


1引言
場景圖是一種結(jié)構(gòu)表示,它將圖片中的對象表示為節(jié)點,并將它們的關(guān)系表示為邊。最近,場景圖已成功應(yīng)用于不同的視覺任務(wù),例如圖像檢索[3]、目標(biāo)檢測、語義分割、圖像合成[4]和高級視覺-語言任務(wù)(如圖像字幕[1]或視覺問答[2]等)。它是一種具有豐富信息量的整體場景理解方法,可以連接視覺和自然語言領(lǐng)域之間巨大差距的橋梁。
雖然從單個圖像生成場景圖(靜態(tài)場景圖生成)取得了很大進(jìn)展,但從視頻生成場景圖(動態(tài)場景圖生成)的任務(wù)是新的且更具挑戰(zhàn)性。最流行的靜態(tài)場景圖生成方法是建立在對象檢測器之上的,然后推斷它們的關(guān)系類型以及它們的對象類。然而,物體在視頻序列的每一幀中不一定是一致的,任意兩個物體之間的關(guān)系可能會因為它們的運動而變化,具有動態(tài)的特點。在這種情況下,時間依賴性發(fā)揮了作用,因此,靜態(tài)場景圖生成方法不能直接應(yīng)用于動態(tài)場景圖生成,這在[5]中進(jìn)行了充分討論。
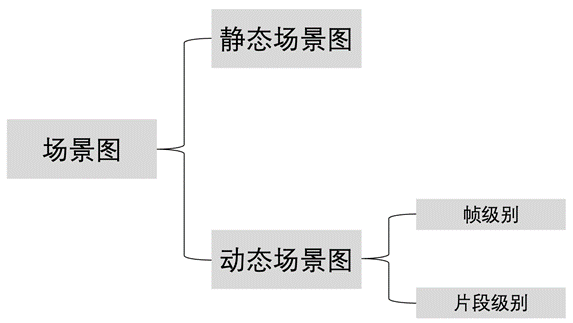
圖1. 場景圖分類
2 靜態(tài)場景圖
2.1 任務(wù)定義
靜態(tài)場景圖生成任務(wù)(Staticscene graph generation)目標(biāo)是讓計算機自動生成一種語義化的圖結(jié)構(gòu)(稱為 scenegraph,場景圖),作為圖像的表示。圖像中的目標(biāo)對應(yīng) graph node,目標(biāo)間的關(guān)系對應(yīng) graph edge(目標(biāo)的各種屬性,如顏色,有時會在圖中表示)。 這種結(jié)構(gòu)化表示方法相對于向量表示更加直觀,可以看作是小型知識圖譜,因此可以廣泛應(yīng)用于知識管理、推理、檢索、推薦等。此外,該表示方法是模態(tài)無關(guān)的,自然語言、視頻、語音等數(shù)據(jù)同樣可以表示成類似結(jié)構(gòu),因此對于融合多模態(tài)信息很有潛力。
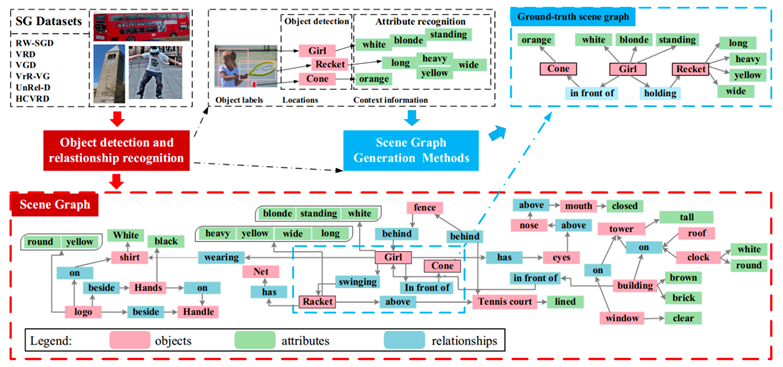
圖2.靜態(tài)場景圖生成任務(wù)圖例
2.2 數(shù)據(jù)集
