 編譯器的亂序策略
編譯器的亂序策略
很多現代高級語言多提供了多線程并發技術,今天服務器CPU基本上都是多核架構,在Java中,JVM能夠根據處理器特性(CPU多級緩存系統、多核處理器等)適當對機器指令進行重排序,最大限度發揮機器性能。Java中的指令重排有兩次,第一次發生在將字節碼編譯成機器碼的階段,第二次發生在CPU執行的時候,也會適當對指令進行重排。
寫這篇文章的目的,是想明確下cpu指令亂序這件事。只要是熟悉計算機底層系統的同學就會知道,程序里面的每行代碼的執行順序,有可能會被編譯器和cpu根據某種策略,給打亂掉,目的是為了性能的提升,讓指令的執行能夠盡可能的并行起來。
知道指令的亂序策略很重要,原因是這樣我們就能夠通過barrier(內存屏障)等指令,在正確的位置告訴cpu或者是編譯器,這里我可以接受亂序,那里我不能接受亂序等等。從而,能夠在保證代碼正確性的前提下,最大限度地發揮機器的性能。
10多年前的程序員對處理器亂序執行和內存屏障應該是很熟悉的,但隨著計算機技術突飛猛進的發展,我們離底層原理越來越遠,這并不是一件壞事,但在有些情況下了解一些底層原理有助于我們更好的工作,比如現代高級語言多提供了多線程并發技術,如果不深入下來,那么有些由多線程造成問題就很難排查和理解。
前言
這里我不打算討論編譯器的亂序策略,這里討論的指令亂序,含義稍廣些,包括在多核上分別執行的指令間,在時間維度上的亂序。
如果在多核cpu層面考慮亂序執行的話,我們要來梳理清楚以下幾個概念:單核和多核,亂序執行和順序提交,store buffer和invalid queue。最后會對x86和arm/power架構的異同,做一個總結。
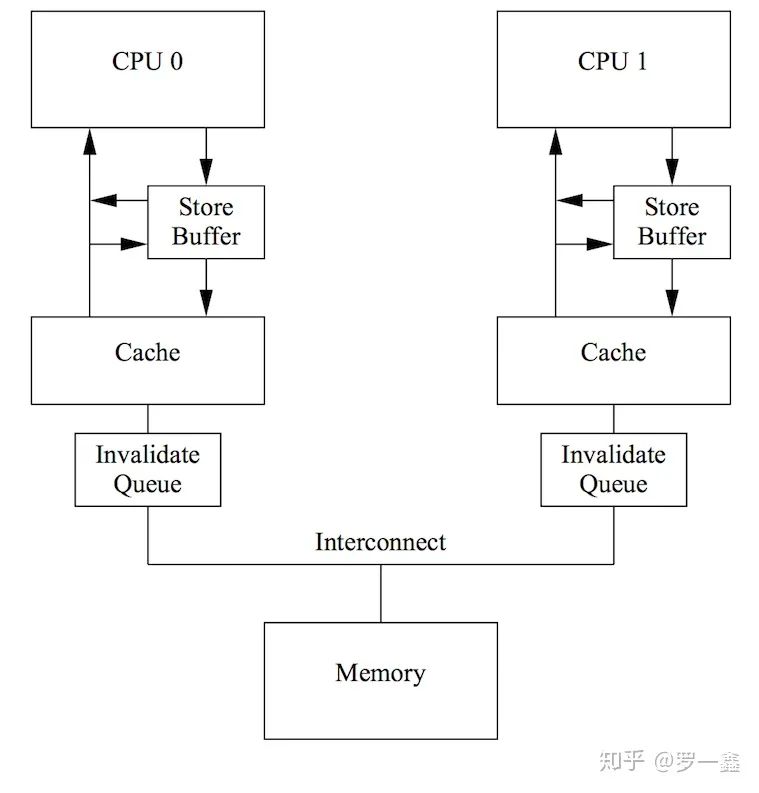
單核 vs 多核
從多核的視角上來說,是存在著亂序的可能的。比如,假設存在變量x = 0,cpu0上執行寫入W0(x, 1),對x寫入1。接著在cpu1上,執行讀取R1(x, 0),得到x = 0,這在x86和arm/power的cpu上都是可能出現的。原因是x86上cpu核和cache以及內存之間,存在著store buffer,當W0(x, 1)執行成功后,修改只存在于store buffer中,并未寫到cache以及內存上,因此cpu1讀取不到最新的x值。對于arm/power來說,同樣也有store buffer,而且還可能會有invalid queue,導致cpu1讀不到最新的x值。
對于沒有invalid queue的x86系列cpu來說,當修改從store buffer刷入cache時,就能夠保證在其他核上能夠讀到最新的修改。但是,對于存在invalid queue的cpu來說,則不一定。
為了能夠保證多核之間的修改的可見性,我們在寫程序的時候需要加上內存屏障,例如x86上的mfence指令。
亂序執行 vs 順序提交
我們知道,在cpu中為了能夠讓指令的執行盡可能地并行起來,從而發明了流水線技術。但是如果兩條指令的前后存在依賴關系,比如數據依賴,控制依賴等,此時后一條語句就必需等到前一條指令完成后,才能開始。
cpu為了提高流水線的運行效率,會做出比如:
1)對無依賴的前后指令做適當的亂序和調度;
2)對控制依賴的指令做分支預測;
3)對讀取內存等的耗時操作,做提前預讀;
等等。以上總總,都會導致指令亂序的可能。
但是對于x86的cpu來說,在單核視角上,其實它做出了Sequential consistency[1]的一致性保障。Sequential consistency的在wiki上的定義如下:
"... the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program."
也就是說,要滿足Sequential consistency,必需保障每個處理器的指令執行順序必需和程序給出的順序一致。奇怪吧?這不就和我剛才說的指令亂序優化矛盾了嘛?其實并不矛盾,指令在cpu核內部確實是亂序執行和調度的,但是它們對外表現卻是順序提交的。
