 7nm制程,比GPU效率高,Meta發布第一代AI推理加速器
7nm制程,比GPU效率高,Meta發布第一代AI推理加速器
人們提起 Meta 時,通常會想到其應用程序,包括 Facebook、Instagram、WhatsApp 或即將推出的元宇宙。但許多人不知道的是這家公司設計和構建了非常復雜的數據中心來運營這些服務。
與 AWS、GCP 或 Azure 等云服務提供商不同,Meta 不需要披露有關其硅芯選擇、基礎設施或數據中心設計的細節,除了其 OCP 設計用來給買家留下深刻印象。Meta 的用戶希望獲得更好、更一致的體驗,而不關心它是如何實現的。
在 Meta,AI 工作負載無處不在,它們構成了廣泛用例的基礎,包括內容理解、信息流、生成式 AI 和廣告排名。這些工作負載在 PyTorch 上運行,具有一流的 Python 集成、即時模式(eager-mode)開發和 API 簡潔性。特別是深度學習推薦模型(DLRMs),對于改善 Meta 的服務和應用體驗非常重要。但隨著這些模型的大小和復雜性的增加,底層的硬件系統需要在保持高效的同時提供指數級增長的內存和計算能力。
Meta 發現,對于目前規模的 AI 運算和特定的工作負載,GPU 的效率不高,并不是最佳選擇。因此,該公司提出了推理加速器 MTIA,幫助更快地訓練 AI 系統。
MTIA V1
MTIA v1(推理)芯片(die)
2020 年,Meta 為其內部工作負載設計了第一代 MTIA ASIC 推理加速器。該推理加速器是其全棧解決方案的一部分,整個解決方案包括芯片、PyTorch 和推薦模型。
MTIA 加速器采用 TSMC 7nm 工藝制造,運行頻率為 800 MHz,在 INT8 精度下提供 102.4 TOPS,在 FP16 精度下提供 51.2 TFLOPS。它的熱設計功耗 (TDP) 為 25 W。
MTIA 加速器由處理元件 (PE)、片上和片外存儲器資源以及互連組成。該加速器配備了運行系統固件的專用控制子系統。固件管理可用的計算和內存資源,通過專用主機接口與主機通信,協調加速器上的 job 執行。
內存子系統使用 LPDDR5 作為片外 DRAM 資源,可擴展至 128 GB。該芯片還有 128 MB 的片上 SRAM,由所有 PE 共享,為頻繁訪問的數據和指令提供更高的帶寬和更低的延遲。
MTIA 加速器網格包含以 8x8 配置組織的 64 個 PE,這些 PE 相互連接,并通過網狀網絡連接到內存塊。整個網格可以作為一個整體來運行一個 job,也可以分成多個可以運行獨立 job 的子網格。
每個 PE 配備兩個處理器內核(其中一個配備矢量擴展)和一些固定功能單元,這些單元經過優化以執行關鍵操作,例如矩陣乘法、累加、數據移動和非線性函數計算。處理器內核基于 RISC-V 開放指令集架構 (ISA),并經過大量定制以執行必要的計算和控制任務。
每個 PE 還具有 128 KB 的本地 SRAM 內存,用于快速存儲和操作數據。該架構最大限度地提高了并行性和數據重用性,這是高效運行工作負載的基礎。
該芯片同時提供線程和數據級并行性(TLP 和 DLP),利用指令級并行性 (ILP),并通過允許同時處理大量內存請求來實現大量的內存級并行性 (MLP)。
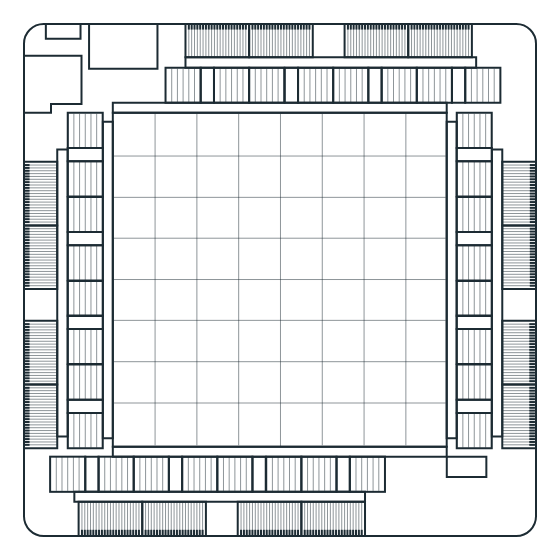
MTIA v1 系統設計
MTIA 加速器安裝在小型雙 M.2 板上,可以更輕松地集成到服務器中。這些板使用 PCIe Gen4 x8 鏈接連接到服務器上的主機 CPU,功耗低至 35 W。

