 GPT-4推理提升1750%!清華姚班校友提出全新ToT框架
GPT-4推理提升1750%!清華姚班校友提出全新ToT框架
【導讀】由普林斯頓和谷歌DeepMind聯合提出的全新「思維樹」框架,讓GPT-4可以自己提案、評估和決策,推理能力最高可提升1750%。
2022年,前谷歌大腦華人科學家Jason Wei在一篇思維鏈的開山之作中首次提出,CoT可以增強LLM的推理能力。
但即便有了思維鏈,LLM有時也會在非常簡單的問題上犯錯。
最近,來自普林斯頓大學和Google DeepMind研究人員提出了一種全新的語言模型推理框架——「思維樹」(ToT)。
ToT將當前流行的「思維鏈」方法泛化到引導語言模型,并通過探索文本(思維)的連貫單元來解決問題的中間步驟。

論文地址:https://arxiv.org/abs/2305.10601
項目地址:https://github.com/kyegomez/tree-of-thoughts
簡單來說,「思維樹」可以讓LLM:
· 自己給出多條不同的推理路徑
· 分別進行評估后,決定下一步的行動方案
· 在必要時向前或向后追溯,以便實現進行全局的決策
論文實驗結果顯示,ToT顯著提高了LLM在三個新任務(24點游戲,創意寫作,迷你填字游戲)中的問題解決能力。
比如,在24點游戲中,GPT-4只解決了4%的任務,但ToT方法的成功率達到了74%。
讓LLM「反復思考」
用于生成文本的大語言模型GPT、PaLM,現已經證明能夠執行各種廣泛的任務。
所有這些模型取得進步的基礎仍是最初用于生成文本的「自回歸機制」,以從左到右的方式一個接一個地進行token級的決策。

那么,這樣一個簡單的機制能否足以建立一個通向「解決通用問題的語言模型」?如果不是,哪些問題會挑戰當前的范式,真正的替代機制應該是什么?
恰恰關于「人類認知」的文獻為這個問題提供了一些線索。
「雙重過程」模型的研究表明,人類有兩種決策模式:快速、自動、無意識模式——「系統1」和緩慢、深思熟慮、有意識模式——「系統2」。
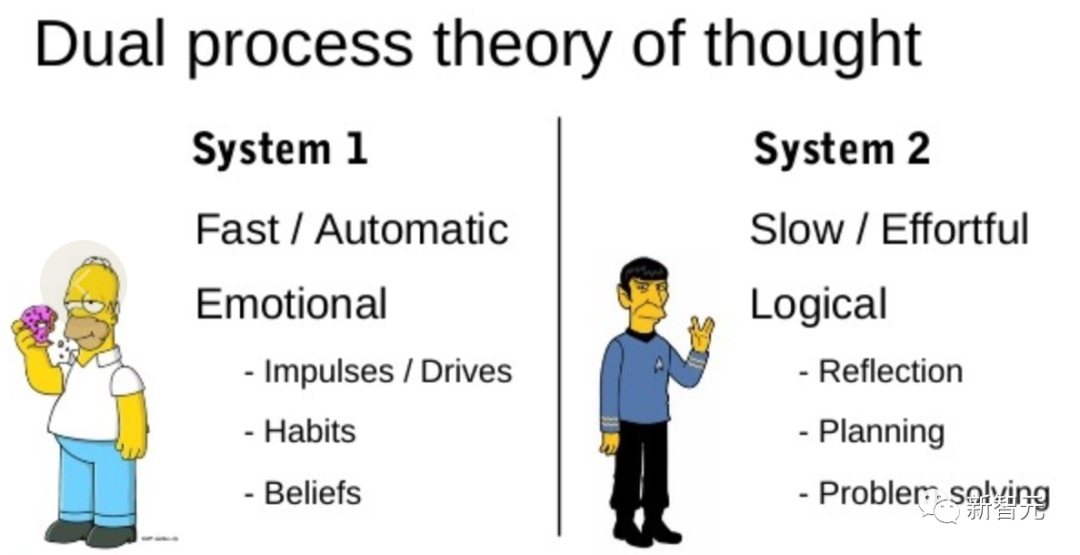
