 模型在學習可轉移的語義分割表示方面的有效性
模型在學習可轉移的語義分割表示方面的有效性
目錄
前言
DPSS 方法概述
DeP 和 DDeP
基礎網絡結構
損失函數
diffusion 的擴展
實驗
總結
參考
前言
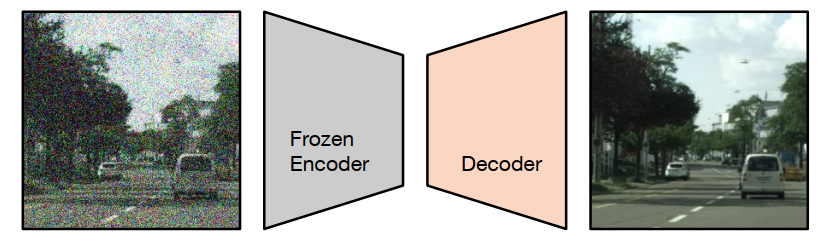
當前語義分割任務存在一個特別常見的問題是收集 groundtruth 的成本和耗時很高,所以會使用預訓練。例如監督分類或自監督特征提取,通常用于訓練模型 backbone。基于該問題,這篇文章介紹的方法被叫做 decoder denoising pretraining (DDeP),如下圖所示。
 請添加圖片描述
請添加圖片描述
與標準的去噪自編碼器類似,網絡被訓練用于對帶有噪聲的輸入圖像進行去噪。然而,編碼器是使用監督學習進行預訓練并凍結的,只有解碼器的參數使用去噪目標進行優化。此外,當給定一個帶有噪聲的輸入時,解碼器被訓練用于預測噪聲,而不是直接預測干凈圖像,這也是比較常見的方式。
DPSS 方法概述
這次介紹的這篇文章叫做 Denoising Pretraining for Semantic Segmentation,為了方便,后文統一簡寫為 DPSS。DPSS 將基于 Transformer 的 U-Net 作為去噪自編碼器進行預訓練,然后在語義分割上使用少量標記示例進行微調。與隨機初始化的訓練以及即使在標記圖像數量較少時,對編碼器進行監督式 ImageNet-21K 預訓練相比,去噪預訓練(DeP)的效果更好。