 大模型在不同任務中的優缺點
大模型在不同任務中的優缺點
如果自己是一個大模型的小白,第一眼看到 GPT、PaLm、LLaMA 這些單詞的怪異組合會作何感想?假如再往深里入門,又看到 BERT、BART、RoBERTa、ELMo 這些奇奇怪怪的詞一個接一個蹦出來,不知道作為小白的自己心里會不會抓狂?
哪怕是一個久居 NLP 這個小圈子的老鳥,伴隨著大模型這爆炸般的發展速度,可能恍惚一下也會跟不上這追新打快日新月異的大模型到底是何門何派用的哪套武功。這個時候可能就需要請出一篇大模型綜述來幫忙了!這篇由亞馬遜、得克薩斯農工大學與萊斯大學的研究者推出的大模型綜述《Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond》,為我們以構建一顆“家譜樹”的方式梳理了以 ChatGPT 為代表的大模型的前世今生與未來,并且從任務出發,為我們搭建了非常全面的大模型實用指南,為我們介紹了大模型在不同任務中的優缺點,最后還指出了大模型目前的風險與挑戰。
家譜樹——大模型的前世今生
追尋大模型的“萬惡之源”,大抵應該從那篇《Attention is All You Need》開始,基于這篇由谷歌機器翻譯團隊提出的由多組 Encoder、Decoder 構成的機器翻譯模型 Transformer 開始,大模型的發展大致走上了兩條路,一條路是舍棄 Decoder 部分,僅僅使用 Encoder 作為編碼器的預訓練模型,其最出名的代表就是 Bert 家族。這些模型開始嘗試“無監督預訓練”的方式來更好的利用相較其他數據而言更容易獲得的大規模的自然語言數據,而“無監督”的方式就是 Masked Language Model(MLM),通過讓 Mask 掉句子中的部分單詞,讓模型去學習使用上下文去預測被 Mask 掉的單詞的能力。在 Bert 問世之初,在 NLP 領域也算是一顆炸彈,同時在許多自然語言處理的常見任務如情感分析、命名實體識別等中都刷到了 SOTA,Bert 家族的出色代表除了谷歌提出的 Bert 、ALBert之外,還有百度的 ERNIE、Meta 的 RoBERTa、微軟的 DeBERTa等等。
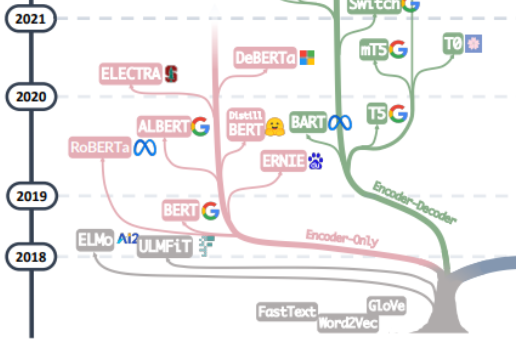
可惜的是,Bert 的進路沒能突破 Scale Law,而這一點則由當下大模型的主力軍,即大模型發展的另一條路,通過舍棄 Encoder 部分而基于 Decoder 部分的 GPT 家族真正做到了。GPT 家族的成功來源于一個研究人員驚異的發現:“擴大語言模型的規模可以顯著提高零樣本(zero-shot)與小樣本(few-shot)學習的能力”,這一點與基于微調的 Bert 家族有很大的區別,也是當下大規模語言模型神奇能力的來源。