語言模型簡單關聯token級選擇可以讓人聯想到「系統1」,因此這種能力可能會從「系統2」規劃過程中增強。
「系統1」可以讓LLM保持和探索當前選擇的多種替代方案,而不僅僅是選擇一個,而「系統2」評估其當前狀態,并積極地預見、回溯以做出更全局的決策。

為了設計這樣一個規劃過程,研究者便追溯到人工智能和認知科學的起源,從科學家Newell、Shaw和Simon在20世紀50年代開始探索的規劃過程中汲取靈感。
Newell及其同事將問題解決描述為「通過組合問題空間進行搜索」,表示為一棵樹。
一個真正的問題解決過程包括重復使用現有信息來探索,反過來,這將發現更多的信息,直到最終找到解決方法。

這個觀點突出了現有使用LLM解決通用問題方法的2個主要缺點:
1. 局部來看,LLM沒有探索思維過程中的不同延續——樹的分支。
2. 總的來看,LLM不包含任何類型的計劃、前瞻或回溯,來幫助評估這些不同的選擇。
為了解決這些問題,研究者提出了用語言模型解決通用問題的思維樹框架(ToT),讓LLM可以探索多種思維推理路徑。
ToT四步法
當前,現有的方法,如IO、CoT、CoT-SC,通過采樣連續的語言序列進行問題解決。
而ToT主動維護了一個「思維樹」。每個矩形框代表一個思維,并且每個思維都是一個連貫的語言序列,作為解決問題的中間步驟。
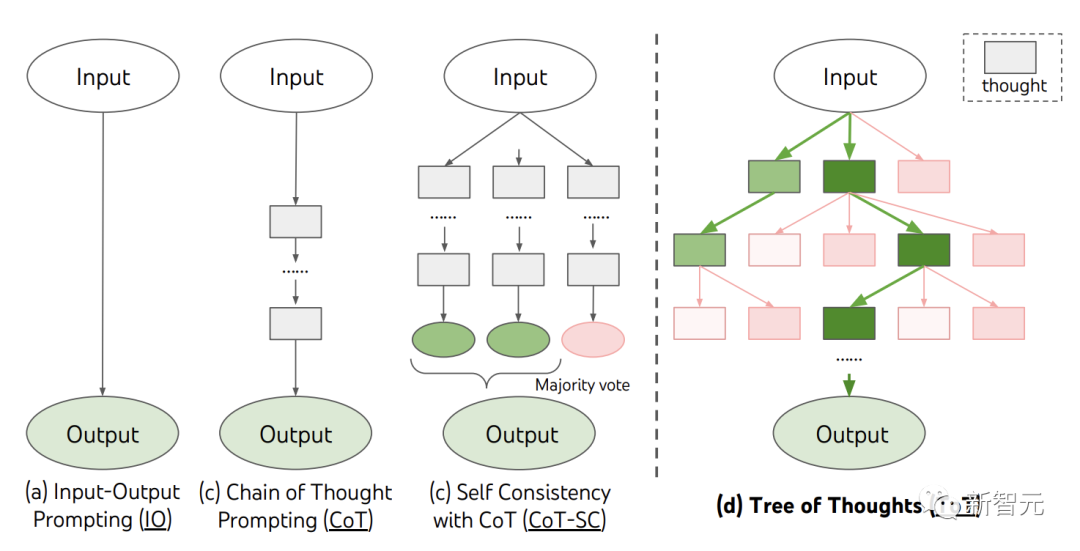
ToT將任何問題定義為在樹上進行搜索,其中每個節點都是一個狀態
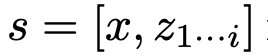
,表示到目前為止輸入和思維序列的部分解。
ToT執行一個具體任務時需要回答4個問題:
如何將中間過程分解為思維步驟;如何從每個狀態生成潛在的想法;如何啟發性地評估狀態;使用什么搜索算法。
1. 思維分解
CoT在沒有明確分解的情況下連貫抽樣思維,而ToT利用問題的屬性來設計和分解中間的思維步驟。
根據不同的問題,一個想法可以是幾個單詞(填字游戲) ,一條方程式(24點) ,或者一整段寫作計劃(創意寫作)。
