 基于自監督邏輯歸納的模糊時序推理框架LECTER
基于自監督邏輯歸納的模糊時序推理框架LECTER
動機介紹
理解自然語言中與事件相交織的時間概念是理解事件演化的重要內容。人可以具有對事件的典型發生時間、發生頻率、持續時間等時間屬性的感知能力,同時,也能夠把握好在上下文中,時間概念之間相對大小,前后順序等依賴關系。對于機器而言,掌握這些時序常識知識,獲取相應的時序推理能力,也對進行也對事件脈絡構建,醫療事件時序分析,改進對話系統中時間常識一致性等下游任務有著重要的意義。
為了讓模型能夠掌握相關的時序常識知識以提高其在下游自然語言理解任務上的性能,前人的典型做法是,首先基于弱監督的方法(如模版匹配)從海量的自然語言文本中獲取顯式表達了時序常識的自然文本,然后基于富時序常識的自然文本來構建以掩碼恢復為代表的自監督目標函數,對預訓練模型重新訓練。然而, 這種基于傳統語言模型目標函數的方法存在一定的局限性。如圖1(a)所示,為了在空白處填入正確的答案,模型首先要具備一定的全局推理能力,即能夠根據上下文歸納出正確答案對應的時間概念與在文中所提到的“3點”之間的依賴關系(即早于)。除此之外,與傳統的同樣需要這種邏輯關系歸納能力的任務不同,這種推理過程存在著固有的模糊性。例如,在圖1(b)所示的閱讀理解型數值推理任務中,一旦模型可以正確歸納出正確的計算邏輯為對應數值的減法,即可得到正確答案(2008-2007=1)。但是在圖1(b)的時序推理問題中,文中出現的“3點”是一個模糊的時間表述,模型需要理解其表示的是一天種的某個時間,而且最可能是下午的3點。因此正確答案的邏輯約束為早于("下午3點",?)決定。同時,需要注意的是,最終的答案本身也并非一個確切的結果,在一定的模糊的時間區間內的時刻均是合理的。然而當前時序推理模型往往僅僅是隱式的對上下文進行編碼,使其并不能夠具備這種模糊的時序歸納推理能力,而往往依賴于淺層的表面線索來實現這種復雜推理,這使得推理的結果不可解釋且并不可靠。
 圖1: 精確推理與模糊推理
圖1: 精確推理與模糊推理
為此,在本文中,我們提出了一個基于自監督邏輯歸納的模糊時序推理框架LECTER。其將時序推理過程結構化為3個連續的步驟,即(1)歸納出文中的時間表達式間的邏輯約束關系(2)將文中的模糊時間概念進行具體化(3)綜合利用前兩步的結果以及額外的上下文信息來驗證候選時間概念的正確性。具體的,其包含有3個子模塊分別完成上述的3個子過程,分別是時間依賴邏輯歸納模塊,模糊時間概念具體化模塊和邏輯驗證模塊。我們通過邏輯編程語言DeepProbLog來實現邏輯驗證模塊。為了在對LECTER進行自監督的訓練,我們引入了兩個自監督的目標函數:(1)基于回歸的時間概念預測損失(2)模糊時序邏輯蘊含損失。其充分考慮到了文中的模糊時間概念對推理過程帶來的影響,前者用于使得模型從數據中學習相關的時間常識,后者則是使得模型能夠基于蘊含來歸納出正確的時序邏輯。
背景介紹
問題定義
在文檔中包含有個句子,以及個時間表達式, 這里>.代表所含有的時間表達式的集合. 本章中的時序推理任務被定義為一個多項選擇任務:將原文檔中的某一個時間表達式刪去獲得文檔,給定,該任務要求模型能夠從給定的候選時間表達式集中選取出所有的合適的時間表達式能夠填入中被刪去的時間表達式的位置,并且符合上下文語義。
例如,對于圖1 (a)中的空缺,2點,下午兩點2:00 pm都是正確的答案,但是上午8點就不符合原文中的語義約束了。
邏輯編程語言框架DeepProbLog
概率邏輯編程[2]是一種依賴于正式邏輯(formal logic)的編程范式。由概率邏輯編程語言所編寫的程序包含有一組形如 的概率事實(probabilistic facts)和一組邏輯規則,其中代表概率代表原子式。例如,如下的程序定義了在扔硬幣中的概率過程
0.4 :: coin(x1,h).0.5 :: coin(x2,h).twoHeads(X,Y) :- coin(X, h), coin(Y, h).