GPT 家族基于給定前面單詞序列預測下一個單詞來進行訓練,因此 GPT 最初僅僅是作為一個文本生成模型而出現的,而 GPT-3 的出現則是 GPT 家族命運的轉折點,GPT-3 第一次向人們展示了大模型帶來的超越文本生成本身的神奇能力,顯示了這些自回歸語言模型的優越性。而從 GPT-3 開始,當下的 ChatGPT、GPT-4、Bard 以及 PaLM、LLaMA 百花齊放百家爭鳴,帶來了當下的大模型盛世。
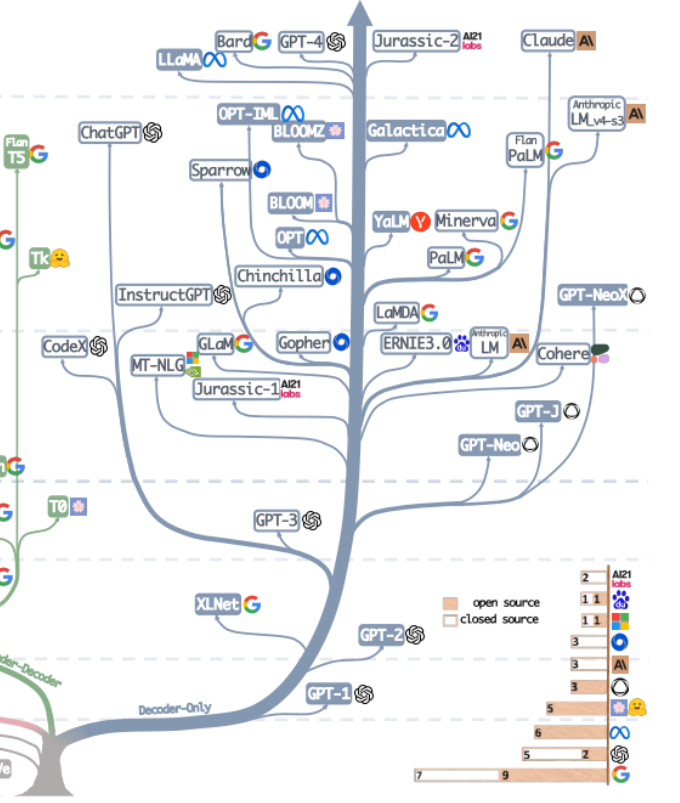
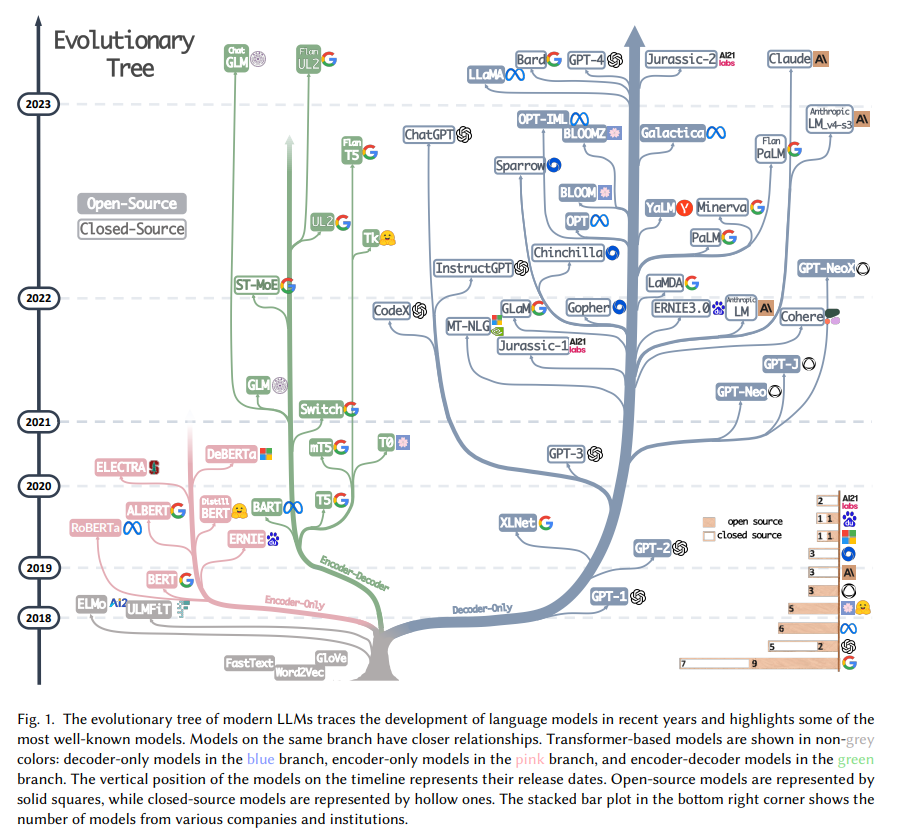
從合并這家譜樹的兩支,可以看到早期的 Word2Vec、FastText,再到預訓練模型的早期探索 ELMo、ULFMiT ,再到 Bert 橫空出世紅極一時,到 GPT 家族默默耕耘直到 GPT-3 驚艷登場,ChatGPT 一飛沖天,技術的迭代之外也可以看到 OpenAI 默默堅持自己的技術路徑最終成為目前 LLMs 無可爭議的領導者,看到 Google 對整個 Encoder-Decoder 模型架構做出的重大理論貢獻,看到 Meta 對大模型開源事業的持續慷慨的參與,當然也看到從 GPT-3 之后 LLMs 逐漸趨向于“閉”源的趨勢,未來很有可能大部分研究不得不變成 API-Based 的研究。
數據——大模型的力量源泉
歸根結底,大模型的神奇能力是來源于 GPT 么?我覺得答案是否定的,GPT 家族幾乎每一次能力的躍遷,都在預訓練數據的數量、質量、多樣性等方面做出了重要的提升。大模型的訓練數據包括書籍、文章、網站信息、代碼信息等等,這些數據輸入到大模型中的目的,實質在于全面準確的反應“人類”這個東西,通過告訴大模型單詞、語法、句法和語義的信息,讓模型獲得識別上下文并生成連貫響應的能力,以捕捉人類的知識、語言、文化等等方面。
一般而言,面對許多 NLP 的任務,我們可以從數據標注信息的角度將其分類為零樣本、少樣本與多樣本。無疑,零樣本的任務 LLMs 是最合適的方法,幾乎沒有例外,大模型在零樣本任務上遙遙領先于其他的模型。同時,少樣本任務也十分適合大模型的應用,通過為大模型展示“問題-答案”對,可以增強大模型的表現性能,這種方式我們一般也稱為上下文學習(In-Context Learning)。而多樣本任務盡管大模型也可以去覆蓋,但是微調可能仍然是最好的方法,當然在一些如隱私、計算等約束條件下,大模型可能仍然有用武之地。

同時,微調的模型很有可能會面對訓練數據與測試數據分布變化的問題,顯著的,微調的模型在 OOD 數據上一般表現都非常差。而相應的,LLMs 由于并沒有一個顯式的擬合過程,因此表現要好許多,典型的 ChatGPT 基于人類反饋的強化學習(RLHF)在大部分分布外的分類與翻譯任務中都表現優異,在專為 OOD 評估設計的醫學診斷數據集 DDXPlus 上也表現出色。