帶有 MTIA 的樣品測試板
托管這些加速器的服務器使用來自開放計算項目的 Yosemite V3 服務器規范。每臺服務器包含 12 個加速器,這些加速器連接到主機 CPU,并使用 PCIe 交換機層級相互連接。因此,不同加速器之間的通信不需要涉及主機 CPU。此拓撲允許將工作負載分布在多個加速器上并并行運行。加速器的數量和服務器配置參數經過精心選擇,以最適合執行當前和未來的工作負載。
MTIA 軟件棧
MTIA 軟件(SW)棧旨在提供給開發者更好的開發效率和高性能體驗。它與 PyTorch 完全集成,給用戶提供了一種熟悉的開發體驗。使用基于 MTIA 的 PyTorch 與使用 CPU 或 GPU 的 PyTorch 一樣簡單。并且,得益于蓬勃發展的 PyTorch 開發者生態系統和工具,現在 MTIA SW 棧可以使用 PyTorch FX IR 執行模型級轉換和優化,并使用 LLVM IR 進行低級優化,同時還支持 MTIA 加速器自定義架構和 ISA。
下圖為 MTIA 軟件棧框架圖:
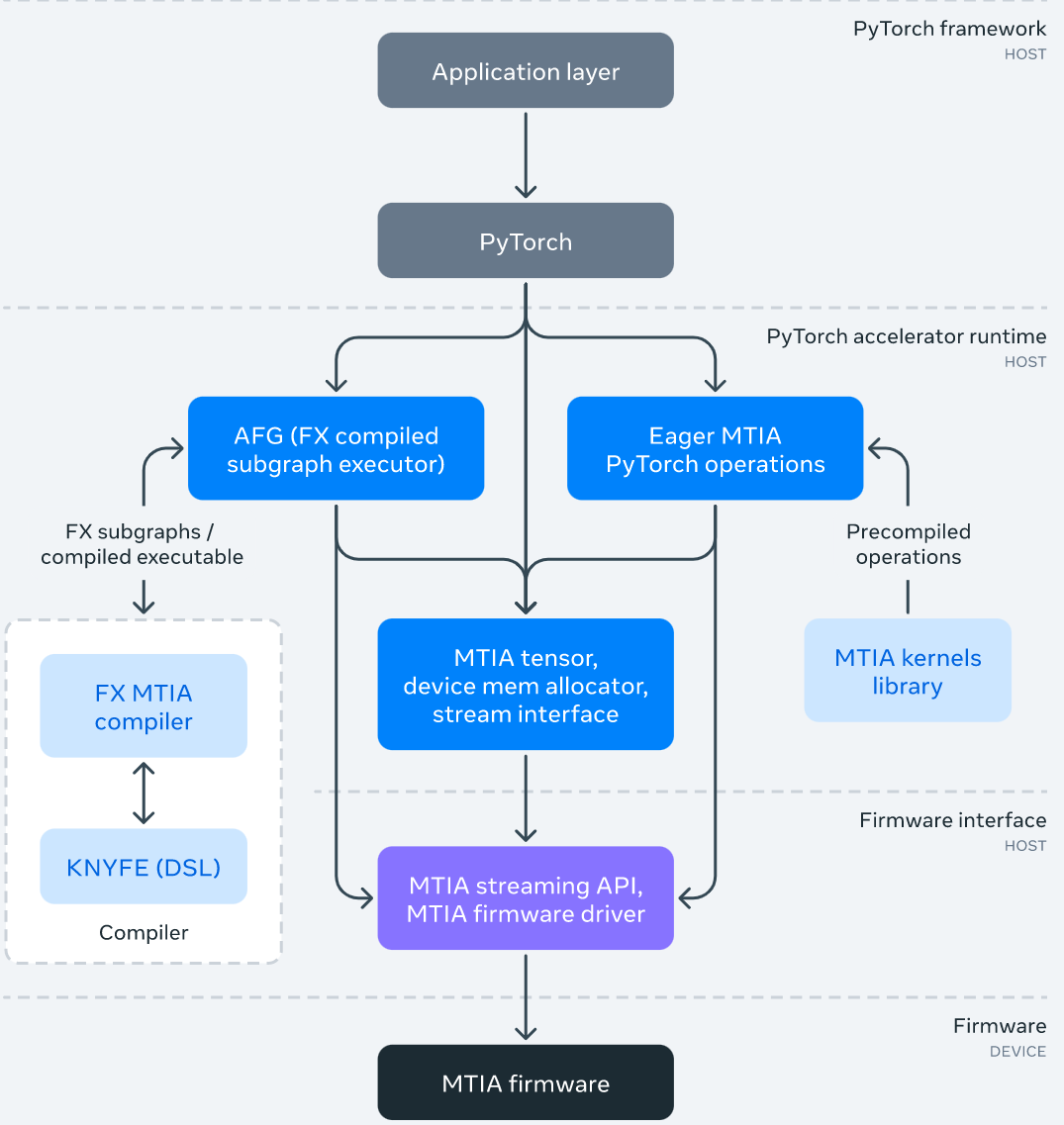
作為 SW 棧的一部分,Meta 還為性能關鍵型 ML 內核開發了一個手動調整和高度優化的內核庫,例如完全連接和嵌入包運算符。在 SW 棧的更高層級可以選擇在編譯和代碼生成過程中實例化和使用這些高度優化的內核。
