") 生成式AI,可以設(shè)計芯片了
生成式AI,可以設(shè)計芯片了
自從去年開始,以ChatGPT為代表的生成式AI(Generative)站在了整個世界的聚光燈下。ChatGPT可以理解用戶基于自然語言的輸入,并且產(chǎn)生相應(yīng)的輸出。ChatGPT基于大語言模型技術(shù),通過使用海量的語料訓(xùn)練,可以實現(xiàn)回答用戶的各種問題,還可以幫助用戶完成一些簡單的任務(wù),包括完成文檔編寫甚至Python代碼編寫等等。
而在五月十日,谷歌在IO大會上發(fā)布了ChatGPT的競品,即PaLM 2大語言模型。谷歌表示,目前ChatGPT類生成式大語言模型最重要的用戶體驗之一就是幫助用戶編寫代碼,而PaLM 2的一大特性就是完成20多種編程語言的支持。其中,對于芯片設(shè)計工程師來說,最大的亮點就是PaLM 2支持數(shù)字電路設(shè)計領(lǐng)域最常用的編程語言Verilog。
百聞不如一試,目前PaLM 2已經(jīng)在谷歌的Bard平臺上線開放公測,因此我們也嘗試使用Bard去體會了一把PaLM 2生成Verilog代碼的能力。在試驗中,我們讓Bard生成了兩段代碼,一段代碼是生成一個FIFO(數(shù)字電路中最常用的模塊之一),而另一段代碼則是生成一個模塊,其中包含了兩個前面編寫的FIFO,并且讓第一個FIFO的輸出接入第二個FIFO的輸入。生成的方法非常簡單,我們只需要給Bard一個基于自然語言的指令(prompt),Bard就能夠在幾秒鐘之內(nèi)完成相應(yīng)的代碼生成。例如,在第一個實驗中,我們使用的指令是“生成一段Verilog代碼來實現(xiàn)FIFO”,生成結(jié)果如下圖:
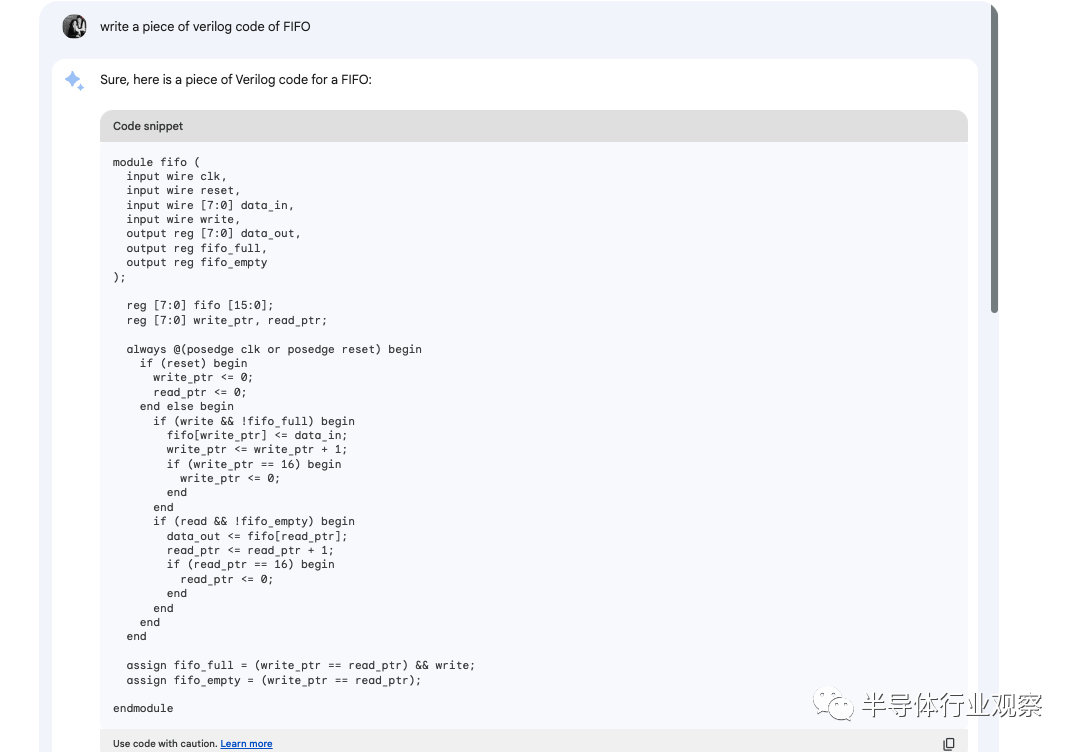
從結(jié)果來看該生成的代碼的語法正確,邏輯基本正確,但是在FIFO full和empty的信號邏輯上并沒有完全弄對(當(dāng)然其實FIFO的full和empty的邏輯也是面試中常考的問題,要完全弄對并沒那么簡單)。在代碼風(fēng)格上,我們還可以在指令中加入更多提示,類似“在代碼中加入更多注釋”,“使用參數(shù)來定義接口寬度”等等。
而在第二個實驗中,我們主要看的是Bard能否復(fù)用之前生成的模塊,并且基于這個來生成新的更大的模塊。我們使用的指令是“寫一個模塊,其中包括兩個你前面寫的FIFO模塊,并且第一個FIFO的輸出接入第二個FIFO的輸入”。
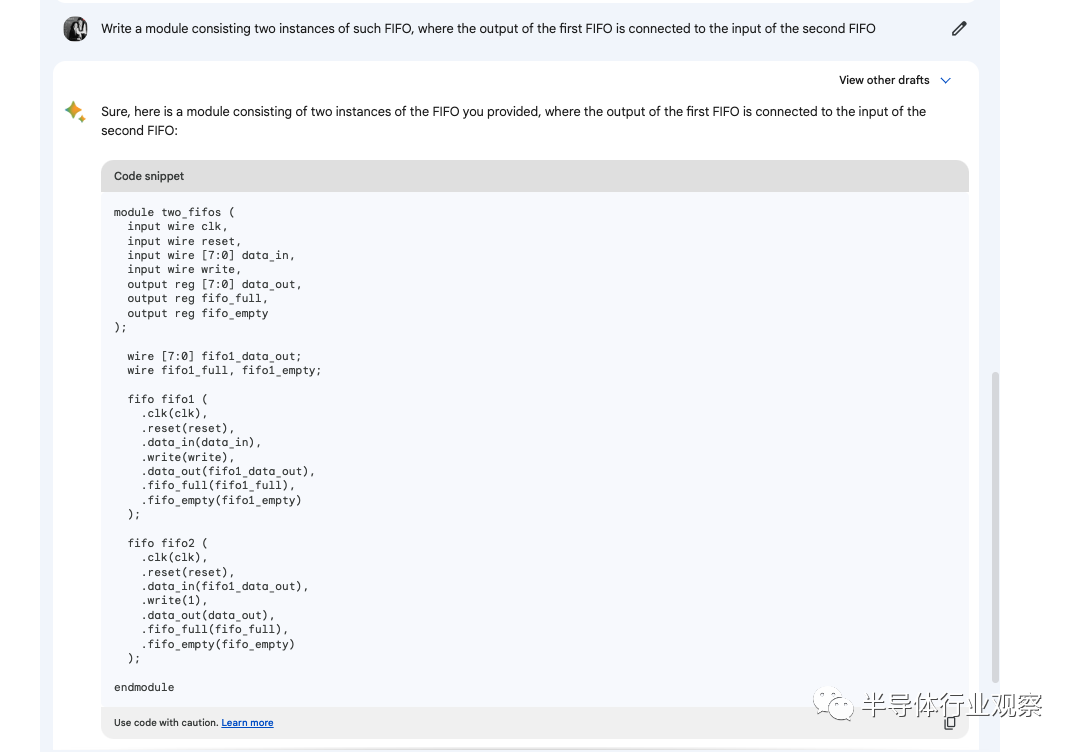
在這里我們可以看到生成的代碼基本正確,因此我們認(rèn)為PaLM 2基本擁有了能基于自底向上生成復(fù)雜代碼的能力。
芯片設(shè)計領(lǐng)域生成式AI的進(jìn)化之路
我們從上述實驗中可以看到,谷歌的PaLM 2已經(jīng)具有了基本的Verilog代碼生成能力,可以生成基本模塊和復(fù)合模塊,當(dāng)然其代碼生成的質(zhì)量還有待提高。而除了PaLM 2之外,我們認(rèn)為其他公司推出的類似ChatGPT的大語言模型也有可能會加入對于Verilog類硬件描述語言的支持。
