

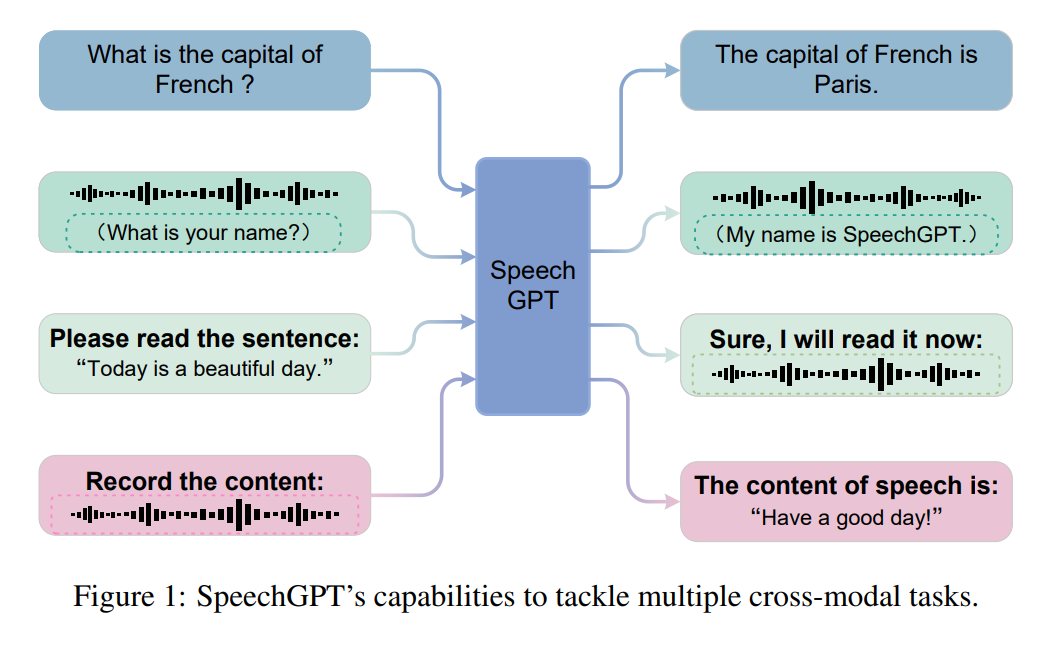
「 SpeechGPT 為打造真正的多模態大語言模型指明了方向:將不同模態的數據(視覺,語音等)統一表示為離散單元集成在 LLM 之中,在跨模態數據集上經過預訓練和指令微調,來使得模型具有多模態理解和生成的能力,從而離 AGI 更進一步。」—— 復旦大學計算機學院教授邱錫鵬

大型語言模型(LLM)在各種自然語言處理任務上表現出驚人的能力。與此同時,多模態大型語言模型,如 GPT-4、PALM-E 和 LLaVA,已經探索了 LLM 理解多模態信息的能力。然而,當前 LLM 與通用人工智能(AGI)之間仍存在顯著差距。首先,大多數當前 LLM 只能感知和理解多模態內容,而不能自然而然地生成多模態內容。其次,像圖像和語音這樣的連續信號不能直接適應接收離散 token 的 LLM。
當前的語音 - 語言(speech-language)模型主要采用級聯模式,即 LLM 與自動語音識別(ASR)模型或文本到語音(TTS)模型串聯連接,或者 LLM 作為控制中心,與多個語音處理模型集成以涵蓋多個音頻或語音任務。一些關于生成式口語語言模型的先前工作涉及將語音信號編碼為離散表示,并使用語言模型對其進行建模。
雖然現有的級聯方法或口語語言模型能夠感知和生成語音,但仍存在一些限制。首先,在級聯模型中,LLM 僅充當內容生成器。由于語音和文本的表示沒有對齊,LLM 的知識無法遷移到語音模態中。其次,級聯方法存在失去語音的附加語言信號(如情感和韻律)的問題。第三,現有的口語語言模型只能合成語音,而無法理解其語義信息,因此無法實現真正的跨模態感知和生成。
在本文中,來自復旦大學的張棟、邱錫鵬等研究者提出了 SpeechGPT,這是一個具有內生跨模態對話能力的大型語言模型,能夠感知和生成多模態內容。他們通過自監督訓練的語音模型對語音進行離散化處理,以統一語音和文本之間的模態。然后,他們將離散的語音 token 擴展到 LLM 的詞匯表中,從而賦予模型感知和生成語音的內生能力。

