 20個必知的自動化機器學習庫(Python)
20個必知的自動化機器學習庫(Python)
本文介紹了20個必須知道的機器學習自動化庫。
AutoML是指自動機器學習。它說明了如何在組織和教育水平上自動化機器學習的端到端過程。機器學習模型基本上包括以下步驟:
- 數據讀取和合并,使其可供使用。
- 數據預處理是指數據清理和數據整理。
- 優化功能和模型選擇過程的位置。
- 將其應用于應用程序以預測準確的值。
- 用于自動參數調整的AutoML(相對基本的類型)
- 用于非深度學習的AutoML,例如AutoSKlearn。此類型主要應用于數據預處理,自動特征分析,自動特征檢測,自動特征選擇和自動模型選擇。
- 用于深度學習/神經網絡的AutoML,包括NAS和ENAS以及用于框架的Auto-Keras。

為什么需要AutoML?
機器學習的需求日益增長。組織已經在應用程序級別采用了機器學習。仍在進行許多改進,并且仍然有許多公司正在努力為機器學習模型的部署提供更好的解決方案。 為了進行部署,企業需要有一個經驗豐富的數據科學家團隊,他們期望高薪。即使企業確實擁有優秀的團隊,通常也需要更多的經驗而不是AI知識來決定哪種模型最適合企業。機器學習在各種應用中的成功導致對機器學習系統的需求越來越高。即使對于非專家也應該易于使用。AutoML傾向于在ML管道中自動執行盡可能多的步驟,并以最少的人力保持良好的模型性能。
AutoML三大優點
-
它通過自動化最重復的任務來提高效率。這使數據科學家可以將更多的時間投入到問題上,而不是模型上。
-
自動化的ML管道還有助于避免由手工作業引起的潛在錯誤。
-
AutoML是朝著機器學習民主化邁出的一大步,它使每個人都可以使用ML功能。
以下是用Python實現
auto-sklearn
 圖片
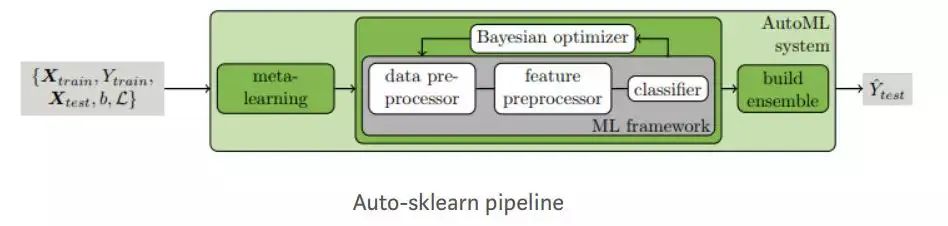
auto-sklearn是一種自動機器學習工具包,是scikit-learn估計器的直接替代品。Auto-SKLearn將機器學習用戶從算法選擇和超參數調整中解放出來。它包括功能設計方法,例如一站式,數字功能標準化和PCA。該模型使用SKLearn估計器來處理分類和回歸問題。Auto-SKLearn創建管道并使用貝葉斯搜索來優化該渠道。在ML框架中,通過貝葉斯推理為超參數調整添加了兩個組件:元學習用于使用貝葉斯初始化優化器,并在優化過程中評估配置的自動集合構造。
Auto-SKLearn在中小型數據集上表現良好,但無法生成在大型數據集中具有最先進性能的現代深度學習系統。
圖片
auto-sklearn是一種自動機器學習工具包,是scikit-learn估計器的直接替代品。Auto-SKLearn將機器學習用戶從算法選擇和超參數調整中解放出來。它包括功能設計方法,例如一站式,數字功能標準化和PCA。該模型使用SKLearn估計器來處理分類和回歸問題。Auto-SKLearn創建管道并使用貝葉斯搜索來優化該渠道。在ML框架中,通過貝葉斯推理為超參數調整添加了兩個組件:元學習用于使用貝葉斯初始化優化器,并在優化過程中評估配置的自動集合構造。
Auto-SKLearn在中小型數據集上表現良好,但無法生成在大型數據集中具有最先進性能的現代深度學習系統。
詳細原理與案例請見(點擊查看):一文徹底搞懂自動機器學習AutoML:Auto-Sklearn
例子
import sklearn.model_selection
import sklearn.datasets
import sklearn.metrics
import autosklearn.regression
def main():
X, y = sklearn.datasets.load_boston(return_X_y=True)
feature_types = (['numerical'] * 3) + ['categorical'] + (['numerical'] * 9)
X_train, X_test, y_train, y_test =
