


前言
我們公司有個項目的數據量高達五千萬,但是因為報表那塊數據不太準確,業務庫和報表庫又是跨庫操作,所以并不能使用 SQL 來進行同步。當時的打算是通過mysqldump或者存儲的方式來進行同步,但是嘗試后發現這些方案都不切實際:
mysqldump:不僅備份需要時間,同步也需要時間,而且在備份的過程,可能還會有數據產出(也就是說同步等于沒同步)
存儲方式:這個效率太慢了,要是數據量少還好,我們使用這個方式的時候,三個小時才同步兩千條數據…
后面在網上查看后,發現 DataX 這個工具用來同步不僅速度快,而且同步的數據量基本上也相差無幾。
一、DataX 簡介
DataX 是阿里云 DataWorks 數據集成 的開源版本,主要就是用于實現數據間的離線同步。DataX 致力于實現包括關系型數據庫(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各種異構數據源(即不同的數據庫)間穩定高效的數據同步功能。
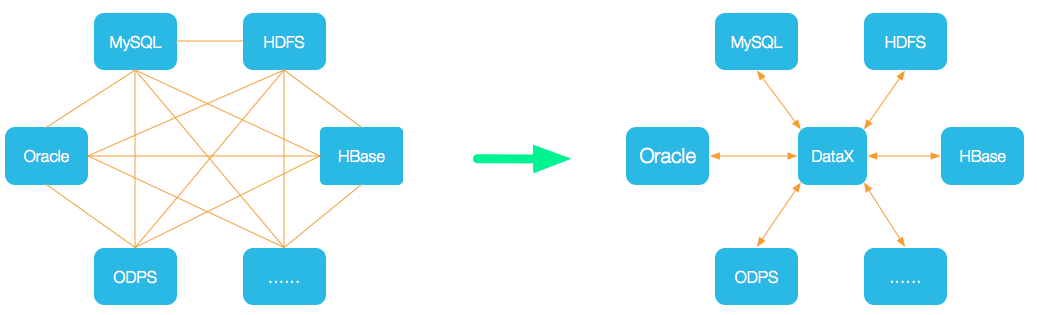
- 為了解決異構數據源同步問題,DataX 將復雜的網狀同步鏈路變成了星型數據鏈路,DataX 作為中間傳輸載體負責連接各種數據源;
- 當需要接入一個新的數據源時,只需要將此數據源對接到 DataX,便能跟已有的數據源作為無縫數據同步。
1.DataX3.0 框架設計
DataX 采用 Framework + Plugin 架構,將數據源讀取和寫入抽象稱為 Reader/Writer 插件,納入到整個同步框架中。

| 角色 | 作用 |
|---|---|
| Reader(采集模塊) |
負責采集數據源的數據,將數據發送給Framework。 |
| Writer(寫入模塊) |
負責不斷向Framework中取數據,并將數據寫入到目的端。 |
| Framework(中間商) |
負責連接Reader和Writer,作為兩者的數據傳輸通道,并處理緩沖,流控,并發,數據轉換等核心技術問題。 |
2.DataX3.0 核心架構
DataX 完成單個數據同步的作業,我們稱為 Job,DataX 接收到一個 Job 后,將啟動一個進程來完成整個作業同步過程。DataX Job 模塊是單個作業的中樞管理節點,承擔了數據清理、子任務切分、TaskGroup 管理等功能。
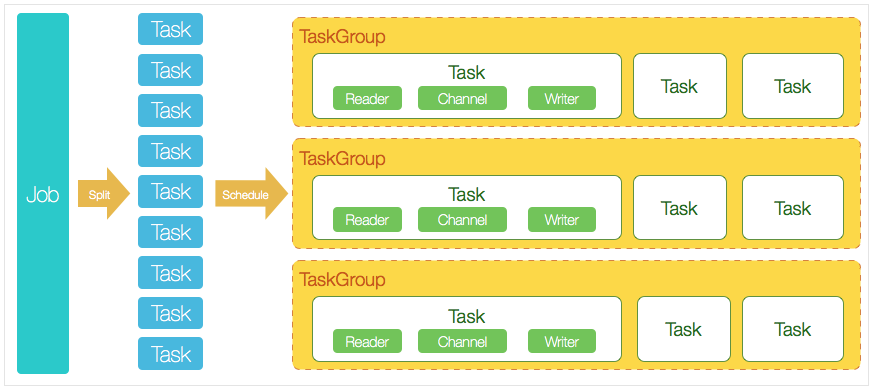
- DataX Job 啟動后,會根據不同源端的切分策略,將 Job 切分成多個小的 Task (子任務),以便于并發執行。
- 接著 DataX Job 會調用 Scheduler 模塊,根據配置的并發數量,將拆分成的 Task 重新組合,組裝成 TaskGroup(任務組)
-
每一個 Task 都由 TaskGroup 負責啟動,Task 啟動后,會固定啟動 Reader
-->Channel-->Writer 線程來完成任務同步工作。 - DataX 作業運行啟動后,Job 會對 TaskGroup 進行監控操作,等待所有 TaskGroup 完成后,Job 便會成功退出(異常退出時值非 0)