根據(jù)谷歌在IO大會上發(fā)布的信息,目前ChatGPT類的大語言模型已經(jīng)成為許多工程師在代碼編寫時的重要助手。如果我們參考IT領(lǐng)域軟件開發(fā)工程師應(yīng)用ChatGPT類大語言模型協(xié)助代碼編寫的發(fā)展的話,我們認(rèn)為在芯片行業(yè)大語言模型也非常有可能會起到重要作用。這里,根據(jù)大語言模型在開發(fā)流程中起到的角色,我們可以大致分成三種應(yīng)用。第一種應(yīng)用是根據(jù)用戶的指令直接生成代碼,即我們在本文前面給出的兩個例子。第二種應(yīng)用是在工程師編寫代碼的時候,幫助工程師自動補全代碼;例如工程師只需要輸入一行代碼的前幾個字符,大語言模型就可以根據(jù)代碼的上下文自動幫助補全代碼,從而節(jié)省工程師的開發(fā)時間。第三種應(yīng)用是幫助工程師分析代碼和debug,正如ChatGPT可以幫助用戶優(yōu)化Python代碼并找到代碼中的bug一樣,經(jīng)過相關(guān)數(shù)據(jù)訓(xùn)練的大語言模型也可以在Verilog中實現(xiàn)相似的功能。
展望未來,參考大語言模型在IT行業(yè)的應(yīng)用軌跡,我們認(rèn)為大語言模型對于芯片設(shè)計方面的幫助預(yù)計將會從代碼自動補全開始,因為這也是大語言模型在IT行業(yè)的切入口——目前我們已經(jīng)看到類似Github co-pilot這樣的代碼補全產(chǎn)品已經(jīng)得到了許多IT公司的應(yīng)用來幫助軟件工程師提升編程效率。相對來說,代碼補全類應(yīng)用對于大語言模型的要求相對較低,目前的模型已經(jīng)能實現(xiàn)相當(dāng)高的準(zhǔn)確率,因此我們預(yù)期在芯片設(shè)計領(lǐng)域也會有應(yīng)用在Verilog領(lǐng)域的基于大語言模型的代碼補全工具會很快出現(xiàn)幫助工程師提高效率(估計谷歌內(nèi)部芯片團(tuán)隊已經(jīng)開始使用類似的工具)。
在代碼補全之后,隨著大語言模型的進(jìn)一步發(fā)展,根據(jù)用戶的指令自動生成代碼的大語言模型也將會得到越來越多的應(yīng)用。這類代碼直接生成類應(yīng)用從目前來看還需要和整個項目開發(fā)流程進(jìn)一步磨合——究竟這類代碼自動生成的應(yīng)用最適合使用在底層模塊的編寫,還是在上層模塊間集成的生成上,還需要進(jìn)一步探索,但是無論如何ChatGPT在自動代碼編寫領(lǐng)域的潛力驚人,可以把原來人工需要數(shù)小時才能編寫完的代碼在幾秒內(nèi)完成,這樣的效率提升無疑將會給整個行業(yè)和芯片開發(fā)流程帶來革命性的變化。
