") CUDA Runtime和L2 Cache簡析
CUDA Runtime和L2 Cache簡析
CUDA Runtime
運行時在cudart庫中實現(xiàn),該庫通過cudart靜態(tài)地鏈接到應(yīng)用程序。
所有入口都有cuda的前綴。
正如在異構(gòu)編程中提到的,CUDA編程模型假設(shè)一個由主機和設(shè)備組成的系統(tǒng),每個設(shè)備都有自己的獨立內(nèi)存。
Initialization
運行時沒有顯式的初始化函數(shù)。 它在第一次調(diào)用運行時函數(shù) (更確切地說,是參考手冊中錯誤處理和版本管理部分的函數(shù)以外的任何函數(shù)) 時初始化 。
運行時為系統(tǒng)中的每個設(shè)備創(chuàng)建一個CUDA Context 。該上下文是該設(shè)備的primary context, 在該設(shè)備上需要活動上下文的第一個運行時函數(shù)時初始化 。 它在應(yīng)用程序的所有主機線程之間共享 。 作為創(chuàng)建上下文的一部分,如果需要的話,設(shè)備代碼將被實時編譯并加載到設(shè)備內(nèi)存中 。這一切都是透明的。如果需要,例如,為了驅(qū)動API的互操作性,可以從驅(qū)動API訪問設(shè)備的主上下文。
當(dāng)主機線程調(diào)用cudaDeviceReset()時,這將銷毀主機線程當(dāng)前操作的設(shè)備的 primary context (即在device Selection中定義的當(dāng)前設(shè)備)。當(dāng)前擁有該設(shè)備的任何主機線程的下一個運行時函數(shù)調(diào)用將為該設(shè)備創(chuàng)建一個新的 primary context。
注意:CUDA接口使用全局狀態(tài),該狀態(tài)在主機程序啟動時初始化,在主機程序終止時銷毀。CUDA運行時和驅(qū)動程序無法檢測此狀態(tài)是否無效,因此在程序啟動或main后終止期間使用任何這些接口(隱式或顯式)將導(dǎo)致未定義的行為。
Device Memory
正如在異構(gòu)編程中提到的,CUDA編程模型假設(shè)一個由主機和設(shè)備組成的系統(tǒng),每個設(shè)備都有自己的獨立內(nèi)存。內(nèi)核在設(shè)備內(nèi)存之外運行,因此運行時提供了分配、釋放和復(fù)制設(shè)備內(nèi)存的函數(shù),以及在主機內(nèi)存和設(shè)備內(nèi)存之間傳輸數(shù)據(jù)。
設(shè)備內(nèi)存可以分配作為linear memory 或 CUDA arrays。
- CUDA arrays 是為 texture fetching 優(yōu)化的不透明內(nèi)存布局。
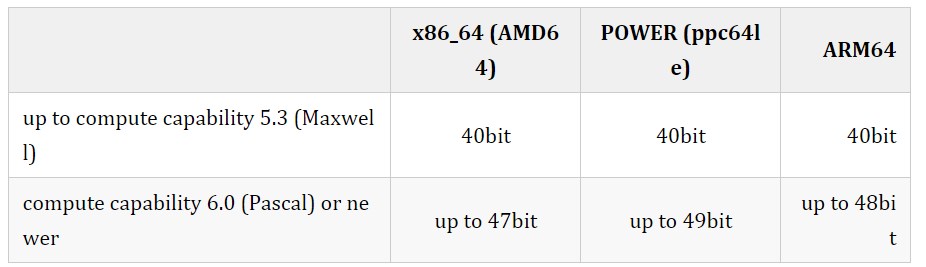
- Linear memory 在單一的統(tǒng)一地址空間中分配,這意味著分別分配的實體可以通過指針相互引用,例如,在二叉樹或鏈表中。地址空間的大小取決于主機系統(tǒng)(CPU)和使用的GPU的計算能力.