解碼器去噪預訓練(DDeP)相對于主干網絡的監督式預訓練的一個關鍵優勢是能夠預訓練解碼器,否則解碼器將被隨機初始化。也就是說,DPSS 使用監督學習初始化編碼器,并僅使用去噪目標預訓練解碼器。盡管方法簡單,但是 DDeP 在 label-efficient 的語義分割上取得了最先進的結果。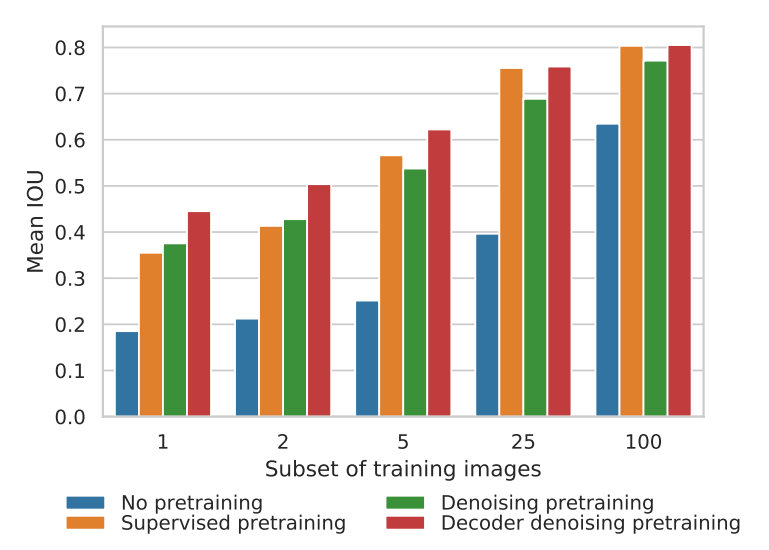
為了方便理解,上圖是以可用的標記訓練圖像比例為橫坐標的 Cityscapes 驗證集上的平均 IOU 結果。從左到右四個直方圖依次是不進行預訓練,使用 ImageNet-21K 預訓練 backbone,使用 DeP 預訓練編碼器和使用 DDeP 的方式。當可用的標記圖像比例小于5%時,去噪預訓練效果顯著。當可用標記比例較大時,基于 ImageNet-21K 的監督式預訓練 backbone 網絡優于去噪預訓練。值得注意的是,DDeP 在各個標記比例下都取得了最佳的結果。
DeP 和 DDeP
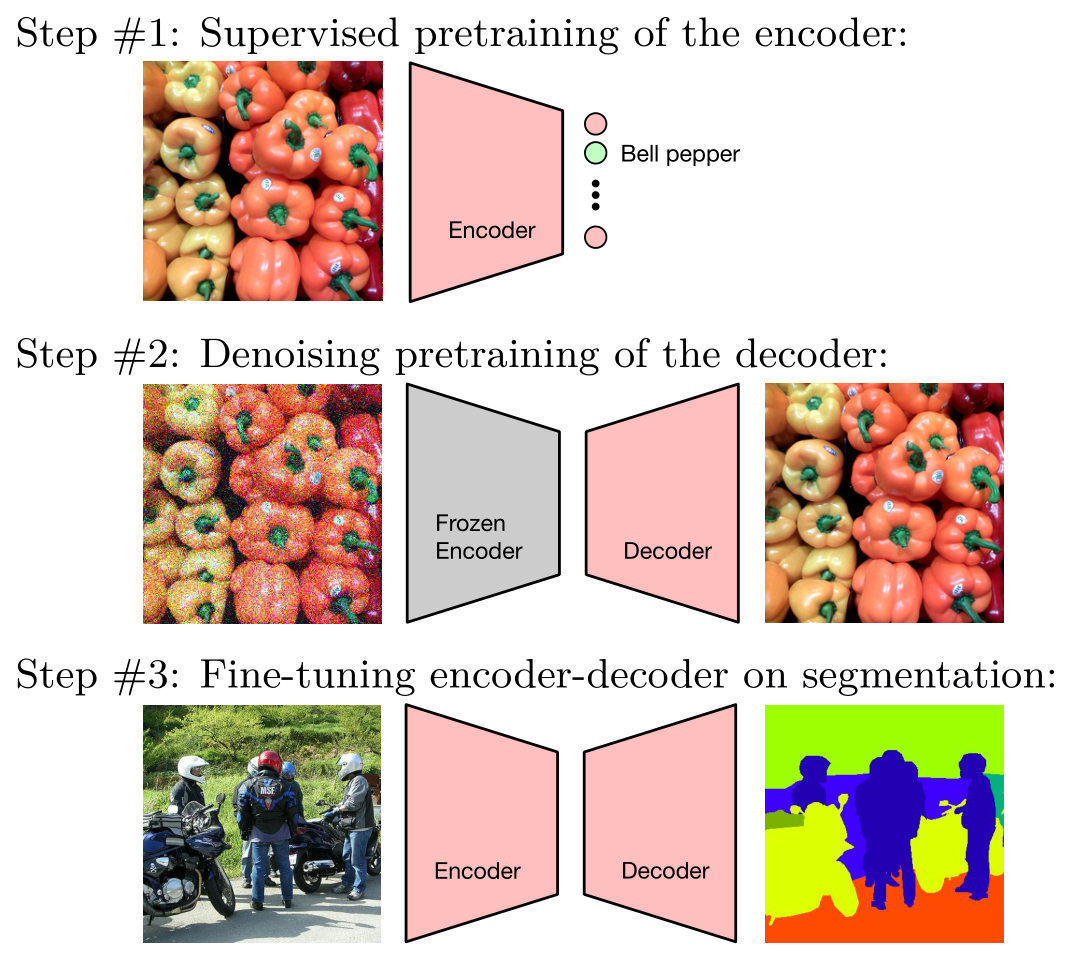
下圖是 DPSS 的一個形象的圖示,其中第二步代表 DDeP。最后的 Fine-tuning 過程是微調整個網絡,而不是只做 last layer。
 請添加圖片描述
請添加圖片描述
基礎網絡結構
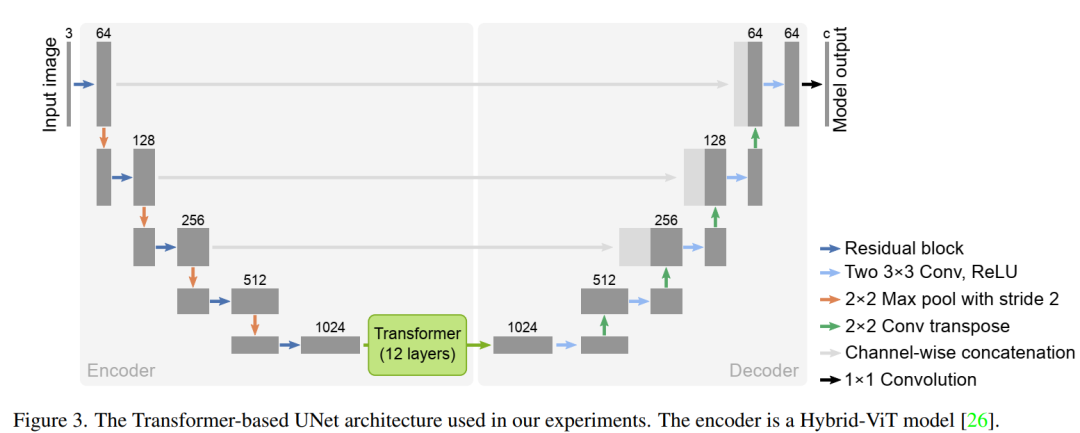
DPSS 使用了基于 Transfomer 的 U-Net 架構:TransUnet,如下圖所示。它將 12 層 Transfomer 與標準的 U-Net 模型相結合。這種架構中的編碼器是一種混合模型,包括卷積層和自注意力層。