Visual Genome(VG)[6]于2016年提出,是這個領(lǐng)域最常用的數(shù)據(jù)集,包含對超過 10W 張圖片的目標(biāo)、屬性、關(guān)系、自然語言描述、視覺問答等的標(biāo)注。與此任務(wù)相關(guān)的數(shù)據(jù)總結(jié)如下:
物體:表示為場景圖中節(jié)點,使用bounding box標(biāo)注物體的坐標(biāo)信息,包含對應(yīng)的類別信息。VG包含約17000種目標(biāo)。
關(guān)系:表示為場景圖中邊,包含動作關(guān)系,空間關(guān)系,從屬關(guān)系和動詞等。VG中包含約13000種關(guān)系。
屬性:可以是顏色,狀態(tài)等。Visual Genome 包含約 155000 種屬性。
2.3 方法分類
方法分類如下:
P(O,B,R | I) = P(O,B | I) * P(R| I,O,B),即先目標(biāo)檢測,再進(jìn)行關(guān)系預(yù)測(有一個專門研究該子任務(wù)的領(lǐng)域,稱為研究視覺關(guān)系識別,visual relationship detection)。最簡單的方法是下文中基于統(tǒng)計頻率的 baseline 方法,另外做視覺關(guān)系檢測任務(wù)的大多數(shù)工作都可以應(yīng)用到這里。
P(O,B,R | I) = P(B | I) * P(R,O| I,O,B),即先定位目標(biāo),然后將一張圖片中所有的目標(biāo)和關(guān)系看作一個未標(biāo)記的圖結(jié)構(gòu),再分別對節(jié)點和邊進(jìn)行類別預(yù)測。這種做法考慮到了一張圖片中的各元素互為上下文,為彼此分類提供輔助信息。事實上,自此類方法提出之后[7],才正式有了 scenegraph generation 這個新任務(wù)名稱(之前基本都稱為visual relationship detection)。
2.4 評價指標(biāo)
最常用的評價指標(biāo)是 recall@topk, 即主謂賓關(guān)系三元組
3 動態(tài)場景圖
3.1 任務(wù)定義
動態(tài)場景圖與靜態(tài)場景圖不同,動態(tài)場景圖以視頻作為輸入,輸出分為兩種情況:輸出每一幀對應(yīng)的場景圖(幀級別場景圖);輸出每一段視頻對應(yīng)的場景圖(片段級別場景圖)。這種結(jié)構(gòu)化的表示可以表征實體之間隨時間變化的動作及狀態(tài)。
