


眾所周知,隨著ChatGPT的爆火,AI全面進(jìn)入大模型時(shí)代,NLP、CV大有統(tǒng)一之勢(shì),回顧發(fā)布的各種大模型,Google BARD,openAI的GPT,Meta的SAM,百度的文心一言等等,這些基本都是有實(shí)力有技術(shù)的大公司引領(lǐng)著來研究的,但是作為一名普通的高校科研工作者,我們大多數(shù)基本上是沒有這么多資源算力去開發(fā)這樣的大模型的,但是大模型在各個(gè)方向效果精度幾乎是碾壓,導(dǎo)致很多領(lǐng)域方向就消失了,很多研究生也是很焦慮,可能在申的論文以及畢業(yè)答辯時(shí)肯定會(huì)comment你的性能差距大模型這么多,還有研究的必要嗎?
所以,大模型時(shí)代下,作為一名普普通通,沒有很多資源算力的科研人如何繼續(xù)研究呢?
最近在arXiv上刷到一篇文章,也許能提供一些思路。
論文名稱:
AV-SAM: Segment Anything Model Meets Audio-VisualLocalization and Segmentation
論文地址:
https://arxiv.org/abs/2305.01836

主要內(nèi)容:
首先,Segment Anything Model(SAM)大模型是Meta提出的一種CV大模型,在1100萬張圖像中的10億個(gè)masks上進(jìn)行訓(xùn)練,并且在各種分割任務(wù)上具有很強(qiáng)的零樣本性能,它在打破分割邊界方面取得了重大進(jìn)展,極大地促進(jìn)了計(jì)算機(jī)視覺基礎(chǔ)模型的發(fā)展,這個(gè)視覺基礎(chǔ)模型由三個(gè)主要組件組成:圖像編碼器、提示編碼器和掩碼解碼器。
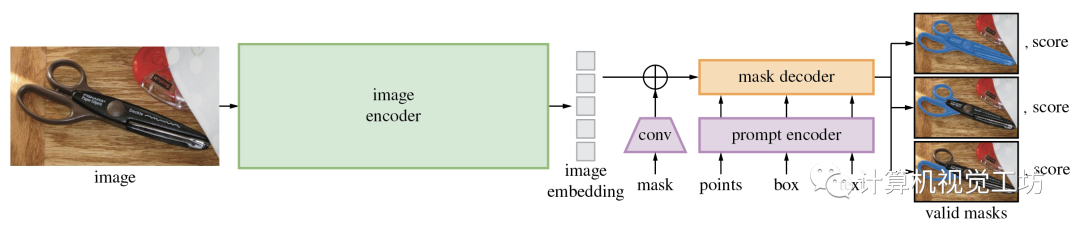

