 中科院針對NL2Code任務,調研了27個大模型,并指出5個重要挑戰
中科院針對NL2Code任務,調研了27個大模型,并指出5個重要挑戰
引言
對于NL2Code任務相信大家都不陌生。它主要目的就是將自然語言轉換成可執行代碼來提高開發人員的工作效率,終極目標就是干翻所有程序員,最近,隨著大模型的出現,距離這一天又稍稍進了一步。基于該背景,分享中科院和微軟亞洲研究院在ACL2023國際頂會上一篇文章:他們調研了NL2Code領域中的「27個大型語言模型以及相關評價指標」,分析了「LLMs的成功在于模型參數、數據質量和專家調優」,并指出了「NL2Code領域研究的5個機遇挑戰」,最后作者建立了一個分享網站來跟蹤LLMs在NL2Code任務上的最新進展。https://nl2code.github.io

背景介紹
新手程序員,甚至是那些沒有任何編程經驗的程序員,是否有可能僅僅通過用自然語言描述他們的需求來創建軟件?實現這一設想將對我們的生活、教育、經濟和勞動力市場產生前所未有的影響。自然語言-代碼(NL2Code)因其廣闊的應用場景,是一項重要的研究任務,在學術界和工業界都引起了廣泛的興趣。
關于NL2Code的發展,其實和自然語言理解的發展類似,一開始,基本都是基于專家規則進行算法設計,但是此類方法需要對不同編程語言進行設計,泛化性差;隨著技術發展,人們逐步開始使用靜態語言模型,并使用向量空間來描述文字,此類方法在初期一般向量空間比較稀疏,不能建立長期的依賴關系;再后來,就用到了我們比較熟悉的神經網絡,例如CNN、RNN、LSTM,此類方法