實用指南——任務導向上手大模型
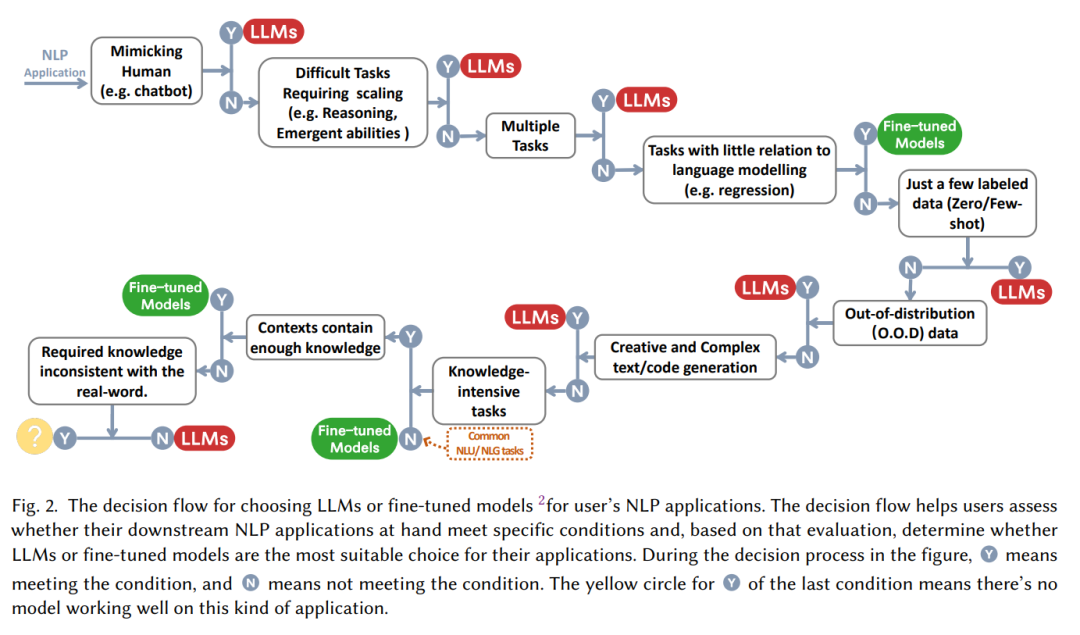
很多時候,“大模型很好!”這個斷言后緊跟著的問題就是“大模型怎么用,什么時候用?”,面對一個具體任務時,我們是應該選擇微調、還是不假思索的上手大模型?這篇論文總結出了一個實用的“決策流”,根據“是否需要模仿人類”,“是否要求推理能力”,“是否是多任務”等一系列問題幫我們判斷是否要去使用大模型。
而從 NLP 任務分類的角度而言:
傳統自然語言理解
目前擁有大量豐富的已標注數據的很多 NLP 任務,微調模型可能仍然牢牢把控著優勢,在大多數數據集中 LLMs 都遜色于微調模型,具體而言:
文本分類:在文本分類中,LLMs 普遍遜色于微調模型;
情感分析:在 IMDB 與 SST 任務上大模型與微調模型表現相仿,而在如毒性監測任務中,幾乎所有的大模型都差于微調模型;
自然語言推理:在 RTE 與 SNLI 上,微調模型優于 LLMs,在 CB 等數據中,LLMs與微調模型相仿;
問答:在 SQuADv2、QuAC 和許多其他數據集上,微調模型具有更好的性能,而在 CoQA 上,LLMs 表現與微調模型性能相仿;
信息檢索:LLMs 尚未在信息檢索領域廣泛應用,信息檢索的任務特征使得沒有自然的方式為大模型建模信息檢索任務;
命名實體識別:在命名實體識別中,大模型仍然大幅度遜色于微調模型,在 CoNLL03 上微調模型的性能幾乎是大模型的兩倍,但是命名實體識別作為一個經典的 NLP 中間任務,很有可能會被大模型取代。
總之,對于大多數傳統自然語言理解的任務,微調模型的效果更好。當然 LLMs 的潛力受限于 Prompt 工程可能仍未完全釋放(其實微調模型也并未達到上限),同時,在一些小眾的領域,如 Miscellaneous Text Classification,Adversarial NLI 等任務中 ,LLMs 由于更強的泛化能力因而具有更好的性能,但是在目前而言,對于有成熟標注的數據而言,微調模型可能仍然是對傳統任務的最優解。
自然語言生成
相較于自然語言理解,自然語言生成可能就是大模型的舞臺了。自然語言生成的目標主要是創建連貫、通順、有意義的符合序列,通常可以分為兩大類,一類是以機器翻譯、段落信息摘要為代表的任務,一類是更加開放的自然寫作,如撰寫郵件,編寫新聞,創作故事等的任務。具體而言:
文本摘要:對于文本摘要而言,如果使用傳統的如 ROUGE 等的自動評估指標,LLMs 并沒有表現出明顯的優勢,但是如果引入人工評估結果,LLMs 的表現則會大幅優于微調模型。這其實表明當前這些自動評估指標有時候并不能完整準確的反應文本生成的效果;