Graphics Interoperability 介紹了運行時提供的與兩個主要圖形API,OpenGL和 Direct3D互操作的各種功能。
Texture and Surface Memory 提供了紋理和表面存儲器空間,提供了訪問設(shè)備內(nèi)存的另一種方式;它們還公開了GPU紋理硬件的一個子集。
Call Stack 提到了用于管理CUDA c++調(diào)用棧的運行時函數(shù)。
Error Checking 描述如何正確檢查運行時生成的錯誤。
Multi-Device System 展示了編程模型如何擴展到具有多個設(shè)備連接到同一主機的系統(tǒng)。
Asynchronous Concurrent Execution 描述了用于在系統(tǒng)的各個級別上支持異步并發(fā)執(zhí)行的概念和API。
Page-Locked Host Memory 引入了頁鎖定主機內(nèi)存,它需要在內(nèi)核執(zhí)行與主機和設(shè)備內(nèi)存之間的數(shù)據(jù)傳輸重疊。
Shared Memory演示了如何使用線程層次結(jié)構(gòu)中引入的共享內(nèi)存來最大化性能。
Linear memory 通常使用 cudaMalloc() 分配,使用cudaFree()釋放,主機內(nèi)存和設(shè)備內(nèi)存之間的數(shù)據(jù)傳輸通常使用cudaMemcpy()完成。在kernel的vector加法代碼示例中,需要將vector從主機內(nèi)存復(fù)制到設(shè)備內(nèi)存:
// Device code
__global__
void
VecAdd
(
float
* A,
float
* B,
float
* C,
int
N)
{
int
i = blockDim.x * blockIdx.x + threadIdx.x;
if
(i < N)
C[i] = A[i] + B[i];
}
// Host code
int
main
()
{
int
N = ...;
size_t
size = N *
sizeof
(
float
);
// Allocate input vectors h_A and h_B in host memory
float
* h_A = (
float
*)
malloc
(size);
float
* h_B = (
float
*)
malloc
(size);
float
* h_C = (
float
*)
malloc
(size);
// Initialize input vectors
...
// Allocate vectors in device memory
float
* d_A;
cudaMalloc(&d_A, size);
float
* d_B;
cudaMalloc(&d_B, size);
float
* d_C;
cudaMalloc(&d_C, size);
// Copy vectors from host memory to device memory
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// Invoke kernel
int
threadsPerBlock =
256
;
int
blocksPerGrid =
(N + threadsPerBlock -
1
) / threadsPerBlock;
VecAdd<<
// Copy result from device memory to host memory
// h_C contains the result in host memory
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// Free host memory
...
}
Linear memory 也可以通過cudaMallocPitch()和cudaMalloc3D()來分配。這些函數(shù)被推薦用于2D或3D數(shù)組的分配,因為它確保分配被適當(dāng)填充,以滿足設(shè)備內(nèi)存訪問中描述的對齊要求,因此在訪問行地址或在2D數(shù)組和設(shè)備內(nèi)存的其他區(qū)域之間執(zhí)行復(fù)制時(使用cudaMemcpy2D()和cudaMemcpy3D()函數(shù))確保最佳性能。返回的pitch(或stride)必須用于訪問數(shù)組元素。
- 下面的代碼示例分配了一個 width x height 的二維浮點值數(shù)組,并展示了如何在設(shè)備代碼中循環(huán)遍歷數(shù)組元素:
// Host code
int
width =
64
, height =
64
;
float
* devPtr;
size_t
pitch;
cudaMallocPitch(&devPtr, &pitch,
width *
sizeof
(
float
), height);
MyKernel<<<
100
,
512
>>>(devPtr, pitch, width, height);
// Device code
__global__
void
MyKernel
(
float
* devPtr,
size_t
pitch,
int
width,
int
height)
{
for
(
int
r =
0
; r < height; ++r) {
float
* row = (
float
*)((
char
*)devPtr + r * pitch);
for
(
int
c =
0
; c < width; ++c) {
float
element = row[c];
}
}
}
- 下面的代碼示例分配了一個 width x height x depth 的浮點值3D數(shù)組,并展示了如何在設(shè)備代碼中循環(huán)遍歷數(shù)組元素:
// Host code
int
width =
64
