") Google GPipe為代表的流水線并行范式
Google GPipe為代表的流水線并行范式
在上一篇的介紹中,我們介紹了以Google GPipe為代表的流水線并行范式。當模型太大,一塊GPU放不下時,流水線并行將模型的不同層放到不同的GPU上,通過切割mini-batch實現(xiàn)對訓練數(shù)據(jù)的流水線處理,提升GPU計算通訊比。同時通過re-materialization機制降低顯存消耗。
但在實際應(yīng)用中,流水線并行并不特別流行,主要原因是模型能否均勻切割,影響了整體計算效率,這就需要算法工程師做手調(diào)。因此,今天我們來介紹一種應(yīng)用最廣泛,最易于理解的并行范式:數(shù)據(jù)并行。
數(shù)據(jù)并行的核心思想是:在各個GPU上都拷貝一份完整模型,各自吃一份數(shù)據(jù),算一份梯度,最后對梯度進行累加來更新整體模型。理念不復雜,但到了大模型場景,巨大的存儲和GPU間的通訊量,就是系統(tǒng)設(shè)計要考慮的重點了。在本文中,我們將遞進介紹三種主流數(shù)據(jù)并行的實現(xiàn)方式:
DP(Data Parallelism):最早的數(shù)據(jù)并行模式,一般采用參數(shù)服務(wù)器(Parameters Server)這一編程框架。實際中多用于單機多卡
DDP(Distributed Data Parallelism):分布式數(shù)據(jù)并行,采用Ring AllReduce的通訊方式,實際中多用于多機場景
ZeRO:零冗余優(yōu)化器。由微軟推出并應(yīng)用于其DeepSpeed框架中。嚴格來講ZeRO采用數(shù)據(jù)并行+張量并行的方式,旨在降低存儲。
本文將首先介紹DP和DDP,在下一篇文章里,介紹ZeRO。全文內(nèi)容如下:
1、數(shù)據(jù)并行(DP)
1.1 整體架構(gòu)
1.2 通訊瓶頸與梯度異步更
2、分布式數(shù)據(jù)并行(DDP)
2.1 圖解Ring-AllReduce
2.2 DP與DDP通訊分析
推薦閱讀: 圖解大模型訓練之:流水線并行,以GPipe為例
一、數(shù)據(jù)并行(DP)
1.1 整體架構(gòu)
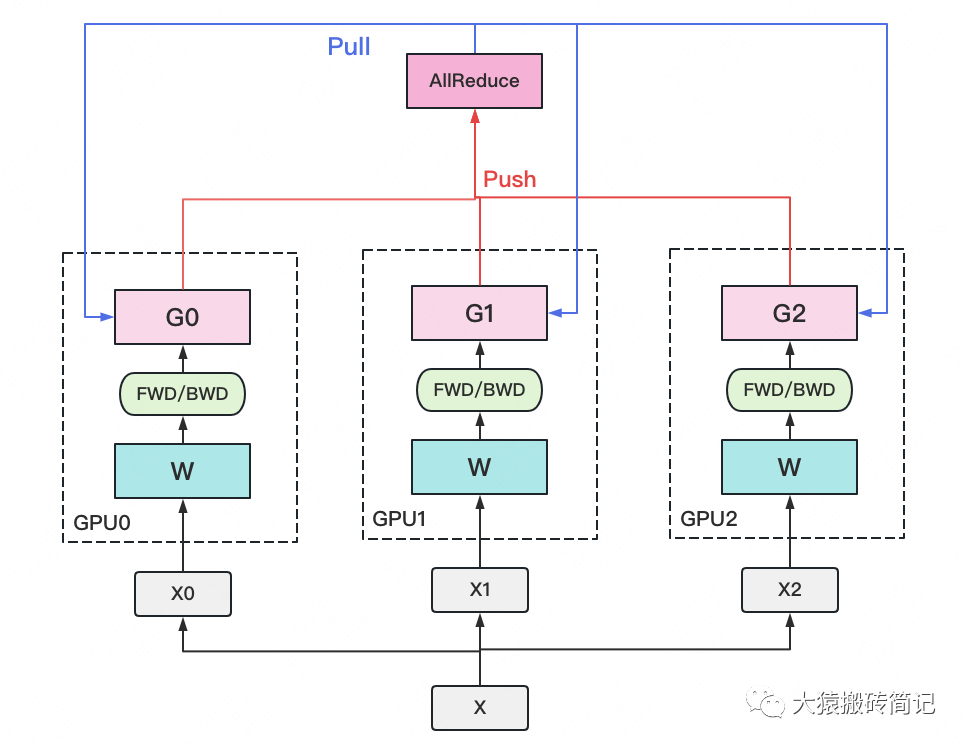
一個經(jīng)典數(shù)據(jù)并行的過程如下:
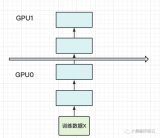
若干塊計算GPU,如圖中GPU0~GPU2;1塊梯度收集GPU,如圖中AllReduce操作所在GPU。
在每塊計算GPU上都拷貝一份完整的模型參數(shù)。
把一份數(shù)據(jù)X(例如一個batch)均勻分給不同的計算GPU。