這里,coin()代表事實:硬幣正面朝上。
邏輯規則twoHeads() :- coin(, ), coin(, )則定義了“什么代表兩枚硬幣都時候正面朝上”,這里, :- 代表了邏輯蘊含: 如果均為真,那么成立。基于這種概率編程語言,可以輕易的計算目標原子式的成立的概率。在本例中,針對查詢原子式twoHeads(), 程序可以自動的計算兩枚硬幣均朝上的計算結果,即P(twoHeads())=0.2。
綜上所述,在概率邏輯中,形如的原子表達式的概率是。而在DeepProbLog中,其將“神經網絡”組件的解釋為一個“神經”謂詞,即在原子表達式上的概率是由神經網絡來得到。而除此之外,其保留了ProbLog語言的包括語義,推理機制和實現在內所有組成部分。
如下的DeepProbLog程序定義了扔硬幣的神經化拓展:
nn(coin_nn, [X], S, [h,t]): coin(X,S)twoHeads(X,Y) :- coin(X, h), coin(Y, h).
(例如可以是扔硬幣結果的一張圖片)輸入到模型中,并映射為在上的分布 (朝上和朝下). 由神經謂詞定義的事實的成立的概率由神經網絡的softmax層給出。
為了對實現神經謂詞的訓練,DeepProbLog框架將基于神經網絡的輸出層所產生的神經謂詞引導的概率事實,以及在邏輯程序中的其他概率事實和子句作為輸入,而由ProbLog編程語言計算查詢原子式的成立概率 ,這里代表神經謂詞的可訓練參數,代表訓練數據,代表查詢的原子式。由于默認查詢原子式一般為真,在訓練時最大化即可,該損失稱之為邏輯蘊含損失。
由于ProbLog的代數擴展已經可以支持自動求導,所以,其可以將梯度信息傳播到神經謂詞的輸出處,故其可以直接基于優化器以梯度下降的方式直接訓練整個模型。
模型方法