一般來說,一個想法應該足夠「小」,以便LLM能夠產生有意義、多樣化的樣本。比如,生成一本完整的書通常太「大」而無法連貫 。
但一個想法也應該「大」,足以讓LLM能夠評估其解決問題的前景。例如,生成一個token通常太「小」而無法評估。
2. 思維生成器
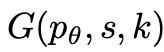
給定樹狀態
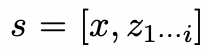
,通過2種策略來為下一個思維步驟生成k個候選者。
(a)從一個CoT提示采樣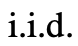 思維:
思維:
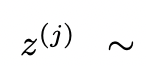
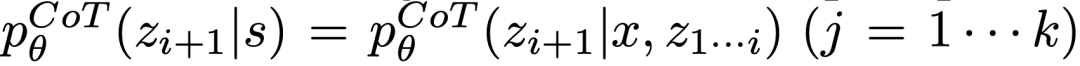
在思維空間豐富(比如每個想法都是一個段落),并且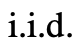 導致多樣性時,效果更好。
導致多樣性時,效果更好。
(b)使用「proposal prompt」按順序提出想法:
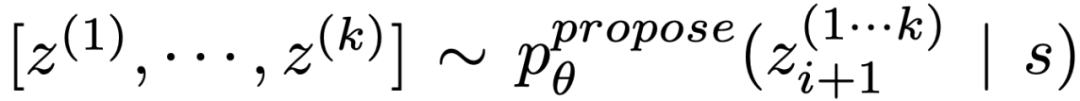
。這在思維空間受限制(比如每個思維只是一個詞或一行)時效果更好,因此在同一上下文中提出不同的想法可以避免重復。
3. 狀態求值器
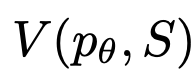
給定不同狀態的前沿,狀態評估器評估它們解決問題的進展,作為搜索算法的啟發式算法,以確定哪些狀態需要繼續探索,以及以何種順序探索。
雖然啟發式算法是解決搜索問題的標準方法,但它們通常是編程的(DeepBlue)或學習的(AlphaGo)。這里,研究者提出了第三種選擇,通過LLM有意識地推理狀態。
在適用的情況下,這種深思熟慮的啟發式方法可以比程序規則更靈活,比學習模型更有效率。與思維生成器,研究人員也考慮2種策略來獨立或一起評估狀態:對每個狀態獨立賦值;跨狀態投票。