DataX 調度過程:
- 首先 DataX Job 模塊會根據分庫分表切分成若干個 Task,然后根據用戶配置并發數,來計算需要分配多少個 TaskGroup;
-
計算過程:
Task / Channel = TaskGroup,最后由 TaskGroup 根據分配好的并發數來運行 Task(任務)
二、使用 DataX 實現數據同步
準備工作:
| 主機名 | 操作系統 | IP 地址 | 軟件包 |
|---|---|---|---|
| MySQL-1 | CentOS 7.4 | 192.168.1.1 |
jdk-8u181-linux-x64.tar.gzdatax.tar.gz |
| MySQL-2 | CentOS 7.4 | 192.168.1.2 |
安裝 JDK:
下載地址:https://www.oracle.com/java/technologies/javase/javase8-archive-downloads.html(需要創建 Oracle 賬號)
[root@MySQL-1~]#ls
anaconda-ks.cfgjdk-8u181-linux-x64.tar.gz
[root@MySQL-1~]#tarzxfjdk-8u181-linux-x64.tar.gz
[root@DataX~]#ls
anaconda-ks.cfgjdk1.8.0_181jdk-8u181-linux-x64.tar.gz
[root@MySQL-1~]#mvjdk1.8.0_181/usr/local/java
[root@MySQL-1~]#cat<>/etc/profile
exportJAVA_HOME=/usr/local/java
exportPATH=$PATH:"$JAVA_HOME/bin"
END
[root@MySQL-1~]#source/etc/profile
[root@MySQL-1~]#java-version
-
因為
CentOS 7上自帶Python 2.7的軟件包,所以不需要進行安裝。
1.Linux 上安裝 DataX 軟件
[root@MySQL-1~]#wgethttp://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
[root@MySQL-1~]#tarzxfdatax.tar.gz-C/usr/local/
[root@MySQL-1~]#rm-rf/usr/local/datax/plugin/*/._*#需要刪除隱藏文件(重要)
-
當未刪除時,可能會輸出:
[/usr/local/datax/plugin/reader/._drdsreader/plugin.json] 不存在. 請檢查您的配置文件.
驗證:
[root@MySQL-1~]#cd/usr/local/datax/bin
[root@MySQL-1~]#pythondatax.py../job/job.json#用來驗證是否安裝成功
輸出:
2021-12-131928.828[job-0]INFOJobContainer-PerfTracenotenable!