目前來看,ChatGPT類大語言模型在Python等流行編程語言的代碼編寫方面已經(jīng)有很不錯的效果,這證明了大語言模型實現(xiàn)自動代碼編寫、補全和debug在理論和工程上都是可以實現(xiàn)的。谷歌的PaLM 2對于Verilog的支持仍然有待進(jìn)一步完善的主要原因我們認(rèn)為還是訓(xùn)練的數(shù)據(jù)量不夠。從訓(xùn)練數(shù)據(jù)數(shù)量的角度來說,互聯(lián)網(wǎng)上有海量的開源Python代碼可供訓(xùn)練大語言模型來完成高質(zhì)量的代碼生成,但是互聯(lián)網(wǎng)上可用于訓(xùn)練大語言模型的Verilog代碼的數(shù)量比起Python等流行語言來說可能是要少了幾個數(shù)量級。并不是人類編寫的Verilog代碼數(shù)量不夠多,而是絕大多數(shù)Verilog代碼都不是開源的,而是芯片公司的知識產(chǎn)權(quán),例如谷歌在訓(xùn)練PaLM的時候不太可能獲得高通的Verilog代碼。未來誰會在開發(fā)芯片設(shè)計領(lǐng)域的大語言模型方面拔得頭籌?我們認(rèn)為有幾個不可忽視的力量:
首先是擁有全棧技術(shù)能力的大型技術(shù)公司,這些公司既有開發(fā)大語言模型的能力,又有成功的芯片業(yè)務(wù),包括美國的谷歌和中國的華為等。從技術(shù)上來說,這些公司積累了大量的Verilog相關(guān)代碼可供訓(xùn)練大語言模型,而從業(yè)務(wù)上來說,這些公司同樣也有使用大語言模型來提升芯片設(shè)計團(tuán)隊效率的驅(qū)動力。
其次是EDA巨頭,包括Synopsys、Cadence等。這些EDA公司擁有極強的業(yè)務(wù)驅(qū)動力和緊迫感,因為大語言模型AI確實會成為EDA行業(yè)下一個革命性變化,誰在這個領(lǐng)域占領(lǐng)了先機(jī)就會在下一代EDA競爭中取得優(yōu)勢;從技術(shù)積累上來說,這些公司擁有不錯的AI模型能力,同時也有海量的Verilog代碼數(shù)據(jù)量可供訓(xùn)練模型(因為這些EDA公司都有相當(dāng)成功的IP業(yè)務(wù),在開發(fā)這些IP的同時積累了足夠的高質(zhì)量代碼數(shù)據(jù))。
最后,開源社區(qū)的力量也不容忽視。從大語言模型角度來看,開源社區(qū)在CahtGPT以及開源LLAMA語言模型的基礎(chǔ)上做了大量有意義的探索,另外隨著RISC-V等開源項目的增加,開源社區(qū)擁有的數(shù)據(jù)量也會越來越多。我們預(yù)期開源社區(qū)有機(jī)會去實現(xiàn)一些小而美的基于大語言模型的新穎應(yīng)用,從而也能推動整個大語言模型在芯片設(shè)計領(lǐng)域的技術(shù)發(fā)展。
生成式AI會如何影響芯片設(shè)計工程師的工作
那么,隨著ChatGPT式AI在芯片設(shè)計中扮演越來越重要的角色,芯片工程師的日常工作將會發(fā)生怎么樣的變化?由于這里ChatGPT類生成式AI主要針對代碼編寫等前端工作,我們這里的討論范圍也主要是前端數(shù)字設(shè)計工程師。