也就是說,patch embeddings 是從 CNN 特征圖中提取的。這篇論文采用了和 Hybrid-vit 模型相同的編碼器,以利用在 imagenet-21k 數據集中預先訓練的監督模型 checkpoints。論文中強調,去噪預訓練方法并不特定模型架構的選擇,只是結果都在 TransUNet 架構上測試。
 請添加圖片描述
請添加圖片描述
損失函數
為了預訓練 U-Net,設計了去噪目標函數。該函數向未標記的圖像添加高斯噪聲以創建噪點圖像。噪音水平由一個叫做 gamma 的標量值控制:
然后,噪聲圖像被輸入到 U-Net,它試圖通過消除噪點來重建原始圖像。去噪目標函數用如下公式表示,它涉及對噪聲水平和噪聲分布的期望值:
還將去噪目標函數與另一種公式進行了比較,該公式對圖像和噪聲進行衰減以確保隨機變量的方差為 1。發現具有固定噪聲水平的更簡單的去噪目標函數非常適合表示學習:
DeP 經過訓練,可以從噪聲損壞的版本中重建圖像,并且可以使用未標記的數據。降噪預訓練目標表示為 DDPM 擴散過程的單次迭代。sigma 的選擇對表示學習質量有很大影響,預訓練后,最終的 projection layer 會被丟棄,然后再對語義分割任務進行微調。此外,上面設計 DDPM 的內容,這里就不贅述了,在 GiantPandaCV 之前的語義分割和 diffusion 系列里可以找到。
diffusion 的擴展
在最簡單的形式下,當在上一節的最后一個方程中使用單個固定的 σ 值時,相當于擴散過程中的一步。DPSS 還研究了使該方法更接近于 DDPM 中使用的完整擴散過程的方法,包括:
Variable noise schedule:在 DDPM 中,模擬從干凈圖像到純噪聲(以及其反向)的完整擴散過程時,σ 被隨機均勻地從 [0, 1] 中抽樣,針對每個訓練樣本。盡管發現固定的 σ 通常表現最佳,但 DPSS 也嘗試隨機采樣 σ。在這種情況下,將 σ 限制在接近 1 的范圍內對于表示質量是必要的。
Conditioning on noise level:在擴散形式化方法中,模型表示從一個噪聲水平過渡到下一個的(反向)轉換函數,因此受當前噪聲水平的條件約束。在實踐中,這是通過將為每個訓練樣本抽樣的 σ 作為額外的模型輸入(例如,用于標準化層)來實現的。由于我們通常使用固定的噪聲水平,對于 DPSS 來說,不需要進行條件設置。
Weighting of noise levels:在 DDPM 中,損失函數中不同噪聲水平的相對權重對樣本質量有很大影響。論文中的實驗表明,學習可轉移表示不需要使用多個噪聲水平。因此,DPSS 并未對不同噪聲水平的加權進行實驗。
實驗
實驗在 Cityscapes,Pascal Context 和 ADE20K 數據集上。下面兩個表是在 Cityscapes 的驗證集上進行測試,其中還測試了可用帶標簽訓練數據為原始訓練數據量 1/30 的情況,表明即使有標簽的樣本數量很少,DPSS 在 mIoU 上的表現也優于以前的方法。
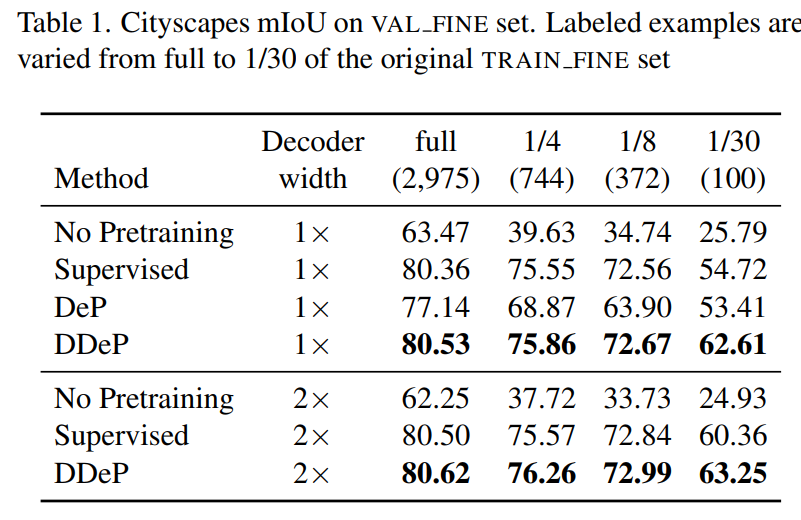 請添加圖片描述
請添加圖片描述 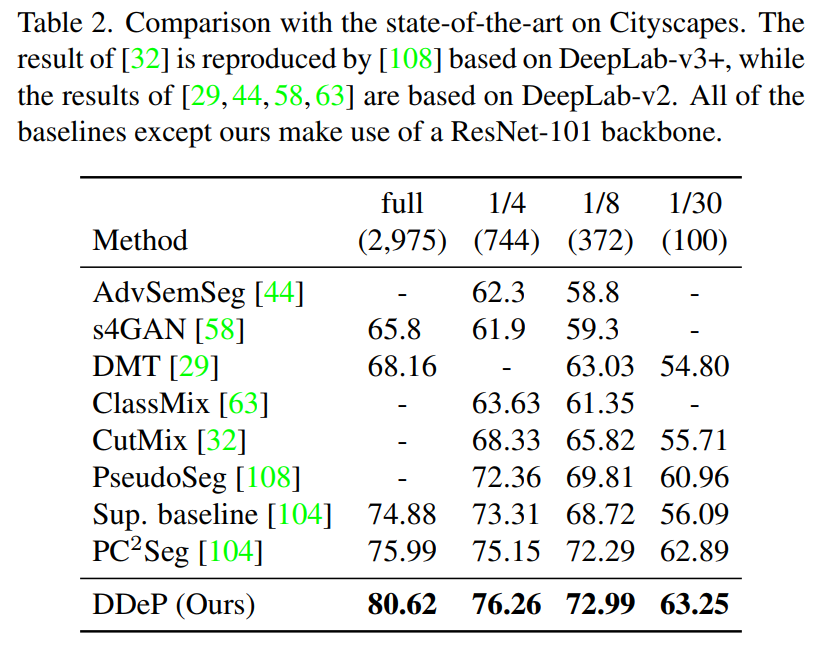 請添加圖片描述
