 億級別大表拆分心路歷程
億級別大表拆分心路歷程
# 前言
筆者是在兩年前接手公司的財務系統的開發和維護工作。在系統移交的初期,筆者和團隊就發現,系統內有一張5000W+的大表。
跟蹤代碼發現,該表是用于存儲資金流水的表格,關聯著眾多功能點,同時也有眾多的下游系統在使用這張表的數據。
進一步的觀察發現,這張表還在以每月600W+的數據持續增長,也就是說,不超過半年,這張表會增長到1個億!
這個數據量,對于mysql數據庫來說是絕對無法繼續維護的了,因此在接手系統兩個月后,我們便開起了大表拆分的專項工作。(兩個月時間實際上主要用來熟悉系統、消化堆積需求了)
# 拆表前系統狀態
涉及到流水表流水的接口超時頻發,部分接口基本不可用
每日新增流水緩慢,主要是插入數據庫的時候非常慢
單表占用空間過大,DBA的數據庫監控經常報警
無法對表進行變更,任何alter操作都會引起主從的高延遲和長時間鎖表
# 拆表的目標
將流水大表數據拆分至各個分表,保證每張分表數據在1000W左右(經驗上看單表1000W的量對mysql來說沒啥壓力)
在拆表的前提下,針對不同接口的查詢條件進行優化,保證各個對外、對內接口的可用性。徹底殺死mysql慢查詢。
# 難點分析
該表的數據可以說是整個財務系統最基礎的數據,相關功能和下游系統非常多。這要求開發、測試和上線流程必須極其嚴密,任何小失誤都會引起大問題。
涉及的場景非常多。統計下來,一共有26個場景,需要改造32個mapper方法,具體需要改造的方法就更加無計其數了。
數據量非常大,遷移數據的過程必須保證系統穩定。
用戶較多且功能重要。分表功能上線時,必須盡量壓縮系統無法使用時長,同時需要保證系統可用性。這要求團隊必須設計完整可靠的上線流程、數據遷移方案、回滾方案、降級策略。
上文提到,表的拆分勢必帶來部分接口的變化,接口的變化又會帶來其他系統的改造。如何推動其他系統進行改造,如何協調多方合作的開發、測試和上線是另一個難點。
# 整體過程
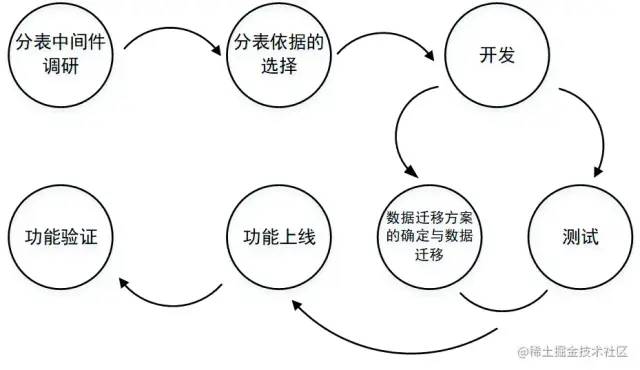
# 具體細節
分表中間件調研
分表插件:采用sharding-jdbc作為分表插件。
其優勢如下:
1、支持多種分片策略,自動識別=或in判斷具體在哪張分表里。
2、輕量級,作為maven依賴引入即可,對業務的侵入性極低。
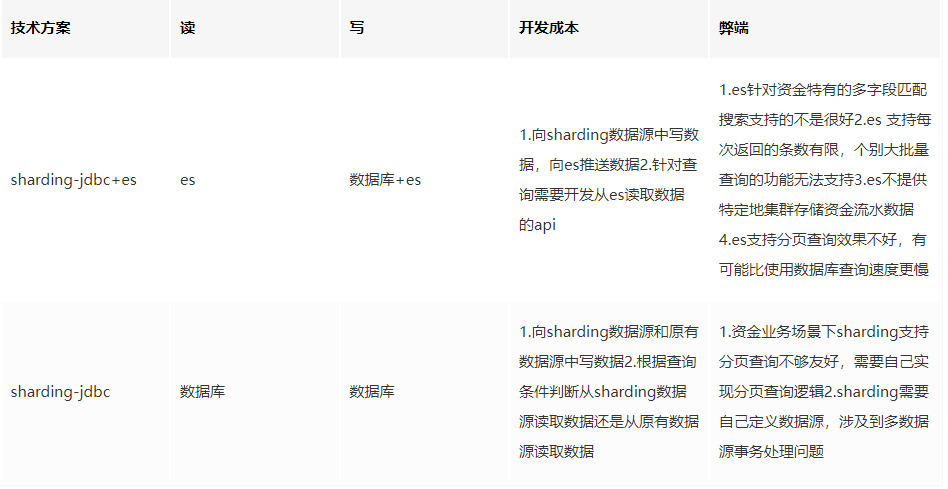
為提升查詢速度,在整個項目的初期,團隊成員考慮引入ES存儲流水以提升查詢速度。
經過與ES維護團隊的兩輪討論,發現公司提供的ES服務對于我們的業務場景并不匹配(見表),經過反復考量,最終我們放棄了引入ES的計劃,直接從數據庫查詢數據,采用每張表設置一個查詢線程的方式提升查詢效率。
分表依據的選擇
分表的方式有很多種,有縱向分表,有橫向分表,有分為固定的幾個表存儲然后取模進行表拆分等等。總的來說,適合我們具體業務的分表方式只有橫向分表。
因為對于資金流水這種特殊數據來說,是不能清理數據的,那么縱向分表和拆成固定的幾個表都不能解決單表數據無限膨脹的問題。而橫向分表,可以把每張表的數據量恒定,到一定時間后可以進行財務數據歸檔。
