") NVIDIA AI 技術(shù)助力 vivo 文本預(yù)訓(xùn)練大模型性能提升
NVIDIA AI 技術(shù)助力 vivo 文本預(yù)訓(xùn)練大模型性能提升
vivo AI 團(tuán)隊(duì)與 NVIDIA 團(tuán)隊(duì)合作,通過算子優(yōu)化,提升 vivo 文本預(yù)訓(xùn)練大模型的訓(xùn)練速度。在實(shí)際應(yīng)用中,訓(xùn)練提速 60%,滿足了下游業(yè)務(wù)應(yīng)用對(duì)模型訓(xùn)練速度的要求。通過 NVIDIA Nsight Systems 性能分析工具進(jìn)行性能瓶頸分析,并在此基礎(chǔ)上,針對(duì) gather、dropout、softmax、scale、layernorm 等算子進(jìn)行優(yōu)化。
客戶簡介及應(yīng)用背景
vivo 是一家以設(shè)計(jì)驅(qū)動(dòng)創(chuàng)造偉大產(chǎn)品,以智能終端和智慧服務(wù)為核心的科技公司。自 2017 年開始,vivo 不斷地思考著如何通過 AI 技術(shù)能力,為全球超過 4 億的用戶提供更好的智能服務(wù)。基于此愿景,vivo 打造了針對(duì)消費(fèi)互聯(lián)網(wǎng)場景的 1001 個(gè) AI 便利。其中,vivo AI 團(tuán)隊(duì)研發(fā)了面向自然語言理解任務(wù)的文本預(yù)訓(xùn)練模型 3MP-Text。在中文語言理解測評(píng)基準(zhǔn) CLUE 榜單上,3MP-Text 1 億參數(shù)模型效果排名同規(guī)模第一,7 億參數(shù)模型排名總榜第十(不包括人類);在 vivo 內(nèi)部的多個(gè)應(yīng)用場景如內(nèi)容理解、輿情分析、語音助手上測試,3MP-Text 1 億模型效果明顯優(yōu)于同規(guī)模開源模型,展現(xiàn)出優(yōu)秀的中文語言理解能力,具有良好的應(yīng)用價(jià)值。

此圖片來源于 vivo
*如果您有任何疑問或需要使用此圖片,請(qǐng)聯(lián)系 vivo
客戶挑戰(zhàn)
為提升預(yù)訓(xùn)練模型的效果,往往需要對(duì)模型的結(jié)構(gòu)做一定修改,(比如改變位置編碼的實(shí)現(xiàn)方式,改變模型的寬度和深度等)而這些修改,可能造成模型訓(xùn)練速度的下降。
3MP-Text 模型,采用 Deberta V2 的模型結(jié)構(gòu),該結(jié)構(gòu)使用相對(duì)位置編碼,相對(duì)于絕對(duì)位置編碼,效果更好,但其相對(duì)位置編碼的實(shí)現(xiàn)過程,增加了模型在注意力機(jī)制部分的計(jì)算量,從而降低了模型的訓(xùn)練速度。如圖 1 所示,在 NVIDIA GPU 單卡測試中,含有相對(duì)位置編碼的注意力機(jī)制的計(jì)算耗時(shí)占了單次迭代耗時(shí)的 71.5%。
另一方面,已有的研究和實(shí)踐驗(yàn)證顯示,相同參數(shù)規(guī)模下,減小模型隱層維度,增加模型層數(shù),能提升效果(效果對(duì)比見圖 2),因此,3MP-Text 模型采用了這種 DeepNarrow 的結(jié)構(gòu)。

圖 1. Deberta V2 xlarge 模型在 NVIDIA GPU 單卡上,batch size = 20 時(shí)一次迭代的 nsys timeline。單次迭代耗時(shí) 965ms,含有相對(duì)位置編碼的注意力機(jī)制(DisentangledSelfAttention)前后向計(jì)算耗時(shí) 690ms,占比 71.5%。