2021-12-131928.829[job-0]INFOStandAloneJobContainerCommunicator-Total100000records,2600000bytes|Speed253.91KB/s,10000records/s|Error0records,0bytes|AllTaskWaitWriterTime0.060s|AllTaskWaitReaderTime0.068s|Percentage100.00%
2021-12-131928.829[job-0]INFOJobContainer-
任務啟動時刻:2021-12-131918
任務結束時刻:2021-12-131928
任務總計耗時:10s
任務平均流量:253.91KB/s
記錄寫入速度:10000rec/s
讀出記錄總數:100000
讀寫失敗總數:0
2.DataX 基本使用
查看streamreader --> streamwriter的模板:
[root@MySQL-1~]#python/usr/local/datax/bin/datax.py-rstreamreader-wstreamwriter
輸出:
DataX(DATAX-OPENSOURCE-3.0),FromAlibaba!
Copyright(C)2010-2017,AlibabaGroup.AllRightsReserved.
Pleaserefertothestreamreaderdocument:
https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md
Pleaserefertothestreamwriterdocument:
https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md
Pleasesavethefollowingconfigurationasajsonfileanduse
python{DATAX_HOME}/bin/datax.py{JSON_FILE_NAME}.json
torunthejob.
{
"job":{
"content":[
{
"reader":{
"name":"streamreader",
"parameter":{
"column":[],
"sliceRecordCount":""
}
},
"writer":{
"name":"streamwriter",
"parameter":{
"encoding":"",
"print":true
}
}
}
],
"setting":{
"speed":{
"channel":""
}
}
}
}
根據模板編寫json文件
[root@MySQL-1~]#cat<test.json
{
"job":{
"content":[
{
"reader":{
"name":"streamreader",
"parameter":{
"column":[#同步的列名(*表示所有)
{
"type":"string",
"value":"Hello."
},
{
"type":"string",
"value":"河北彭于晏"
},
],
"sliceRecordCount":"3"#打印數量
}
},
"writer":{
"name":"streamwriter",
"parameter":{
"encoding":"utf-8",#編碼
"print":true
}
}
}
],
"setting":{
"speed":{
"channel":"2"#并發(即sliceRecordCount*channel=結果)
}
}
}
}
輸出:(要是復制我上面的話,需要把#帶的內容去掉)
3.安裝 MySQL 數據庫
分別在兩臺主機上安裝:
[root@MySQL-1~]#yum-yinstallmariadbmariadb-servermariadb-libsmariadb-devel
[root@MySQL-1~]#systemctlstartmariadb#安裝MariaDB數據庫
[root@MySQL-1~]#mysql_secure_installation#初始化
NOTE:RUNNINGALLPARTSOFTHISSCRIPTISRECOMMENDEDFORALLMariaDB
SERVERSINPRODUCTIONUSE!PLEASEREADEACHSTEPCAREFULLY!
Entercurrentpasswordforroot(enterfornone):#直接回車
OK,successfullyusedpassword,movingon...
Setrootpassword?[Y/n]y#配置root密碼
Newpassword:
Re-enternewpassword:
Passwordupdatedsuccessfully!
Reloadingprivilegetables..
...Success!
Removeanonymoususers?[Y/n]y#移除匿名用戶
...skipping.
Disallowrootloginremotely?[Y/n]n#允許root遠程登錄
...skipping.
Removetestdatabaseandaccesstoit?[Y/n]y#移除測試數據庫
...skipping.
Reloadprivilegetablesnow?[Y/n]y#重新加載表
...Success!
