") 算力呈指數(shù)級增長,服務器有哪些進展?
算力呈指數(shù)級增長,服務器有哪些進展?
電子發(fā)燒友網(wǎng)報道(文/黃晶晶)人工智能的基座包括數(shù)據(jù)、算力和算法。其中算力更是數(shù)據(jù)和算法的支撐。各類模型基于數(shù)據(jù)量、算法的訓練和推理推動了算力需求。
根據(jù)OpenAI的測算數(shù)據(jù),AI訓練運行所使用的算力每3-4個月增長一倍。AI訓練運行所使用的算力已增長超30萬倍。IDC數(shù)據(jù)顯示,2022年我國智能算力規(guī)模達到268百億億次/秒(EFLOPS),超過通用算力規(guī)模;預計未來5年我國智能算力規(guī)模的年復合增長率將達52.3%。
構(gòu)筑算力必然離不開服務器的建設。作為全球頂級的人工智能/高性能計算服務器制造商和解決方案提供商,Supermicro公司日前向電子發(fā)燒友網(wǎng)表示,新業(yè)務合約有很大一部分來自人工智能/高性能計算領域,而且許多與ChatGPT有關。
Supermicro高管表示,人工智能界并不知道未來還會遇到多少計算密集型問題。以GPT-3為例,它需要323 Zetta FLOPS的算力和1750億個參數(shù)來訓練模型,更需要龐大的算力來執(zhí)行推理工作。更加智能的GPT-4將會有更多的參數(shù),有可能達到一萬億甚至更多。
為了運轉(zhuǎn)這樣的大模型和大規(guī)模參數(shù),如何有效運用服務器顯得十分重要,這關乎服務器的性價比選擇。Supermicro公司高管說到,當大量的GPU服務器集群起來時,人工智能/高性能計算應用的每一微秒都很重要。Supermicro設計開發(fā)了各種不同架構(gòu)的GPU服務器,提升了CPU和GPU之間或從GPU到GPU的數(shù)據(jù)傳輸速度。通過合理選擇系統(tǒng)SKU,解決方案的設計可以將每個CPU/GPU核心利用到極致。從邊緣到云,從訓練到推理,當前市面上所需的人工智能/高性能計算應用,Supermicro都可以提供全方位的GPU服務器,能讓客戶充分利用計算資源上花費的每一分錢。
更大的服務器存儲空間
隨著CPU、GPU和內(nèi)存技術的發(fā)展,現(xiàn)代計算集群處理數(shù)據(jù)的速度和數(shù)量不斷增加,因此有必要增強存儲性能,以便將數(shù)據(jù)饋送給應用時不會形成減緩整個系統(tǒng)的速度的瓶頸。
最近,Supermicro推出了超高性能、高密度PB級All-Flash NVMe服務器新機型。更新產(chǎn)品系列中初步推出的產(chǎn)品將在1U 16槽機架式安裝系統(tǒng)中支持高達1/2 PB的儲存空間,隨后的產(chǎn)品則將在2U 32槽機架式安裝系統(tǒng)中為Intel和AMD PCIe Gen5平臺提供1 PB儲存空間。
Supermicro高管表示,Supermicro的Petascale All-Flash服務器提供業(yè)界領先的存儲性能和容量,可以減少滿足熱存儲和溫存儲要求所需的機架式系統(tǒng)數(shù)量,并通過諸多功能特點降低總體擁有成本。
具體來說,容量擴展,更廣泛的PCB有助于實現(xiàn)更靈活的NAND芯片布局;性能擴展,可擴展連接器設計,多鏈路寬度(x4、x8、x16),支持不同電源配置;熱效率,散熱和制冷管理改進;面向未來,通用連接器適用于各種尺寸規(guī)格,可以為未來幾代PCIe提供更加強大的信號完整性;解決方案范圍,各種功率配置(20W-70W),適用于更高容量/性能的固態(tài)硬盤。
“安裝了速度更快的固態(tài)硬盤之后,系統(tǒng)的平衡就變得更加重要。Supermicro擁有全新的NUMA平衡對稱架構(gòu),可以提供到驅(qū)動器的最短信號路徑、到存儲器的帶寬平衡和靈活的網(wǎng)絡選項,從而降低時延。最重要的是,對稱設計還有助于確保整個系統(tǒng)的氣流暢通無阻,因此可以使用更加強大的處理器。”Supermicro高管說道。
桌面型GPU兼顧AI與液冷散熱
CPU/GUP/xPU也構(gòu)成了系統(tǒng)設計的熱量挑戰(zhàn),各種處理器消耗的功率不斷攀升,另一方面,科研/醫(yī)療設施/金融/石油和天然氣企業(yè)需要人工智能/高性能計算來提高其專業(yè)競爭力。在這些企業(yè)中,有很多需要在員工工作的地點設置工作站或本地服務器。
基于這樣的需求,Supermicro推出功能強大、安靜且節(jié)能的NVIDIA加速人工智能(AI)開發(fā)平臺系列當中的首款裝置。全新的AI開發(fā)平臺SYS-751GE-TNRT-NV1是一款應用優(yōu)化的系統(tǒng),在開發(fā)及運行AI軟件時表現(xiàn)尤其出色。此外,這個性能強大的系統(tǒng)可以支持小團隊里的用戶同步運行訓練、推理和分析等工作負載。
獨立的液冷功能可滿足四個NVIDIA? A100 Tensor Core GPU和兩個第4代Intel Xeon可擴展處理器的散熱需求,在發(fā)揮完整性能的同時提高整體系統(tǒng)效率,并實現(xiàn)了在辦公環(huán)境下的安靜(約30dB)運行。
對于散熱的考量,Supermicro高管認為搭載NVIDIA A800等強大的協(xié)加速器、且聲壓級介于30~45分貝的工作站,必須采用液冷解決方案才能滿足這一需求。冷板式液冷在市場上經(jīng)過了十多年的考驗,目前其成熟度和可靠性已經(jīng)達到了數(shù)據(jù)中心大規(guī)模部署的水平。
創(chuàng)新技術驅(qū)動成長
早前,Supermicro就提出了觀察到的七大創(chuàng)新技術,他們包括高性能350W CPU和700W GPU、處理速度更快的DDR5內(nèi)存、第五代PCI-E 5.0技術、Compute Express Link(CXL,開放式互聯(lián)標準)、400G高速網(wǎng)絡、新型固態(tài)硬盤和液冷技術。
簡言之就是更高的功耗和更快的數(shù)據(jù)傳輸速度。這就需要優(yōu)化功率效率、解決熱量挑戰(zhàn)、加強第五代PCIe、DDR5、高速網(wǎng)絡、無阻塞系統(tǒng)架構(gòu)設計和部署等。
Supermicro高管指出,這些創(chuàng)新技術背后的一個共同點是熱量調(diào)度。更快的處理器頻率、更多的計算核心、更高速的網(wǎng)絡都會產(chǎn)生更多的熱量,這些熱量必須輸送到數(shù)據(jù)中心之外。他表示,正如我們預計的技術趨勢和產(chǎn)品路線圖所示,當前和新一代人工智能/高性能計算服務器采用的熱量解決方案必須比目前的空氣冷卻更加高效。
展望已經(jīng)到來的AI爆發(fā)的時代,ChatGPT的需求日益增長,不僅推高了服務器的銷量,而且還推動新技術通過大規(guī)模部署而被普遍接納的機會。GPT提供的服務包括語言翻譯、聊天機器人、內(nèi)容生成、語言分析、語音輔助等等。
要實現(xiàn)人工智能系統(tǒng)的所有關鍵技術,就需要足夠快速的服務器,并通過復雜的架構(gòu)、用于維護工作的液冷管布置等將其聯(lián)網(wǎng)。這些專業(yè)技術知識意味著解決方案將不再作為一個個的服務器提供。完整的解決方案部署更像是一個具有機架級就緒水平的即插即用解決方案。
Supermicro將ChatGPT視為服務器市場增長的關鍵驅(qū)動力,未來我們會看到GPT服務的更多創(chuàng)新型用例。Supermicro已準備好面對這個趨勢,始終保持在AI服務器技術前沿,并提供創(chuàng)新的解決方案,使得客戶能夠加速他們的AI應用規(guī)劃,同時優(yōu)化總體擁有成本并通過綠色計算最大限度地減少對環(huán)境的影響。
-
服務器
+關注
關注
12文章
9129瀏覽量
85338 -
AI
+關注
關注
87文章
30759瀏覽量
268903 -
Supermicro
+關注
關注
0文章
29瀏覽量
9298
發(fā)布評論請先 登錄
相關推薦
算力基礎篇:從零開始了解算力
中科曙光入選2024算力服務產(chǎn)業(yè)圖譜及算力服務產(chǎn)品名錄
算力服務器為什么選擇GPU