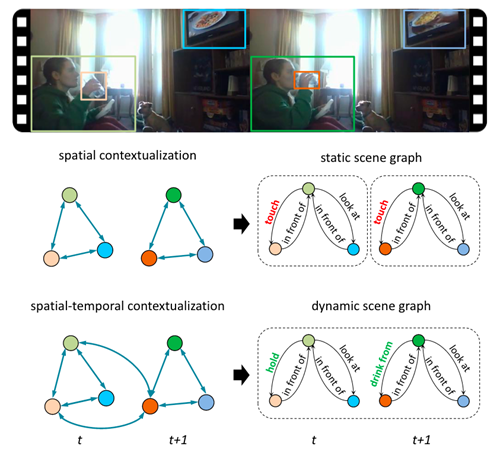
圖3.靜態(tài)/動態(tài)場景圖區(qū)別示例
3.2 幀級別
3.2.1數(shù)據(jù)集
Action Genome該數(shù)據(jù)集是Visual Genome表示的帶時間版本,然而,Visual Genome的目的是詳盡的捕捉圖中每一個區(qū)域的物體和關(guān)系,而Action Genome的目標(biāo)是將動作分解,專注于對那些動作發(fā)生的視頻片段進(jìn)行標(biāo)注,并且只標(biāo)注動作涉及的對象。Action Genome基于Charades進(jìn)行標(biāo)注,該數(shù)據(jù)集包含157類別動作,144個是人類-物體活動。在Charades中,有很多動作可以同時發(fā)生。共有234253個frame,476229個bounding box,35個對象類別,1715568個關(guān)系,25個關(guān)系類別。
3.2.2 方法
Spatial-temporalTransformer(STTran)[8]:一種由兩個核心模塊組成的神經(jīng)網(wǎng)絡(luò):一個空間編碼器,它采用輸入幀來提取空間上下文并推斷幀內(nèi)的視覺關(guān)系,以及一個時間解碼器它將空間編碼器的輸出作為輸入,以捕獲幀之間的時間依賴性并推斷動態(tài)關(guān)系。此外,STTran 可以靈活地將不同長度的視頻作為輸入而無需剪輯,這對于長視頻尤為重要。
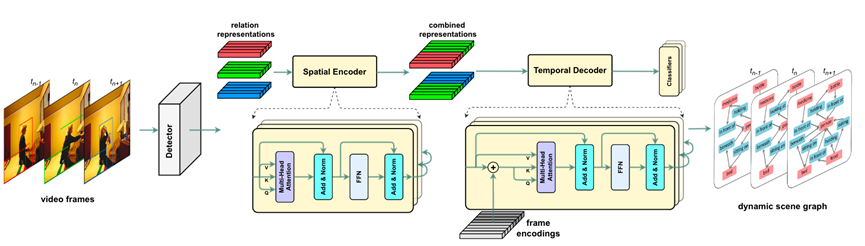
圖4.STTrans模型結(jié)構(gòu)
3.2.3 主實驗結(jié)果

圖5.STTrans模型實驗結(jié)果
3.2.4 樣例測試
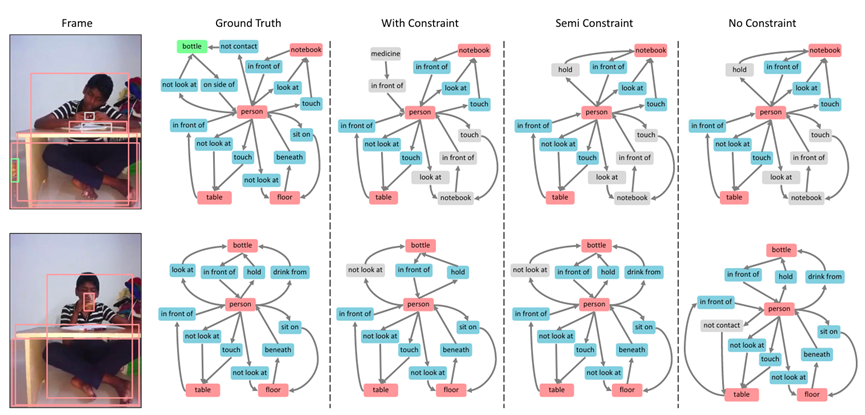
圖6. 樣例
3.3 片段級別
3.3.1 數(shù)據(jù)集