在本文中我們提出了基于模糊邏輯歸納的事件時序常識推理方法LECTER,如圖2所示。其包含有3個部分:(i)上下文編碼器,用于對富時間表達式的上下文進行編碼(ii)邏輯歸納模塊,由時序依賴歸納器和去模糊器構成。其目標是為了能夠預測上下文中的多個時間表達式之間的時序依賴關系,以及得到一個模糊時間概念的具體數值意義。(iii)邏輯驗證器,其通過神經概率邏輯編程語言來表示人對于不同的時間表達式間數值關系的先驗知識,來評估查詢時間表達式是否與神經網絡的預測結果想一致。同時我們還提出了兩個自監督損失以有效的訓練LECTER模型,分別是“基于回歸的時間值恢復損失”和“時序邏輯蘊含損失”。
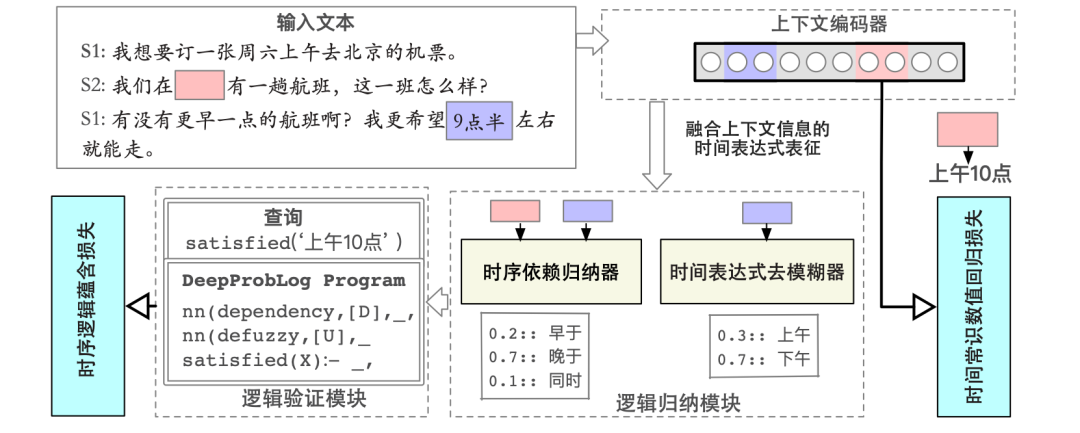 圖2: LECTER模型架構
圖2: LECTER模型架構
上下文編碼器
我們基于預訓練語言模型(如BERT/RoBERTa)來對上下文中的每個時間表達式進行編碼。為構建自監督訓練數據,我們從給定的輸入數據中隨機選擇一個時間表達式,將其刪去并替換為2個[MASK]符.這兩個[MASK]分別代表在一個時間概念中的數值部分和單位部分。于是,對于每一條原始富時間表達式文本,我們都可以得到一個填空形式的輸入。在下文中,稱需要被恢復的時間表達式為“目標時間表達式”,而文中剩余的時間表達式為“輔助時間表達式“。基于該編碼器對上下文進行編碼后,可得到待恢復的時間表達式的表示為,而上下文中輔助時間表達式的表示為.
邏輯歸納模塊
時序依賴歸納器時序依賴歸納器用于生成上下文相關的目標時間表達式與輔助時間表達式之間應滿足的邏輯約束關系。在本文中,我們建模了潛在的二元依賴關系,形式上即為一種關系抽取任務,我們考查了3種關系,分別是早于、晚于和同時。對于輸入的目標和輔助時間表達式和,該歸納器輸出在標簽集上的概率分布:
時間概念去模糊器這里我們定義在文本中,只給出其數值內容,但是單位缺失的時間概念為模糊時間概念。例如,“I wake up at 6”中,“6”代表了一個時刻,然而其單位(上午/下午)未在文中顯式的給出。這使得并不能直接將基于時序依賴歸納器得到的概念間邏輯關系實例化以實現對答案數值區間的推理。為此,我們引入了時間概念去模糊器,其目標是估計模糊時間概念具體化為每個特定可行解的概率。
具體的,每個時間表達式的上下文表示都會作為其對應維度的時間單位分類器的輸入:
即在給定的維度的標簽集上每個標簽的分數,.