論文鏈接:https://arxiv.org/pdf/2305.11000.pdf
demo 地址:https://0nutation.github.io/SpeechGPT.github.io/
GitHub 地址:https://github.com/0nutation/SpeechGPT
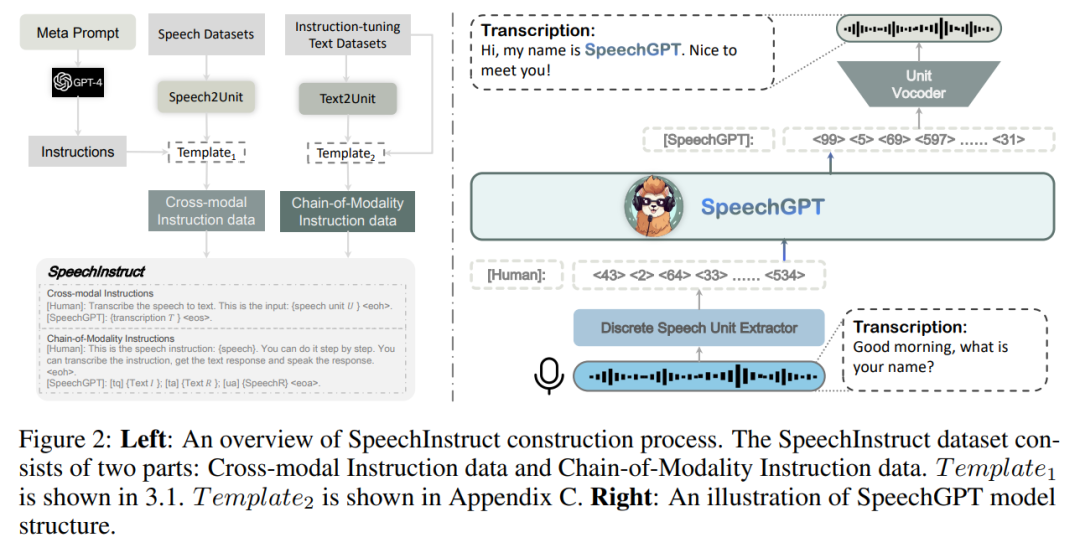
為了為模型提供處理多模態指令的能力,研究者構建了第一個語音 - 文本跨模態指令遵循數據集 SpeechInstruct。具體而言,他們將語音離散化為離散單元(discrete unit),并基于現有的 ASR 數據集構建跨模態的單元 - 文本(unit-text)對。同時,他們使用 GPT-4 構建了針對多個任務的數百個指令,以模擬實際用戶的指令,具體見附錄 B。此外,為了進一步增強模型的跨模態能力,他們設計了「Chain-of-Modality」指令數據,即模型接收語音命令,用文本思考過程,然后以語音形式輸出響應。
為了實現更好的跨模態遷移和高效的訓練,SpeechGPT 經歷了三個階段的訓練過程:模態適應預訓練、跨模態指令微調和 chain-of-modality 指令微調。第一階段通過離散語音單元連續任務實現了 SpeechGPT 的語音理解能力。第二階段利用 SpeechInstruct 改進了模型的跨模態能力。第三階段利用參數高效的 LoRA 微調進行進一步的模態對齊。
為了評估 SpeechGPT 的有效性,研究者進行了廣泛的人工評估和案例分析,以評估 SpeechGPT 在文本任務、語音 - 文本跨模態任務和口語對話任務上的性能。結果表明,SpeechGPT 在單模態和跨模態指令遵循任務以及口語對話任務方面展現出強大的能力。
SpeechInstruct
由于公開可用的語音數據的限制和語音 - 文本任務的多樣性不足,研究者構建了 SpeechInstruct,這是一個語音 - 文本跨模態指令遵循數據集。該數據集分為兩個部分,第一部分叫做跨模態指令,第二部分叫做 Chain-of-Modality 指令。SpeechInstruct 的構建過程如圖 2 所示。
SpeechGPT
研究者設計了一個統一的框架,以實現不同模態之間的架構兼容性。如圖 2 所示,他們的模型有三個主要組件:離散單元提取器、大型語言模型和單元聲碼器。在這個架構下,LLM 可以感知多模態輸入并生成多模態輸出。
離散單元提取器
離散單元提取器利用 Hidden-unit BERT(HuBERT)模型將連續的語音信號轉換為一系列離散單元的序列。
HuBERT 是一個自監督模型,它通過對模型的中間表示應用 k-means 聚類來為掩蔽的音頻片段預測離散標簽進行學習。它結合了 1-D 卷積層和一個 Transformer 編碼器,將語音編碼為連續的中間表示,然后使用 k-means 模型將這些表示轉換為一系列聚類索引的序列。隨后,相鄰的重復索引被移除,得到表示為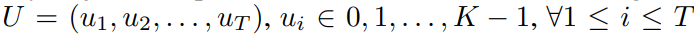 的離散單元序列,K 表示聚類總數。
的離散單元序列,K 表示聚類總數。
大型語言模型
研究者采用 Meta AI 的 LLaMA 模型作為他們的大型語言模型。LLaMA 包括一個嵌入層、多個 Transformer 塊和一個語言模型頭層。LLaMA 的參數總數范圍從 7B 到 65B 不等。通過使用包含 1.0 萬億 token 的大規模訓練數據集,LLaMA 在各種自然語言處理基準測試中展現出與規模更大的 175B GPT-3 相當的性能。
單元聲碼器
由于 (Polyak et al., 2021) 中單個說話人單元聲碼器的限制,研究者訓練了一個多說話人單元的 HiFi-GAN,用于從離散表示中解碼語音信號。HiFi-GAN 的架構包括一個生成器 G 和多個判別器 D。生成器使用查找表(Look-Up Tables,LUT)來嵌入離散表示,并通過一系列由轉置卷積和具有擴張層的殘差塊組成的模塊對嵌入序列進行上采樣。說話人嵌入被連接到上采樣序列中的每個幀上。判別器包括一個多周期判別器(Multi-Period Discriminator,MPD)和一個多尺度判別器(Multi-Scale Discriminator,MSD),其架構與 (Polyak et al., 2021) 相同。
實驗
跨模態指令遵循
如表 1 所示,當提供不同的指令時,模型能夠執行相應的任務并根據這些輸入生成準確的輸出。

