") Food2K:大規(guī)模食品圖像識別
Food2K:大規(guī)模食品圖像識別
美團基礎研發(fā)平臺視覺智能部與中科院計算所展開科研課題合作,共同構(gòu)建大規(guī)模數(shù)據(jù)集Food2K,并提出漸進式區(qū)域增強網(wǎng)絡用于食品圖像識別,相關研究成果已發(fā)表于T-PAMI 2023。
本文主要介紹了數(shù)據(jù)集特點、方法設計、性能對比,以及基于該數(shù)據(jù)集的遷移實驗等方面的內(nèi)容,并對Food2K未來的工作進行了展望。希望本文能為從事相關工作的同學帶來一些幫助或者啟發(fā)。

論文標題: Large Scale Visual Food Recognition 論文鏈接: https://arxiv.org/pdf/2103.16107.pdf
一、引言
美團基礎研發(fā)平臺視覺智能部與中科院計算所于2020-2021年度展開了《細粒度菜品圖像識別和檢索》科研課題合作,本文系雙方聯(lián)合在IEEE TPAMI2023發(fā)布論文《Large Scale Visual Food Recognition》 (Weiqing Min, Zhiling Wang, Yuxin Liu, Mengjiang Luo, Liping Kang, Xiaoming Wei, Xiaolin Wei, Shuqiang Jiang*) 的解讀。IEEE TPAMI全稱為IEEE Transactions on Pattern Analysis and Machine Intelligence, 是模式識別、計算機視覺及機器學習領域的國際頂級期刊, 2022年公布的影響因子為24.314。

食品計算[1]因能夠支撐許多食品相關的應用得到越來越廣泛的關注。食品圖像識別作為食品計算的一項基本任務,在人們通過辨認食物進而滿足他們生活需求方面發(fā)揮著重要作用。這也是許多健康應用中的重要步驟,如食品營養(yǎng)理解[2,3]和飲食管理[4]。此外,食品圖像識別是細粒度視覺識別的一個重要分支,具有重要的理論研究意義。
現(xiàn)有的工作主要是利用中小規(guī)模的圖像數(shù)據(jù)集進行食品圖像識別,如ETH Food-101[5]、Vireo Food-172[6]和ISIA Food- 500[7]。由于食品類別和圖像數(shù)量的不足,不足以支撐更復雜更先進的食品計算統(tǒng)計模型的建立。考慮到大規(guī)模數(shù)據(jù)集已成為許多常規(guī)圖像分類和理解任務發(fā)展的關鍵推動因素,因此食品計算領域也迫切需要一個大規(guī)模的食品圖像數(shù)據(jù)集來開發(fā)先進的食品視覺表示學習算法,從而進一步支撐各種食品計算任務,如跨模態(tài)食譜檢索和生成[8,9]。為此,我們構(gòu)建了一個新的大規(guī)模基準數(shù)據(jù)集Food2K。該數(shù)據(jù)集包含1,036,564張食品圖像和2,000類食品,涉及12個超類(如蔬菜、肉類、燒烤和油炸食品等)和26個子類別。與現(xiàn)有的數(shù)據(jù)集(如ETH Food-101)相比,F(xiàn)ood2K在類別和圖像數(shù)量均超過其一個數(shù)量級。除了規(guī)模之外,我們還進行了嚴格的數(shù)據(jù)清理、迭代標注和多項專業(yè)檢查,以保證其數(shù)據(jù)的質(zhì)量。
在此基礎上,我們進一步提出了一個面向食品圖像識別的深度漸進式區(qū)域增強網(wǎng)絡。該網(wǎng)絡主要由漸進式局部特征學習模塊和區(qū)域特征增強模塊組成。前者通過改進的漸進式訓練方法學習多樣互補的局部細粒度判別性特征(如食材相關區(qū)域特征),后者利用自注意力機制將多尺度的豐富上下文信息融入到局部特征中,進一步增強特征表示。本文在Food2K上進行的大量實驗證明了所提出方法的有效性,并且在Food2K上訓練的網(wǎng)絡能夠改進各種食品計算視覺任務的性能,如食品圖像識別、食品圖像檢索、跨模態(tài)菜譜-食品圖像檢索、食品檢測和分割等。我們期待 Food2K及在Food2K上的訓練模型能夠支撐研究者探索更多的食品計算新任務。本論文相關的數(shù)據(jù)集、代碼和模型可從網(wǎng)站下載:http://123.57.42.89/FoodProject.html。