機器翻譯:對于機器翻譯這樣一個擁有成熟商業軟件的任務而言,LLMs 的表現一般略遜于商業翻譯工具,但在一些冷門語言的翻譯中,LLMs 有時表現出了更好的效果,譬如在羅馬尼亞語翻譯英語的任務中,LLMs 在零樣本和少樣本的情況下擊敗了微調模型的 SOTA;
開放式生成:在開放式生成方面,顯示是大模型最擅長的工作,LLMs 生成的新聞文章幾乎與人類編寫的真實新聞無法區分,在代碼生成、代碼糾錯等領域 LLMs 都表現了令人驚訝的性能。
知識密集型任務
知識密集型任務一般指強烈依賴背景知識、領域特定專業知識或者一般世界知識的任務,知識密集型任務區別于簡單的模式識別與句法分析,需要對我們的現實世界擁有“常識”并能正確的使用,具體而言:
閉卷問答:在 Closed-book Question-Answering 任務中,要求模型在沒有外部信息的情況下回答事實性的問題,在許多數據集如 NaturalQuestions、WebQuestions、TriviaQA 上 LLMs 都表現了更好的性能,尤**其在 TriviaQA 中,零樣本的 LLMs 都展現了優于微調模型的性別表現;
大規模多任務語言理解:大規模多任務語言理解(MMLU)包含 57 個不同主題的多項選擇題,也要求模型具備一般性的知識,在這一任務中最令人印象深刻的當屬 GPT-4,在 MMLU 中獲得了 86.5% 的正確率。
值得注意的是,在知識密集型任務中,大模型并不是百試百靈,有些時候,大模型對現實世界的知識可能是無用甚至錯誤的,這樣“不一致”的知識有時會使大模型的表現比隨機猜測還差。如重定義數學任務(Redefine Math)中要求模型在原含義和從重新定義的含義中做出選擇,這需要的能力與大規模語言模型的學習到的知識恰恰相反,因此,LLMs 的表現甚至不如隨機猜測。
推理任務
LLMs 的擴展能力可以極大的增強預訓練語言模型的能力,當模型規模指數增加時,一些關鍵的如推理的能力會逐漸隨參數的擴展而被激活,LLMs 的算術推理與常識推理的能力肉眼可見的異常強大,在這類任務中:
算術推理:不夸張的說,GPT-4 的算術與推理判斷的能力超過了以往的任何模型,在 GSM8k、SVAMP 和 AQuA 上大模型都具有突破性的能力,值得指出的是,通過思維鏈(CoT)的提示方式,可以顯著的增強 LLMs 的計算能力;
常識推理:常識推理要求大模型記憶事實信息并進行多步推理,在大多數數據集中,LLMs 都保持了對微調模型的優勢地位,特別在 ARC-C (三-九年級科學考試困難題)中,GPT-4 的表現接近 100%(96.3%)。
除了推理之外,隨著模型規模的增長,模型還會浮現一些 Emergent Ability,譬如符合操作、邏輯推導、概念理解等等。但是還有類有趣的現象稱為“U形現象”,指隨著 LLMs 規模的增加,模型性能出現先增加后又開始下降的現象,典型的代表就是前文提到的重定義數學的問題,這類現象呼喚著對大模型原理更加深入與細致的研究。