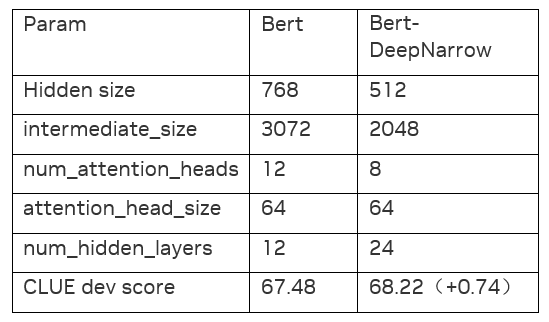
圖 2. 實(shí)際驗(yàn)證的數(shù)據(jù)表格
以上兩點(diǎn)修改,使得 3MP-Text 模型,相比同參數(shù)規(guī)模的 BERT 模型,訓(xùn)練時(shí)間多 60%,訓(xùn)練成本相應(yīng)增加,對(duì)模型在實(shí)際業(yè)務(wù)場景的應(yīng)用,造成一定障礙。比如,采用領(lǐng)域預(yù)訓(xùn)練的方法,提升 3MP-Text 模型在手機(jī)輿情領(lǐng)域任務(wù)上的整體表現(xiàn),由于模型訓(xùn)練時(shí)間比 BERT 長 60%,采用該模型會(huì)使業(yè)務(wù)功能的上線時(shí)間明顯延遲,從而影響了正常迭代優(yōu)化。
應(yīng)用方案
本案例將以 NVIDIA GPU 單卡訓(xùn)練情況為例,展開介紹 NVIDIA 所進(jìn)行的算子優(yōu)化。
如上文提到,含有相對(duì)位置編碼的注意力機(jī)制計(jì)算耗時(shí)占比達(dá) 71.5%,因此,NVIDIA 團(tuán)隊(duì)優(yōu)先對(duì)該模塊進(jìn)行了優(yōu)化,其中包括 gather 算子、dropout 算子、softmax 算子和 scale 算子的優(yōu)化。
● Gather 算子優(yōu)化:
對(duì)于 gather 操作本身,在 cuda kernel 實(shí)現(xiàn)方面,采用了 float4/half4 等數(shù)據(jù)類型進(jìn)行向量化讀寫(一次讀寫 4 個(gè) float 或 4 個(gè) half 元素),并且利用 shared memory 確保合并訪問,從而優(yōu)化 gather(前向)/ scatter(反向)cuda kernels。
除了 gather 本身的優(yōu)化外,如圖 3 所示的 pytorch 代碼中看到,有不少 elementwise 的操作(紅框所示)可以通過 kernel 融合(kernel fusion)的優(yōu)化手段,把它們都融合到一個(gè) cuda kernel(藍(lán)框所示)中,從而提升性能。如圖 4 所示,在進(jìn)行 kernel 融合前,完成相應(yīng)計(jì)算需要 9 個(gè) cuda kernels,kernel 融合后,只需要 4 個(gè) cuda kernels。
綜合 gather kernel 優(yōu)化和 kernel 融合優(yōu)化,該模塊性能提升 3.3 倍。
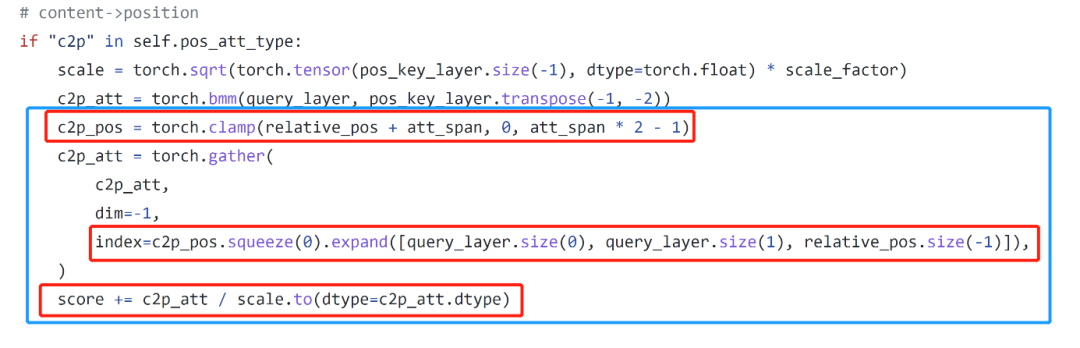
圖 3. gather 及相關(guān)操作的 pytorch 源碼。紅框?yàn)?gather 操作上下游的 elementwise 操作。藍(lán)框示意進(jìn)行 kernel 融合后,對(duì)應(yīng) cuda kernel 所執(zhí)行的全部操作。
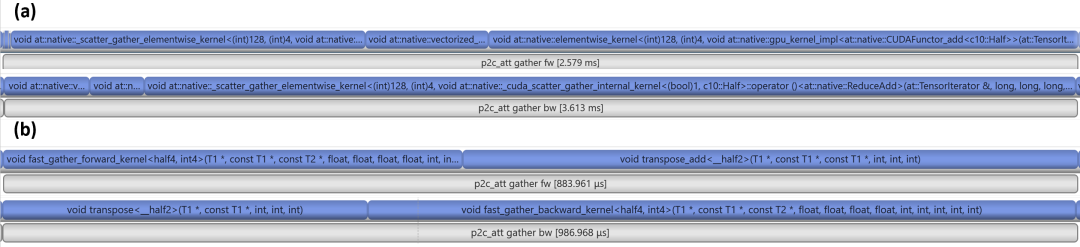
圖 4. gather 及相關(guān)操作優(yōu)化 nsys timeline 對(duì)比。(a) 優(yōu)化前,前向 (fw) 6 個(gè) cuda kernels 耗時(shí) 2.6ms,反向 (bw) 3 個(gè)cuda kernels 耗時(shí) 3.6 ms;(b)優(yōu)化后,前向 (fw) 2 個(gè) cuda kernels 耗時(shí) 0.88ms,反向 (bw) 2 個(gè) cuda kernels 耗時(shí) 0.99ms。優(yōu)化后加速比 3.3x。
●Dropout 算子優(yōu)化:
在 debertaV2 中會(huì)使用 StableDropout,如果仔細(xì)對(duì)比 pytorch 代碼,會(huì)發(fā)現(xiàn)其計(jì)算公式絕大部分情況下可以簡化為:
-
Step 1. rand_data = torch.rand_like(input)
-
Step 2. x.bernoulli_(1 - dropout) == rand_data < (1 - dropout)
-
Step 3. mask = (1 - torch.empty_like(input).bernoulli_(1 - dropout)).to(torch.bool)
-
Step 4. input.masked_fill(mask, 0) * (1.0 / (1 - dropout))
顯然上述操作涉及大量的 elementwise 的操作,因此把 step 2~4 融合到一個(gè)獨(dú)立的 cuda kernel 中,同時(shí)再次采用了 float4/half4 等數(shù)據(jù)類型進(jìn)行向量化讀寫來優(yōu)化 cuda kernel。
如圖 5 所示,在進(jìn)行 kernel 融合前,完成相應(yīng)計(jì)算需要 9 個(gè) cuda kernels,kernel 融合后,只需要 3 個(gè) cuda kernels。
綜合 dropout kernel 優(yōu)化和 kernel 融合優(yōu)化,該模塊性能提升 4.5 倍。
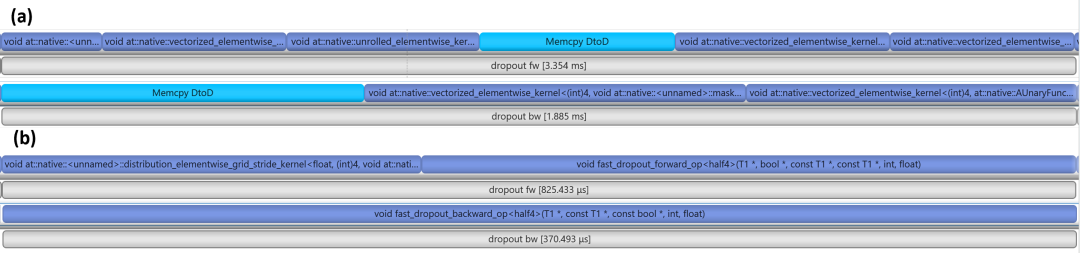
圖 5. dropout 及相關(guān)操作優(yōu)化 nsys timeline 對(duì)比。(a) 優(yōu)化前,前向 (fw) 6 個(gè) cuda kernels 耗時(shí) 3.4ms,反向 (bw) 3 個(gè) cuda kernels 耗時(shí) 1.9 ms;(b)優(yōu)化后,前向 (fw) 2 個(gè) cuda kernels 耗時(shí) 0.82ms,反向 (bw) 1 個(gè) cuda kernels 耗時(shí) 0.37ms。優(yōu)化后加速比 4.5x。
●Softmax 算子優(yōu)化:
與 dropout 類似,根據(jù)源碼對(duì) Softmax 算子的計(jì)算步驟進(jìn)行如下劃分:
-
Step 1. rmask = ~(mask.to(torch.bool))
-
Step 2. output = input.masked_fill(rmask, torch.tensor(torch.finfo(input.dtype).min))
-
Step 3. output = torch.softmax(output, self.dim)
-
Step 4. output.masked_fill_(rmask, 0)
把 step 1~4 融合到一個(gè)獨(dú)立的 cuda kernel 中。由于 softmax 計(jì)算中涉及 cuda 線程之間的同步操作,當(dāng)采用 float4/half4 等數(shù)據(jù)類型進(jìn)行向量化讀寫時(shí),也減少了參與同步的 cuda 線程數(shù)目,從而減少了同步的開銷。此外,NVIDIA 團(tuán)隊(duì)也利用寄存器數(shù)組來緩存數(shù)據(jù),避免了多次從全局內(nèi)存中讀取數(shù)據(jù)。
在 softmax 優(yōu)化中,只優(yōu)化了其前向,沿用了原有的反向?qū)崿F(xiàn)。如圖 6 所示,經(jīng)過優(yōu)化后,該模塊前向性能提升 4 倍。