口語對話
表 2 展示了 SpeechGPT 的 10 個口語對話案例。對話表明,在與人類的交互中,SpeechGPT 能夠理解語音指令并用語音作出相應回應,同時遵守「HHH」標準(無害、有幫助、誠實)。

局限性
盡管 SpeechGPT 展示出令人印象深刻的跨模態指令遵循和口語對話能力,但仍存在一些限制:
它不考慮語音中的語音外語言信息,例如無法以不同的情緒語調生成回應;
它在生成基于語音的回應之前需要生成基于文本的回應;
由于上下文長度的限制,它無法支持多輪對話。
審核編輯 :李倩
-
模態
+關注
關注
0文章
9瀏覽量
6335 -
語言模型
+關注
關注
0文章
558瀏覽量
10624 -
數據集
+關注
關注
4文章
1222瀏覽量
25231
原文標題:邱錫鵬團隊提出SpeechGPT:具有內生跨模態能力的大語言模型
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》
簡單的模型進行流固耦合的模態分析
可提高跨模態行人重識別算法精度的特征學習框架
基于預訓練視覺-語言模型的跨模態Prompt-Tuning

ACL2021的跨視覺語言模態論文之跨視覺語言模態任務與方法
百圖生科AIGP平臺發布:提供多種蛋白質生成能力,邀伙伴聯手開發“新物種”
利用大語言模型做多模態任務
邱錫鵬團隊提出具有內生跨模態能力的SpeechGPT,為多模態LLM指明方向

650億參數,8塊GPU就能全參數微調!邱錫鵬團隊把大模型門檻打下來了!


更強更通用:智源「悟道3.0」Emu多模態大模型開源,在多模態序列中「補全一切」

北大&華為提出:多模態基礎大模型的高效微調

自動駕駛和多模態大語言模型的發展歷程

機器人基于開源的多模態語言視覺大模型

?VLM(視覺語言模型)?詳細解析






 工商網監
工商網監

評論