sklearn.model_selection.train_test_split(X, y, random_state=1)
automl = autosklearn.regression.AutoSklearnRegressor(
time_left_for_this_task=120,
per_run_time_limit=30,
tmp_folder='/tmp/autosklearn_regression_example_tmp',
output_folder='/tmp/autosklearn_regression_example_out',
)
automl.fit(X_train, y_train, dataset_name='boston',
feat_type=feature_types)
print(automl.show_models())
predictions = automl.predict(X_test)
print("R2 score:", sklearn.metrics.r2_score(y_test, predictions))
if __name__ == '__main__':
main()
FeatureTools
它是用于自動功能工程的python庫。
安裝
用pip安裝
python-mpipinstallfeaturetools
或通過conda上的Conda-forge頻道:
condainstall-cconda-forgefeaturetools
附加組件
我們可以運行以下命令單獨安裝或全部安裝附件
python-mpipinstallfeaturetools[complete]
更新檢查器—接收有關FeatureTools新版本的自動通知
python-mpipinstallfeaturetools[update_checker]
TSFresh基本體-在Featuretools中使用tsfresh中的60多個基本體
python-mpipinstallfeaturetools[tsfresh]
例
import featuretools as ft
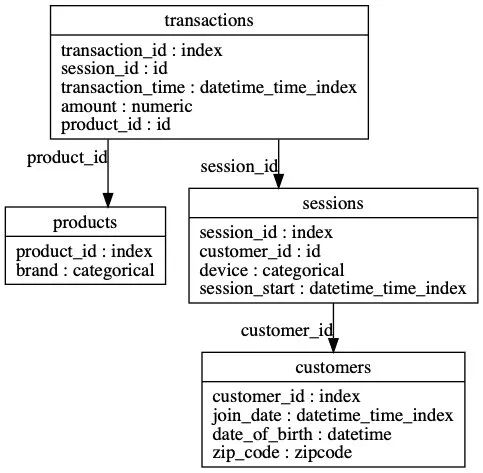
es = ft.demo.load_mock_customer(return_entityset=True)
es.plot()
圖片
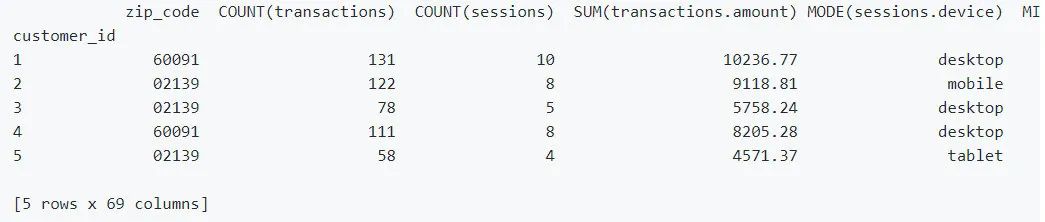
Featuretools可以為任何"目標實體"自動創建一個特征表
feature_matrix,features_defs=ft.dfs(entityset=es,
target_entity="customers")
feature_matrix.head(5)
 圖片
圖片官方網站:
https://featuretools.alteryx.com/cn/stable/
MLBox
MLBox是功能強大的自動化機器學習python庫。詳細原理與案例請見(點擊查看)一文徹底掌握自動機器學習AutoML:MLBox
根據官方文檔,它具有以下功能:
-
快速讀取和分布式數據預處理/清理/格式化
-
高度強大的功能選擇和泄漏檢測以及精確的超參數優化
-
最新的分類和回歸預測模型(深度學習,堆疊,LightGBM等)
-
使用模型解釋進行預測,MLBox已在Kaggle上進行了測試,并顯示出良好的性能。
-
管道
MLBox體系結構
MLBox主軟件包包含3個子軟件包:
-
預處理:讀取和預處理數據
-
優化:測試或優化各種學習者
-
預測:預測測試數據集上的目標
官方網站:https://github.com/AxeldeRomblay/MLBox
TPOT
TPOT代表基于樹的管道優化工具,它使用遺傳算法優化機器學習管道.TPOT建立在scikit-learn的基礎上,并使用自己的回歸器和分類器方法。TPOT探索了數千種可能的管道,并找到最適合數據的管道。 TPOT通過智能地探索成千上萬的可能管道來找到最適合我們數據的管道,從而使機器學習中最繁瑣的部分自動化。 TPOT建立在scikit-learn的基礎上,因此它生成的所有代碼都應該看起來很熟悉……無論如何,如果我們熟悉scikit-learn。詳細原理與案例請見(點擊查看)一文徹底搞懂自動機器學習AutoML:TPOT