總結——大模型的挑戰與未來
大模型必然是未來很長一段時間我們工作生活的一部分,而對于這樣一個與我們生活高度同頻互動的“大家伙”,除了性能、效率、成本等問題外,大規模語言模型的安全問題幾乎是大模型所面對的所有挑戰之中的重中之重,機器幻覺是大模型目前還沒有極佳解決方案的主要問題,大模型輸出的有偏差或有害的幻覺將會對使用者造成嚴重后果。同時,隨著 LLMs 的“公信度”越來越高,用戶可能會過度依賴 LLMs 并相信它們能夠提供準確的信息,這點可以預見的趨勢增加了大模型的安全風險。
除了誤導性信息外,由于 LLMs 生成文本的高質量和低成本,LLMs 有可能被利用為進行仇恨、歧視、暴力、造謠等攻擊的工具,LLMs 也有可能被攻擊以未惡意攻擊者提供非法信息或者竊取隱私,據報道,三星員工使用 ChatGPT 處理工作時意外泄漏了最新程序的源代碼屬性、與硬件有關的內部會議記錄等絕密數據。
除此之外,大模型是否能應用于敏感領域,如醫療保健、金融、法律等的關鍵在于大模型的“可信度”的問題,在當下,零樣本的大模型魯棒性往往會出現降低。同時,LLMs 已經被證明具有社會偏見或歧視,許多研究在口音、宗教、性別和種族等人口統計類別之間觀察到了顯著的性能差異。這會導致大模型的“公平”問題。
最后,如果脫開社會問題做個總結,也是展望一下大模型研究的未來,目前大模型主要面臨的挑戰可以被歸類如下:
實踐驗證:當前針對大模型的評估數據集往往是更像“玩具”的學術數據集,但是這些學術數據集無法完全反應現實世界中形形色色的問題與挑戰,因此亟需實際的數據集在多樣化、復雜的現實問題上對模型進行評估,確保模型可以應對現實世界的挑戰;
模型對齊:大模型的強大也引出了另一個問題,模型應該與人類的價值觀選擇進行對齊,確保模型行為符合預期,不會“強化”不良結果,作為一個高級的復雜系統,如果不認真處理這種道德問題,有可能會為人類醞釀一場災難;
安全隱患:大模型的研究要進一步強調安全問題,消除安全隱患,需要具體的研究確保大模型的安全研發,需要更多的做好模型的可解釋性、監督管理工作,安全問題應該是模型開發的重要組成部分,而非錦上添花可有可無的裝飾;
模型未來:模型的性能還會隨著模型規模的增加而增長嗎?,這個問題估計 OpenAI 也難以回答,我們針對大模型的神奇現象的了解仍然十分有限,針對大模型原理性的見解仍然十分珍貴。
-
微軟
+關注
關注
4文章
6590瀏覽量
104026 -
模型
+關注
關注
1文章
3226瀏覽量
48809 -
自然語言處理
+關注
關注
1文章
618瀏覽量
13552
原文標題:大模型綜述來了!一文帶你理清全球AI巨頭的大模型進化史
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論