每塊計算GPU做一輪FWD和BWD后,算得一份梯度G。
每塊計算GPU將自己的梯度push給梯度收集GPU,做聚合操作。這里的聚合操作一般指梯度累加。當然也支持用戶自定義。
梯度收集GPU聚合完畢后,計算GPU從它那pull下完整的梯度結(jié)果,用于更新模型參數(shù)W。更新完畢后,計算GPU上的模型參數(shù)依然保持一致。
聚合再下發(fā)梯度的操作,稱為AllReduce。
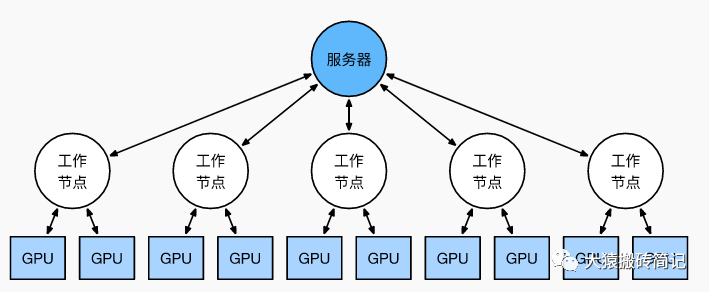
前文說過,實現(xiàn)DP的一種經(jīng)典編程框架叫“參數(shù)服務(wù)器”,在這個框架里,計算GPU稱為Worker,梯度聚合GPU稱為Server。在實際應(yīng)用中,為了盡量減少通訊量,一般可選擇一個Worker同時作為Server。比如可把梯度全發(fā)到GPU0上做聚合。需要再額外說明幾點:
1個Worker或者Server下可以不止1塊GPU。
Server可以只做梯度聚合,也可以梯度聚合+全量參數(shù)更新一起做在參數(shù)服務(wù)器的語言體系下,DP的過程又可以被描述下圖:
1.2 通訊瓶頸與梯度異步更新
DP的框架理解起來不難,但實戰(zhàn)中確有兩個主要問題:
存儲開銷大。每塊GPU上都存了一份完整的模型,造成冗余。關(guān)于這一點的優(yōu)化,我們將在后文ZeRO部分做講解。
通訊開銷大。Server需要和每一個Worker進行梯度傳輸。當Server和Worker不在一臺機器上時,Server的帶寬將會成為整個系統(tǒng)的計算效率瓶頸。
我們對通訊開銷再做詳細說明。如果將傳輸比作一條馬路,帶寬就是馬路的寬度,它決定每次并排行駛的數(shù)據(jù)量。例如帶寬是100G/s,但每秒?yún)s推給Server 1000G的數(shù)據(jù),消化肯定需要時間。那么當Server在搬運數(shù)據(jù),計算梯度的時候,Worker們在干嘛呢?當然是在:

人類老板不愿意了:“打工系統(tǒng)里不允許有串行存在的任務(wù)!”,于是梯度異步更新這一管理層略誕生了。

上圖刻畫了在梯度異步更新的場景下,某個Worker的計算順序為:
在第10輪計算中,該Worker正常計算梯度,并向Server發(fā)送push&pull梯度請求。
但是,該Worker并不會實際等到把聚合梯度拿回來,更新完參數(shù)W后再做計算。而是直接拿舊的W,吃新的數(shù)據(jù),繼續(xù)第11輪的計算。這樣就保證在通訊的時間里,Worker也在馬不停蹄做計算,提升計算通訊比。