TPOT仍在積極開發中。 下面是分類和回歸問題的兩個例子:
分類
這是具有手寫數字數據集光學識別功能的示例。
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data,
digits.target,
train_size=0.75,
test_size=0.25,
random_state=42)
tpot = TPOTClassifier(generations=5, population_size=50,
verbosity=2, random_state=42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_digits_pipeline.py')
此代碼將發現達到98%的測試精度的管道。應將相應的Python代碼導出到tpot_digits_pipeline.py文件,其外觀類似于以下內容:
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline, make_union
from sklearn.preprocessing import PolynomialFeatures
from tpot.builtins import StackingEstimator
from tpot.export_utils import set_param_recursive
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target =
train_test_split(features, tpot_data['target'], random_state=42)
# Average CV score on the training set was: 0.9799428471757372
exported_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False),
StackingEstimator(estimator=LogisticRegression(C=0.1, dual=False, penalty="l1")),
RandomForestClassifier(bootstrap=True, criterion='entropy',
max_features=0.35000000000000003,
min_samples_leaf=20, min_samples_split=19,
n_estimators=100)
)
# Fix random state for all the steps in exported pipeline
set_param_recursive(exported_pipeline.steps, 'random_state', 42)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
回歸
TPOT可以優化管道以解決回歸問題。以下是使用波士頓房屋價格數據集的最小工作示例。
from tpot import TPOTRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
housing = load_boston()
X_train, X_test, y_train, y_test = train_test_split(
housing.data,
housing.target,
train_size=0.75,
test_size=0.25,
random_state=42)
tpot = TPOTRegressor(generations=5, population_size=50,