1)準備同步數據(要同步的兩臺主機都要有這個表)
MariaDB[(none)]>createdatabase`course-study`;
QueryOK,1rowaffected(0.00sec)
MariaDB[(none)]>createtable`course-study`.t_member(IDint,Namevarchar(20),Emailvarchar(30));
QueryOK,0rowsaffected(0.00sec)
因為是使用 DataX 程序進行同步的,所以需要在雙方的數據庫上開放權限:
grantallprivilegeson*.*toroot@'%'identifiedby'123123';
flushprivileges;
2)創建存儲過程:
DELIMITER$$
CREATEPROCEDUREtest()
BEGIN
declareAintdefault1;
while(Ado
insertinto`course-study`.t_membervalues(A,concat("LiSa",A),concat("LiSa",A,"@163.com"));
setA=A+1;
ENDwhile;
END$$
DELIMITER;
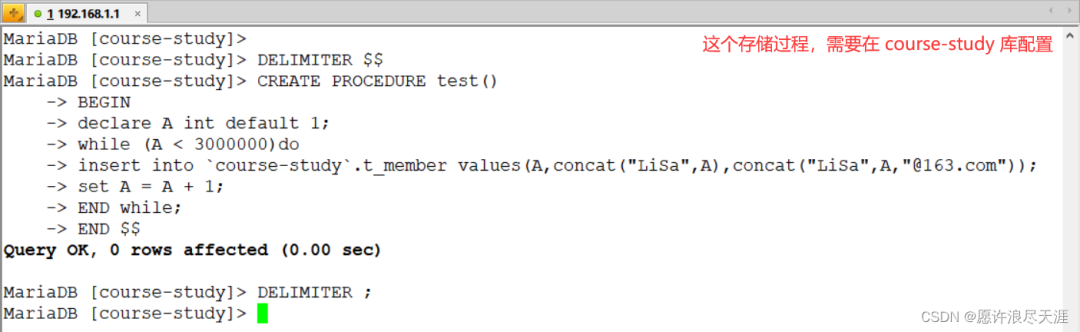
3)調用存儲過程(在數據源配置,驗證同步使用):
calltest();
4.通過 DataX 實 MySQL 數據同步
1)生成 MySQL 到 MySQL 同步的模板:
[root@MySQL-1~]#python/usr/local/datax/bin/datax.py-rmysqlreader-wmysqlwriter
{
"job":{
"content":[
{
"reader":{
"name":"mysqlreader",#讀取端
"parameter":{
"column":[],#需要同步的列(*表示所有的列)
"connection":[
{
"jdbcUrl":[],#連接信息
"table":[]#連接表
}
],
"password":"",#連接用戶
"username":"",#連接密碼
"where":""#描述篩選條件
}
},
"writer":{
"name":"mysqlwriter",#寫入端
"parameter":{
"column":[],#需要同步的列
"connection":[
{
"jdbcUrl":"",#連接信息
"table":[]#連接表
}
],
"password":"",#連接密碼
"preSql":[],#同步前.要做的事
"session":[],
"username":"",#連接用戶
"writeMode":""#操作類型
}
}
}
],
"setting":{
"speed":{
"channel":""#指定并發數
}
}
}
}
2)編寫json文件:
[root@MySQL-1~]#viminstall.json
{
"job":{
"content":[
{
"reader":{
"name":"mysqlreader",
"parameter":{
"username":"root",
"password":"123123",
"column":["*"],
"splitPk":"ID",
"connection":[
{
"jdbcUrl":[
"jdbc//192.168.1.1:3306/course-study?useUnicode=true&characterEncoding=utf8"
],
"table":["t_member"]
}
]
}
},
"writer":{
"name":"mysqlwriter",
"parameter":{
"column":["*"],
"connection":[
{
"jdbcUrl":"jdbc//192.168.1.2:3306/course-study?useUnicode=true&characterEncoding=utf8",
"table":["t_member"]
}
],
"password":"123123",
"preSql":[
"truncatet_member"
],
"session":[
"setsessionsql_mode='ANSI'"
],
"username":"root",
"writeMode":"insert"
}
}
}
],
"setting":{
"speed":{
"channel":"5"
}
}
}
}
3)驗證
[root@MySQL-1~]#python/usr/local/datax/bin/datax.pyinstall.json
輸出:
2021-12-151615.120[job-0]INFOJobContainer-PerfTracenotenable!