二、Food2K數(shù)據(jù)集
Food2K同時包含西方菜和東方菜,在食品專家的幫助下,我們結(jié)合現(xiàn)有的食品分類方法建立了一個食品拓撲體系。Food2K包括12個超類(如“面包”和“肉”),每個超類都有一些子類別(如“肉”中的“牛肉”和“豬肉”),每種食品類別包含許多菜肴(如“牛肉”中的“咖喱牛肉”和“小牛排”),如圖1所示。
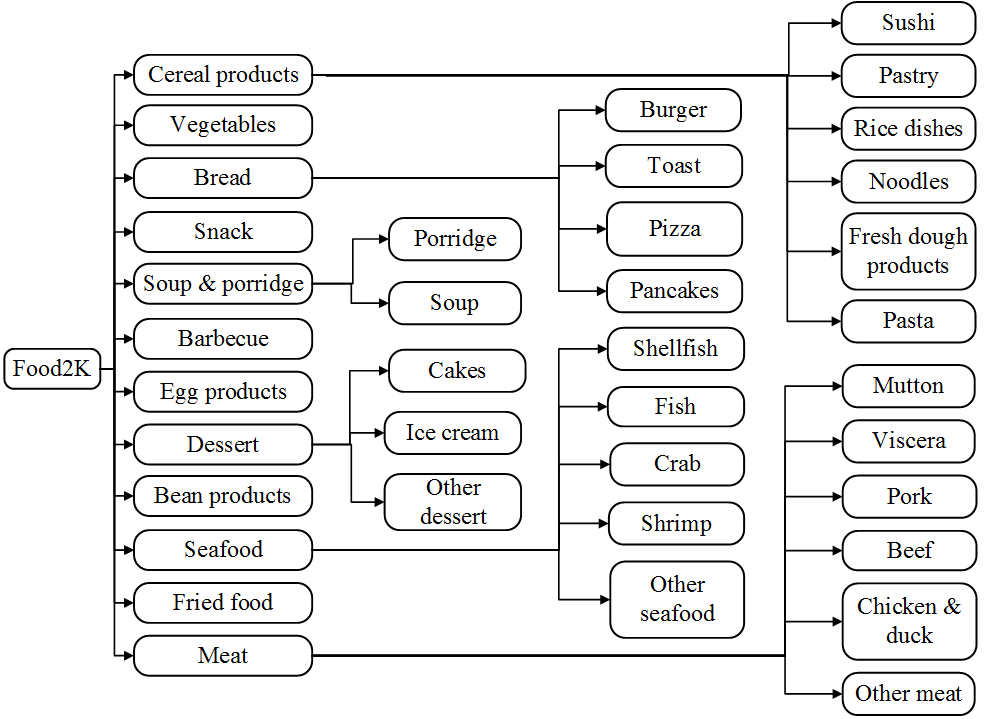
圖1 Food2K分類體系
圖2展示了每個食品類別的圖像數(shù)量,F(xiàn)ood2K中每個類別的圖像數(shù)量分布在[153,1999]之間不等,呈現(xiàn)出明顯的長尾分布現(xiàn)象,與類別不平衡性。
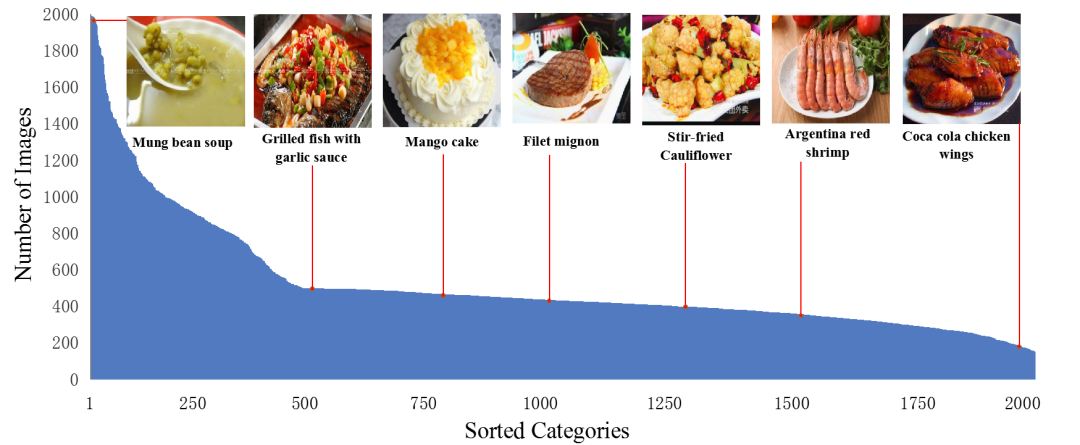
圖2 Food2K各類別圖像數(shù)量分布
圖3展示了Food2K與現(xiàn)有食品圖像識別數(shù)據(jù)集的圖像數(shù)量對比,可以看到Food2K在類別和圖像數(shù)量上都遠超過它們。
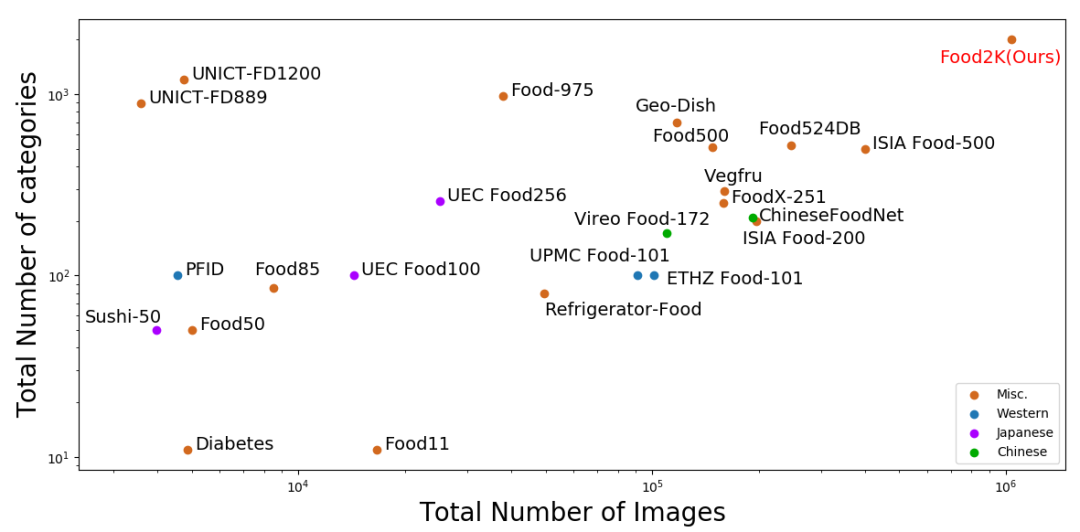
圖3 Food2K與其它食品識別數(shù)據(jù)集圖像數(shù)量對比
除此之外,F(xiàn)ood2K還具有以下特征:
1)Food2K涵蓋了更多樣化的視覺外觀和模式。不同食材組合、不同配飾、不同排列等都會導致同一類別的視覺差異。舉例來說,新鮮水果沙拉因其不同的水果成分混合而呈現(xiàn)出不同的視覺外觀。這些食品的獨特特征導致了更高的類內(nèi)差異,使大規(guī)模的食品圖像識別變得困難。
2)Food2K包含更細粒度的類別標注。以“Pizza”為例,一些經(jīng)典的食品數(shù)據(jù)集,如Food-101,只有較粗粒度的披薩類。而Food2K中的披薩類則進一步分為更多的類別。不同披薩圖像之間的細微視覺差異主要是由獨特的食材或同一食材的粒度不同引起的,這也導致了識別的困難。所有這些因素使Food2K成為一個新的更具挑戰(zhàn)性的大規(guī)模食品圖像識別基準,可以視為食品計算領域的“ImageNet”。
三、方法
食品圖像識別需要挖掘食品圖像的本身特點,并同時考慮不同粒度的圖像特征進行識別。通過觀察我們發(fā)現(xiàn),食品圖像有著明顯的全局特征和局部特征。
首先,食品圖像明顯有著全局的外觀、形狀和其他結(jié)構(gòu)方面的特征,且該特征存在較大的類內(nèi)差異。如圖4的奶油核桃餅明顯有著變化不一的形狀,炒面有著豐富多樣的紋理。雖然當前已經(jīng)有很多方法來解決這一問題,但大多數(shù)方法主要集中在提取某種類型的特征,而忽略了其他類型的特征。

圖4 食品圖像的全局特征與局部特征
其次,食品圖像中有細微差別的細節(jié)信息,部分細節(jié)信息是其關鍵的局部特征。在許多情況下,現(xiàn)有的神經(jīng)網(wǎng)絡無法很好地挖掘那些具有判別性的細節(jié)特征。如圖4中第三欄所示,僅僅依靠全局特征是不足以區(qū)分玉米羹和雞蛋羹,必須進一步挖掘其食材信息的不同(圖中黃色框內(nèi))。因此如何更好地挖掘食品圖像的全局特征和局部特征對于提升食品圖像特征表達能力尤為重要。
此外,如圖5所示,不同的食材在不同的食品類別中所占的權(quán)重也是不一樣的,香菜在香菜拌牛肉中是一個關鍵性食材,必不可少,但是在老醋海蜇這道菜中僅僅是一個配料,并不總是出現(xiàn)在該類別的所有圖像中。因此需要挖掘局部特征之間的關系,突出重點局部特征。進而提高食品識別的準確率。

圖 5 不同食材在不同的食品圖像中所占比重不同
