


Shared Memory
共享內(nèi)存是使用__shared__內(nèi)存空間說明符分配的 。
共享內(nèi)存預(yù)期要比全局內(nèi)存快得多 。 它可以用作臨時存儲器(或軟件管理緩存),以最小化來自CUDA block 的全局內(nèi)存訪問 ,如下面的矩陣乘法示例所示。
下面的代碼示例是一個簡單的矩陣乘法實現(xiàn),它不利用共享內(nèi)存。每個線程讀取A的一行和B的一列,并計算C的相應(yīng)元素,如圖1所示。因此, A從全局內(nèi)存中讀取B的width次數(shù),B從全局內(nèi)存中讀取A的height次數(shù) 。
從左到右是x的方向,從上到下是y的方向。 (x,y) x是0-dim,y是1-dim,和正常的 shape 表示是反著的。
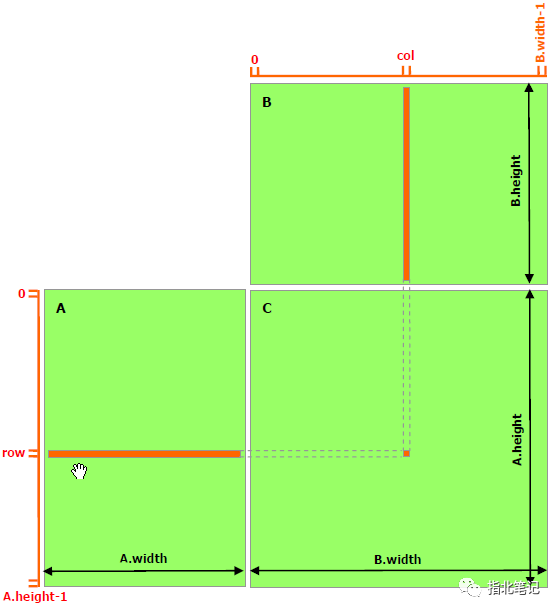
圖1 Matrix Multiplication without Shared Memory
// Matrices are stored in row-major order:
// M(row, col) = *(M.elements + row * M.width + col)
typedef struct {
int width;
int height;
float* elements;
} Matrix;
// Thread block size
#define BLOCK_SIZE 16
// Forward declaration of the matrix multiplication kernel
__global__ void MatMulKernel(const Matrix, const Matrix, Matrix);
// Matrix multiplication - Host code
// Matrix dimensions are assumed to be multiples of BLOCK_SIZE
void MatMul(const Matrix A, const Matrix B, Matrix C)
{
// Load A and B to device memory
Matrix d_A;
d_A.width = A.width; d_A.height = A.height;
size_t size = A.width * A.height * sizeof(float);
cudaMalloc(&d_A.elements, size);
cudaMemcpy(d_A.elements, A.elements, size,
cudaMemcpyHostToDevice);
Matrix d_B;
d_B.width = B.width; d_B.height = B.height;
size = B.width * B.height * sizeof(float);
cudaMalloc(&d_B.elements, size);
cudaMemcpy(d_B.elements, B.elements, size,
cudaMemcpyHostToDevice);
// Allocate C in device memory
Matrix d_C;
d_C.width = C.width; d_C.height = C.height;
size = C.width * C.height * sizeof(float);
cudaMalloc(&d_C.elements, size);
// Invoke kernel
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
MatMulKernel<<
下面的代碼示例是一個利用共享內(nèi)存的矩陣乘法的實現(xiàn)。在這個實現(xiàn)中, 每個線程塊負責計算C的一個方陣子矩陣Csub,塊中的每個線程負責計算Csub中的一個元素 。如圖2所示, Csub等于兩個矩形矩陣的乘積:一個是與Csub具有相同行索引的維數(shù)(A.width, block_size)的子矩陣,另一個是與Csub具有相同列索引的維數(shù)(block_size, A.width)的子矩陣 。為了適應(yīng)設(shè)備的資源,這兩個矩形矩陣根據(jù)需要被分成多個尺寸為block_size的方陣,Csub被計算為這些方陣乘積的和。每一個乘積都是這樣執(zhí)行的:首先將兩個對應(yīng)的方陣從全局內(nèi)存加載到共享內(nèi)存,由一個線程加載每個矩陣的一個元素,然后讓每個線程計算乘積的一個元素。每個線程將每個產(chǎn)品的結(jié)果累積到一個寄存器中,并將結(jié)果寫入全局內(nèi)存。