通過標記數據進行訓練來構建自然語言(NL)和代碼(Code)之間的關系,但實際效果對NL2Code任務的能力有限;現在,在ChatGPT風靡全球的背景下,越來越多的大型語言模型(LLMs)如雨后春筍一樣出現,通過語言指令,它們可以在零樣本狀況下生成代碼,并在NL2Code任務上中取到了驚人的成績。具有標志性的一個LLM模型就是Codex,它擁有120億個參數,在Python編程任務上測試,可解決72.31%的問題,并且該模型已經商用可在實踐中提高開發人員的工作效率。
NL2Code任務與27個LLMs
對于NL2Code任務,其主要目的是基于給定自然語言問題描述生成所需要的代碼。以下是一個關于Python編程問題的示例。其中灰色塊部分表示問題描述,綠色塊部分表示模型生成代碼,黃色塊部分表示測試樣例。
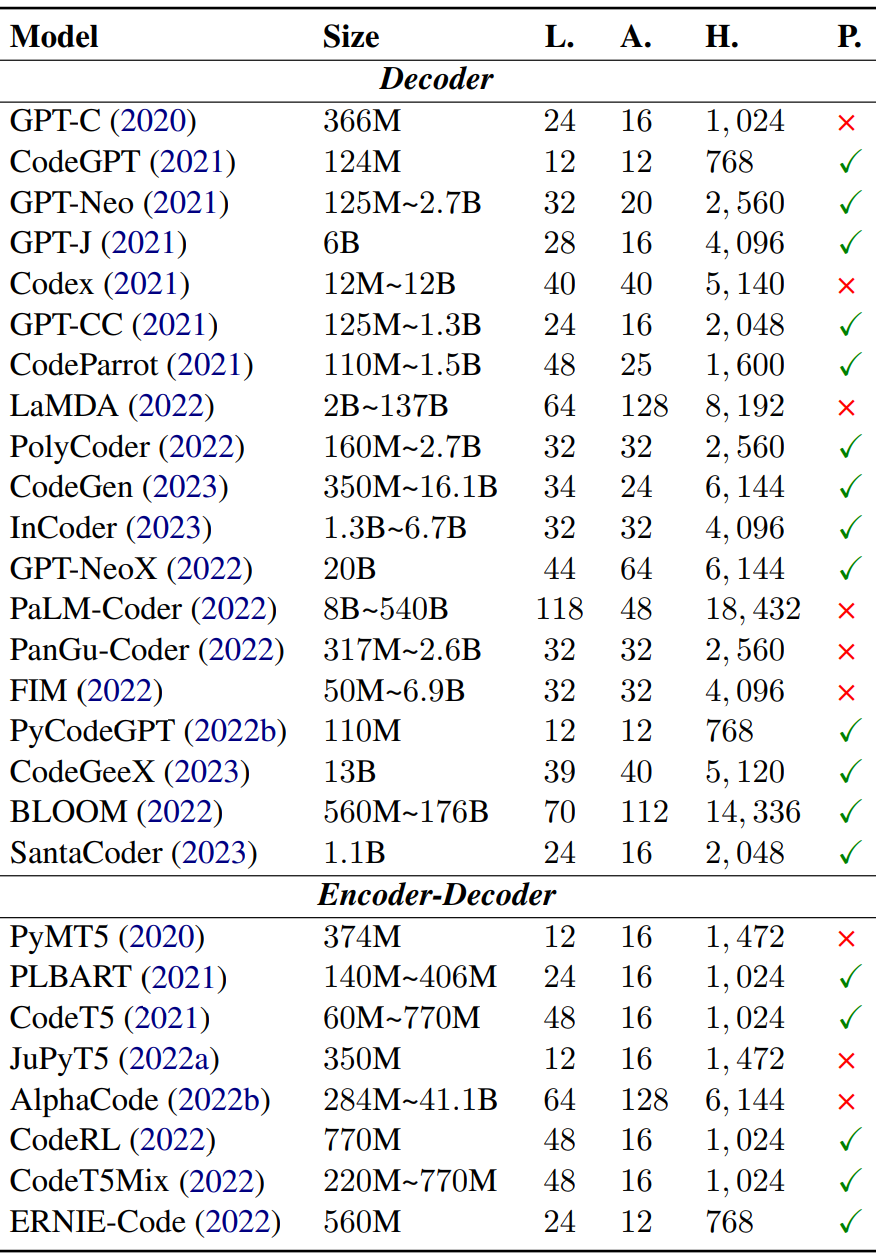
針對NL2Code任務對27個具有代表性的LLMs進行了全面調研,下表總結了每個模型的詳細信息,其中主要包括:模型架構、模型大小、模型層數(L)、注意力頭數量(A)、隱藏維度(H)、模型參數是否開放(P)等五個方面。
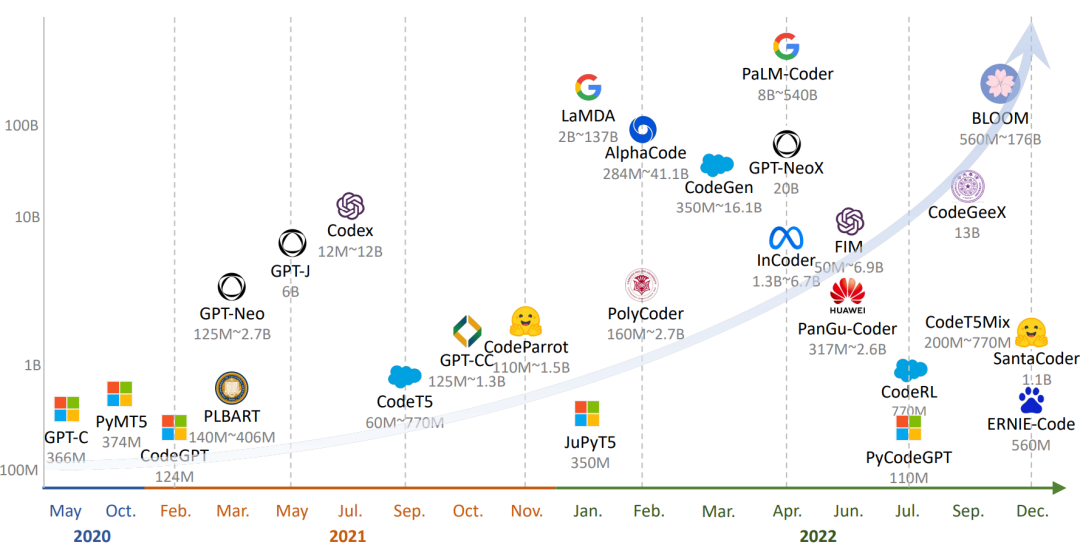
為了更好地可視化,下圖按時間順序展示了這些模型,繪制了最大的模型大小。觀察到的一個趨勢是,隨著研究領域的發展,這些大型語言模型的規模也在不斷擴大。此外,只有解碼器的架構更適合于規模較大的預訓練模型。
27個LLMs評估