針對上述這些特點,本文設計了深度漸進式區(qū)域特征增強網(wǎng)絡,它可以共同學習多樣化且互補的局部和全局特征。該網(wǎng)絡結(jié)構(gòu)如圖6所示,該網(wǎng)絡主要由三部分組成:全局特征學習模塊、漸進式局部特征學習模塊和區(qū)域特征增強模塊。
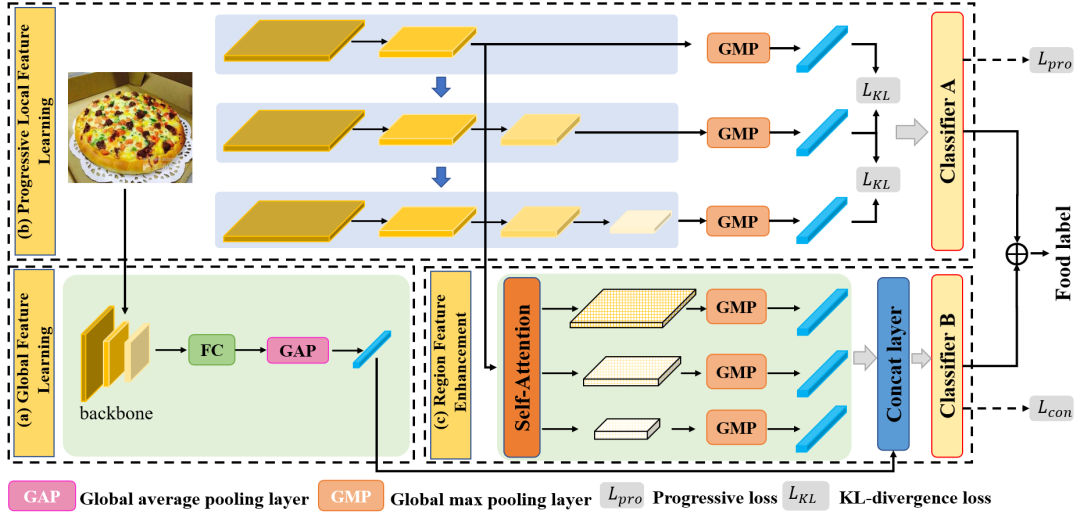
圖6 深度漸進式區(qū)域增強網(wǎng)絡框架圖
其中,漸進式局部特征學習主要采用漸進式訓練策略來學習互補的多尺度細粒度的局部特征,例如不同的食材相關信息。區(qū)域特征增強使用自注意力機模塊將更豐富的多尺度上下文信息合并到局部特中,以增強局部特征表示。然后,我們通過特征融合層將增強的局部特征和來自全局特征學習模塊的全局特征融合到統(tǒng)一的特征中。
此外,在模型訓練時,本文逐步漸進式地訓練網(wǎng)絡的不同階段,最后將訓練整個網(wǎng)絡,并在此過程中引入散度以增加各個階段之間的差異性,以捕獲更豐富多樣化的局部信息。在推理階段,考慮到每個階段的輸出特征和融合后的特征之間的互補性,我們將它們的預測結(jié)果結(jié)合起來得到最終分類得分。接下來將詳細介紹各個模塊的計算原理。
全局-局部特征學習
食品識別可以看作是一個層次化的任務,在不同超類下的食品圖像有著明顯可分的視覺差異,因此可以基于他們的全局特征進行識別。但是在同一超類下,不同子類的食品圖像之間的差異卻非常小。因此食品識別需要同時學習食品圖像的全局特征和局部特征。因此, 我們提取并融合了這兩個特征,此過程可以使用兩個子網(wǎng)絡分別提取食品圖像的全局和局部特征。這兩個子網(wǎng)絡可以是兩個獨立的網(wǎng)絡,但是本工作為了提高效率并減小模型參數(shù),本文中兩個子網(wǎng)絡共享基礎網(wǎng)絡的大部分層。
全局特征學習
對于全局特征學習,本文取最后一個卷積層的輸出,使用全局平均池化(Global Average Pooling, GAP)來提取全局特征: 其中為從主干網(wǎng)絡最后一個卷積層中提取的特征。
漸進式局部特征學習
局部特征子網(wǎng)絡旨在學習食品的區(qū)分性細粒度特征。由于食材和烹飪風格的多樣性,食品圖像的關鍵判別部分是多尺度和不規(guī)則的。作為本方法第一個創(chuàng)新點,我們提出了漸進式訓練策略來解決這個問題。在這種策略中,我們首先訓練具有較小感受野的網(wǎng)絡較低階段(可以理解為模型中較低的層),然后逐步擴大該局部區(qū)域范圍并引入新的層加入訓練。
這種訓練策略將迫使我們的模型提取更精細的判別性局部特征,例如與食材相關的特征。在此過程之后,我們從不同層提取特征以獲得多尺度的特征表示。具體來說,對于來自局部特征子網(wǎng)絡的每一層的輸出,其中u是網(wǎng)絡的不同階段。我們使用一個卷積層和一個全局最大池化層(Global Maximum Pooling,GMP)來得到它們的局部特征向量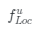 :
:
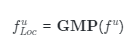
因此,該策略可以首先在網(wǎng)絡較淺的層中學習更穩(wěn)定的細粒度信息,然后隨著訓練的進行逐漸將注意力轉(zhuǎn)移到在較深的層中學習粗粒度信息。具體來說,當具有不同粒度的特征被送入網(wǎng)絡時,它可以提取出有判別性的局部細粒度特征,例如食材成分信息。然而,簡單地使用漸進式訓練策略不會得到多樣化的細粒度特征,因為通過漸進式訓練學習到的多尺度特征信息可能集中在食品圖像中相似的區(qū)域。
因此,作為本方法第二個創(chuàng)新點,我們引入KL散度對來自不同階段的特征進行離散化,以增加它們之間的差異性。通過最大化不同階段特征之間的KL散度值,可以迫使網(wǎng)絡模型在不同階段關注不同區(qū)域的多尺度特征,這有助于網(wǎng)絡捕獲盡可能多的細節(jié)信息。