, height =
64
, depth =
64
;
cudaExtent extent = make_cudaExtent(width *
sizeof
(
float
),
height, depth);
cudaPitchedPtr devPitchedPtr;
cudaMalloc3D(&devPitchedPtr, extent);
MyKernel<<<
100
,
512
>>>(devPitchedPtr, width, height, depth);
// Device code
__global__
void
MyKernel
(cudaPitchedPtr devPitchedPtr,
int
width,
int
height,
int
depth)
{
char
* devPtr = devPitchedPtr.ptr;
size_t
pitch = devPitchedPtr.pitch;
size_t
slicePitch = pitch * height;
for
(
int
z =
0
; z < depth; ++z) {
char
* slice = devPtr + z * slicePitch;
for
(
int
y =
0
; y < height; ++y) {
float
* row = (
float
*)(slice + y * pitch);
for
(
int
x =
0
; x < width; ++x) {
float
element = row[x];
}
}
}
}
下面的代碼示例演示了通過運行時API訪問全局變量的各種方法:
__constant__
float
constData[
256
];
float
data[
256
];
cudaMemcpyToSymbol(constData, data,
sizeof
(data));
cudaMemcpyFromSymbol(data, constData,
sizeof
(data));
__device__
float
devData;
float
value =
3.14f
;
cudaMemcpyToSymbol(devData, &value,
sizeof
(
float
));
__device__
float
* devPointer;
float
* ptr;
cudaMalloc(&ptr,
256
*
sizeof
(
float
));
cudaMemcpyToSymbol(devPointer, &ptr,
sizeof
(ptr));
cudaGetSymbolAddress()用于檢索指向分配給在全局內(nèi)存空間中聲明的變量的內(nèi)存的地址。所分配內(nèi)存的大小通過cudaGetSymbolSize()獲得。
Device Memory L2 Access Management
當(dāng)CUDA內(nèi)核重復(fù)訪問全局內(nèi)存中的數(shù)據(jù)區(qū)域時,可以認(rèn)為這種數(shù)據(jù)訪問是 persisting 。
另一方面,如果數(shù)據(jù)只被訪問一次,則可以將這種數(shù)據(jù)訪問視為 streaming 。
從CUDA 11.0開始,具有8.0及以上計算能力的設(shè)備能夠影響L2緩存中的數(shù)據(jù)持久性,從而可能提供更高的帶寬和更低的全局內(nèi)存訪問延遲。
L2 cache Set-Aside for Persisting Accesses
L2緩存的一部分可以被預(yù)留出來,用于持久化對全局內(nèi)存的數(shù)據(jù)訪問 。持久化訪問優(yōu)先使用L2緩存的預(yù)留部分,而正常的或流的全局內(nèi)存訪問只能在持久化訪問未使用時使用L2的這部分。
用于持久化訪問的L2緩存預(yù)留大小可以在限制范圍內(nèi)進行調(diào)整:
cudaGetDeviceProperties(&prop, device_id);
size_t
size = min(
int
(prop.l2CacheSize *
0.75
), prop.persistingL2CacheMaxSize);
cudaDeviceSetLimit(cudaLimitPersistingL2CacheSize, size);
/* set-aside 3/4 of L2 cache for persisting accesses or the max allowed*/
當(dāng)GPU配置為MIG (Multi-Instance GPU)模式時,L2緩存預(yù)留功能不可用。
當(dāng)使用多進程服務(wù)(MPS)時,L2緩存預(yù)留大小不能通過cudaDeviceSetLimit來改變。相反,只能在啟動MPS服務(wù)器時通過環(huán)境變量CUDA_DEVICE_DEFAULT_PERSISTING_L2_CACHE_PERCENTAGE_LIMIT指定預(yù)留大小。
L2 Policy for Persisting Accesses
訪問策略窗口指定全局內(nèi)存的連續(xù)區(qū)域和L2緩存中的持久性屬性,以便在該區(qū)域內(nèi)進行訪問。
下面的代碼示例展示了如何使用CUDA流設(shè)置L2持久化訪問窗口。
- CUDA Stream Example
cudaStreamAttrValue stream_attribute;
// Stream level attributes data structure
stream_attribute.accessPolicyWindow.base_ptr =
reinterpret_cast
<
void
*>(ptr);
// Global Memory data pointer
stream_attribute.accessPolicyWindow.num_bytes = num_bytes;
// Number of bytes for persistence access.