上面總結了NL2Code現有的大型語言模型(LLMs),但是這些模型在架構、模型規模等方面各不相同,無法進行統一的評估。為此,作者在HumanEval基準上進行了Zero-shot統一評估,其中HumanEval基準由164個手寫的Python編程問題組成,對于每個編程問題都提供了測試用例,以評估生成代碼正確性。使用pass@k作為評估指標,即通過k次嘗試可以正確回答的問題的比例。下表顯示根據模型大小進行分組,在該測試集上的測試結果。
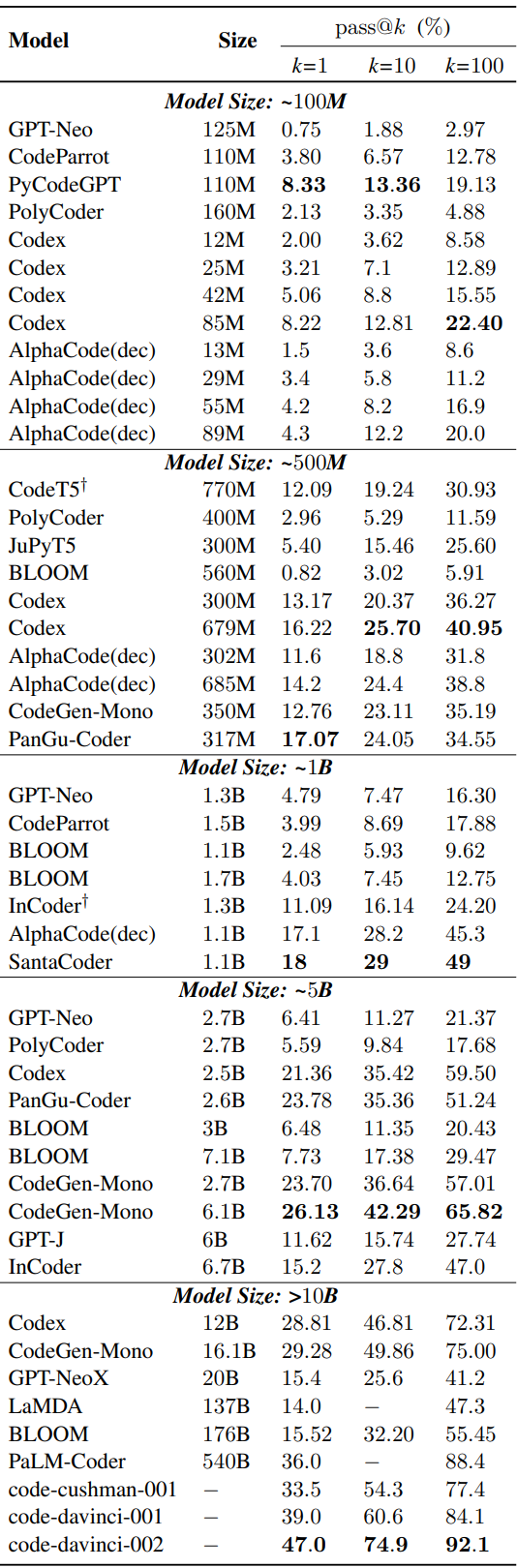
從上表可以看出,這些LLM在該數據集上的性能差異很大,盡管模型參數相似但效果差異也是很大。可以發現Codex 在各種尺寸上都處于領先地位。為什么會存在這個問題呢?影響模型效果的關鍵因素是啥呢?作者經過分析給出的結論有:模型大小、數據質量、專家調優。
模型大小
根據前面的整理用于NL2Code的LLMs時間發展圖可以發現,只要模型參數越多性能就越好。為了進一步說明模型參數大小和模型效果之間的關系,作者整理了10個比較有代表性的模型,在HumanEval基準上的pass@1結果,如下圖所示:
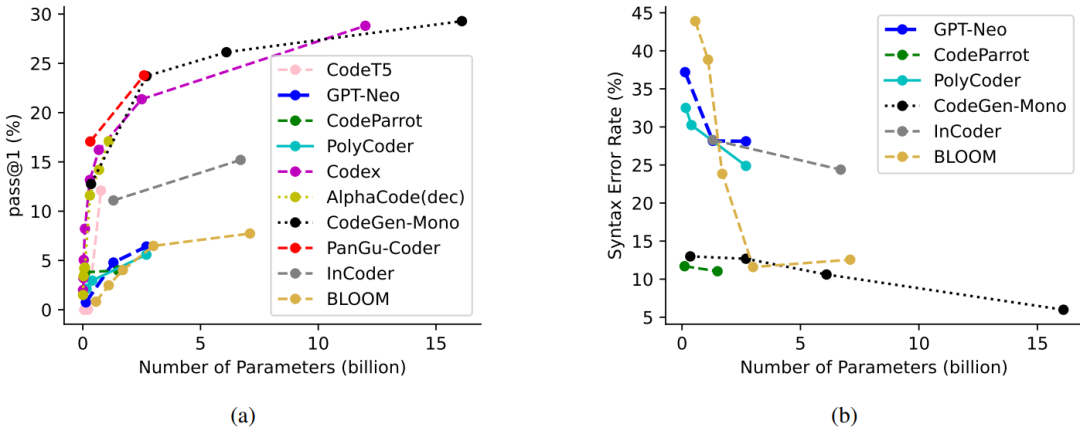
根據上圖,很明顯的可以「發現較大的模型通常會產生更好的結果」。此外,「當前模型無論大小,仍然可以通過進一步增加模型參數來實現性能的提升」。
數據質量