2021-12-151615.120[job-0]INFOStandAloneJobContainerCommunicator-Total2999999records,107666651bytes|Speed2.57MB/s,74999records/s|Error0records,0bytes|AllTaskWaitWriterTime82.173s|AllTaskWaitReaderTime75.722s|Percentage100.00%
2021-12-151615.124[job-0]INFOJobContainer-
任務啟動時刻:2021-12-151632
任務結束時刻:2021-12-151615
任務總計耗時:42s
任務平均流量:2.57MB/s
記錄寫入速度:74999rec/s
讀出記錄總數:2999999
讀寫失敗總數:0
你們可以在目的數據庫進行查看,是否同步完成。
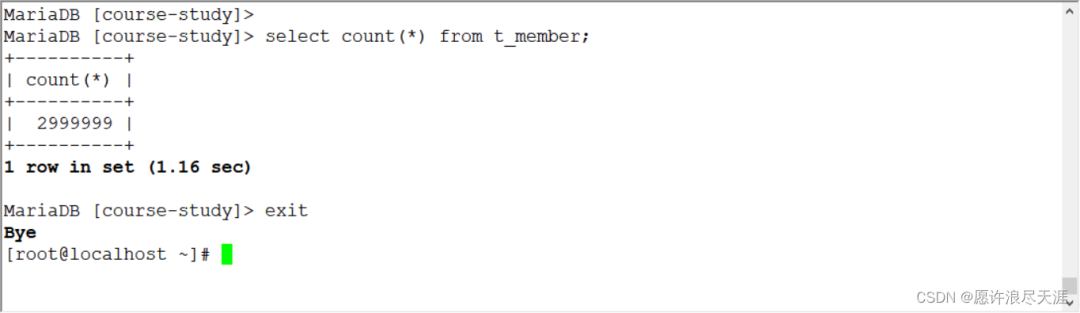
- 上面的方式相當于是完全同步,但是當數據量較大時,同步的時候被中斷,是件很痛苦的事情;
- 所以在有些情況下,增量同步還是蠻重要的。
5.使用 DataX 進行增量同步
使用 DataX 進行全量同步和增量同步的唯一區別就是:增量同步需要使用where進行條件篩選。(即,同步篩選后的 SQL)
1)編寫json文件:
[root@MySQL-1~]#vimwhere.json
{
"job":{
"content":[
{
"reader":{
"name":"mysqlreader",
"parameter":{
"username":"root",
"password":"123123",
"column":["*"],
"splitPk":"ID",
"where":"ID<=?1888",
"connection":[
{
"jdbcUrl":[
"jdbc//192.168.1.1:3306/course-study?useUnicode=true&characterEncoding=utf8"
],
"table":["t_member"]
}
]
}
},
"writer":{
"name":"mysqlwriter",
"parameter":{
"column":["*"],
"connection":[
{
"jdbcUrl":"jdbc//192.168.1.2:3306/course-study?useUnicode=true&characterEncoding=utf8",
"table":["t_member"]
}
],
"password":"123123",
"preSql":[
"truncatet_member"
],
"session":[
"setsessionsql_mode='ANSI'"
],
"username":"root",
"writeMode":"insert"
}
}
}
],
"setting":{
"speed":{
"channel":"5"
}
}
}
}
-
需要注意的部分就是:
where(條件篩選) 和preSql(同步前,要做的事) 參數。
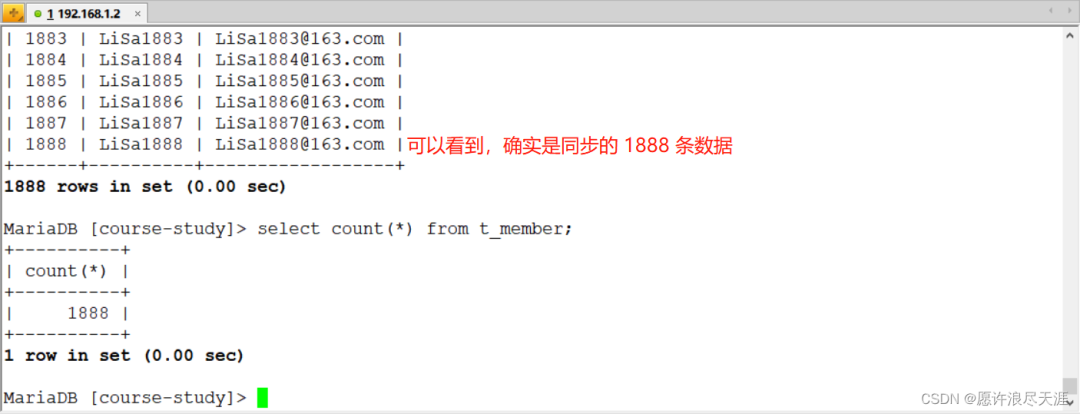
2)驗證:
[root@MySQL-1~]#python/usr/local/data/bin/data.pywhere.json
輸出:
2021-12-161738.534[job-0]INFOJobContainer-PerfTracenotenable!