請添加圖片描述
下面比較了在 DeP 模型中調整 sigma 參數的兩種不同方法的性能。第二種方法使用固定的 sigma 值,而第一種方法從間隔 [0.2,0.3] 對西格瑪進行均勻采樣。此外,折線圖表示固定 sigma 在值為 0.2 左右的區間效果更好。這部分實驗基于 Pascal Context 和 ADE20K 數據集。
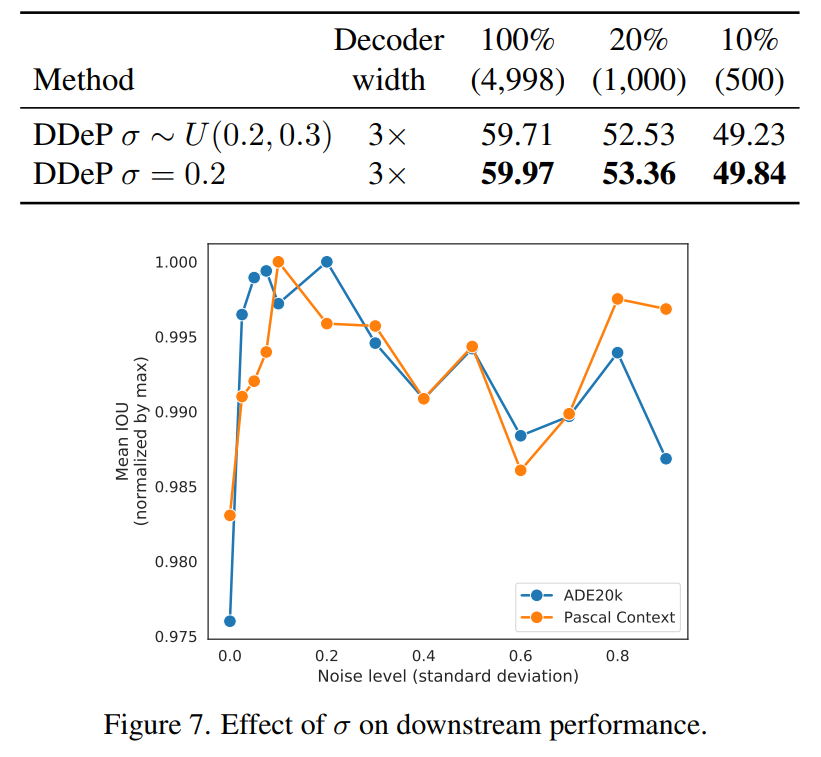 請添加圖片描述
請添加圖片描述
總結
這篇文章受到 diffusion 的啟發,探索了這些模型在學習可轉移的語義分割表示方面的有效性。發現將語義分割模型預訓練為去噪自編碼器可以顯著提高語義分割性能,尤其是在帶標記樣本數量有限的情況下。基于這一發現,提出了一個兩階段的預訓練方法,其中包括監督預訓練的編碼器和去噪預訓練的解碼器的組合。在不同大小的數據集上都表現出了性能提升,是一種很實用的預訓練方法。
-
解碼器
+關注
關注
9文章
1157瀏覽量
41176 -
函數
+關注
關注
3文章
4353瀏覽量
63292 -
模型
+關注
關注
1文章
3415瀏覽量
49475
原文標題:用于語義分割的解碼器 diffusion 預訓練方法
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
特征選擇在減少預測推理時間方面的有效性展示
高斯混合模型對乳腺癌診斷的有效性初探
利用深度學習模型實現監督式語義分割


基于深度神經網絡的圖像語義分割方法







 工商網監
工商網監
評論