首先,對于主要工作是前端模塊設(shè)計和集成的芯片工程師來說,我們預(yù)計很快就會有ChatGPT類的工具可以幫助代碼補全,從而增加效率。而在未來三到五年的時間范圍內(nèi),直接使用ChatGPT類生成式AI首先模塊代碼編寫有望獲得真正的應(yīng)用。從這個角度來說,我們并不認(rèn)為前端工程師的工作會被取代;相反,數(shù)字前端工程師的工作可能會越來越多地專注于模塊的功能定義,以及如何使用生成式AI能理解的方式來描述這個設(shè)計,讓AI能產(chǎn)生和工程師設(shè)計相符的代碼;從這個角度,甚至可能會出現(xiàn)一些標(biāo)準(zhǔn)化的模塊功能定義描述語言,從而讓AI能產(chǎn)生合理的代碼。
此外,芯片驗證工程師的工作將會變得越來越重要。生成式AI可以在幾秒鐘內(nèi)生成代碼,但是其生成質(zhì)量從目前來看尚需提高。從這個角度,芯片驗證一方面需要確保AI生成的代碼沒有bug,而更重要的是,芯片驗證需要能和代碼生成形成閉環(huán),例如如何實現(xiàn)一套工作流程,讓AI生成的代碼可以快速使用testbench來確保功能是否正確,并且有辦法告訴AI哪里功能不對來提示AI修改,從而在經(jīng)過多次迭代后能讓AI自動生成正確的代碼。雖然可能會需要多次迭代,但是因為每次代碼生成需要的時間很短,因此總得來看需要的代碼生成時間還是比起手寫要快許多。此外,使用生成式AI來自動生成testbench以及驗證需要的assertion也將會改變驗證工程師的工作流程,工程師將會需要花更多時間教會AI來生成正確的代碼,從而大大提升效率。
審核編輯 :李倩
-
芯片
+關(guān)注
關(guān)注
455文章
50732瀏覽量
423275 -
AI
+關(guān)注
關(guān)注
87文章
30763瀏覽量
268913 -
代碼
+關(guān)注
關(guān)注
30文章
4780瀏覽量
68539 -
生成式AI
+關(guān)注
關(guān)注
0文章
502瀏覽量
471
原文標(biāo)題:生成式AI,可以設(shè)計芯片了
文章出處:【微信號:wc_ysj,微信公眾號:旺材芯片】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
生成式AI工具作用
天璣9400生成式AI技術(shù)太牛了!打造最強AI體驗

NVIDIA AI助力SAP生成式AI助手Joule加速發(fā)展
STAR AI進(jìn)軍美股科技星智能領(lǐng)跑生成式AI賽道

生成式AI的基本原理和應(yīng)用領(lǐng)域
原來這才是【生成式AI】!!

聯(lián)發(fā)科攜生態(tài)伙伴發(fā)布《生成式AI手機(jī)產(chǎn)業(yè)白皮書》,引領(lǐng)手機(jī)生成式AI風(fēng)潮


聯(lián)發(fā)科聯(lián)合生態(tài)伙伴推出《生成式AI手機(jī)產(chǎn)業(yè)白皮書》,生成式AI手機(jī)發(fā)展路線明確了!

聯(lián)發(fā)科發(fā)布旗艦5G生成式AI移動芯片
生成式 AI 進(jìn)入模型驅(qū)動時代

生成式AI商業(yè)進(jìn)程加速,將帶動芯片需求增長
生成式 AI (3/4):如何緩解人才短缺,促進(jìn)芯片設(shè)計多元化?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論