圖 6. softmax 及相關(guān)操作優(yōu)化 nsys timeline 對(duì)比。(a) 優(yōu)化前,前向 (fw) 6 個(gè) cuda kernels 耗時(shí) 2.1ms;(b)優(yōu)化后,前向 (fw) 1 個(gè) cuda kernels 耗時(shí) 0.5ms。優(yōu)化后加速比 4x。
● Scale 算子優(yōu)化:
如圖 7 所示,在 attention 部分,計(jì)算 attention score 時(shí)會(huì)有一個(gè)除以 scale 的操作,這個(gè)除法操作其實(shí)可以很容易通過 cublas 的 API 融合 到矩陣乘法之中,因此,直接調(diào)用 cublasGemmStridedBatchedEx() API,實(shí)現(xiàn)了一個(gè)融合 gemm + scale 的 torch op。取得了 1.9x 的加速比(優(yōu)化前 1.42 ms,優(yōu)化后 0.75 ms)。

圖 7. Attention 部分,scale 操作相關(guān)源碼。
●Layernorm 算子優(yōu)化:
除了上述提到算子外,還通過改造 apex 中的 layer_norm 模塊(https://github.com/NVIDIA/apex/tree/master/apex/contrib/csrc/layer_norm),以便在 hidden dim=512 情況下,優(yōu)化 layernorm 算子,取得了 2.4 倍的加速比(優(yōu)化前 0.53 ms,優(yōu)化后 0.22 ms)。
使用效果及影響
使用 NVIDIA 做的算子優(yōu)化,vivo 3MP-Text 模型的訓(xùn)練速度提升 60%,達(dá)到了和同規(guī)模 BERT 模型相同的速度,下游業(yè)務(wù)應(yīng)用時(shí),模型的訓(xùn)練速度不再成為瓶頸,訓(xùn)練成本進(jìn)一步降低。另外,這些算子優(yōu)化,也可以應(yīng)用到其他使用 Deberta V2 模型的場景中。
未來,vivo AI 團(tuán)隊(duì)和 NVIDIA 將在大模型分布式訓(xùn)練、推理等方面持續(xù)合作,共同推進(jìn)生成式 AI 在手機(jī)場景行業(yè)的應(yīng)用落地(如語音助手、智能創(chuàng)作、智能辦公等)和性能提升。
點(diǎn)擊 “閱讀原文”,或掃描下方海報(bào)二維碼,在 5 月 29 日觀看 NVIDIA 創(chuàng)始人兼 CEO 黃仁勛為 COMPUTEX 2023 帶來的主題演講直播,了解AI、圖形及其他領(lǐng)域的最新進(jìn)展!
原文標(biāo)題:NVIDIA AI 技術(shù)助力 vivo 文本預(yù)訓(xùn)練大模型性能提升
文章出處:【微信公眾號(hào):NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3770瀏覽量
90990
原文標(biāo)題:NVIDIA AI 技術(shù)助力 vivo 文本預(yù)訓(xùn)練大模型性能提升
文章出處:【微信號(hào):NVIDIA_China,微信公眾號(hào):NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
KerasHub統(tǒng)一、全面的預(yù)訓(xùn)練模型庫
GPU是如何訓(xùn)練AI大模型的
NVIDIA推出全新生成式AI模型Fugatto
NVIDIA AI助力實(shí)現(xiàn)更好的癌癥檢測
AI大模型的訓(xùn)練數(shù)據(jù)來源分析
NVIDIA Nemotron-4 340B模型幫助開發(fā)者生成合成訓(xùn)練數(shù)據(jù)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論