分表的依據一般都是根據表的某個或者某幾個字段進行拆分,最終其實是對數據和業務分析綜合出來的結果。總的來說,原則有這幾個:
盡可能選擇查詢條件里最常出現的字段,這樣能夠減少方法改造的工程
需要考慮根據某個字段拆分數據是否能夠均勻分布,是否能夠滿足單表1000W左右的要求
該字段必須是必現字段,不允許出現空值
綜合分析我們的數據以及業務需要,“交易時間”這個分表依據就呼之欲出了。
首先,這個字段作為流水最重要的字段之一一定會出現;
第二,如果按照交易月份進行拆表,每張表大概也就是600W-700W的數據;
最后,有70%的查詢都附帶“交易時間”作為查詢條件。
技術難點
多數據源事務問題
sharding-jdbc在使用的時候是需要用自己的獨立數據源的,那么就難免出現多數據源事務問題。
這個我們通過自定義注解,自定義切面開啟事務,通過方法棧逐層回滾or提交的方式解決的。出于保密原則,具體代碼細節不再展開。
多表的分頁問題
拆表一定會引起分頁查詢的難度增加。由于各個表查出來的數據量不等,原始的sql語句limit不再適用,需要設計一個新方法便捷的獲取分頁信息。
在此介紹一個分頁的思路供大家參考(團隊共同的成果,筆者不敢私自占有):
綜合考慮業務實際與開發的復雜程度,項目團隊決定在出現跨表查詢的情況下,每一張表采用一個線程進行查詢,以提高查詢效率。
這個方案的難點在于分頁規則的轉換。例如,頁面傳入的offset和pageSize分別為8和20。各分表中符合條件的數量分別為10,10,50。那么我們需要將總的分頁條件轉化為三個分表各自的分頁條件,如圖
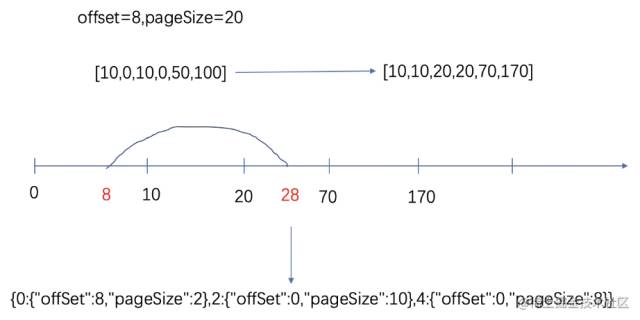
通過上圖可以看到,大分頁條件(offset=8,pageSize=20),轉換為(offset=8,pageSize=2),(offset=0.pageSize=10),(offset=0,pageSize=8)三個條件。
整個計算過程如下:
1) 多線程查詢各個分表中滿足條件的數據數量
2) 將各個表數量按照分表的先后順序累加,形成圖 8的數軸
3) 判斷第一條數據和最后一條數據所在的表
4) 除第一條和最后一條數據所在表外,其他表offset=0,pageSize=總數量
5) 計算第一條數據的offset,pageSize
計算最后一條數據的pageSize,同時將該表查詢條件的offset設置為0
數據遷移方案
在數據遷移前,團隊討論過兩套遷移方案:
1)請DBA遷移數據;
2)手寫代碼遷移數據,他們各有自己的優缺點:

綜合考慮時間成本和對線上數據庫的影響,團隊決定采用兩種方案結合的方式:
交易時間為三個月前的冷數據,由于更新幾率不大,采用代碼的方式遷移,人為控制每次遷移數量,少量多次,螞蟻搬家;
交易時間為三個月內的熱數據,由于會在上線前頻繁出現更新操作,則在上線前停止寫操作,而后由DBA整體遷移。這樣將時間成本平攤到平時,上線前只有約2個小時左右遷移數據時系統無法使用。
同時,除了最后一次DBA遷移數據外,能夠人為控制每次遷移的數據量,整體避免數據庫實例級別的高延遲。
整體上線流程
為保證新表拆分功能的穩定性和大表下線的穩定,團隊將整個項目分為三個階段:
第一階段:建立分表,大表數據遷移分表,線上數據新表老表雙寫,所有查詢走分表(驗證觀察)