具體來說,我們將訓練過程劃分為個步驟,每一步訓練前個階段,其中是網(wǎng)絡的總階段數(shù)。因為我們將在最后階段(也稱為特征融合階段)將融合所有的全局和局部特征,因此總步驟數(shù)為。在我們的方法中,對于漸進式訓練的每一步訓練的網(wǎng)絡不同層的輸出,使用對該輸出特征進行處理。由一個卷積層、一個批歸一化層和一個單元組成。然后我們可以得到局部特征表示。 此外,對于來自不同階段的這些多個局部特征, 我們利用散度來增加階段之間的差異,這有助于捕獲盡可能多的細節(jié)。對每兩個相鄰階段的輸出,計算散度的方式如下,其中散度的reduction設置為batchmean。
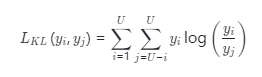
區(qū)域特征增強不同于一般的細粒度任務中的識別對象,食品圖像沒有固定的語義信息。現(xiàn)有的大部分食品識別方法直接挖掘這些判別性局部特征,忽略了局部特征之間的關系。因此,我們采用自注意力機制來學習不同局部特征之間的關系。該策略旨在捕獲特征圖中同時出現(xiàn)的食品特征。 具體來說,借鑒于 non-local interaction的操作,我們在同一個特征圖內(nèi)操作實現(xiàn)自注意力增強,并輸出與輸入同尺度的特征圖。我們首先提取所有個階段局部特征表示?,然后通過自注意力機制獲得增強后的特征,計算方式如下:
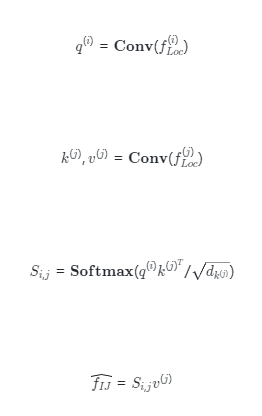
其中,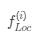 和
和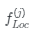 是?中位于i和j位置的像素特征基于此我們可以得到增強特征
是?中位于i和j位置的像素特征基于此我們可以得到增強特征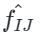 。最后我們將這些相同大小的增強后的特征圖融合起來,并使用卷積運算將它們轉(zhuǎn)換為相同的維度。最后我們可以得到??個局部特征
。最后我們將這些相同大小的增強后的特征圖融合起來,并使用卷積運算將它們轉(zhuǎn)換為相同的維度。最后我們可以得到??個局部特征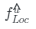 。通過這種策略我們的模型能夠使局部特征實現(xiàn)跨空間和尺度的信息交互。在訓練過程中,在獲得全局特征和局部特征后,我們在特征融合階段將它們?nèi)诤虾鬄樽罱K表示:
。通過這種策略我們的模型能夠使局部特征實現(xiàn)跨空間和尺度的信息交互。在訓練過程中,在獲得全局特征和局部特征后,我們在特征融合階段將它們?nèi)诤虾鬄樽罱K表示:
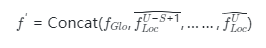
訓練和預測
在網(wǎng)絡優(yōu)化過程中,我們迭代更新網(wǎng)絡的參數(shù)。首先,我們利用各個階段的交叉熵損失來反向傳播以更新相應網(wǎng)絡的參數(shù)。在此過程中,當前階段的所有網(wǎng)絡參數(shù)都將被優(yōu)化, 即使它們在之前的階段已經(jīng)被更新過。然后在特征融合階段,我們利用另一個交叉熵損失函數(shù)來更新整個網(wǎng)絡的參數(shù)。 此外,我們的網(wǎng)絡以端到端的方式進行訓練。在漸進式訓練過程中,對于每個階段的輸出,我們采用以下交叉熵損失:
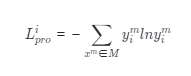
其中是一組訓練數(shù)據(jù),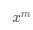 表示
表示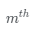 個樣本,
個樣本, 是對應的類別標簽。對于最后融合得到的特征表示,我們使用另一個交叉熵損失:
是對應的類別標簽。對于最后融合得到的特征表示,我們使用另一個交叉熵損失:
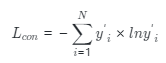
其中是預測標簽,是訓練樣本的總數(shù)。 此外,我們引入的散度作為一項損失加入到最終的損失函數(shù)中,以增加階段之間的差異性進而以捕獲更豐富的細節(jié)信息,所以最終損失函數(shù)為:
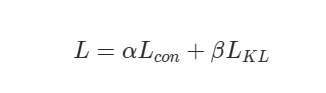
其中,α和β是平衡參數(shù)。 在模型推理階段, 來自最終特征融合征階段輸出的特征被輸入到分類器 B 中獲得對應的預測輸出。對于前幾個階段的輸出, 我們可以利用分類器 A 來預測相應的輸出值。其中分類器 A 由兩個全連接層和 Batchnorm 及 Elu 非線性單元組成。 考慮到不同階段的預測輸出和特征融合階段最終輸出之間的互補性, 我們可以將所有輸出組合在一起以提高識別性能。因此我們將所有階段的預測得分(包括最終得分) 相加, 以相同的權(quán)重來預測對應的食品類別:
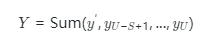
四、實驗
首先,我們在Food2k上對現(xiàn)有的食品識別方法和我們提出的方法進行了比較。然后,我們研究Food2K在食品識別、食品圖像檢索、跨模態(tài)菜譜-食品圖像檢索、食品檢測和食品分割五個食品計算任務上的泛化能力。
實驗驗證與分析
本文使用在 ImageNet 上預訓練的ResNet[10]作為基礎網(wǎng)絡。對于實驗性能評估,使用Top-1準確率(Top-1)和Top-5準確率(Top-5)對食品類別識別進行評估。
在Food2K上的性能實驗
表1展示了在Food2K上現(xiàn)有的食品識別方法和所提方法的性能比較。從表中可以看出,我們的方法在Top-1和Top-5準確率上分別高出主干網(wǎng)絡(ResNet) 2.24%和1.4%,以ResNet101為主干的網(wǎng)絡超過了現(xiàn)有的食品識別方法,取得了最佳的識別性能。這證實了結(jié)合漸進式訓練策略和自注意力來增強局部特征表示的優(yōu)勢。
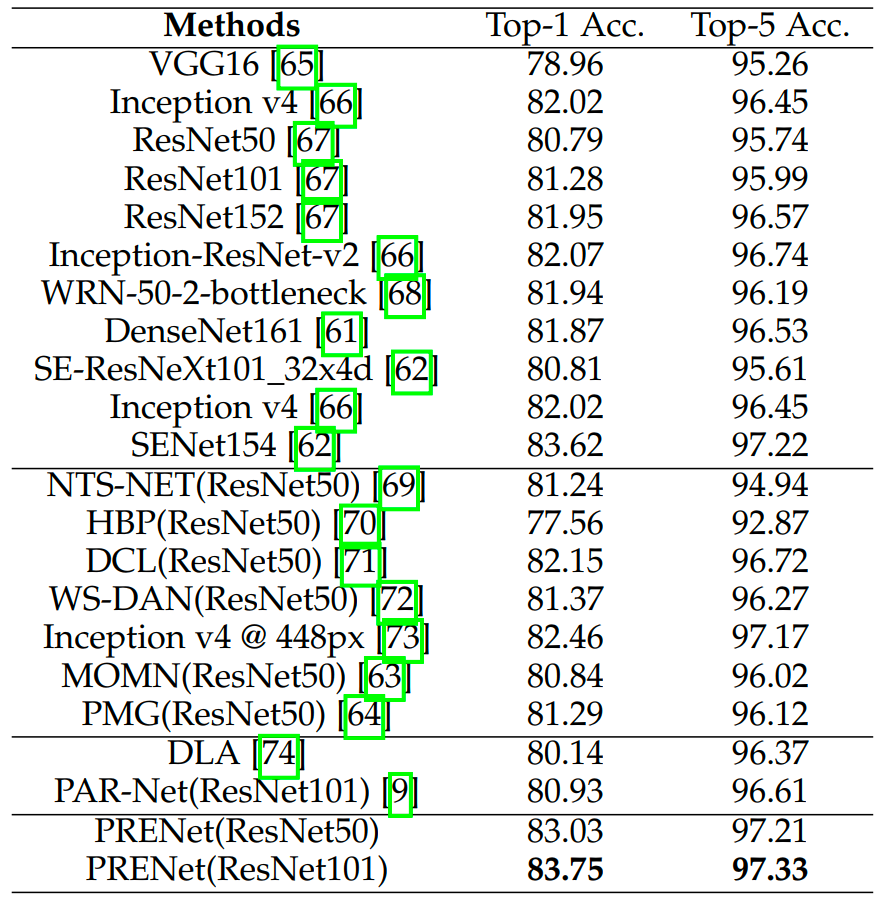
表1 現(xiàn)有方法在Food2K上性能對比
在Food2k上的消融實驗
本文在消融實驗中主要探討了以下幾個問題:
(1)網(wǎng)絡不同組件的有效性:從圖7(a)中可以看出,漸進式策略(PL)的引入能夠帶來識別性能增益,且與區(qū)域特征增強(RE)相結(jié)合后進一步提高了性能。這說明我們提出的PL+RE的學習策略能夠有效地學到更具判別性的局部特征。
(2)漸進式學習階段的數(shù)量U:從圖7(b)中可以看出,當U從1到3時,我們的方法在Food2K上分別取得了81.45%,82.11%和83.03%的Top-1分類準確率。模型的分類性能連續(xù)提高了0.66%和0.92%。然而,當U = 4時,精度開始下降。可能的原因是淺層網(wǎng)絡主要關注類別無關的特征。
(3)不同學習階段的效果:為了更好地驗證每個學習階段和最終的連接階段的貢獻,我們還通過分別使用每個階段的預測分數(shù)來進行評估。從圖7中可以看出,相比于使用單一階段進行預測,聯(lián)合每個階段的得分進行預測能夠帶來性能提升。此外,我們的方法將每個階段的預測分數(shù)和聯(lián)合特征的預測分數(shù)進行組合,能夠?qū)崿F(xiàn)最佳的識別性能。
(4)平衡參數(shù)α和β:我們還研究了公式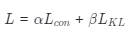 中平衡參數(shù)對性能的影響。我們發(fā)現(xiàn),當?
中平衡參數(shù)對性能的影響。我們發(fā)現(xiàn),當?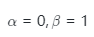 時,即總損失僅包括??散度時,此時模型無法收斂。當?
時,即總損失僅包括??散度時,此時模型無法收斂。當?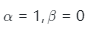 時,即僅使用交叉熵損失進行優(yōu)化,模型的性能明顯下降。當
時,即僅使用交叉熵損失進行優(yōu)化,模型的性能明顯下降。當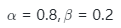 時,模型取得了最佳的識別性能,這說明聯(lián)合漸進式訓練和KL散度的策略能夠提高多樣化局部細節(jié)特征的學習能力。