// (Must be less than cudaDeviceProp::accessPolicyMaxWindowSize)
stream_attribute.accessPolicyWindow.hitRatio =
0.6
;
// Hint for cache hit ratio
stream_attribute.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting;
// Type of access property on cache hit
stream_attribute.accessPolicyWindow.missProp = cudaAccessPropertyStreaming;
// Type of access property on cache miss.
//Set the attributes to a CUDA stream of type cudaStream_t
cudaStreamSetAttribute(stream, cudaStreamAttributeAccessPolicyWindow, &stream_attribute);
當(dāng)內(nèi)核隨后在CUDA stream 中執(zhí)行時,全局內(nèi)存范圍 [ptr..ptr+num_bytes] 內(nèi)的內(nèi)存訪問比訪問其他全局內(nèi)存位置更有可能持久存在L2緩存中。
- CUDA GraphKernelNode Example
cudaKernelNodeAttrValue node_attribute;
// Kernel level attributes data structure
node_attribute.accessPolicyWindow.base_ptr =
reinterpret_cast
<
void
*>(ptr);
// Global Memory data pointer
node_attribute.accessPolicyWindow.num_bytes = num_bytes;
// Number of bytes for persistence access.
// (Must be less than cudaDeviceProp::accessPolicyMaxWindowSize)
node_attribute.accessPolicyWindow.hitRatio =
0.6
;
// Hint for cache hit ratio
node_attribute.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting;
// Type of access property on cache hit
node_attribute.accessPolicyWindow.missProp = cudaAccessPropertyStreaming;
// Type of access property on cache miss.
//Set the attributes to a CUDA Graph Kernel node of type cudaGraphNode_t
cudaGraphKernelNodeSetAttribute(node, cudaKernelNodeAttributeAccessPolicyWindow, &node_attribute);
可以使用hitRatio參數(shù)指定接收hitProp屬性的訪問的比例。在上面的兩個示例中,全局內(nèi)存區(qū)域中60%的內(nèi)存訪問[ptr..ptr+num_bytes]具有持久化屬性,40%的內(nèi)存訪問具有流屬性。哪些特定的內(nèi)存訪問被分類為持久化(hitProp)是隨機的,概率近似于hitRatio;概率分布取決于硬件架構(gòu)和內(nèi)存大小。
例如,如果L2預(yù)留緩存大小為16KB,而accessPolicyWindow中的num_bytes為32KB:
- 當(dāng)命中率為0.5時,硬件將隨機選擇32KB窗口中的16KB指定為持久化并緩存到預(yù)留的L2緩存區(qū)。
- 當(dāng)hitRatio為1.0時,硬件將嘗試將整個32KB窗口緩存到預(yù)留的L2緩存區(qū)。由于預(yù)留區(qū)域比窗口小,緩存行將被刪除,以將最近使用的16KB數(shù)據(jù)保存在L2緩存的預(yù)留部分。
因此,可以使用hitRatio來避免緩存線的抖動,并從總體上減少移動到L2緩存和移出的數(shù)據(jù)量。
hitRatio值低于1.0可用于手動控制與并發(fā)CUDA流不同的accessPolicyWindows可以在L2中緩存的數(shù)據(jù)量。例如,設(shè)L2預(yù)留緩存大小為16KB;在兩個不同的CUDA流中的兩個并發(fā)內(nèi)核,每個都具有16KB的accessPolicyWindow,并且都具有1.0的hitRatio值,在競爭共享的L2資源時,可能會驅(qū)逐彼此的緩存線。但是,如果兩個accessPolicyWindows的hitRatio值都是0.5,它們就不太可能驅(qū)逐自己的或彼此的持久化緩存行。
L2 Access Properties
為不同的全局內(nèi)存數(shù)據(jù)訪問定義了三種類型的訪問屬性:
cudaAccessPropertyStreaming:帶有streaming屬性的內(nèi)存訪問不太可能持久存在L2緩存中,因為這些訪問會優(yōu)先被刪除。cudaAccessPropertyPersisting:具有persisting屬性的內(nèi)存訪問更有可能保存在L2緩存中,因為這些訪問優(yōu)先保存在L2緩存的預(yù)留部分。cudaAccessPropertyNormal: 這個訪問屬性強制重置之前應(yīng)用的持久化訪問屬性到正常狀態(tài)。來自以前CUDA內(nèi)核的具有持久化屬性的內(nèi)存訪問可能會在預(yù)期使用之后很長時間內(nèi)保留在L2緩存中。這種使用后持久化減少了不使用持久化屬性的后續(xù)內(nèi)核可用的L2緩存量。使用cudaAccessPropertyNormal屬性重置訪問屬性窗口將刪除先前訪問的持久(優(yōu)先保留)狀態(tài),就像先前訪問沒有訪問屬性一樣。
L2 Persistence Example
下面的例子展示了如何為持久訪問預(yù)留L2緩存,通過CUDA流在CUDA內(nèi)核中使用預(yù)留的L2緩存,然后重置L2緩存。
cudaStream_t stream;
cudaStreamCreate(&stream);
// Create CUDA stream
cudaDeviceProp prop;
// CUDA device properties variable
cudaGetDeviceProperties( &prop, device_id);
// Query GPU properties
size_t
size = min(
int
(prop.l2CacheSize *
0.75
) , prop.persistingL2CacheMaxSize );
cudaDeviceSetLimit( cudaLimitPersistingL2CacheSize, size);
// set-aside 3/4 of L2 cache for persisting accesses or the max allowed
size_t
window_size = min(prop.accessPolicyMaxWindowSize, num_bytes);
// Select minimum of user defined num_bytes and max window size.
cudaStreamAttrValue stream_attribute;
// Stream level attributes data structure
stream_attribute.accessPolicyWindow.base_ptr =
reinterpret_cast
<
void
*>(data1);
// Global Memory data pointer
stream_attribute.accessPolicyWindow.num_bytes = window_size;
// Number of bytes for persistence access
stream_attribute.accessPolicyWindow.hitRatio =
0.6
;
// Hint for cache hit ratio
stream_attribute.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting;
// Persistence Property
stream_attribute.accessPolicyWindow.missProp = cudaAccessPropertyStreaming;
// Type of access property on cache miss
cudaStreamSetAttribute(stream, cudaStreamAttributeAccessPolicyWindow, &stream_attribute);
// Set the attributes to a CUDA Stream
for
(
int
i =
0
; i <
10
; i++) {
cuda_kernelA<<
`
0
,stream>>>(data1);
// This data1 is used by a kernel multiple times
}
// [data1 + num_bytes) benefits from L2 persistence
cuda_kernelB<<,block_size,<>
0
,stream>>>(data1);
// A different kernel in the same stream can also benefit
// from the persistence of data1
stream_attribute.accessPolicyWindow.num_bytes =
0
;
// Setting the window size to 0 disable it
cudaStreamSetAttribute(stream, cudaStreamAttributeAccessPolicyWindow, &stream_attribute);
// Overwrite the access policy attribute to a CUDA Stream
cudaCtxResetPersistingL2Cache();
// Remove any persistent lines in L2