verbosity=2, random_state=42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_boston_pipeline.py')
這將導致流水線達到約12.77均方誤差(MSE),tpot_boston_pipeline.py中的Python代碼應類似于:
import numpy as np
import pandas as pd
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
from tpot.export_utils import set_param_recursive
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE',
sep='COLUMN_SEPARATOR',
dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target =
train_test_split(features, tpot_data['target'], random_state=42)
#AverageCVscoreonthetrainingsetwas:-10.812040755234403
exported_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False),
ExtraTreesRegressor(bootstrap=False, max_features=0.5,
min_samples_leaf=2, min_samples_split=3,
n_estimators=100)
)
# Fix random state for all the steps in exported pipeline
set_param_recursive(exported_pipeline.steps, 'random_state', 42)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
Github鏈接
https://github.com/EpistasisLab/tpot
Lightwood
一個基于Pytorch的框架,它將機器學習問題分解為較小的塊,可以與一個目標無縫地粘合在一起:讓它變得如此簡單,以至于您只需要一行代碼就可以構建預測模型。
安裝
我們可以從pip安裝Lightwood:
pip3installlightwood
注意:根據我們的環境,在上面的命令中我們可能必須使用pip而不是pip3。
鑒于簡單的sensor_data.csv,我們可以預測sensor3的值。
從Lightwood導入預測變量
from lightwood import Predictor
訓練模型。
import panda
ssensor3_predictor = Predictor(output=['sensor3']
).learn(from_data=pandas.read_csv('sensor_data.csv'))
現在我們可以預測sensor3的值。
prediction = sensor3_predictor.predict(when={'sensor1':1, 'sensor2':-1})
官方鏈接:
https://github.com/mindsdb/lightwood
MindsDB
MindsDB是現有數據庫的開源AI層,可讓您輕松使用SQL查詢來開發,訓練和部署最新的機器學習模型。
官方鏈接:
https://github.com/mindsdb/mindsdb
mljar-supervised
mljar-supervised是一個自動化的機器學習Python軟件包,可用于表格數據。它旨在為數據科學家節省時間time。它抽象了預處理數據,構建機器學習模型以及執行超參數調整以找到最佳模型common的通用方法。這不是黑盒子,因為您可以確切地看到ML管道的構造方式(每個ML模型都有詳細的Markdown報告)。 在mljar-supervised中,將幫助您:
-
解釋和理解您的數據,
-
嘗試許多不同的機器學習模型,
-
通過分析創建有關所有模型的詳細信息的Markdown報告,
-
保存,重新運行和加載分析和ML模型。
它具有三種內置的工作模式:
- 解釋模式,非常適合于解釋和理解數據,其中包含許多數據解釋,例如決策樹可視化,線性模型系數顯示,排列重要性和數據的SHAP解釋,
- 執行構建用于生產的ML管道,
- 競爭模式,用于訓練具有集成和堆疊功能的高級ML模型,目的是用于ML競賽中。
官方鏈接:
https://github.com/mljar/mljar-supervisedv
Auto-Keras
Auto-Keras是由DATA Lab開發的用于自動機器學習(AutoML)的開源軟件庫。Auto-Keras建立在深度學習框架Keras之上,提供自動搜索深度學習模型的體系結構和超參數的功能。 Auto-Keras遵循經典的Scikit-Learn API設計,因此易于使用。當前版本提供了在深度學習期間自動搜索超參數的功能。 在Auto-Keras中,趨勢是通過使用自動神經體系結構搜索(NAS)算法來簡化ML。NAS基本上使用一組算法來自動調整模型,以取代深度學習工程師/從業人員。
官方鏈接:
https://github.com/keras-team/autokeras
神經網絡智能 NNI
用于神經體系結構搜索和超參數調整的開源AutoML工具包。NNI提供了CommandLine Tool以及用戶友好的WebUI來管理訓練實驗。使用可擴展的API,您可以自定義自己的AutoML算法和培訓服務。為了使新用戶容易使用,NNI還提供了一組內置的最新AutoML算法,并為流行的培訓平臺提供了開箱即用的支持。 官方網站https://nni.readthedocs.io/en/latest/
Ludwig
路德維希(Ludwig)是一個工具箱,可讓用戶無需編寫代碼即可訓練和測試深度學習模型。它建立在TensorFlow之上,Ludwig基于可擴展性原則構建,并基于數據類型抽象,可以輕松添加對新數據類型和新模型架構的支持,可供從業人員快速培訓和測試深度學習模型以及由研究人員獲得的強基準進行比較,并具有實驗設置,可通過執行相同的數據處理和評估來確保可比性。 路德維希提供了一組模型體系結構,可以將它們組合在一起以為給定用例創建端到端模型。舉例來說,如果深度學習圖書館提供了建造建筑物的基礎,路德維希提供了建造城市的建筑物,您可以在可用建筑物中進行選擇,也可以將自己的建筑物添加到可用建筑物中。
- 無需編碼:不需要任何編碼技能即可訓練模型并將其用于獲取預測。
- 通用性:新的基于數據類型的深度學習模型設計方法使該工具可在許多不同的用例中使用。
- 靈活性:經驗豐富的用戶對模型的建立和培訓具有廣泛的控制權,而新用戶則會發現它易于使用。
- 可擴展性:易于添加新的模型架構和新的特征數據類型。
- 可理解性:深度學習模型的內部通常被認為是黑匣子,但是路德維希(Ludwig)提供了標準的可視化效果來了解其性能并比較其預測。
- 開源:Apache License 2.0
官方鏈接
https://github.com/uber/ludwig
AdaNet
AdaNet是基于TensorFlow的輕量級框架,可在最少的專家干預下自動學習高質量的模型。AdaNet建立在AutoML最近的努力基礎上,以提供快速的,靈活的學習保證。重要的是,AdaNet提供了一個通用框架,不僅用于學習神經網絡體系結構,而且還用于學習集成以獲得更好的模型。 AdaNet具有以下目標:
- 易于使用:提供熟悉的API(例如Keras,Estimator)用于訓練,評估和提供模型。
- 速度:可用計算進行擴展,并快速生成高質量的模型。
- 靈活性:允許研究人員和從業人員將AdaNet擴展到新穎的子網體系結構,搜索空間和任務。
- 學習保證:優化提供理論學習保證的目標。
Darts