時,模型取得了最佳的識別性能,這說明聯(lián)合漸進式訓練和KL散度的策略能夠提高多樣化局部細節(jié)特征的學習能力。
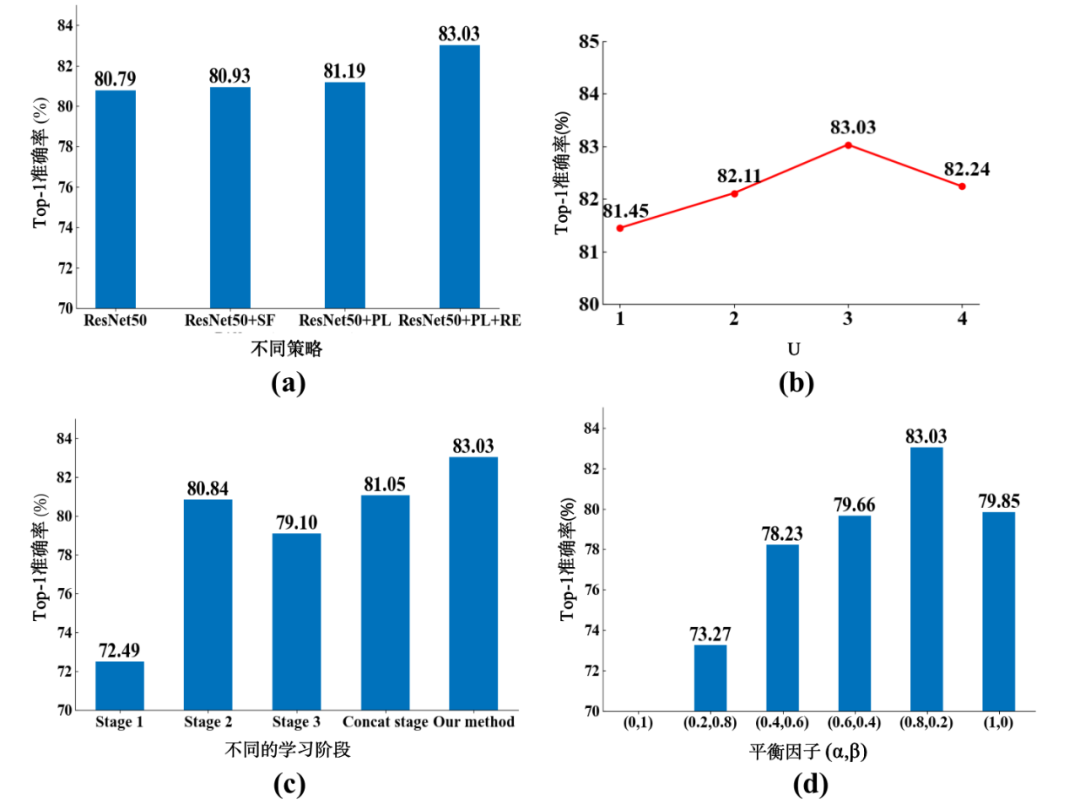
圖7 我們方法在Food2K上的消融實驗
可視化
我們使用Grad-CAM來進行可視化分析。如圖8所示,以“Wasabi Octopus”為例,基線方法僅能獲得有限的信息,不同的特征圖傾向于關注相似的區(qū)域。相比之下,我們的方法在第一階段更關注“Vegetable Leaf”,而第二階段主要關注“Octopus”。而在第三階段,我們的方法可以捕獲該食品的總體特征,因此全局和局部特征都被用于識別。

圖8 來自Food2K一些樣本的可視化結(jié)果
基于Food2K的泛化實驗
(1)食品圖像識別
我們評估了在Food2K上預訓練過的模型在ETH Food-101,Vireo Food-172和ISIA Food-500上的泛化能力。從表2中我們可以看出,使用Food2K進行預訓練后所有方法都取得了一定程度的性能提升,這說明我們的數(shù)據(jù)集在食品圖像識別任務上具有良好的泛化能力。
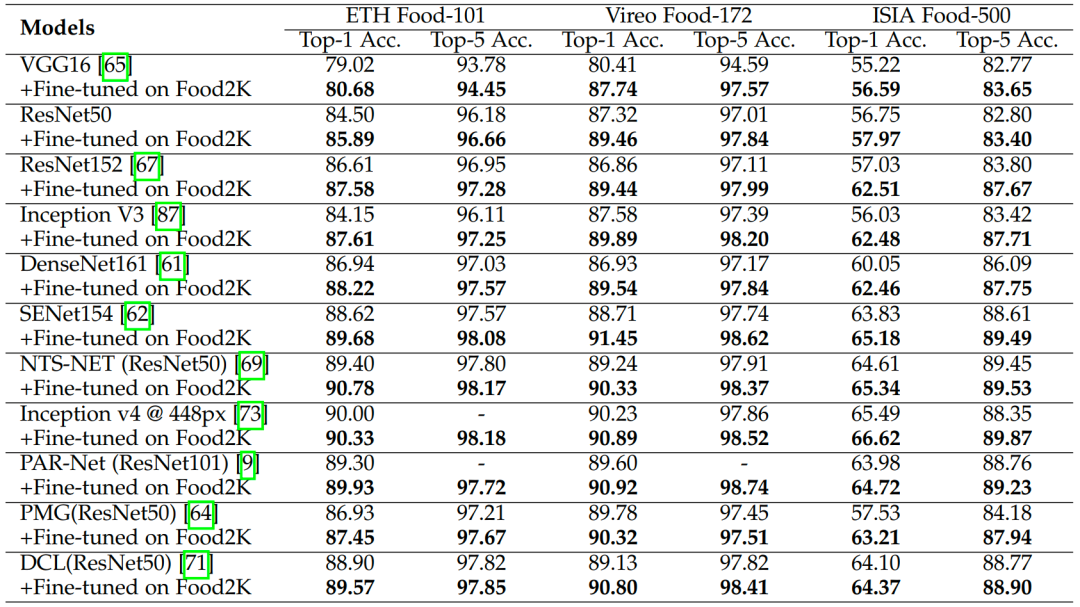
表2 基于Food2K微調(diào)的模型在食品圖像識別任務上的性能
(2)食品檢測
我們評估了Food2K數(shù)據(jù)集對食品檢測任務的泛化能力,評估任務為檢測食品托盤中的食品。為了進行比較,我們還對在ETH Food-101上進行預訓練的模型進行了評估。從表3中可以看出,使用Food-101和Food2K能夠提升所有方法的mAP和AP75指標,且Food2K所帶來的性能增益要超過Food-101。這說明我們的方法在食品檢測任務上表現(xiàn)出良好的泛化性能。
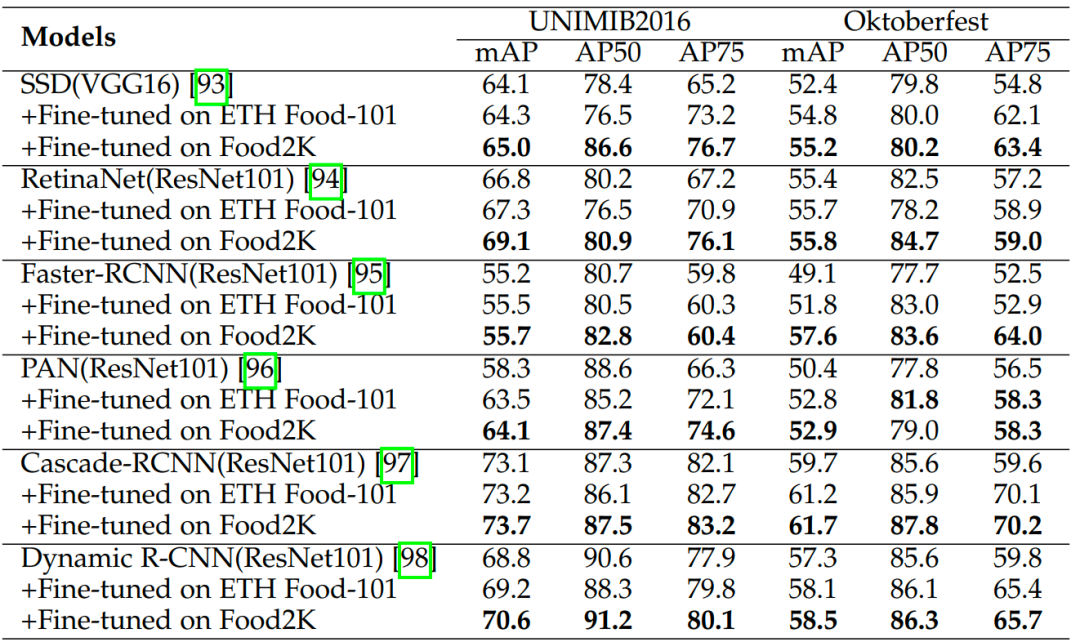
表3 基于Food2K和ETH Food-101微調(diào)的模型在食品檢測任務上的性能比較
(3)食品分割
我們還評估了Food2K在食品分割任務上的性能。從表4中可以看出,對于所有使用Food2K進行預訓練的模型均能帶來性能的提升。這證明了我們的數(shù)據(jù)集在分割任務上良好的泛化表現(xiàn)。
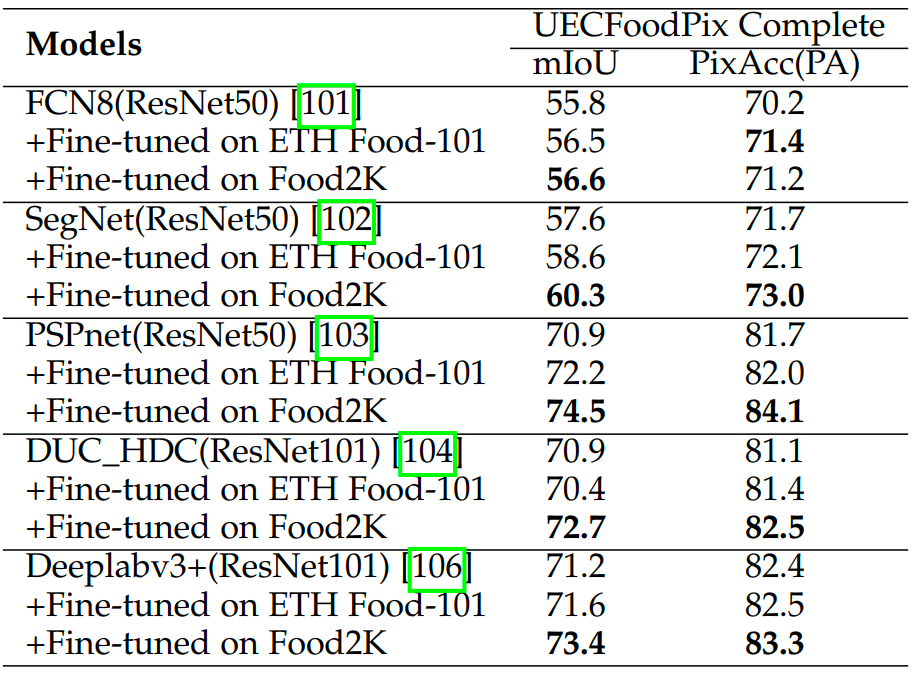
表4 基于Food2K和ETH Food-101微調(diào)的模型在食品分割任務上的性能比較
(4)食品圖像檢索
我們進一步在食品圖像檢索任務上驗證Food-2K的泛化能力。具體來說,我們在ETH Food-101、Vireo Food-172和ISIA Food-500數(shù)據(jù)集上實驗,并使用與前文相同的數(shù)據(jù)集劃分方式。測試集的每張圖片依次作為查詢項,其余的圖片作為檢索庫。我們分別使用交叉熵損失函數(shù)和以Contrastive loss和Triplet loss為代表的度量學習損失函數(shù)來微調(diào)ResNet101網(wǎng)絡,并使用mAP和Recall@1指標評估方法的性能。
表5的結(jié)果展示了在Food-2K數(shù)據(jù)集上預訓練后微調(diào)的網(wǎng)絡取得了不同程度的性能增益。具體來說,在Vireo Food-172數(shù)據(jù)集上取得了最優(yōu)性能,并在三個數(shù)據(jù)集上分別取得了4.04%, 5.28% 和4.16%的性能增益。值得注意的是,當使用額外的ETH Food-101數(shù)據(jù)集預訓練并在度量學習損失函數(shù)方法上微調(diào)的方法并沒有取得性能增益,但使用Food2K數(shù)據(jù)集預訓練仍然取得了性能增益,這是因為食品圖像檢索任務對目標數(shù)據(jù)集之間的差異較為敏感(ETH Food-101和Vireo Food-172),并間接表明來自Food2K的圖像類別和尺度的多樣性提升了食品圖像檢索任務的泛化性。