邏輯驗證器
邏輯驗證器用于計算目標時間表達式滿足神經網絡所歸納的邏輯約束的概率,在訓練時,該概率將會被最大化(即“蘊含損失”)。這部分由神經-符號系統DeepProbLog實現。一旦符號實例化的結構給定,DeepProblog程序既可以使得我們能夠簡單的基于反向傳播的方式來完成訓練。圖3展示了一個符號實例化之后,DeepProbLog框架進行概率前向傳播的過程。
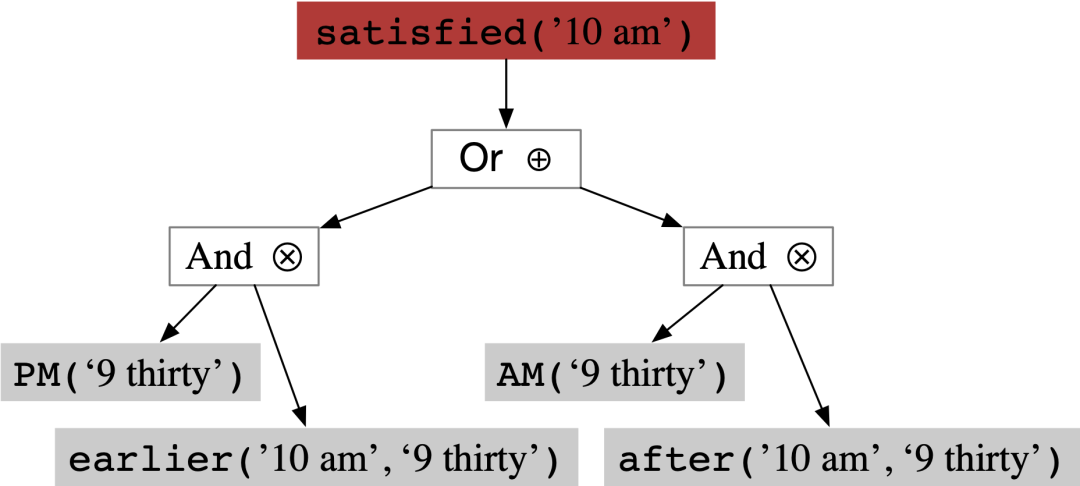 圖3: DeepProbLog框架進行概率前向傳播的過程
圖3: DeepProbLog框架進行概率前向傳播的過程
訓練
基于回歸的時間數值恢復損失本文中我們同樣以使得模型恢復文中被掩蓋住的時間表達式的一個損失函數,該損失函數要求模型能夠跟據給定上下文,預測出缺失時間表達式的歸一化之后的數值。前人的工作[3]證明了在持續時間維度,基于回歸的方式構建預訓練損失能夠取得良好的效果,我們將其拓展到更廣泛的時序常識維度。
這里是模型預測得到的歸一化值,。其中,時間表達式歸一化方法為:將時刻統一以小數時間表示,將持續時間轉化為以秒為單位后的數值的對數(例如, 2 小時 7200 秒 ). 7:30 pm 19.5). )。基于均方差誤差來優化:
這里就代表時間表達式的歸一化后的值。
時序邏輯蘊含損失仿照DeepProbLog[4], 我們也同樣使用了“蘊含損失”函數。給定訓練數據和查詢,模型調整其參數來最大化查詢為真的概率. 可以描述為對于查詢的平均負對數損失:
綜上,LECTER的損失函數為:
在進行推理時,我們基于如下方式里選擇最正確的答案:
這里是答案集,代表被刪去一個時間表達式的輸入文檔。
實驗
數據集及評估方式
我們在一個具有挑戰性的TIMEDIAL[4]數據集上評估LECTER的性能。TIMEDIAL是一個面向復雜上下文(對話)的時序常識推理數據集。給定一個多輪對話并掩住其含有的一個時間表示式,該任務需要模型能夠從4個選項中選擇出合理的候選時間表達式,在4個答案中有且僅有兩個答案是正確答案。只有模型能夠正確的理解上下文語義與目標時間表達式的因果關系,其才有可能做出正確的預測。該數據集中總計有1.1k個數據實例,平均每段對話有11輪,包含有3個以上的時間表達式。我們使用2-best accuracy指標來評估模型的性能。在實驗中,我們基于收集了在TIMEDIAL域外分布的對話數據來以自監督的方式訓練LECTER模型。訓練和驗證集的數據量分別為97k和24k。
結果分析
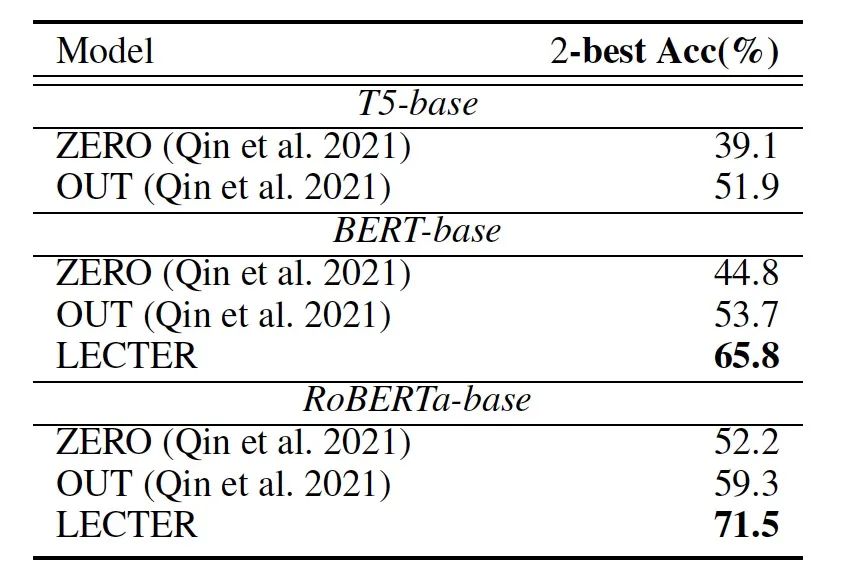 表1: 主實驗結果