VidVRD提出了一個新穎的VidVRD任務(wù),旨在探索視頻中物體之間的各種關(guān)系,它提供了一個比ImgVRD更可行的VRD任務(wù),通過目標(biāo)軌跡建議、關(guān)系預(yù)測和貪婪關(guān)系關(guān)聯(lián)來檢測視頻中的視覺關(guān)系,包含1000個帶有手動標(biāo)記的視覺關(guān)系的視頻,被分解為30幀的片段,其中由15幀重疊,再進(jìn)行謂詞標(biāo)記。30類+(人、球、沙發(fā)、滑板、飛盤)=35類(獨立,沒有對象之間的包含關(guān)系),14個及物動詞、3個比較詞、11個空間謂詞,11個不及物動詞,能夠衍生160類謂詞。
3.3.2 方法
VidSGG提出了一個新的框架,在此框架下,將視頻場景圖重新表述為時間二分圖,其中實體和謂詞是兩類具有時隙的節(jié)點,邊表示這些節(jié)點之間的不同語義角色。
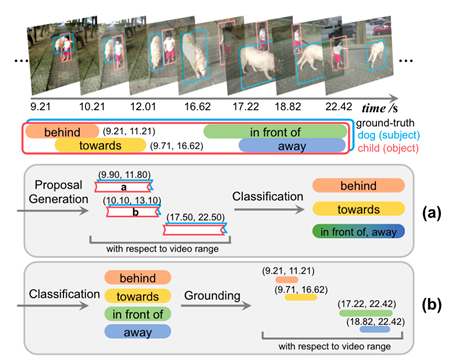
圖7.VidVRD任務(wù)示例
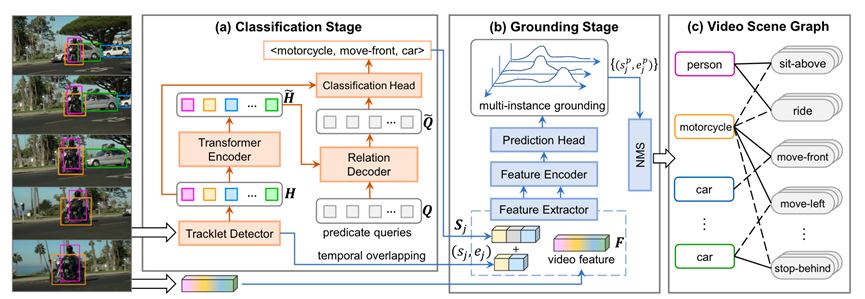
圖8.BIG-C模型結(jié)構(gòu)
3.3.3 主實驗結(jié)果
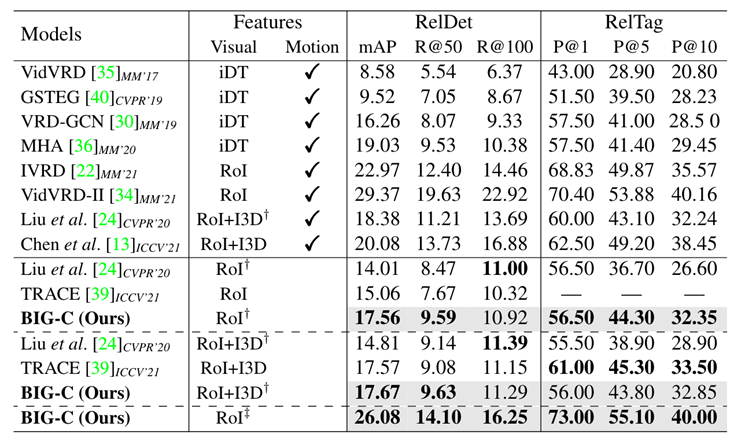
圖9.BIG-C模型實驗結(jié)果
3.3.4 樣例測試
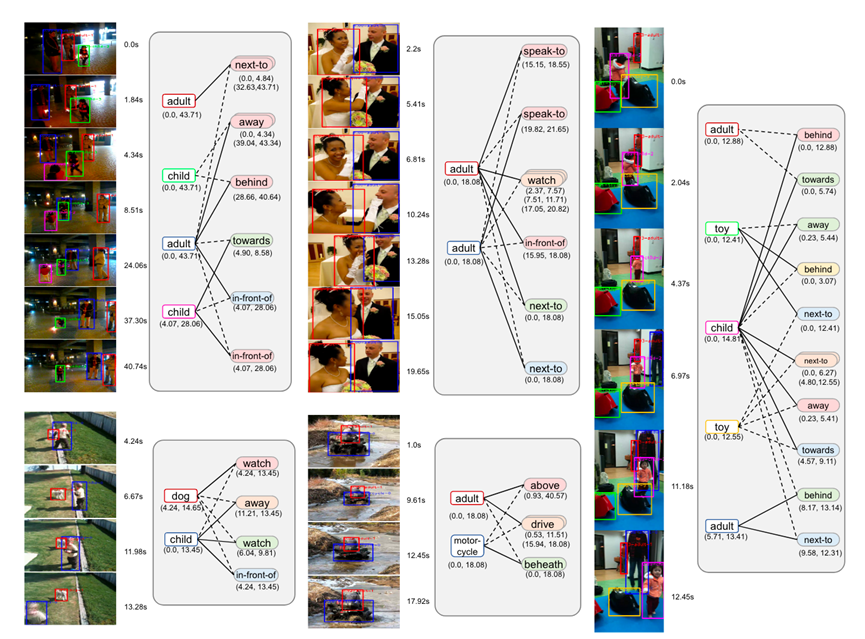
圖10.對話情緒識別示例
-
檢測器
+關(guān)注
關(guān)注
1文章
896瀏覽量
48762 -
Baseline
+關(guān)注
關(guān)注
0文章
3瀏覽量
6953 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1224瀏覽量
25495
原文標(biāo)題:哈工大SCIR | 場景圖生成簡述
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
看門狗喚醒導(dǎo)致baseline降低的原因?
6678功耗計算工具中baseline功耗問題
8168編碼的問題,如何編出baseline profile 3.1的H264碼流
愛立信話務(wù)統(tǒng)計概述

數(shù)字頻率表設(shè)計方法
支持Baseline和Extended Sequential
無線電騷擾的統(tǒng)計測量方法研究
基于統(tǒng)計和理解的自動摘要方法

基于步數(shù)步幅統(tǒng)計的測距方法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論