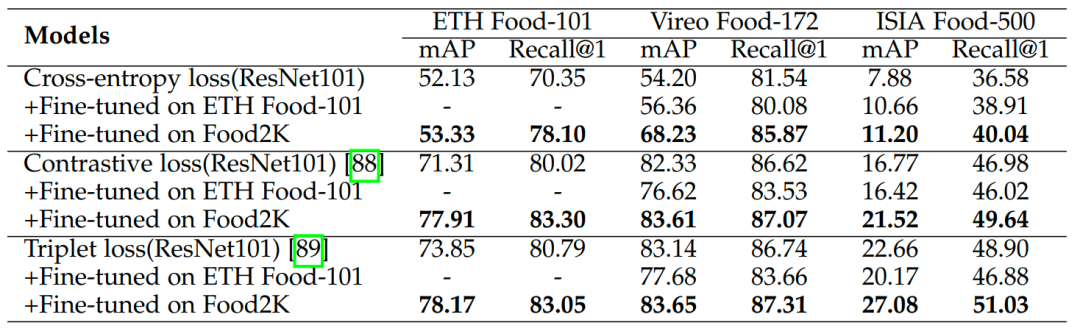
表5 基于Food2K和ETH Food-101微調(diào)的模型在食品圖像檢索任務上的性能比較
(5)跨模態(tài)菜譜-食品圖像檢索
我們還在跨模態(tài)菜譜-食品圖像檢索任務上進一步驗證Food2K的泛化能力。具體來說,我們在Recipe1M[11]數(shù)據(jù)集上驗證方法的性能,并使用與之相同的數(shù)據(jù)集劃分方法。與此同時,我們使用MedR和Recall@K指標來評估。表6展示了我們使用不同的網(wǎng)絡主干,并分別通過ImageNet、ETH Food-101和Food2K數(shù)據(jù)集預訓練的結(jié)果。結(jié)果發(fā)現(xiàn)使用ETH Food-101和Food2K數(shù)據(jù)集預訓練后在目標數(shù)據(jù)集上微調(diào)都取得了性能的增益,使用我們的Food-2K數(shù)據(jù)集取得了更大的性能增益。
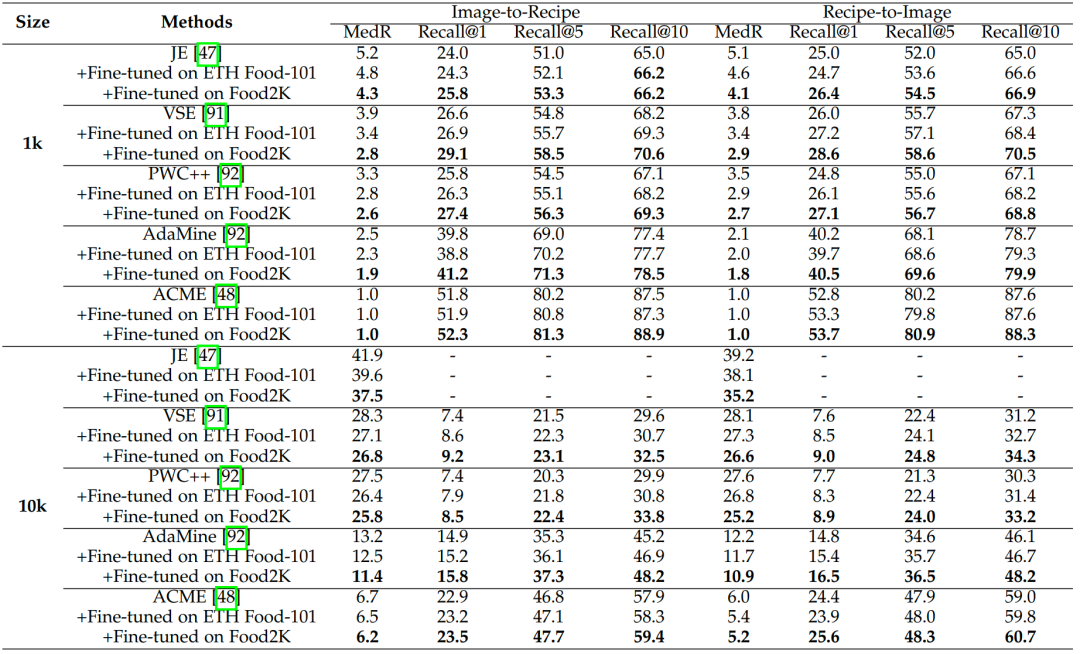
表6 基于Food2K和ETH Food-101微調(diào)的模型在跨模態(tài)菜譜-食品圖像檢索任務上的性能比較
五、未來工作
本文全面的實驗證明了Food2K對于各種視覺和多模態(tài)任務具有較好的泛化能力。基于Food2K的一些潛在研究問題和方向如下。
(1)大規(guī)模魯棒的食品圖像識別:盡管一些細粒度識別方法(如PMG[12,22])在常規(guī)細粒度識別數(shù)據(jù)集中獲得了最佳性能,但它們在Food2K上表現(xiàn)欠佳。雖然也有一些食品圖像識別方法(如PAR-Net[13])在中小規(guī)模食品數(shù)據(jù)集上取得了較好的性能,但它們在Food2K大規(guī)模食品圖像識別數(shù)據(jù)集上也并不能獲得更好的性能。我們推測,隨著食品數(shù)據(jù)的多樣性和規(guī)模的增加,不同食材、配飾和排列等因素產(chǎn)生了更復雜的視覺模式,以前的方法不再適用,因此,基于Food2K有更多的方法值得進一步探究。例如Transformers[14,23]在細粒度圖像識別方面產(chǎn)生了巨大的影響,其在大規(guī)模數(shù)據(jù)集上的性能高于CNNs。Food2K可以提供足夠的訓練數(shù)據(jù)來開發(fā)基于Transformers的食品圖像識別方法來提高性能。
(2)食品圖像識別的人類視覺評價:與人類視覺對一般物體識別的研究相比,對食品圖像識別進行評價可能更加困難。例如,食品具有較強的地域和文化特征,因此來自不同地區(qū)的人對食品圖像識別會有不同的偏見。最近的一項研究[15]給出了人類視覺系統(tǒng)和CNN在食品圖像識別任務中的比較。為了避免信息負擔過重,需要學習的菜肴數(shù)量被限制在16種不同類型的食物中。更有趣的問題值得進一步的探索。
(3)跨模態(tài)遷移學習的食品圖像識別:我們已經(jīng)驗證了Food2K在各種視覺和多模態(tài)任務中的推廣。未來我們可以從更多的方面來研究遷移學習。例如,食物有獨特的地理和文化屬性,可以進行跨菜系的遷移學習。這意味著我們可以使用來自東方菜系的訓練模型對西方菜系進行性能分析,反之亦然。經(jīng)過更細粒度的場景標注,如區(qū)域級甚至餐廳級標注,我們可以進行跨場景遷移學習來進行食品圖像識別。此外,我們還可以研究跨超類別遷移學習的食品圖像識別。例如,我們可以使用來自海鮮超類的訓練模型來對肉類超類進行性能分析。這些有趣的問題都值得深入探索。
(4)大規(guī)模小樣本食品圖像識別:最近,有一些基于中小型食品類別的小樣本食品圖像識別方法[16,17]研究。LS-FSFR[18]是一項更現(xiàn)實的任務,它旨在識別數(shù)百種新的類別而不忘記以前的類別,且這些數(shù)百種新的食品類別的樣本數(shù)很少。Food2K提供了大規(guī)模的食品數(shù)據(jù)集測試基準來支持這項任務。