圖2 Matrix Multiplication with Shared Memory
通過這種方式阻塞計算,我們利用了快速共享內(nèi)存的優(yōu)勢,并節(jié)省了大量全局內(nèi)存帶寬, 因為A只從全局內(nèi)存讀取(B.width / block_size)次,而B是讀取(a.height / block_size)次 。
前面代碼示例中的Matrix類型使用stride字段進行了擴充,以便子矩陣可以有效地用相同的類型表示 。__device__函數(shù)用于獲取和設(shè)置元素,并從矩陣中構(gòu)建任何子矩陣。
// Matrices are stored in row-major order:
// M(row, col) = *(M.elements + row * M.stride + col)
typedef struct {
int width;
int height;
int stride;
float* elements;
} Matrix;
// Get a matrix element
__device__ float GetElement(const Matrix A, int row, int col)
{
return A.elements[row * A.stride + col];
}
// Set a matrix element
__device__ void SetElement(Matrix A, int row, int col,
float value)
{
A.elements[row * A.stride + col] = value;
}
// Get the BLOCK_SIZExBLOCK_SIZE sub-matrix Asub of A that is
// located col sub-matrices to the right and row sub-matrices down
// from the upper-left corner of A
__device__ Matrix GetSubMatrix(Matrix A, int row, int col)
{
Matrix Asub;
Asub.width = BLOCK_SIZE;
Asub.height = BLOCK_SIZE;
Asub.stride = A.stride;
Asub.elements = &A.elements[A.stride * BLOCK_SIZE * row
+ BLOCK_SIZE * col];
return Asub;
}
// Thread block size
#define BLOCK_SIZE 16
// Forward declaration of the matrix multiplication kernel
__global__ void MatMulKernel(const Matrix, const Matrix, Matrix);
// Matrix multiplication - Host code
// Matrix dimensions are assumed to be multiples of BLOCK_SIZE
void MatMul(const Matrix A, const Matrix B, Matrix C)
{
// Load A and B to device memory
Matrix d_A;
d_A.width = d_A.stride = A.width; d_A.height = A.height;
size_t size = A.width * A.height * sizeof(float);
cudaMalloc(&d_A.elements, size);
cudaMemcpy(d_A.elements, A.elements, size,
cudaMemcpyHostToDevice);
Matrix d_B;
d_B.width = d_B.stride = B.width; d_B.height = B.height;
size = B.width * B.height * sizeof(float);
cudaMalloc(&d_B.elements, size);
cudaMemcpy(d_B.elements, B.elements, size,
cudaMemcpyHostToDevice);
// Allocate C in device memory
Matrix d_C;
d_C.width = d_C.stride = C.width; d_C.height = C.height;
size = C.width * C.height * sizeof(float);
cudaMalloc(&d_C.elements, size);
// Invoke kernel
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
MatMulKernel<<
-
寄存器
+關(guān)注
關(guān)注
31文章
5433瀏覽量
124306 -
存儲器
+關(guān)注
關(guān)注
38文章
7648瀏覽量
167210 -
CUDA
+關(guān)注
關(guān)注
0文章
122瀏覽量
14113
發(fā)布評論請先 登錄
內(nèi)存共享原理解析
共享內(nèi)存IPC原理,Linux進程間如何共享內(nèi)存?
CUDA 6中的統(tǒng)一內(nèi)存模型
深入剖析Linux共享內(nèi)存原理
通過使用CUDA GPU共享內(nèi)存
CUDA簡介: CUDA編程模型概述
CUDA編程模型的統(tǒng)一內(nèi)存
Linux系統(tǒng)的共享內(nèi)存的使用
使用CUDA進行編程的要求有哪些
介紹CUDA編程模型及CUDA線程體系
CUDA編程分布式共享內(nèi)存
Linux進程間如何實現(xiàn)共享內(nèi)存通信
CUDA核心是什么?CUDA核心的工作原理






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論