隨著LLMs模型參數的增加,其訓練數據規模也在不斷的增加。這在數據選擇和預處理方面也有更高的要求。早期的模型,例如CodeSearchNet、CoST、XLCoST等都是基于人工標注數據對進行訓練(耗時耗力);GPT系列模型(GPT-3 、GPT-Neo、GPT-J )開始在大規模無監督數據集上進行訓練,但是由于代碼數據限制,并沒有顯示出很強的代碼生成能力。由于LLMs模型的出現,它們可以在更大規模的未標記代碼數據集上進行訓練,最終模型效果驚人。
在驚嘆于LLMs效果的同時,也要知道LLMs在訓練之前通常會對數據進行預處理。為此作者調研了Codex、AlphaCode、CodeGen、InCoder和PyCodeGPT等5個強大模型的數據預處理方法。發現它們具有幾個共同的特點:一是刪除可能自動生成或未完成的代碼文件,二是使用特定的規則來過濾不常見的代碼文件。「總之,這些預處理策略的目標是實現一個不重復的、完整的、正確的、干凈的和通用的代碼語料庫」。
專家調優
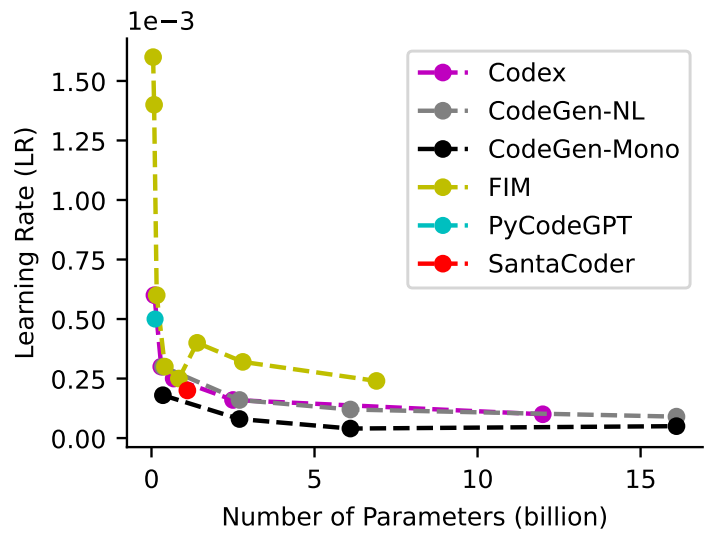
訓練一個優秀的模型需要認真考慮模型訓練階段的各個參數。通過對27個LLMs模型的研究發現,它們都有一些共同的設置,比如都應用了Adam相關優化器并在初始化階段相差不大。除此之外,還有需要調節的超參數,如lr、batch、窗口大小、預熱、梯度累積和temperature。對于學習率來說,隨著模型的增大,學習率會逐步變小。如下圖所示:
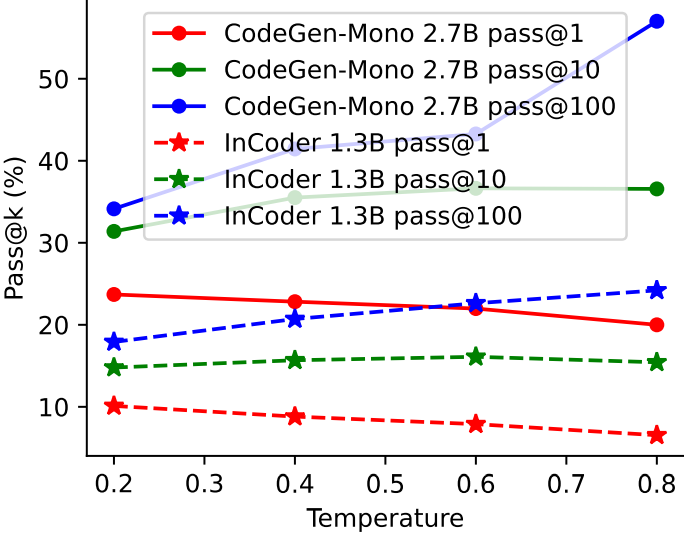
對于temperature,這里對比了兩個模型在HumanEval任務上使用不同temperature后模型的性能。結果發現,更高的temperature產生更低的pass@1和更高的pass@100,這表明更高的temperature使LLM產生更多樣化的預測,反之亦然。如下圖所示:
此外,有研究表明窗口大小也是一個關鍵因素,具有大窗口的小模型會有時優于具有小窗口的大模型。此外,強大的LLMs通常主要使用兩種技術在代碼語料庫上訓練新的標記器:字節級字節對編碼和sentencepece 。新的標記器可以更有效和準確地將代碼內容拆分為Tokens。這些經過驗證的調優技術將為培訓更強大的llm提供有價值的參考。
評估基準指標
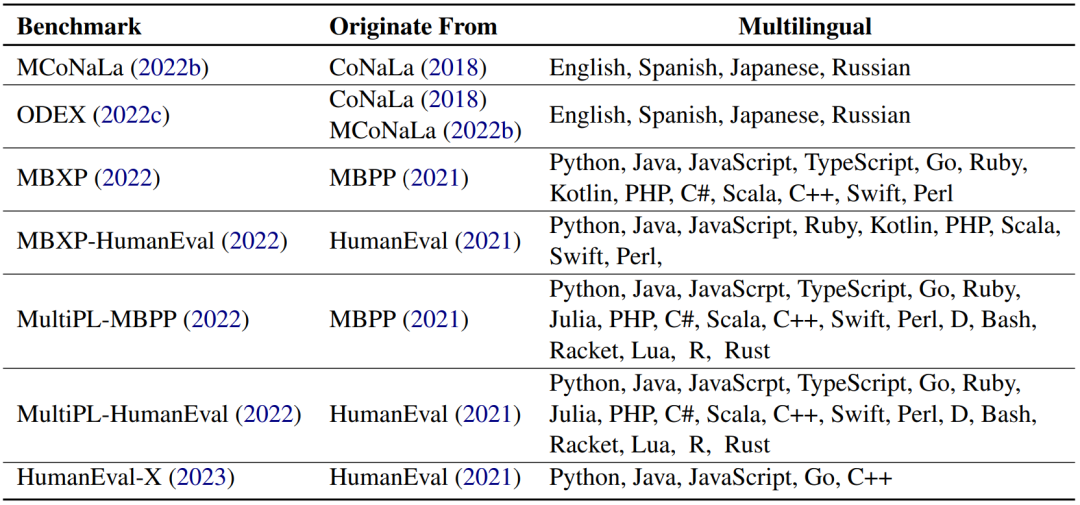
「對NL2Code任務的評估,高質量的基準和可靠的度量是基礎和必要的」。作者總結了17個NL2Code基準測試,每個基準測試在大小、語言、復雜性和場景方面都有自己的特點,如下表所示。
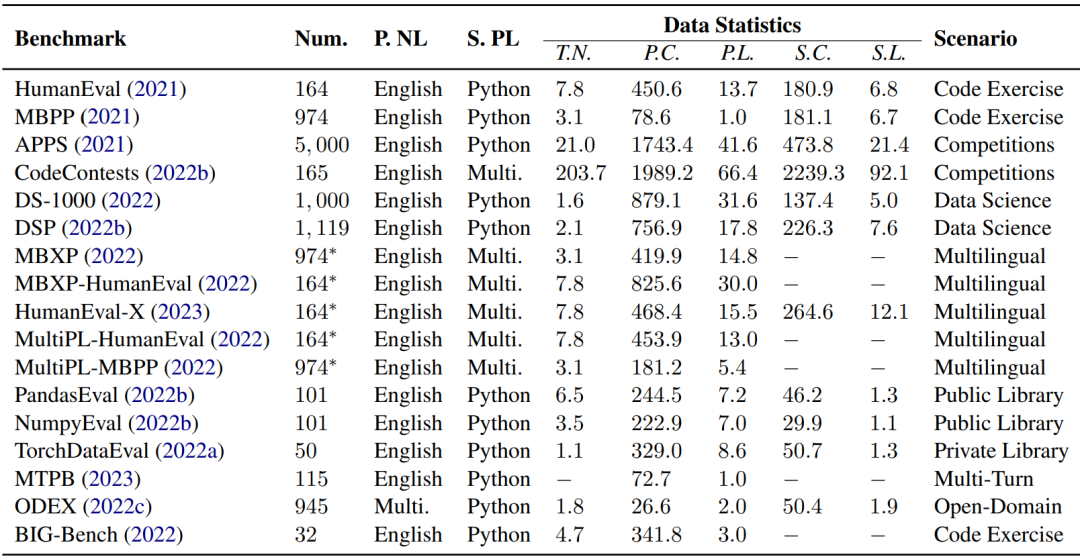
但大多數基準測試只包含有限數量的實例。例如,HumanEval和MBPP分別有164和974個實例。這是因為這些基準通常是手寫的以防數據泄露。「在大型語言模型時代,在創建新基準時避免數據泄漏至關重要」。此外,大多數當前的基準測試都有英文的問題描述和Python的代碼解決方案。最近,已經提出了幾個多語言基準,例如涵蓋「多種編程語言的MBXP,HumanEvalX和MultiPL ,以及涵蓋多種自然語言的ODEX」。多語言基準測試的詳細信息如下表所示:
「手動評估生成的代碼是不切實際的,這就需要自動度量」。上述基準均提供了基于執行的評估的測試用例,其中指標如 pass@k、n@k、測試用例平均值和執行精度。但是,「這種方法對測試用例的質量有嚴格的要求,并且只能評估可執行代碼。對于不可執行的代碼」,使用了 BLEU 、ROUGE 和 CodeBLEU等指標,無法準確評估代碼的正確性。到目前為止,「在設計指標來評估代碼的各個方面(例如漏洞、可維護性、清晰度、執行復雜性和穩定性)方面存在許多開放性挑戰」。
NL2Code挑戰與機遇
大預言模型在NL2Code的應用對學術界和工業界都有相當大的影響。雖然取得了驚人的進展,但仍然有很多挑戰需求解決,這也為研究人員提供了充足的機會。下面作者總結了 NL2Code任務的五個挑戰和機會。
「1、理解能力」:人類能夠理解不同抽象層次的各種描述, 相比之下,當前的 LLM 往往對給定的上下文敏感,這可能會導致性能下降。作者認為探索LLM的理解能力是一個重要的研究方向。
「2、判斷能力」:人類能夠判定一個編程問題是否被解決。當前模型不論輸入什么都會給出答案,而且該答案正確與否都不能確定,這在實際應用中會存在一定的問題。目前為了提高LLM的判斷能力,需要根據用戶反饋采用強化學習的方式進行調優。作者認為探索LLM自我判斷能力,也是一個比較重要的研究方向。
「3、解釋能力」:人類開發人員能夠解釋他們編寫的代碼,這對教育的和軟件維護至關重要。最近的研究表明,LLM 具有自動生成代碼解釋的潛力。作者認為針對該能力也需要進一步的研究和探索,以充分發揮LLM在這方面的潛力。