4. 搜索算法
最后,在ToT框架中,人們可以根據樹的結構,即插即用不同的搜索算法。
研究人員在此探索了2個相對簡單的搜索算法:
算法1——廣度優先搜索(BFS),每一步維護一組b最有希望的狀態。
算法2——深度優先搜索(DFS),首先探索最有希望的狀態,直到達到最終的輸出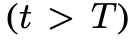 ,或者狀態評估器認為不可能從當前的
,或者狀態評估器認為不可能從當前的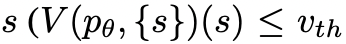 為閾值
為閾值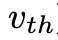 解決問題。在這兩種情況下,DFS都會回溯到s的父狀態以繼續探索。
解決問題。在這兩種情況下,DFS都會回溯到s的父狀態以繼續探索。

由上,LLM通過自我評估和有意識的決策,來實現啟發式搜索的方法是新穎的。
實驗
為此,團隊提出了三個任務用于測試——即使是最先進的語言模型GPT-4,在標準的IO提示或思維鏈(CoT)提示下,都是非常富有挑戰的。

24點(Game of 24)
24點是一個數學推理游戲,目標是使用4個數字和基本算術運算(+-*/)來得到24。
例如,給定輸入「4 9 10 13」,答案的輸出可能是「(10-4)*(13-9)=24」。
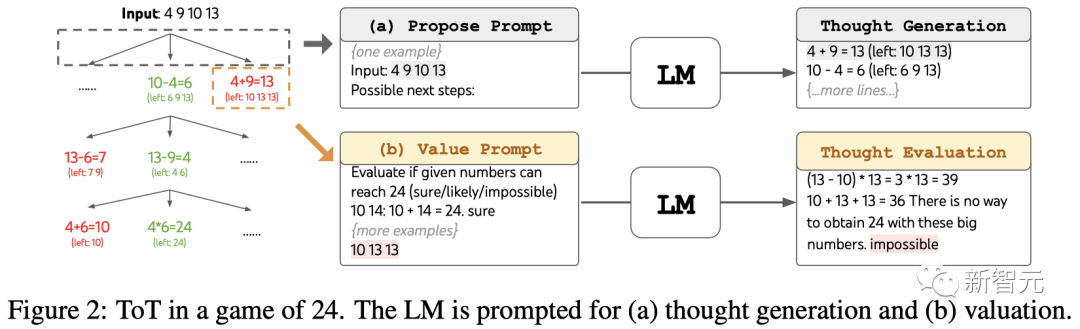
ToT設置
團隊將模型的思維過程分解為3個步驟,每個步驟都是一個中間方程。
如圖2(a)所示,在每個節點上,提取「左邊」的數字并提示LLM生成可能的下一步。(每一步給出的「提議提示」都相同)
其中,團隊在ToT中進行寬度優先搜索(BFS),并在每一步都保留最好的b=5個候選項。
如圖2(b)所示,提示LLM評估每個思維候選項是「肯定/可能/不可能」達到24。基于「過大/過小」的常識消除不可能的部分解決方案,保留剩下的「可能」項。
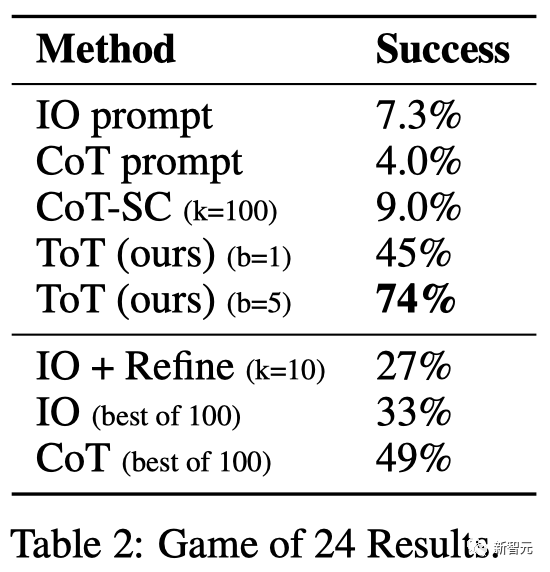
結果
