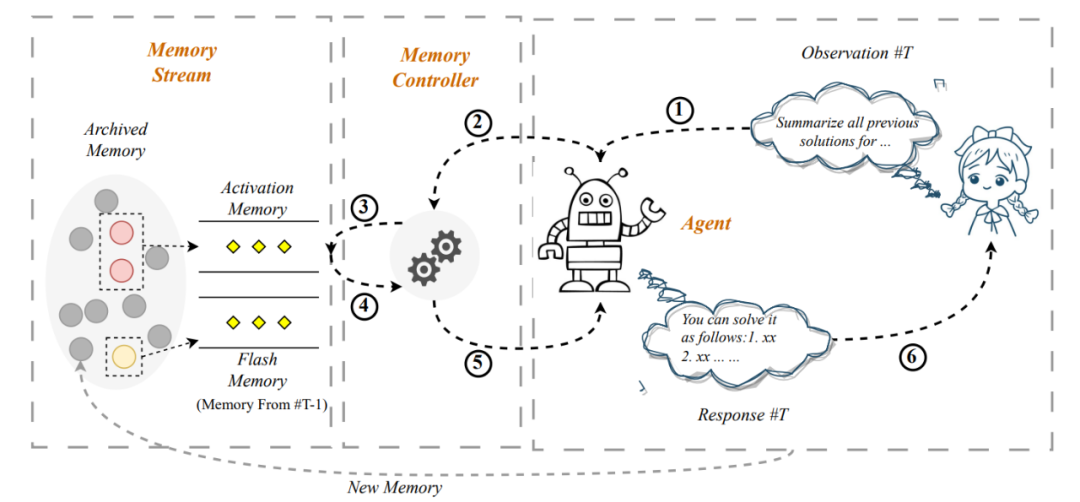
如上圖所示,此方法號稱可以將輸入延申至無限長,具體流程為:
-
用戶輸入
-
判斷是否需要從歷史會話中獲得記憶,提示詞如下:
給定一個用戶指令,判斷執行該指令是否需要歷史信 息或者上文的信息,或者需要回憶對話內容,只需要 回答是(A)或者否(B),不需要解釋信息: 指令:[用戶輸入] -
如果需要獲取記憶,通過相關性(余弦相似度)、近期性分數相加對歷史記憶進行排序
-
將記憶摘要
以下是用戶和人工智能助手的一段對話,請分 別用一句話寫出用戶摘要、助手摘要,分段列 出,要求盡可能保留用戶問題和助手回答的關 鍵信息。 對話內容: 用戶:[用戶輸入] 助手:[系統回復] 摘要: -
將記憶和輸入拼接輸入模型
以下是用戶和人工智能助手的對話,請根據歷史 對話內容,回答用戶當前問題: 相關歷史對話: [歷史輪對話內容] 上一輪對話: [上一輪對話內容] ### 用戶:[用戶問題] 助手: -
回復
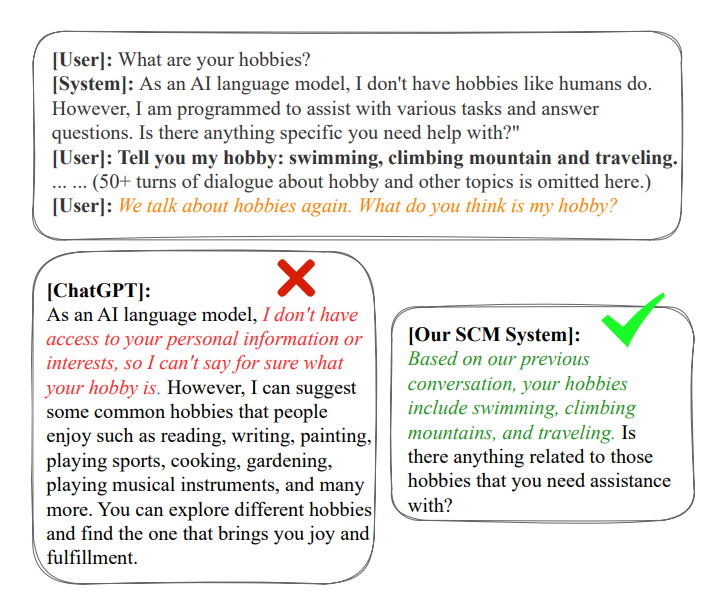
注意:此論文中只進行了定性分析,沒有定量實驗。以下是效果圖:
詞匯壓縮
VIP-token centric compression (Vcc)
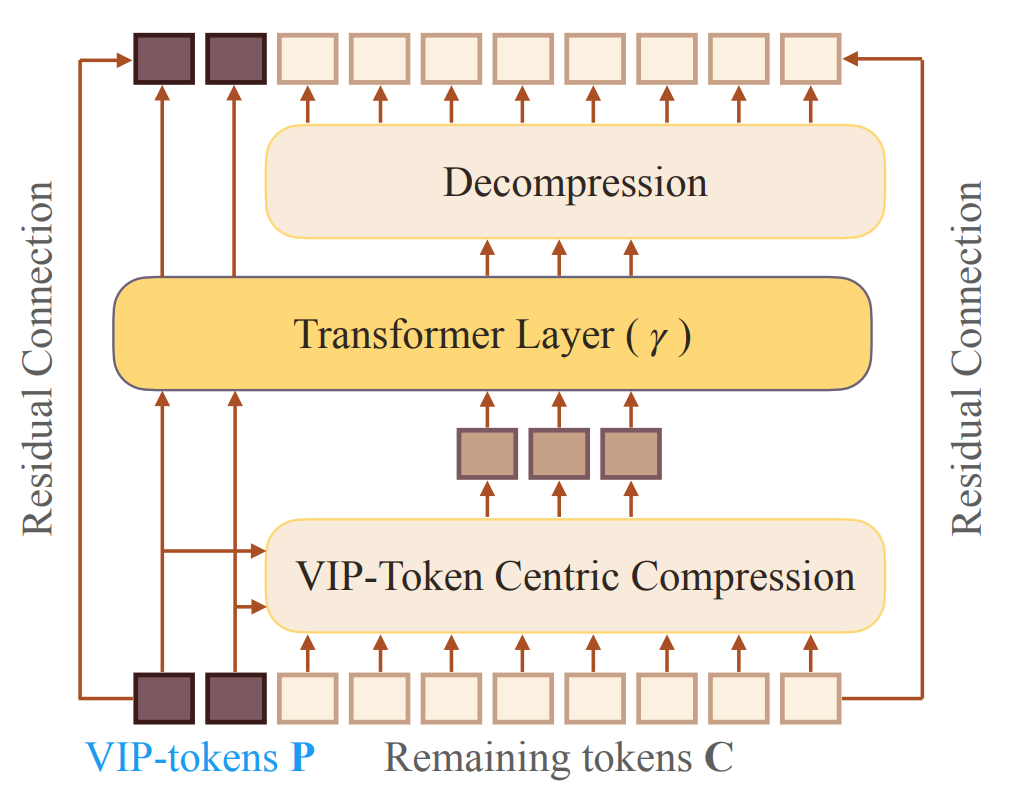
該方法使得模型輸入延申至128K,并在Encoder-Only、Encoder-Decoder兩種模型架構上都進行了實驗。
一句話描述思想:使模型輸入長度獨立于文本長度。
具體一點:
- 將當前問句視為vip-token
- 利用當前問句與歷史記憶的關系,壓縮歷史記憶到模型輸入長度,無論歷史記憶有多長
- transformer層輸出之后再進行解壓縮
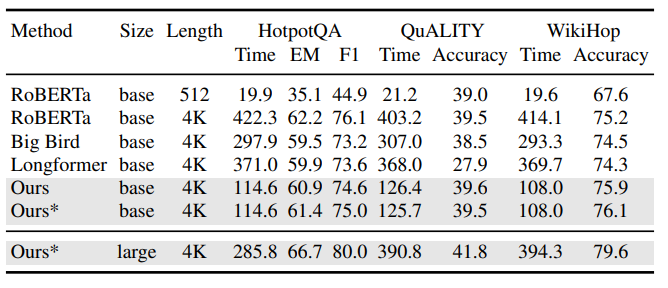
Encoder-Only架構表現:
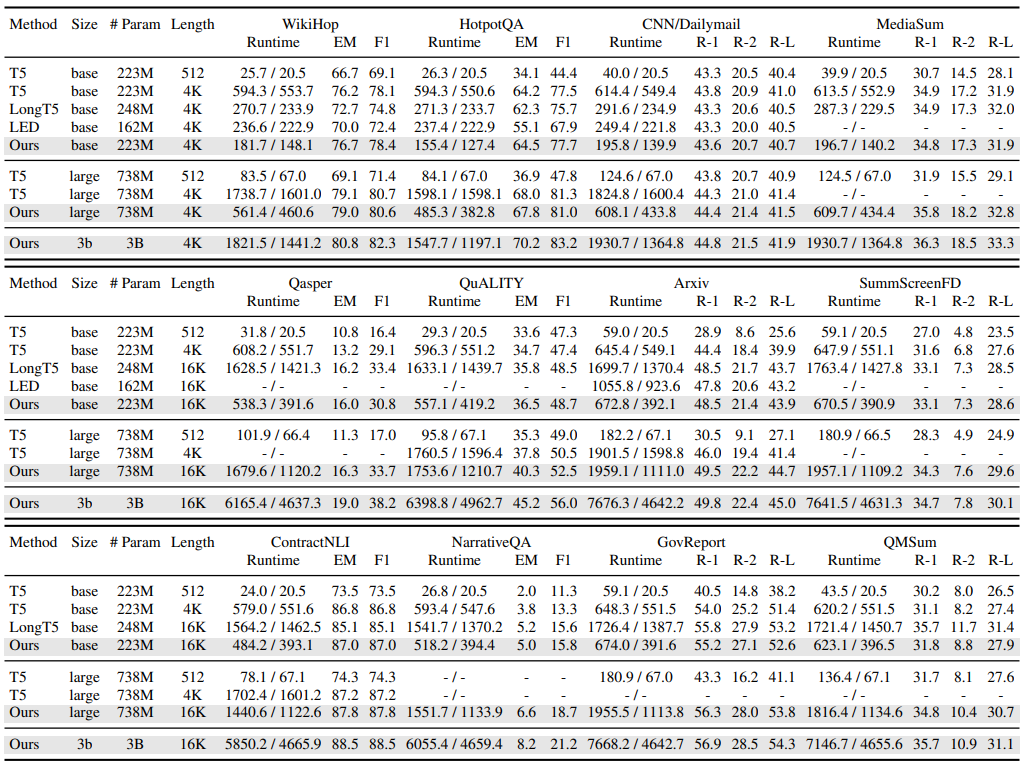
Encoder-Decoder表現:
檢索+交叉注意力
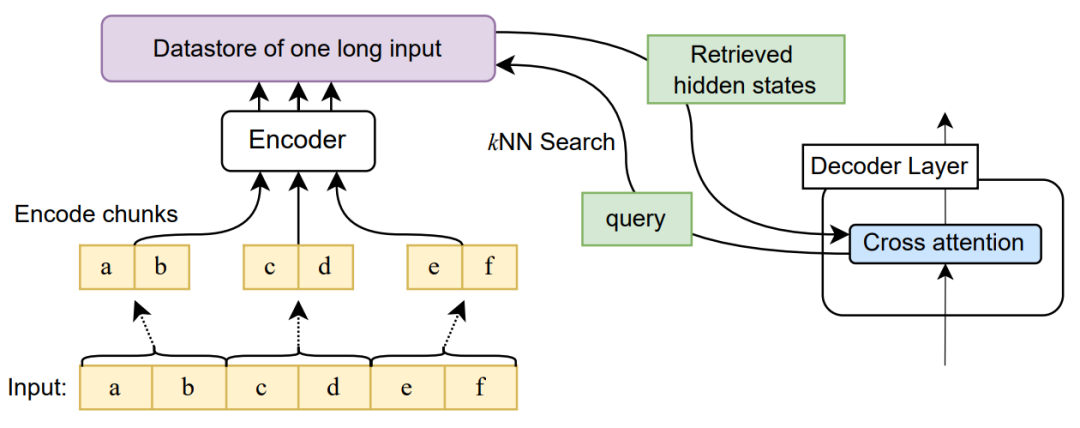
此方法只試用于Encoder-Decoder架構,其也稱可以將輸入長度延申至無限長。
思路如下:
- 將長文本分成多個部分,將每一段進行編碼