當然,異步也不能太過份。只計算梯度,不更新權(quán)重,那模型就無法收斂。圖中刻畫的是延遲為1的異步更新,也就是在開始第12輪對的計算時,必須保證W已經(jīng)用第10、11輪的梯度做完2次更新了。
參數(shù)服務(wù)器的框架下,延遲的步數(shù)也可以由用戶自己決定,下圖分別刻劃了幾種延遲情況:
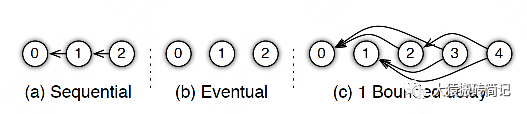
(a) 無延遲
(b) 延遲但不指定延遲步數(shù)。也即在迭代2時,用的可能是老權(quán)重,也可能是新權(quán)重,聽天由命。
(c) 延遲且指定延遲步數(shù)為1。例如做迭代3時,可以不拿回迭代2的梯度,但必須保證迭代0、1的梯度都已拿回且用于參數(shù)更新。
總結(jié)一下,異步很香,但對一個Worker來說,只是等于W不變,batch的數(shù)量增加了而已,在SGD下,會減慢模型的整體收斂速度。異步的整體思想是,比起讓Worker閑著,倒不如讓它多吃點數(shù)據(jù),雖然反饋延遲了,但只要它在干活在學習就行。
batch就像活,異步就像畫出去的餅,且往往不指定延遲步數(shù),每個Worker干越來越多的活,但模型卻沒收斂取效。讀懂分布式訓練系統(tǒng)其實也不難。
二、分布式數(shù)據(jù)并行(DDP)
受通訊負載不均的影響,DP一般用于單機多卡場景。因此,DDP作為一種更通用的解決方案出現(xiàn)了,既能多機,也能單機。DDP首先要解決的就是通訊問題:將Server上的通訊壓力均衡轉(zhuǎn)到各個Worker上。實現(xiàn)這一點后,可以進一步去Server,留Worker。
前文我們說過,聚合梯度 + 下發(fā)梯度這一輪操作,稱為AllReduce。接下來我們介紹目前最通用的AllReduce方法:Ring-AllReduce。它由百度最先提出,非常有效地解決了數(shù)據(jù)并行中通訊負載不均的問題,使得DDP得以實現(xiàn)。
2.1 Ring-AllReduce
如下圖,假設(shè)有4塊GPU,每塊GPU上的數(shù)據(jù)也對應(yīng)被切成4份。AllReduce的最終目標,就是讓每塊GPU上的數(shù)據(jù)都變成箭頭右邊匯總的樣子。
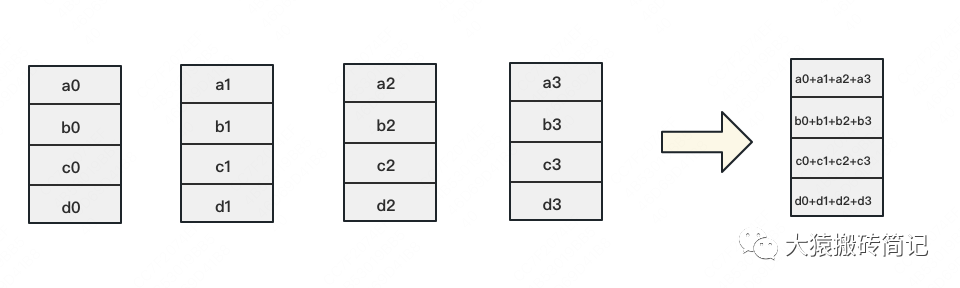
Ring-ALLReduce則分兩大步驟實現(xiàn)該目標:Reduce-Scatter和All-Gather。
Reduce-Scatter
定義網(wǎng)絡(luò)拓撲關(guān)系,使得每個GPU只和其相鄰的兩塊GPU通訊。每次發(fā)送對應(yīng)位置的數(shù)據(jù)進行累加。每一次累加更新都形成一個拓撲環(huán),因此被稱為Ring。看到這覺得困惑不要緊,我們用圖例把詳細步驟畫出來。