AI高算力服務器散熱,需要用到哪些導熱界面材料?

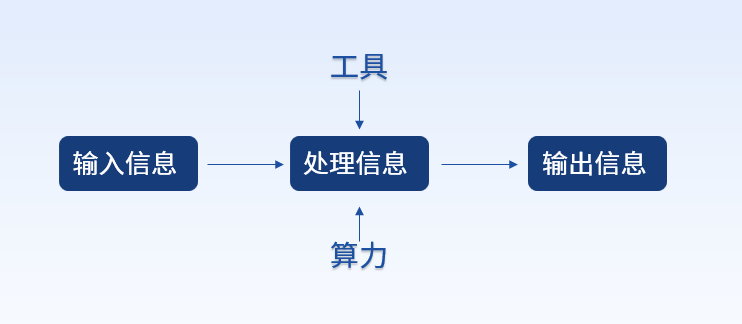
引領柔性算力新風潮,加速企業(yè)數(shù)智轉(zhuǎn)型首選服務器就是它
智能算力存在缺口,AI服務器市場規(guī)模持續(xù)提升
弘信電子簽訂算力服務器產(chǎn)品銷售合同
算力十問:超算智算,通算及算存比
解鎖未來,華為云耀云服務器 X 實例引領柔性算力新時代
256Tops算力!CSA1-N8S1684X算力服務器

華為中國合作伙伴大會2024 | 軟通動力全面布局算力服務







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論