此外,MTIA SW 棧隨著與 PyTorch 2.0 的集成而不斷發展,PyTorch 2.0 更快、更 Python 化,但一如既往地動態。這將啟用新功能,例如 TorchDynamo 和 TorchInductor。Meta 還在擴展 Triton DSL 以支持 MTIA 加速器,并使用 MLIR 進行內部表示和高級優化。
MTIA 性能
Meta 比較了 MTIA 與其他加速器的性能,結果如下:
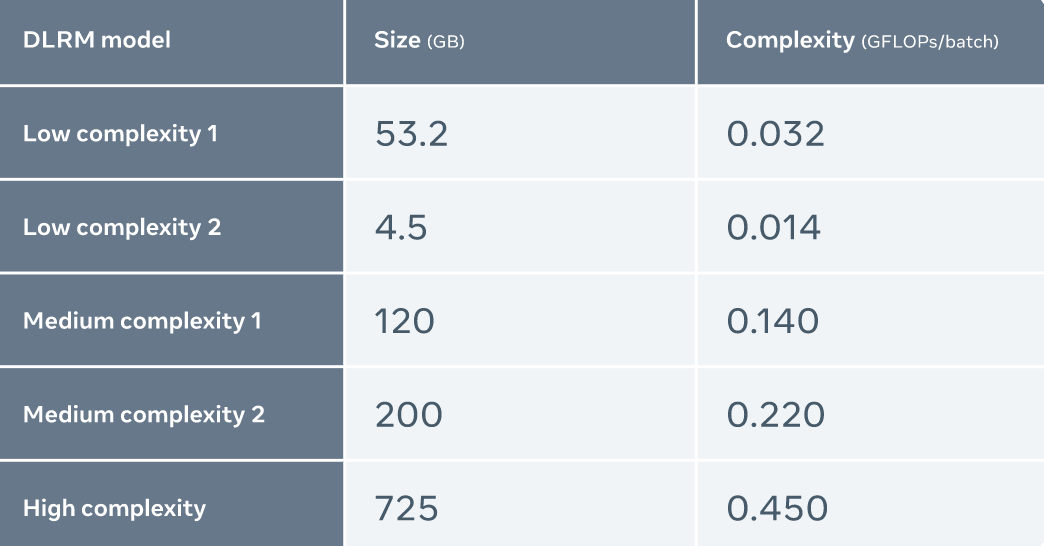
Meta 使用五種不同的 DLRMs(復雜度從低到高)來評估 MTIA
此外,Meta 還將 MTIA 與 NNPI 以及 GPU 進行了比較,結果如下:
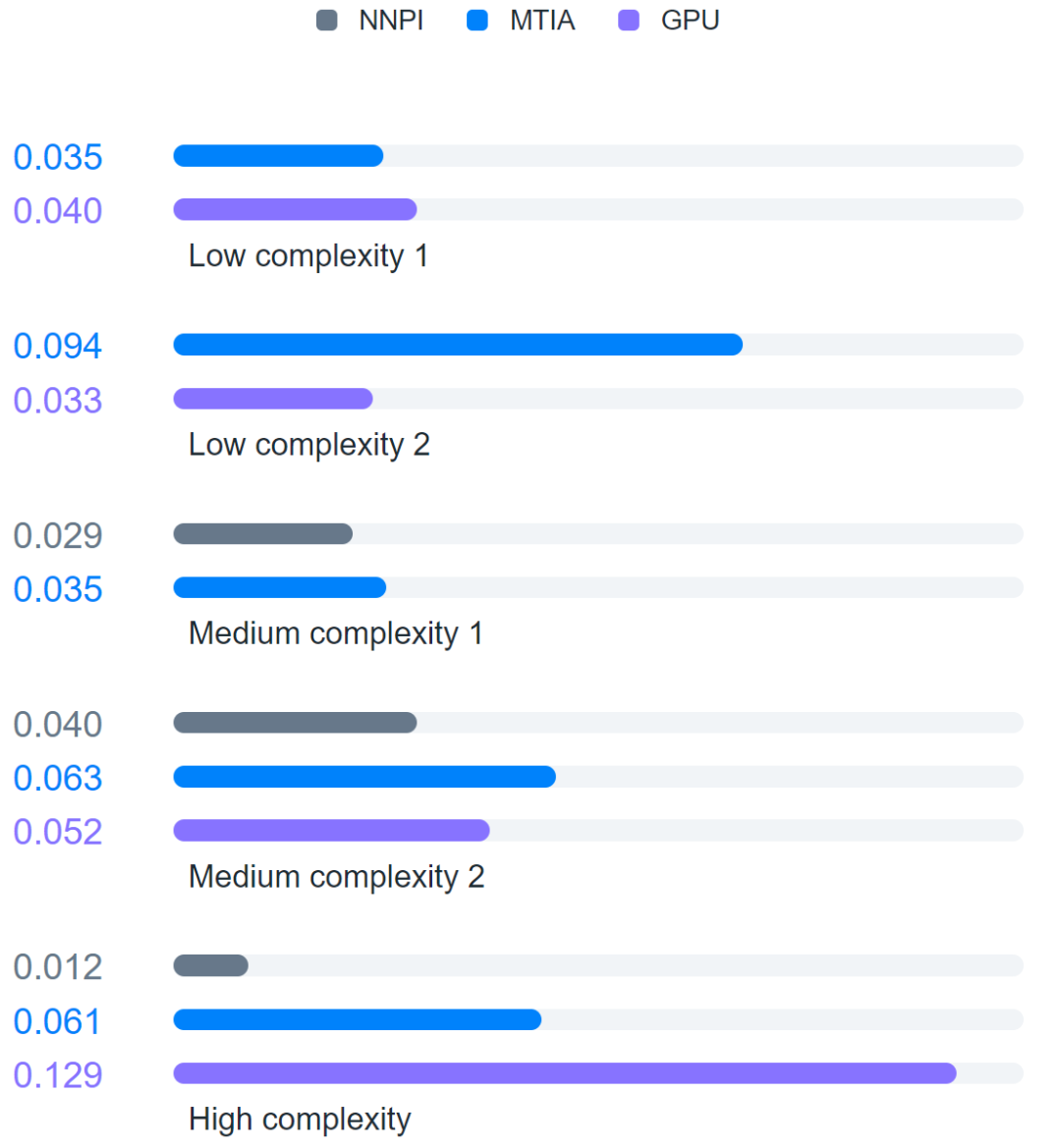
評估發現,與 NNPI 和 GPU 相比,MTIA 能夠更高效地處理低復雜度(LC1 和 LC2)和中等復雜度(MC1 和 MC2)的模型。此外,Meta 尚未針對高復雜度(HC)模型進行 MTIA 的優化。
審核編輯 :李倩
-
加速器
+關注
關注
2文章
799瀏覽量
37842 -
gpu
+關注
關注
28文章
4729瀏覽量
128899 -
pytorch
+關注
關注
2文章
808瀏覽量
13202
原文標題:7nm制程,比GPU效率高,Meta發布第一代AI推理加速器
文章出處:【微信號:AI智勝未來,微信公眾號:AI智勝未來】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
所謂的7nm芯片上沒有一個圖形是7nm的

AMD助力HyperAccel開發全新AI推理服務器

下一代高功能新一代AI加速器(DRP-AI3):10x在高級AI系統高級AI中更快的嵌入處理

進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
英特爾AI產品助力其運行Meta新一代大語言模型Meta Llama 3
Arm推動生成式AI落地邊緣!全新Ethos-U85 AI加速器支持Transformer 架構,性能提升四倍

Meta第二代自研AI芯片出世,性能提升三倍以上

2024年全球與中國7nm智能座艙芯片行業總體規模、主要企業國內外市場占有率及排名
瑞薩發布下一代動態可重構人工智能處理器加速器
NVIDIA將在今年第二季度發布Blackwell架構的新一代GPU加速器“B100”






 工商網監
工商網監
評論