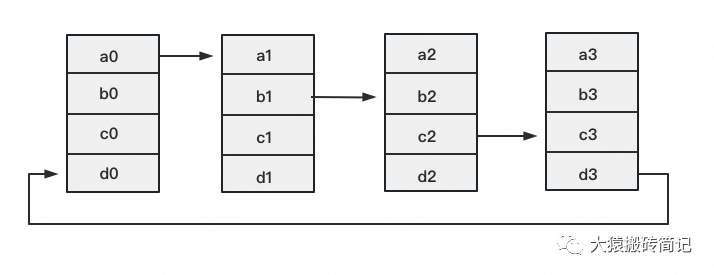
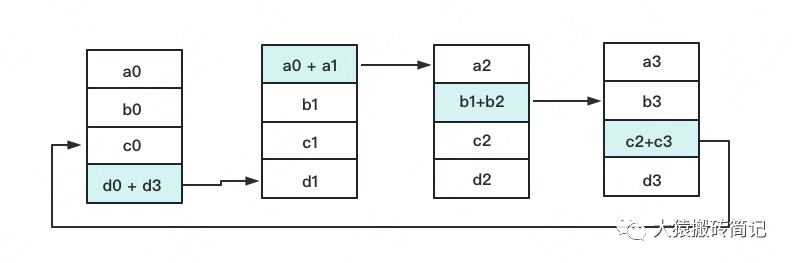
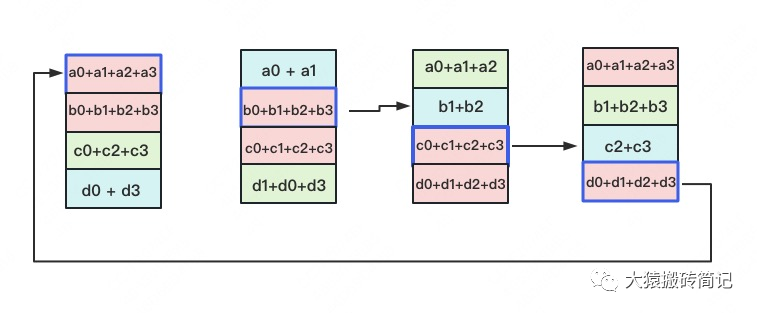
一次累加完畢后,藍色位置的數(shù)據(jù)塊被更新,被更新的數(shù)據(jù)塊將成為下一次更新的起點,繼續(xù)做累加操作。
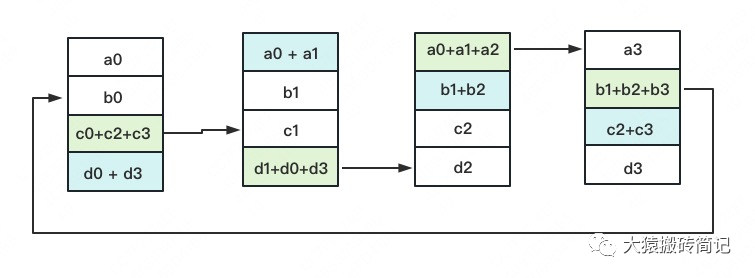
3次更新之后,每塊GPU上都有一塊數(shù)據(jù)擁有了對應(yīng)位置完整的聚合(圖中紅色)。此時,Reduce-Scatter階段結(jié)束。進入All-Gather階段。目標是把紅色塊的數(shù)據(jù)廣播到其余GPU對應(yīng)的位置上。
All-Gather
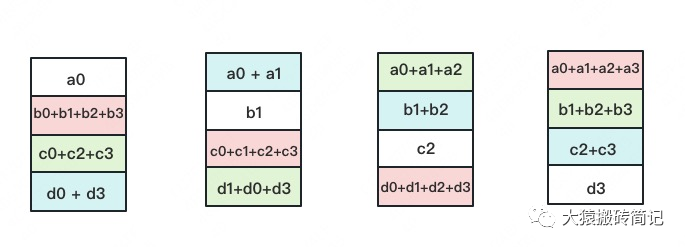
如名字里Gather所述的一樣,這操作里依然按照“相鄰GPU對應(yīng)位置進行通訊”的原則,但對應(yīng)位置數(shù)據(jù)不再做相加,而是直接替換。All-Gather以紅色塊作為起點。
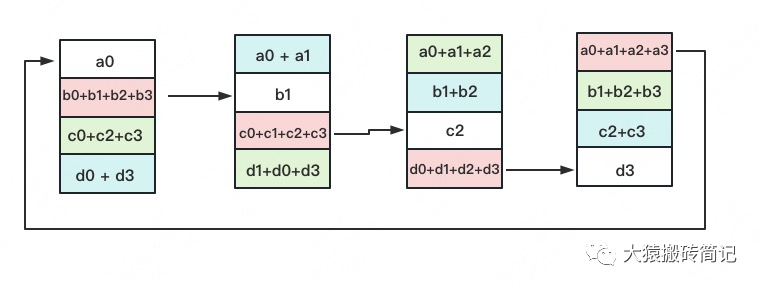
以此類推,同樣經(jīng)過3輪迭代后,使得每塊GPU上都匯總到了完整的數(shù)據(jù),變成如下形式:
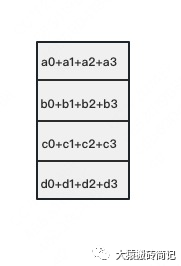
建議讀者們手動推一次,加深理解(注:最后一圖箭頭畫錯,公眾號不許修改
2.2 Ring-AllReduce通訊量分析
假設(shè)模型參數(shù)W的大小為,GPU個數(shù)為。則梯度大小也為,每個梯度塊的大小為。
對單卡GPU來說:
Reduce-Scatter階段,通訊量為
All-Gather階段,通訊量為
總通訊量為,隨著N的增大,可以近似
而對前文的DP來說,它的Server承載的總通訊量也是。雖然通訊量相同,但搬運相同數(shù)據(jù)量的時間卻不一定相同。DDP把通訊量均衡負載到了每一時刻的每個Worker上,而DP僅讓Server做勤勞的搬運工。當越來越多的GPU分布在距離較遠的機器上時,DP的通訊時間是會增加的。
但這并不說明參數(shù)服務(wù)器不能打(有很多文章將參數(shù)服務(wù)器當作old dinosaur來看)。事實上,參數(shù)服務(wù)器也提供了多Server方法,如下圖:
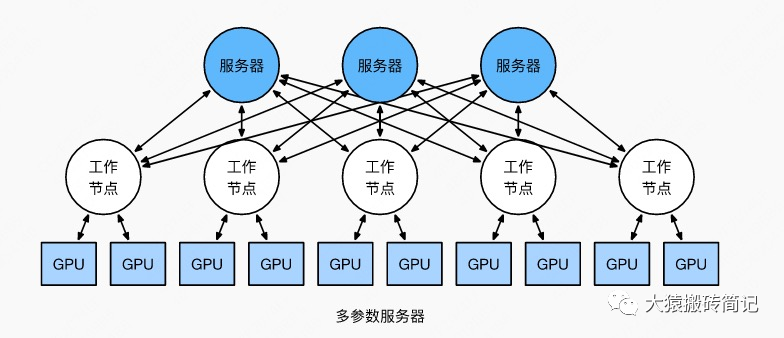