「4、自適應能力」:當前的大型語言模型與人類之間的一個根本區別是它們適應新知識和更新知識的能力。人類開發人員能夠根據文檔資料實現API的快速開發,而LLM需要大量的知識和訓練。作者認為如何提高LLM快速自學習能力也是一個比較大挑戰。
「5、多任務處理能力」:LLM在多任務處理方面與人類存在較大差異。人類可以在任務之間無縫切換,而LLM可能需要復雜的提示工程。為此作者任務提升LLM多任務能力同樣是一個重要的研究方向。
審核編輯 :李倩
-
語言模型
+關注
關注
0文章
521瀏覽量
10268 -
python
+關注
關注
56文章
4793瀏覽量
84632 -
自然語言
+關注
關注
1文章
288瀏覽量
13347
原文標題:ACL2023 | 中科院 針對NL2Code任務,調研了27個大模型,并指出5個重要挑戰
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI模型部署邊緣設備的奇妙之旅:目標檢測模型
從零開始訓練一個大語言模型需要投資多少錢?

開啟全新AI時代 智能嵌入式系統快速發展——“第六屆國產嵌入式操作系統技術與產業發展論壇”圓滿結束
如何使用freeRTOS在兩個任務之間傳輸任務數據?
中科院重慶研究院在勢壘可光調諧新型肖特基紅外探測器研究獲進展
【大語言模型:原理與工程實踐】大語言模型的應用
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
中科加禾完成天使輪數千萬元融資,專注編譯技術,推動國產算力和大數據發展
湖南大學校長、王耀南院士一行赴中科億海微調研指導






 工商網監
工商網監
評論