第二階段:停止寫老數據表,其他業務直連數據庫改為資金提供對外接口(驗證觀察)
第三階段:大表下線
# 總結
應再進一步調研分表相關中間件。由于項目分表依據的特殊性,導致sharding-jdbc的很多功能無法利用,其對于簡化查詢邏輯的幫助低于預期。并且sharding-jdbc獨立數據源的特性,引發了多數據源事務問題,反而增加了開發的工作量。
多線程需要仔細分析線程池核心線程的大小,同時分析多線程池同時存在的時候是否會引起核心線程數過多,避免機器線程打滿。
如果是一個已有的項目,在進行分表改造時,一定要將各種場景都羅列清楚,將各個場景細化到程序中的每個類、每個方法中,將所有業務場景都覆蓋到。
在遷移歷史數據時,一定要做好遷移數據方案,以及應對出現數據不一致時的處理方案。要綜合考慮時間成本、數據準確性、對線上功能的影響等諸多因素。
在上線一個比較復雜的方案時,一定要提前設計好回滾方案和降級措施,能夠極大保證穩定性。
# 說點兒題外話
為啥說想說點兒題外話呢,主要是對這次延續了5個多月的項目有感而發。項目進行過程中,難免會與其他系統的維護團隊有工作上的交集,有需要其他團隊配合的地方。
這個時候非常考驗程序員的溝通能力,最優秀的程序員能夠通過話術把對方拉到自己的陣線當中,讓對方感到這項工作對自己也是有好處的。這樣能夠讓對方心甘情愿的配合你的工作,達到雙贏的目的。
如果程序設計和學習能力是程序員的硬實力,那溝通技巧就是程序員的軟實力,硬實力能夠保障你的下線,而決定上線的恰恰是軟實力。
因此很多程序員不注重溝通技巧的培養,其實是相當于瘸腿的,畢竟現在憑單打獨斗是不大可能做出事情的。
另外,至少對于我們單位來說,對后端程序員的綜合素質其實要求最高。后端程序員集業務、技術于一身。需要有比較強的業務把控能力,還要有過硬的技術素質。
同時,大多數工作的主owner是后端,一般都是后端程序員把控前端、后端、QA的開發節奏,協調好各個時間點,做好風險反饋。
這就要求后端程序員既要懂業務,還要懂技術,還需要有一定的管理能力。這其實對人的鍛煉還是很可觀的。
審核編輯 :李倩
-
數據
+關注
關注
8文章
7006瀏覽量
88944 -
數據庫
+關注
關注
7文章
3794瀏覽量
64362 -
MySQL
+關注
關注
1文章
804瀏覽量
26533
原文標題:麻了!億級別大表拆分心路歷程
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
今年就有L5級別自動駕駛?馬斯克表示有信心
解決Labview報表問題的一般思路
【睿賽德 RW007 WiFi 模塊試用連載】RW007模塊調試心路歷程
一個AVR新手藍牙模塊調試的心路歷程簡介遇到的問題
學習單片機的心路歷程分享
手機界最防水機型:蘋果8防水達IP68級別
3DMark的可變著色率測試加入Tier 2級別
元一能源從分布式光伏業務到綜合能源業務的心路歷程
黃仁勛分享作為工程師的心路歷程
一個AVR新手藍牙模塊調試的心路歷程


編程的技術|藝術|術術(上篇)骨灰級程序員的心路歷程
億級別大表拆分——記一次分表工作的心路歷程





 工商網監
工商網監
評論