表1: 主實驗結果
表1展示了我們的方法與[1]中提出的基線方法相比的結果。我們可以得出如下結論:(1)通過時序增強的持續訓練,預訓練模型的表現可以得到很大提升,證明了通過弱監督方式獲取時序知識信號對與時序推理任務的意義。(2)得益于對模糊時間概念的建模,LECTER模型可以大幅度的超過基線方法,取得了超過10%的提升。
消融實驗
表2展示了消融實驗的結果,我們證明了我們添加的兩個自監督損失的有效性。如表2所示,基于回歸的時間概念恢復損失,提升了約9.0%。可能的原因在于,經典的預訓練的損失并不能夠很好的完全建模時間常識的模糊性,在給定的語義下,在一個模糊的連續區間內的時間概念都可以是可行解。而這種連續性恰好可以很好的基于數值回歸的方式進行建模。時序邏輯歸納損失也提升了2.1%,這是由于通過顯式的邏輯歸納,模型獲得了更強的依據潛在的邏輯關系進行推理的能力,這比隱式的編碼上下文的方式往往更魯棒可靠。
 表2: 消融實驗結果
表2: 消融實驗結果
結論
在本文中,我們提出了基于模糊邏輯歸納的事件時序常識推理方法LECTER。我們將典型的時序常識推理過程建模為三個連續步驟:(1)歸納出文中的時間表達式間的邏輯約束關系(2)將文中的模糊時間概念進行具體化(3)綜合利用前兩步的結果以及額外的上下文信息來驗證候選時間概念的正確性。利用“基于回歸的時間值恢復損失”和“時序邏輯蘊含損失”,模型可以在深度理解文中時間表達式之間全局依賴的同時,有更好的針對模糊時間概念的推理能力。在TIMEDIAL數據集中,我們大幅度超越了基線方法。
-
框架
+關注
關注
0文章
403瀏覽量
17509 -
函數
+關注
關注
3文章
4333瀏覽量
62723 -
自然語言
+關注
關注
1文章
288瀏覽量
13359
原文標題:AAAI 2023 | 基于自監督邏輯歸納的可解釋模糊時序常識推理
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
MATLAB模糊邏輯工具箱函數介紹
通過LabVIEW與MATLAB設計模糊參數自整定PID
在MATLAB環境下的模糊參數自整定PID控制
基于Matlab FIS工具箱的模糊自整定PID控制系統的設
戰場目標的模糊邏輯檢測與識別方法
基于條件熵的直覺模糊條件推理
基于直覺模糊推理的醫學圖像融合方法研究

基于改進模糊熵和證據推理的多屬性決策方法
深度學習框架區分訓練還是推理嗎
一種利用幾何信息的自監督單目深度估計框架





 工商網監
工商網監
評論