SAM的項(xiàng)目地址:https://github.com/facebookresearch/segment-anything
我們普通科研人如果想重新設(shè)計(jì)訓(xùn)練這樣一個(gè)大模型顯然不現(xiàn)實(shí),那么這篇論文的作者另辟蹊徑,雖然大模型的泛化性很好,在很多任務(wù)上做的不錯(cuò),但是不可能面面俱到,往往是大而不精的,這篇論文就利用已經(jīng)預(yù)訓(xùn)練好的SAM大模型去做更具體的下游任務(wù)——視聽定位和分割。
視聽定位和分割:
視聽定位和分割是以熱圖或掩模的方式預(yù)測(cè)視頻中單個(gè)聲源的位置。
所以,這篇arXiv的論文提出了一個(gè)簡(jiǎn)單而有效的基于SAM大模型的視聽定位和分割框架,即AV-SAM,它可以生成與音頻相對(duì)應(yīng)的發(fā)聲對(duì)象掩碼。具體而言,利用SAM中預(yù)先訓(xùn)練的圖像編碼器的視覺特征,把它和音頻特征逐像素視聽融合來聚合跨模態(tài)表示,然后將聚合的跨模態(tài)特征輸入到提示編碼器和掩碼解碼器以生成最終的視聽分割掩碼。
方向主要包括:3D視覺領(lǐng)域各細(xì)分方向,比如相機(jī)標(biāo)定|三維點(diǎn)云|三維重建|視覺/激光SLAM|感知|控制規(guī)劃|模型部署|3D目標(biāo)檢測(cè)|TOF|多傳感器融合|AR|VR|編程基礎(chǔ)等。
Methods
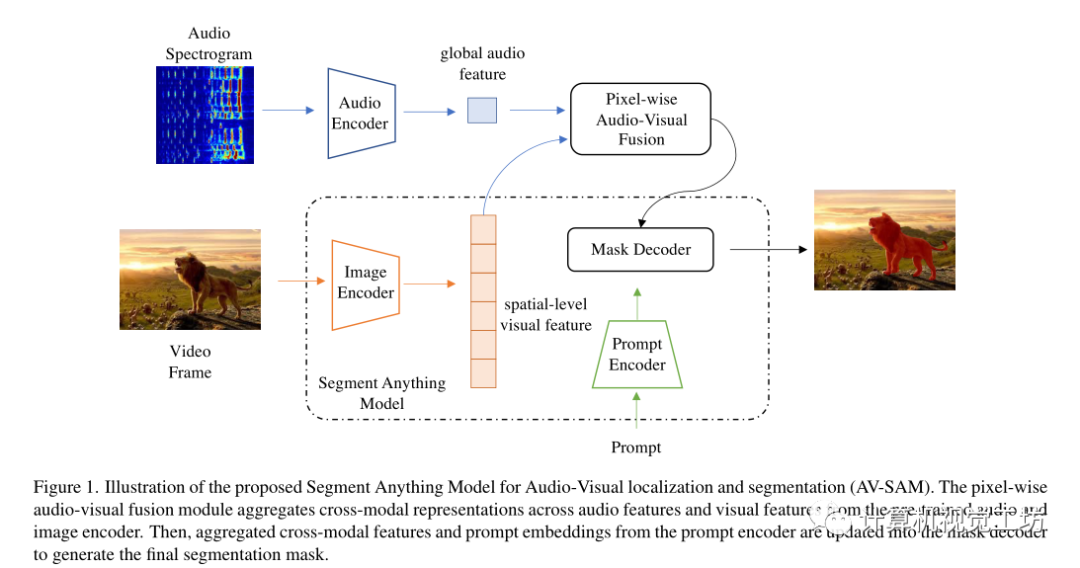
給定圖像和音頻,目標(biāo)是預(yù)測(cè)圖像上聲音對(duì)象的像素掩碼。主要由兩個(gè)模塊組成,像素級(jí)視聽融合和視聽掩碼解碼器。
讓表示聽覺和視覺數(shù)據(jù)對(duì),T、F分別表示音頻頻譜圖的時(shí)間和頻率維度。
首先使用雙流編碼器和投影頭對(duì)音頻和視覺輸入進(jìn)行編碼,分別表示為,音頻編碼器計(jì)算全局音頻特征,視覺編碼器為每s階段生成多尺度空間級(jí)特征。
為了解決視聽分割問題,引入了逐像素視聽融合模塊來對(duì)多尺度空間級(jí)視覺特征和全局音頻表示進(jìn)行編碼,以更新輸入到SAM的掩碼解碼器。在跨模態(tài)融合之后,第s階段的視聽特征被更新為:
其中,表示全局音頻表示ai的復(fù)制版本,該復(fù)制版本在第s階段重復(fù)次。這里表示1×1×1的卷積。通過這種特殊的視聽融合,推動(dòng)學(xué)習(xí)到的視覺標(biāo)記嵌入與全局音頻特征有區(qū)別地對(duì)齊。
利用逐像素視聽融合的優(yōu)勢(shì),使用多尺度特征圖的最后階段更新SAM中預(yù)訓(xùn)練圖像編碼器的原始視覺特征。然后這些更新的多級(jí)特征圖被傳遞到SAM中的掩碼解碼器和提示編碼器,以生成最終的輸出掩碼,以像素級(jí)標(biāo)注Y作為監(jiān)督,將預(yù)測(cè)和標(biāo)簽之間的二進(jìn)制交叉熵(BCE)作為損失:
實(shí)驗(yàn):
在VGG-Sound中使用144k對(duì)的子集進(jìn)行訓(xùn)練,并在Flickr SoundNet測(cè)試集上用250對(duì)聲音對(duì)象的視聽對(duì)測(cè)試模型。
使用在ImageNet上預(yù)訓(xùn)練的ResNet50通過特征圖的雙線性插值來生成偽掩碼。
對(duì)于輸入視覺幀,分辨率調(diào)整為1024×1024。對(duì)于輸入音頻,使用長(zhǎng)度為3s的對(duì)數(shù)頻譜圖,采樣率為22050Hz。
使用輕量級(jí)的ResNet18作為音頻編碼器,并使用SAM發(fā)布的權(quán)重初始化視覺模型。該模型使用128的batch size,學(xué)習(xí)率為1e?4的Adam優(yōu)化器進(jìn)行了100個(gè)epochs的訓(xùn)練。