在多Server的模式下,進一步,每個Server可以只負責維護和更新某一塊梯度(也可以某塊梯度+參數(shù)一起維護),此時雖然每個Server仍然需要和所有Worker通訊,但它的帶寬壓力會小非常多。經(jīng)過調(diào)整設(shè)計后,依然可以用來做DDP。雖然這篇文章是用遞進式的方式來介紹兩者,但不代表兩者間一定要決出優(yōu)劣。我想表達的觀點是,方法是多樣性的。對參數(shù)服務(wù)器有興趣的朋友,可以閱讀參考的第1個鏈接。
最后,請大家記住Ring-AllReduce的方法,因為在之后的ZeRO,Megatron-LM中,它將頻繁地出現(xiàn),是分布式訓練系統(tǒng)中重要的算子。
三、總結(jié)
1、在DP中,每個GPU上都拷貝一份完整的模型,每個GPU上處理batch的一部分數(shù)據(jù),所有GPU算出來的梯度進行累加后,再傳回各GPU用于更新參數(shù)。
2、DP多采用參數(shù)服務(wù)器這一編程框架,一般由若個計算Worker和1個梯度聚合Server組成。Server與每個Worker通訊,Worker間并不通訊。因此Server承擔了系統(tǒng)所有的通訊壓力。基于此DP常用于單機多卡場景。
3、異步梯度更新是提升計算通訊比的一種方法,延遲更新的步數(shù)大小決定了模型的收斂速度。
4、Ring-AllReduce通過定義網(wǎng)絡(luò)環(huán)拓撲的方式,將通訊壓力均衡地分到每個GPU上,使得跨機器的數(shù)據(jù)并行(DDP)得以高效實現(xiàn)。
5、DP和DDP的總通訊量相同,但因負載不均的原因,DP需要耗費更多的時間搬運數(shù)據(jù)。
-
Google
+關(guān)注
關(guān)注
5文章
1762瀏覽量
57506 -
gpu
+關(guān)注
關(guān)注
28文章
4729瀏覽量
128890 -
模型
+關(guān)注
關(guān)注
1文章
3226瀏覽量
48809
原文標題:圖解大模型訓練之:數(shù)據(jù)并行上篇(DP, DDP與ZeRO)
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
FPGA中的流水線設(shè)計
基于流水線技術(shù)的并行高效FIR濾波器設(shè)計
CPU流水線的定義
Verilog基本功之:流水線設(shè)計Pipeline Design
FPGA之為什么要進行流水線的設(shè)計
各種流水線特點及常見流水線設(shè)計方式
如何選擇合適的LED生產(chǎn)流水線輸送方式
嵌入式_流水線

GTC 2023:深度學習之張星并行和流水線并行
什么是流水線 Jenkins的流水線詳解
以Gpipe作為流水線并行的范例進行介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論