如表2所示,IO,CoT和CoT-SC提示方法在任務上的表現不佳,成功率僅為7.3%,4.0%和9.0%。相比之下,ToT在廣度為b=1時已經達到了45%的成功率,而在b=5時達到了74%。
團隊還考慮了IO/CoT的預測設置,通過使用最佳的k個樣本(1≤k≤100)來計算成功率,并在圖3(a)中繪出5個成功率。
不出所料,CoT比IO擴展得更好,最佳的100個CoT樣本達到了49%的成功率,但仍然比在ToT中探索更多節點(b》1)要差。
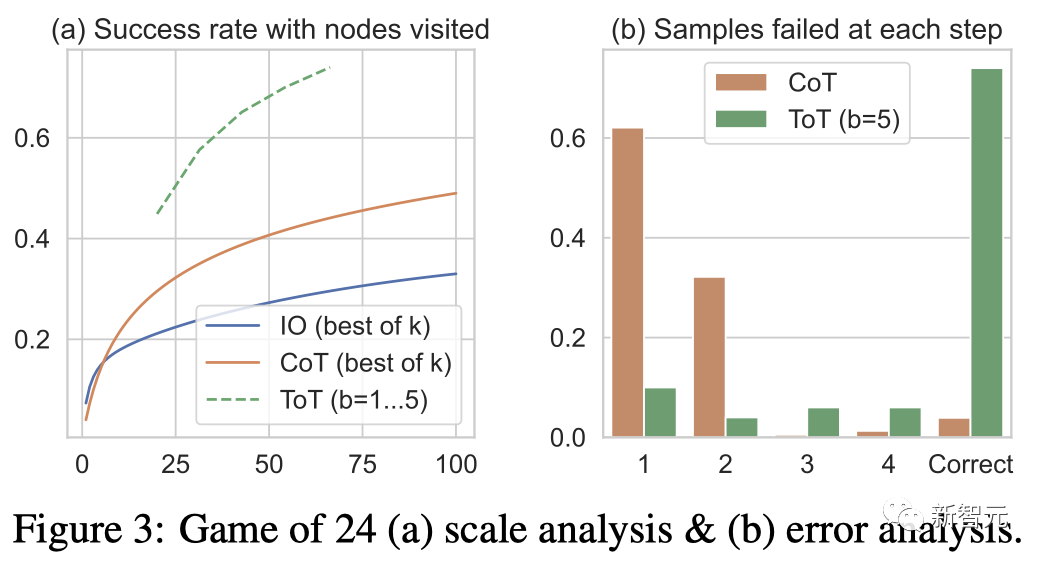
錯誤分析
圖3(b)分析了CoT和ToT樣本在哪一步失敗了任務,即思維(在CoT中)或所有b個思維(在ToT中)都是無效的或無法達到24。
值得注意的是,大約60%的CoT樣本在第一步就已經失敗了,或者說,是前三個詞(例如「4+9」)。
創意寫作
接下來,團隊設計了一個創意寫作任務。
其中,輸入是四個隨機句子,輸出應該是一個連貫的段落,每段都以四個輸入句子分別結束。這樣的任務開放且富有探索性,挑戰創造性思維以及高級規劃。
值得注意的是,團隊還在每個任務的隨機IO樣本上使用迭代-優化(k≤5)方法,其中LLM基于輸入限制和最后生成的段落來判斷段落是否已經「完全連貫」,如果不是,就生成一個優化后的。
ToT設置
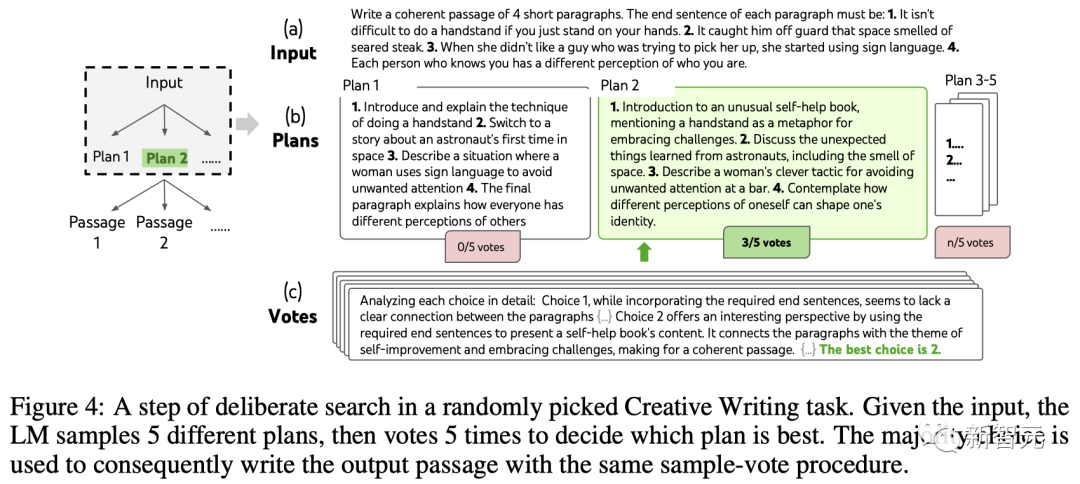
團隊構建了一個深度為2(只有1個中間思維步驟)的ToT。
LLM首先生成k=5的計劃并投票選擇最佳的一個(圖4),然后根據最佳計劃生成k=5的段落,然后投票選擇最佳的一個。
一個簡單的zero-shot投票提示(「分析以下選擇,然后得出哪個最有可能實現指令」)被用來在兩個步驟中抽取5票。
結果
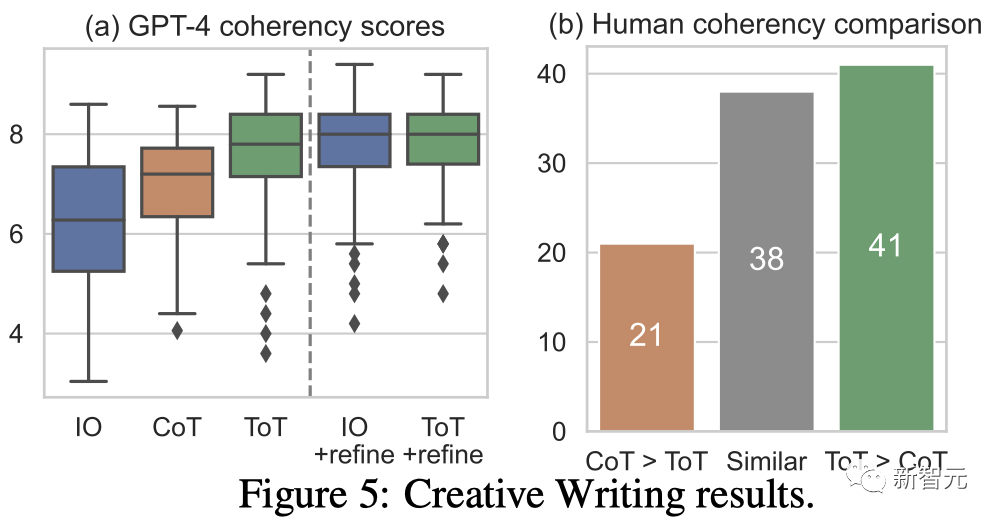
圖5(a)顯示了100個任務中的GPT-4平均分數,其中ToT(7.56)被認為比IO(6.19)和CoT(6.93)平均生成更連貫的段落。