該算法基于架構空間中的連續松弛和梯度下降。它能夠有效地設計用于圖像分類的高性能卷積體系結構(在CIFAR-10和ImageNet上),以及用于語言建模的循環體系結構(在Penn Treebank和WikiText-2上)。只需要一個GPU。
官方鏈接
https://github.com/quark0/darts
automl-gs
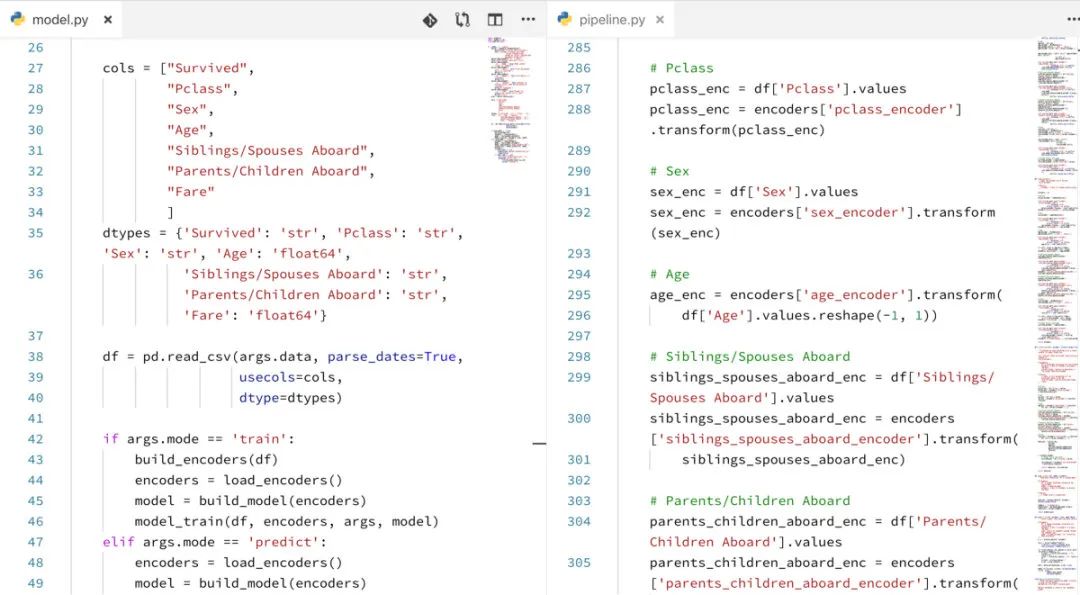
提供一個輸入的CSV文件和一個您希望預測為automl-gs的目標字段,并獲得訓練有素的高性能機器學習或深度學習模型以及本機Python代碼管道,使您可以將該模型集成到任何預測工作流中。沒有黑匣子:您可以確切地看到如何處理數據,如何構建模型以及可以根據需要進行調整。
 圖片
automl-gs是一種AutoML工具,與Microsoft的NNI,Uber的Ludwig和TPOT不同,它提供了零代碼/模型定義界面,可在多個流行的ML / DL框架中以最少的Python依賴關系獲得優化的模型和數據轉換管道。
圖片
automl-gs是一種AutoML工具,與Microsoft的NNI,Uber的Ludwig和TPOT不同,它提供了零代碼/模型定義界面,可在多個流行的ML / DL框架中以最少的Python依賴關系獲得優化的模型和數據轉換管道。
官方鏈接
https://github.com/minimaxir/automl-gs
以下是用R實現AutoKeras的R接口
AutoKeras是用于自動機器學習(AutoML)的開源軟件庫。它是由德克薩斯農工大學的DATA Lab和社區貢獻者開發的。AutoML的最終目標是為數據科學或機器學習背景有限的領域專家提供易于訪問的深度學習工具。AutoKeras提供了自動搜索深度學習模型的體系結構和超參數的功能。 在RStudio TensorFlow for R博客上查看AutoKeras博客文章。
官方文檔
https://github.com/r-tensorflow/autokeras
以下是用Scala實現
TransmogrifAI
TransmogrifAI(發音為tr?ns-m?g?r?-fī)是用Scala編寫的AutoML庫,它在Apache Spark之上運行。它的開發重點是通過機器學習自動化來提高機器學習開發人員的生產率,以及一個用于強制執行編譯時類型安全,模塊化和重用的API。通過自動化,它實現了接近手動調整模型的精度,時間減少了近100倍。 如果您需要機器學習庫來執行以下操作,請使用TransmogrifAI:
- 數小時而不是數月內即可構建生產就緒的機器學習應用程序
- 在沒有博士學位的情況下建立機器學習模型在機器學習中
- 構建模塊化,可重用,強類型的機器學習工作流程
官方鏈接
https://github.com/salesforce/TransmogrifAI
以下是用Java實現
Glaucus
Glaucus是基于數據流的機器學習套件,它結合了自動機器學習管道,簡化了機器學習算法的復雜過程,并應用了出色的分布式數據處理引擎。對于跨領域的非數據科學專業人士,幫助他們以簡單的方式獲得強大的機器學習工具的好處。 用戶只需要上傳數據,簡單配置,算法選擇,并通過自動或手動參數調整來訓練算法。該平臺還為培訓模型提供了豐富的評估指標,因此非專業人員可以最大限度地發揮機器學習在其領域中的作用。整個平臺結構如下圖所示,主要功能是:
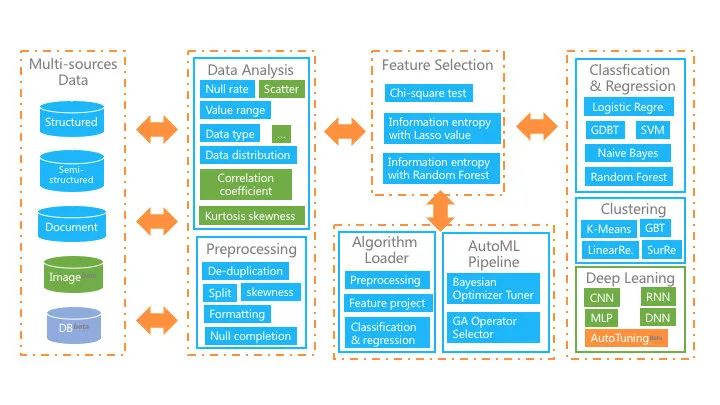 圖片
圖片
- 接收多源數據集,包括結構化,文檔和圖像數據;
- 提供豐富的數學統計功能,圖形界面使用戶輕松掌握數據情況;
- 在自動模式下,我們實現了從預處理,特征工程到機器學習算法的全管道自動化;
- 在手動模式下,它極大地簡化了機器學習流程,并提供了自動數據清理,半自動特征選擇和深度學習套件。
官方網站
https://github.com/ccnt-glaucus/glaucus
介紹幾款其他工具H20 AutoML