2021-12-161738.534[job-0]INFOStandAloneJobContainerCommunicator-Total1888records,49543bytes|Speed1.61KB/s,62records/s|Error0records,0bytes|AllTaskWaitWriterTime0.002s|AllTaskWaitReaderTime100.570s|Percentage100.00%
2021-12-161738.537[job-0]INFOJobContainer-
任務啟動時刻:2021-12-161706
任務結束時刻:2021-12-161738
任務總計耗時:32s
任務平均流量:1.61KB/s
記錄寫入速度:62rec/s
讀出記錄總數:1888
讀寫失敗總數:0
目標數據庫上查看:
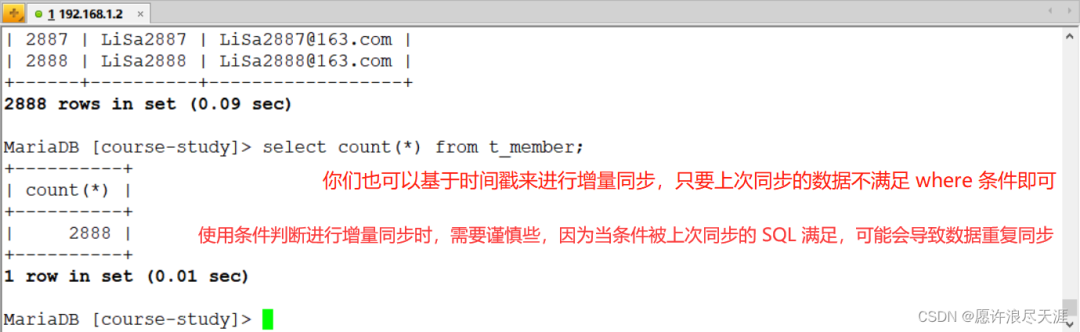
3)基于上面數據,再次進行增量同步:
主要是where配置:"where":"ID>1888ANDID<=?2888"#通過條件篩選來進行增量同步
同時需要將我上面的preSql刪除(因為我上面做的操作時truncate表)
審核編輯 :李倩
-
SQL
+關注
關注
1文章
783瀏覽量
45456 -
數據庫
+關注
關注
7文章
3945瀏覽量
66777 -
架構
+關注
關注
1文章
530瀏覽量
26074
原文標題:阿里又開源一款數據同步工具 DataX,穩定又高效,好用到爆!
文章出處:【微信號:TheBigData1024,微信公眾號:人工智能與大數據技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
免費又好用的PCB參數計算神器——Saturn PCB Toolkit
【飛騰派4G版免費試用】Ubuntu系統上運行的一款賊好用的截圖工具:Flameshot
哪里的域名價位便宜又好用 服務又周到呢
Apple Watch“又丑又無趣”???
mongodb可視化工具如何使用_介紹一款好用 mongodb 可視化工具
繼綠光瀏覽器、Tuber瀏覽器后,小編又發現一款神級APP

超大容量充電寶哪個好?手機充電寶哪款容量大又好用

一款用于Windows的開源反rookit (ARK)工具
爆款推薦 |?迅為RK3568開發板4核處理器+1T算力NPU+好用到爆的配套資料和視頻!






 工商網監
工商網監

評論