雖然這樣的自動評測可能會有噪音,但圖5(b)通過顯示人類在100個段落對中有41個更喜歡ToT而只有21個更喜歡CoT(其他38對被認為「同樣連貫」)來確認這一發現。
最后,迭代優化在這個自然語言任務上更有效——將IO連貫性分數從6.19提高到7.67,將ToT連貫性分數從7.56提高到7.91。
團隊認為它可以被看作是在ToT框架下生成思維的第三種方法,新的思維可以通過優化舊的思維而產生,而不是i.i.d.或順序生成。
迷你填字游戲
在24點游戲和創意寫作中,ToT相對較淺——最多需要3個思維步驟就能完成輸出。
最后,團隊決定通過5×5的迷你填字游戲,來設置一個更難的問題。
同樣,目標不僅僅是解決任務,而是研究LLM作為一個通用問題解決者的極限。通過窺視自己的思維,以有目的性的推理作為啟發,來指導自己的探索。
ToT設置
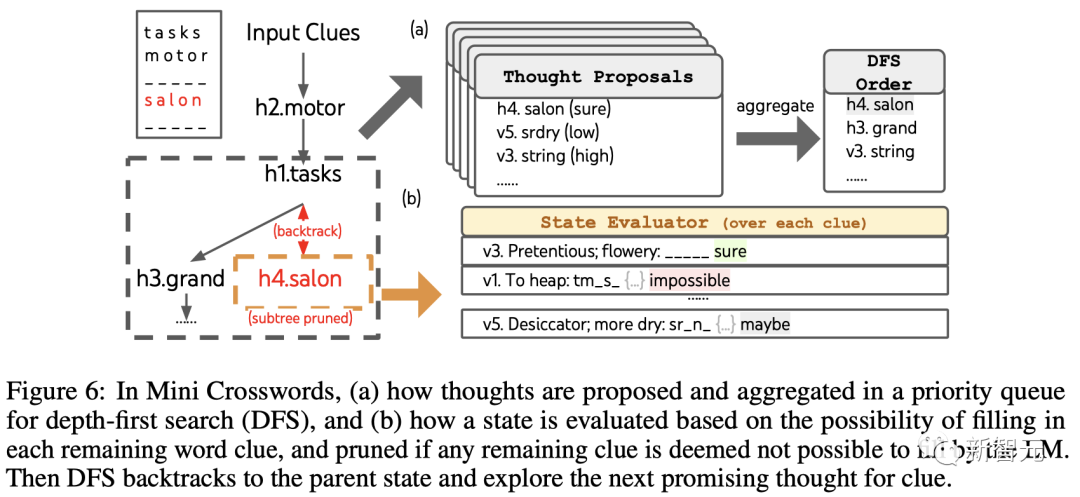
團隊利用深度優先搜索保持探索最有可能成功的后續單詞線索,直到狀態不再有希望,然后回溯到父狀態以探索替代的思維。
為了使搜索可行,后續的思維被限制不改變任何已填寫的單詞或字母,這樣ToT最多有10個中間步驟。
對于思維生成,團隊在每個狀態下將所有現有的思維(例如,「h2.motor; h1.tasks」對于圖6(a)中的狀態)轉換為剩余線索的字母限制(例如,「v1.To heap: tm___;。..」),從而得到下一個單詞填寫位置和內容的候選。 重要的是,團隊也提示LLM給出不同思維的置信度,并在提案中匯總這些以獲得下一個要探索的思維的排序列表(圖6(a))。
對于狀態評估,團隊類似地將每個狀態轉換為剩余線索的字母限制,然后評估每個線索是否可能在給定限制下填寫。
如果任何剩余的線索被認為是「不可能」的(例如,「v1. To heap: tm_s_」),那么該狀態的子樹的探索就被剪枝,并且DFS回溯到其父節點來探索下一個可能的候選。
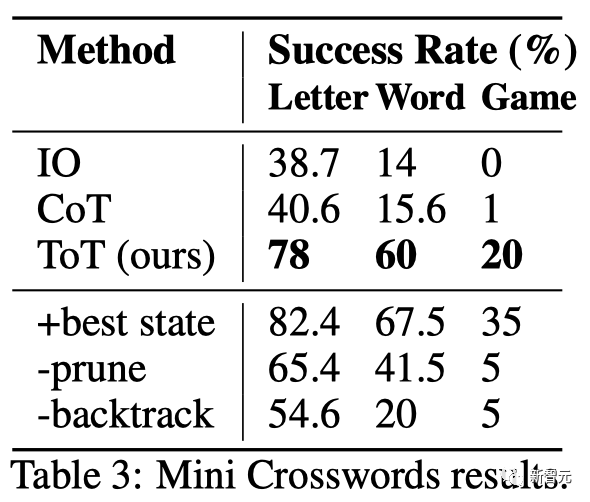
結果
如表3所示,IO和CoT的提示方法在單詞級成功率上表現不佳,低于16%,而ToT顯著改善了所有指標,實現了60%的單詞級成功率,并解決了20個游戲中的4個。