- 利用query KNN檢索長文本topN
- 解碼器對相關段落編碼后的隱藏狀態進行交叉注意力
- 得到輸出
可以看到此方法在長文本摘要任務上都取得了優異的結果
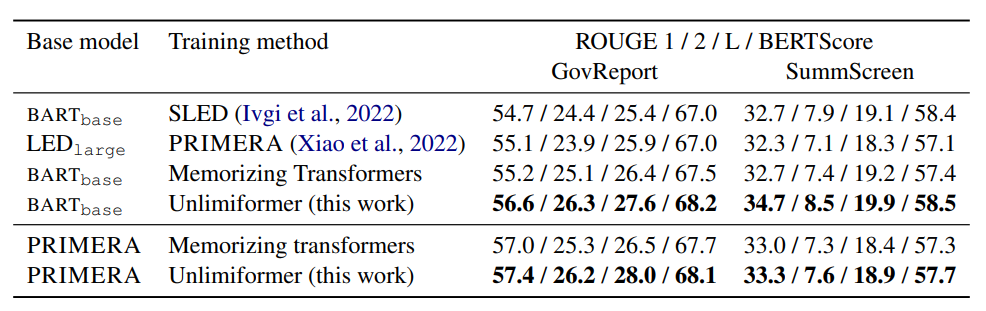
累加
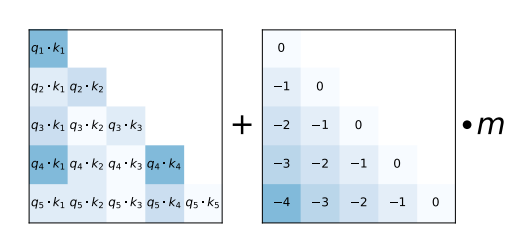
簡單介紹一下ALiBi:
- 不再輸入層保留位置向量
- 而在每層注入線性的偏移量,注意力分數從:
變成了:
可以看到ALiBi比Sinusoidal、Rotary、T5 Bias在長距離輸入上效果都要好得多。
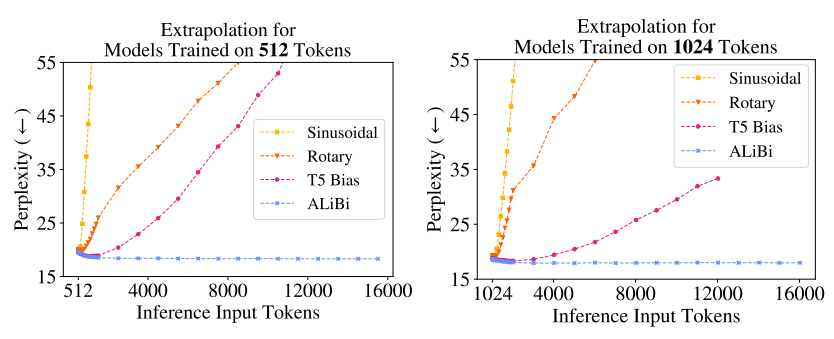
mosaicml/mpt-7b模型利用ALiBi將輸入長度擴展至了84k,核心的思想為一下幾行代碼:
all_hidden_states=()ifoutput_hidden_stateselseNone
for(b_idx,block)inenumerate(self.blocks):
ifoutput_hidden_states:
assertall_hidden_statesisnotNone
all_hidden_states=all_hidden_states+(x,)
past_key_value=past_key_values[b_idx]ifpast_key_valuesisnotNoneelseNone
(x,past_key_value)=block(x,past_key_value=past_key_value,attn_bias=attn_bias,attention_mask=attention_mask,is_causal=self.is_causal)
ifpast_key_valuesisnotNone:
past_key_values[b_idx]=past_key_value
即MPT會對上次得到隱藏狀態與本次的輸入進行相加。
審核編輯 :李倩
-
人工智能
+關注
關注
1792文章
47442瀏覽量
239006 -
ChatGPT
+關注
關注
29文章
1564瀏覽量
7823
原文標題:引用
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論