(5)更多基于Food2K的應用:本文驗證了Food2K在食品圖像識別、食品圖像檢索、跨模態(tài)菜譜-食品圖像檢索、食品檢測和分割等各種任務中具有更好的泛化能力。Food2K還可以支持更多新穎的應用。食品圖像生成是一種新穎而有趣的應用,它可以通過生成對抗網(wǎng)絡(GANs)[19]合成與現(xiàn)實場景相似的新的食品圖像。例如,Zhu等人[20]可以從給定的食材和指令中生成高度真實和語義一致的圖像。不同的GANs,如輕量級的GAN [21],也可以用于生成基于Food2K的食物圖像。
(6)面向更多任務的Food2K擴展:基于訓練的Food2K模型可以應用于更多與食物計算任務中。此外考慮到一些工作[6]已經(jīng)表明食材可以提高識別性能,我們計劃擴展Food2K來提供更豐富的屬性標注以支持不同語義級別的食品圖像識別。我們還可以在Food2K上進行區(qū)域級和像素級標注使其應用范圍更廣。此外,我們還可以開展一些新的任務,如通過在Food2K上標注美學屬性信息,對食品圖像進行美學評估。
六、 總結(jié)與展望
在本文中,我們提出了具有更多數(shù)據(jù)量、更大類別覆蓋率和更高多樣性的Food2K,它可以作為一個新的大規(guī)模食品圖像識別基準。Food2K適用于各種視覺和多模態(tài)任務,包括食品圖像識別、食品圖像檢索、檢測、分割和跨模態(tài)菜譜-食品圖像檢索。
在此基礎上,我們進一步提出了一個面向食品圖像識別的深度漸進式區(qū)域增強網(wǎng)絡。該網(wǎng)絡主要由漸進式局部特征學習模塊和區(qū)域特征增強模塊組成。漸進式局部特征學習模塊通過改進的漸進式訓練方法學習多樣互補的局部細粒度判別性特征,區(qū)域特征增強模塊利用自注意力機制將多尺度的豐富上下文信息融入到局部特征中以進一步增強特征表示。在Food2K上進行的大量實驗證明了該方法的有效性。 美團本身有著豐富的食品數(shù)據(jù)及業(yè)務應用場景,如何利用多元化數(shù)據(jù)進行食品圖像細粒度分析理解,解決業(yè)務痛點問題是我們持續(xù)關注的方向。目前,美團視覺智能部持續(xù)深耕于食品細粒度識別技術,并成功將相關技術應用于按搜出圖、點評智能推薦、掃一掃發(fā)現(xiàn)美食等不同的業(yè)務場景中,不僅提升了用戶體驗,還降低了運營成本。
在技術沉淀層面,我們圍繞此食品計算技術不斷推陳出新,目前申請專利20項,發(fā)表CCF-A類會議或期刊論文4篇(如AAAI、TIP、ACM MM等);我們還參加了2019年和2022年CVPR FGVC細粒度識別比賽,并取得了一冠一亞的成績;同時在ICCV 2021上也成功舉辦了以LargeFineFoodAI為主題的視覺研討會,為推動食品計算領域的發(fā)展貢獻了一份綿薄之力。
未來,我們計劃進一步圍繞這條主線,探索多模態(tài)信息融入、多任務學習等技術路線,不斷沉淀經(jīng)驗教訓,并將相關技術推廣到更多、更遠、更有價值的生活服務場景中,從而更好地服務好社會。
審核編輯 :李倩
-
圖像識別
+關注
關注
9文章
520瀏覽量
38268 -
圖像檢索
+關注
關注
0文章
28瀏覽量
8036 -
數(shù)據(jù)集
+關注
關注
4文章
1208瀏覽量
24691
原文標題:TPAMI 2023 | Food2K:大規(guī)模食品圖像識別
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
基于DSP的快速紙幣圖像識別技術研究
利用Jetson TK1為低功耗圖像識別挑戰(zhàn)做好準備
如何在APT-Pi上實現(xiàn)圖像識別功能

使用K210和Arduino IDE/Micropython進行圖像識別

圖像識別技術原理 深度學習的圖像識別應用研究
模擬矩陣在圖像識別中的應用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論