cuda_kernelC<<,block_size,<>
0
,stream>>>(data2);
// data2 can now benefit from full L2 in normal mode
Reset L2 Access to Normal
Reset L2 Access to Normal
來自上一個CUDA內(nèi)核的持久化L2緩存線可能在它被使用后很長一段時間內(nèi)持久化L2。因此,對于流或正常內(nèi)存訪問來說,L2緩存的正常優(yōu)先級重置為正常是很重要的。有三種方法可以將持久化訪問重置為正常狀態(tài)。
使用訪問屬性cudaAccessPropertyNormal設(shè)置先前的持久化內(nèi)存區(qū)域。
通過調(diào)用cudaCtxResetPersistingL2Cache()將所有持久化L2緩存線重置為正常。
最終未碰觸的線路會自動重置為正常。由于自動復(fù)位發(fā)生所需的時間長度不確定,因此強烈不鼓勵依賴自動復(fù)位。
Manage Utilization of L2 set-aside cache
Manage Utilization of L2 set-aside cache
在不同的CUDA流中并發(fā)執(zhí)行的多個CUDA內(nèi)核可能會為它們的流分配不同的訪問策略窗口。然而, L2預(yù)留緩存部分在所有這些并發(fā)CUDA內(nèi)核之間共享 。因此, 這個預(yù)留緩存部分的凈利用率是所有并發(fā)內(nèi)核單獨使用的總和 。當(dāng)持久化訪問的量超過預(yù)留的L2緩存容量時,將內(nèi)存訪問指定為持久化訪問的好處就會減少。
為了管理預(yù)留的L2緩存部分的利用率,應(yīng)用程序必須考慮以下因素:
L2預(yù)留緩存的大小。
可以并發(fā)執(zhí)行的CUDA內(nèi)核。
可并發(fā)執(zhí)行的所有CUDA內(nèi)核的訪問策略窗口。
需要在何時以及如何重置L2,以允許normal或streaming訪問以同等優(yōu)先級利用之前設(shè)置的L2緩存。
Query L2 cache Properties
Query L2 cache Properties
與L2緩存相關(guān)的屬性是cudaDeviceProp結(jié)構(gòu)的一部分,可以使用CUDA運行時API cudaGetDeviceProperties查詢.
CUDA設(shè)備屬性包括:
l2CacheSize: GPU上可用的L2緩存量。
persistingL2CacheMaxSize:可為持久內(nèi)存訪問預(yù)留的L2緩存的最大數(shù)量。
accessPolicyMaxWindowSize:訪問策略窗口的最大大小。
Control L2 Cache Set-Aside Size for Persisting Memory Access
Control L2 Cache Set-Aside Size for Persisting Memory Access
使用CUDA運行時API cudaDeviceGetLimit查詢用于持久化內(nèi)存訪問的L2預(yù)留緩存大小,并使用CUDA運行時API cudaDeviceSetLimit作為cudaLimit進行設(shè)置。該限制的最大值為cudaDeviceProp::persistingL2CacheMaxSize。
enum
cudaLimit {
/* other fields not shown */
cudaLimitPersistingL2CacheSize
};
-
MPS
+關(guān)注
關(guān)注
26文章
269瀏覽量
64351 -
CUDA
+關(guān)注
關(guān)注
0文章
121瀏覽量
13641 -
cache技術(shù)
+關(guān)注
關(guān)注
0文章
41瀏覽量
1065
發(fā)布評論請先 登錄
相關(guān)推薦
關(guān)于6678 cache的疑問
C674x 平臺(DM8148)數(shù)據(jù)從 DDR3 到 L1,L2,內(nèi)存及cache設(shè)置
請教關(guān)于C674x DSP L1 L2 及cache設(shè)置
在L1或者L2中可以配置為cache或者SRAM,請問cache的配置與什么有關(guān)?
在DSP/BIOS想將L2的64k配置成cache,請問需要怎么操作?
關(guān)于C6747片上RAM,請問shared RAM與L2又有何區(qū)別?
求解6678 L2做cache和 .text放ddr3的問題
請問6678 L2的數(shù)據(jù)搬移到DDR需要人為的進行cache一致性操作嗎?
L2 Cache配置方案那種更好?
請問L2怎么配置成128KRAM和128KCACHE?
介紹一種多級cache的包含策略(Cache inclusion policy)
ARM架構(gòu)下的L1和L2 cache結(jié)構(gòu)有什么聯(lián)系
如何獲取CPU中L1/L2的Cache狀態(tài)和大小?如何禁用和使能Cache呢?
Cache為什么還要分I-Cache,D-Cache,L2 Cache,作用是什么?
深入理解Cache工作原理





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論