如果把ISA寄存器(如EAX,EBX等)和store buffer,作為cpu對外的接口的話,cpu只需要把內部真實的物理寄存器按照指令的執行順序,順序映射到ISA寄存器上,也就是cpu只要將結果順序地提交到ISA寄存器,就可以保證Sequential consistency。
當然,以上是對x86架構的cpu來說的,ARM/Power架構的cpu在單核上的一致性保證要弱一些,無需保證Sequential consistency,因此也不需要順序提交,只需保證控制依賴,數據依賴,地址依賴等指令的順序即可。要想在這些弱一致性模型cpu下保證無關指令間的提交順序,需要使用barrier指令。
Store Buffer & Invalid Queue
store buffer存在于cpu核與cache之間,對于x86架構來說,store buffer是FIFO,因此不會存在亂序,寫入順序就是刷入cache的順序。但是對于ARM/Power架構來說,store buffer并未保證FIFO,因此先寫入store buffer的數據,是有可能比后寫入store buffer的數據晚刷入cache的。從這點上來說,store buffer的存在會讓ARM/Power架構出現亂序的可能。store barrier存在的意義就是將store buffer中的數據,刷入cache。
在某些cpu中,存在invalid queue。invalid queue用于緩存cache line的失效消息,也就是說,當cpu0寫入W0(x, 1),并從store buffer將修改刷入cache,此時cpu1讀取R1(x, 0)仍是允許的。因為使cache line失效的消息被緩沖在了invalid queue中,還未被應用到cache line上。這也是一種會使得指令亂序的可能。load barrier存在的意義就是將invalid queue緩沖刷新。
X86 vs ARM/Power
對于x86架構的cpu來說,在單核上來看,其保證了Sequential consistency,因此對于開發者,我們可以完全不用擔心單核上的亂序優化會給我們的程序帶來正確性問題。在多核上來看,其保證了x86-tso模型,使用mfence就可以將store buffer中的數據,寫入到cache中。而且,由于x86架構下,store buffer是FIFO的和不存在invalid queue,mfence能夠保證多核間的數據可見性,以及順序性。[2]
對于arm和power架構的cpu來說,編程就變得危險多了。除了存在數據依賴,控制依賴以及地址依賴等的前后指令不能被亂序之外,其余指令間都有可能存在亂序。而且,它們的store buffer并不是FIFO的,而且還可能存在invalid queue,這些也同樣讓并發編程變得困難重重。因此需要引入不同類型的barrier來完成不同的需求。[3]
總結
從上面的介紹可以知道,開發者想要做好并發編程是多么困難的事情,但是我們至少跨出了第一步,也就是定義困難本身。
-
處理器
+關注
關注
68文章
19259瀏覽量
229653 -
計算機
+關注
關注
19文章
7488瀏覽量
87852 -
編譯器
+關注
關注
1文章
1623瀏覽量
49108
原文標題:當我們在談論 cpu 指令亂序的時候,究竟在談論什么?
文章出處:【微信號:良許Linux,微信公眾號:良許Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于CoSy的編譯器開發的研究

編譯器是如何工作的_編譯器的工作過程詳解
編譯器原理到底是怎樣的帶你簡單的了解編譯器原理
Verilog HDL 編譯器指令說明

GH集成開發環境和編譯器
交叉編譯器安裝教程
領域編譯器發展的前世今生
當我們在談論cpu指令亂序的時候,究竟在談論什么?
編譯器的優化選項





 工商網監
工商網監
評論