與SAM相比,在兩個(gè)基準(zhǔn)的所有指標(biāo)方面都取得了最佳結(jié)果。
這表明了逐像素視聽融合對(duì)聚合跨模態(tài)輸入的重要性。

同時(shí)進(jìn)行了消融研究以證明SAM凍結(jié)和微調(diào)預(yù)訓(xùn)練重量的效果。
在表2中凍結(jié)/微調(diào)每個(gè)模塊(掩碼解碼器、提示編碼器、圖像編碼器)參數(shù)。
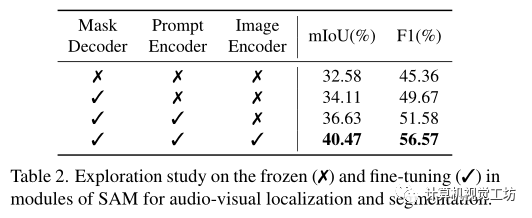
可以觀察到,對(duì)掩碼解碼器進(jìn)行微調(diào)會(huì)增加視聽分割的結(jié)果,表明視聽掩碼解碼器在從聚合的跨模態(tài)特征生成準(zhǔn)確掩碼方面的優(yōu)勢(shì)。同時(shí)微調(diào)提示編碼器也提高了視覺聲源在所有指標(biāo)方面的分割性能。
總結(jié):
本篇是一篇基于大模型來做研究的文章,針對(duì)大模型在視聽定位和分割上不夠魯棒準(zhǔn)確的問題,設(shè)計(jì)模塊去聚合跨模態(tài)表示,顯著提高了在這一具體任務(wù)上的性能。這也許可以給我們普通科研工作者一些啟發(fā),如果我們不能重新研究設(shè)計(jì)訓(xùn)練大模型情況下,我們可以在有限的資源算力下用大模型做一些具體的下游任務(wù),擴(kuò)展大模型的應(yīng)用點(diǎn),用他們已經(jīng)預(yù)訓(xùn)練好的模型權(quán)重去做更具體的任務(wù),原始的大模型不可能面面俱到,其中很多點(diǎn)還是可以去做的。思考大模型如何在自己的研究方向上發(fā)揮它的價(jià)值,如何融合進(jìn)自己的研究。
審核編輯 :李倩
-
解碼器
+關(guān)注
關(guān)注
9文章
1183瀏覽量
42031 -
編碼器
+關(guān)注
關(guān)注
45文章
3815瀏覽量
138219 -
模型
+關(guān)注
關(guān)注
1文章
3525瀏覽量
50487
原文標(biāo)題:大模型時(shí)代下,普通科研人怎么辦?
文章出處:【微信號(hào):3D視覺工坊,微信公眾號(hào):3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論