H2O AutoML界面設計為具有盡可能少的參數,因此用戶所需要做的只是指向他們的數據集,標識響應列,并可選地指定時間限制或訓練的總模型數量的限制。 在R和Python API中,AutoML與其他H2O算法使用相同的數據相關參數x,y,training_frame,validation_frame。大多數時候,您需要做的就是指定數據參數。然后,您可以為max_runtime_secs和/或max_models配置值,以在運行時設置明確的時間或模型數量限制。 詳細原理與案例請見(點擊查看)一文徹底搞懂自動機器學習AutoML:H2O
官方鏈接
https://github.com//h2oai/h2o-3/blob/master/h2o-docs/src/product/automl.rst
PocketFlow
PocketFlow是一個開源框架,用于以最少的人力來壓縮和加速深度學習模型。深度學習廣泛用于計算機視覺,語音識別和自然語言翻譯等各個領域。但是,深度學習模型通常在計算上很昂貴,這限制了在計算資源有限的移動設備上的進一步應用。 PocketFlow旨在為開發人員提供一個易于使用的工具包,以提高推理效率而幾乎不降低性能或不降低性能。開發人員只需指定所需的壓縮和/或加速比,然后PocketFlow將自動選擇適當的超參數以生成用于部署的高效壓縮模型。
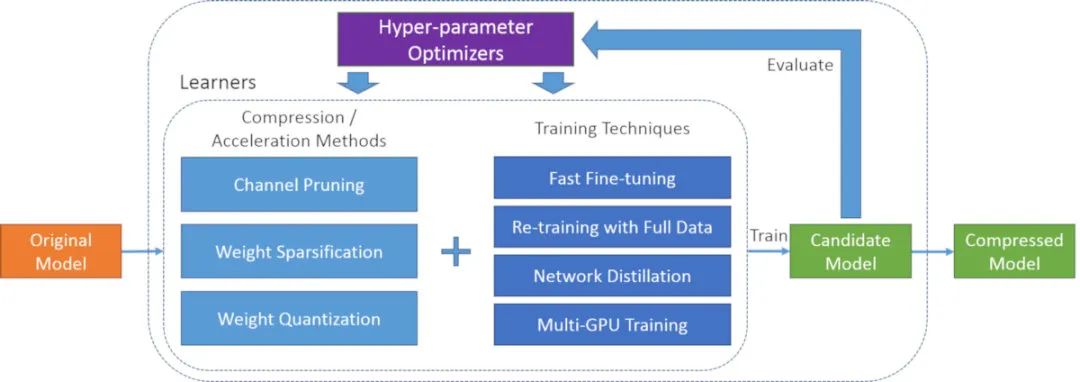 圖片
圖片
官方鏈接
https://github.com/Tencent/PocketFlow
Ray
Ray提供了用于構建分布式應用程序的簡單通用API。 Ray與以下庫打包在一起,以加快機器學習的工作量:
- Tune:可伸縮超參數調整
- RLlib:可擴展的強化學習
- RaySGD:分布式培訓包裝器
- Ray Serve:可擴展和可編程服務
官方鏈接
https://github.com/ray-project/ray
SMAC3
SMAC是用于算法配置的工具,可以跨一組實例優化任意算法的參數。這還包括ML算法的超參數優化。主要核心包括貝葉斯優化和積極的競速機制,可有效地確定兩種配置中哪一種的性能更好。 有關其主要思想的詳細說明,請參閱 Hutter, F. and Hoos, H. H. and Leyton-Brown, K.Sequential Model-Based Optimization for General Algorithm ConfigurationIn: Proceedings of the conference on Learning and Intelligent OptimizatioN (LION 5) SMAC v3是用Python3編寫的,并經過了Python3.6和python3.6的持續測試。它的隨機森林用C++編寫。
結論
autoML庫非常重要,因為它們可以自動執行重復任務,例如管道創建和超參數調整。它為數據科學家節省了時間,因此他們可以將更多的時間投入到業務問題上。AutoML還允許每個人代替一小部分人使用機器學習技術。數據科學家可以通過使用AutoML實施真正有效的機器學習來加速ML開發。 讓我們看看AutoML的成功將取決于組織的使用情況和需求。時間將決定命運。但是目前我可以說AutoML在機器學習領域中很重要。
審核編輯 :李倩
-
算法
+關注
關注
23文章
4608瀏覽量
92844 -
自動化
+關注
關注
29文章
5564瀏覽量
79245 -
機器學習
+關注
關注
66文章
8408瀏覽量
132574
原文標題:20個必知的自動化機器學習庫(Python)
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
介紹10個Python自動化腳本
常用python機器學習庫盤點
機器學習專家們每天都在做什么?如何讓機器學習自動化
分享10個實用的Python自動化腳本
使用Python腳本實現自動化運維任務

python數據挖掘與機器學習
Python 模擬鍵盤鼠標的方式實現自動化





 工商網監
工商網監
評論