鑒于IO和CoT缺乏嘗試不同線索、改變決策或回溯的機制,這種改善并不令人驚訝。
局限性與結論
ToT是一個讓LLM可以更自主、更智能地做決策和解決問題的框架。
它提高了模型決策的可解釋性以及與人類對齊的機會,因為ToT所生成的表征表形式是可讀的、高級的語言推理,而不是隱式的、低級的token值。
對于那些GPT-4已經十分擅長的任務來說,ToT可能并是不必要的。
此外,像ToT這樣的搜索方法需要更多的資源(如GPT-4 API成本)來提高任務性能,但ToT的模塊化靈活性讓用戶可以自定義這種性能-成本平衡。
不過,隨著LLM被用于更多真實世界的決策應用(如編程、數據分析、機器人技術等),ToT可以為研究那些即將出現的更為復雜的任務,提供新的機會。
審核編輯 :李倩
-
框架
+關注
關注
0文章
403瀏覽量
17509 -
語言模型
+關注
關注
0文章
527瀏覽量
10290 -
GPT
+關注
關注
0文章
354瀏覽量
15419
原文標題:GPT-4推理提升1750%!清華姚班校友提出全新ToT框架,讓LLM反復思考
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
OpenAI全新GPT-4o能力炸場!速度快/成本低,能讀懂人類情緒
清華大學宣布成立人工智能學堂班 姚期智擔綱“智班”首席教授
GPT-4發布!多領域超越“人類水平”,專家:國內落后2-3年

ChatGPT升級 OpenAI史上最強大模型GPT-4發布

深度:構建GPT-4模型,如何商業落地?

GPT-4 的模型結構和訓練方法
微軟提出Control-GPT:用GPT-4實現可控文本到圖像生成!

人工通用智能的火花:GPT-4的早期實驗
GPT-4已經會自己設計芯片了嗎?
OpenAI宣布GPT-4 API全面開放使用!
GPT-4沒有推理能力嗎?
ChatGPT plus有什么功能?OpenAI 發布 GPT-4 Turbo 目前我們所知道的功能






 工商網監
工商網監
評論