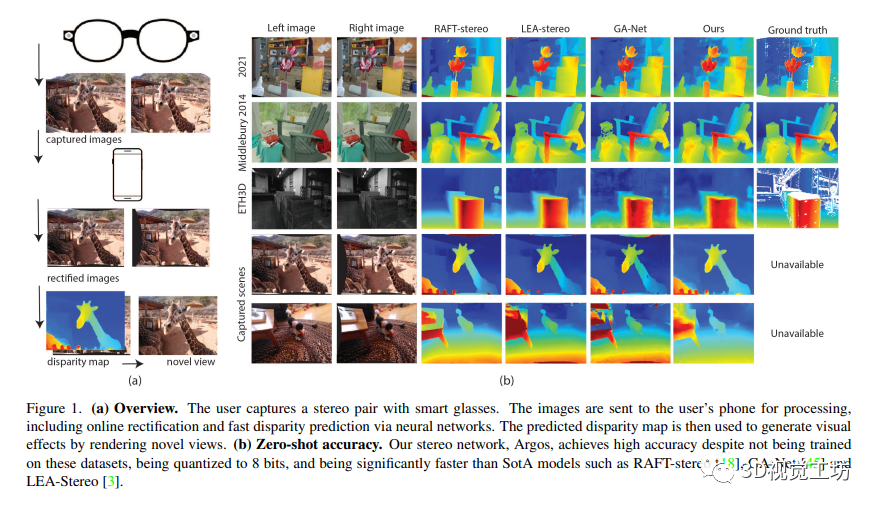
 一種端到端的立體深度感知系統的設計
一種端到端的立體深度感知系統的設計
本文提出了一種生產化的端到端立體深度感知系統設計,可以完成預處理、在線立體校正和立體深度估計,并支持糾偏失敗后的單目深度估計備選方案。同時,該深度感知系統的輸出應用于一種基于智能眼鏡拍攝的視角生成管道,創造出具有3D計算攝影效果的視覺效果。此外,該系統設計可以在手機的嚴格計算預算內運行,具有通用性,可以適用于各種品牌的智能手機。該論文的設計是為了解決智能眼鏡中的深度感知問題,可以為智能眼鏡提供更好的增強現實體驗。
1 前言
本文介紹了一種生產化的端到端深度感知系統,包括預處理、在線立體校正、立體深度估計并支持單目深度估計的備用方案。該系統的輸出結果應用于視角生成的渲染管道,創建具有3D計算攝影效果的效果。該系統設計具有通用性和穩健性,可以用于不同品牌的主流手機。
我們的技術和系統貢獻包括:
詳細描述了一個端到端的立體系統,并提供了小心的設計選擇和備用方案,這些策略可以成為其他類似深度系統的基線;
引入了一種新的在線校正算法,具有快速和穩健的特點,有助于提高立體視覺的準確性;
提出了一種新穎的策略,共同設計立體網絡和單目深度網絡,使兩個網絡的輸出格式相似,從而更好地利用他們的結構信息;
證明了在計算預算有限的情況下,本文的量化網絡實現了競爭性的準確度,可以應用于計算資源有限的場景。
2 相關背景
本文關注于構建用于靈活智能眼鏡的完整立體系統,該系統具有魯棒性和輕量化處理,能夠在線校正,具有用于提顯和3D效果等功能。現有工作多集中在系統的某些組件,很少有文章著眼于整個系統設計。對于在線立體校正,因為幾乎所有實際立體系統都存在校正問題,研究者嘗試了一些方法,其中的一個是在匹配代價中只利用水平梯度或使用包含小的垂直視差樣本進行匹配代價訓練等。對于單目深度估計,有監督和無監督方法都被用于深度學習中,輸出通常是相對深度/視差。對于立體深度估計,最近的研究中,立體匹配的特征學習通過深度學習進行替代,目前主要關注于端到端學習,有2D CNNs、3D CNNs和RNNs等三種類型的架構。其中RNN方法得到最先進的性能,但無法在設備上運行,近期的工作則嘗試著使立體網絡在設備上運行更快。
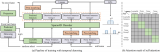
3 系統概述
本文提出了一種基于智能眼鏡的深度感知計算攝影系統。該系統配備一對硬件同步的魚眼相機,可拍攝場景圖像并將其傳輸至智能手機進行進一步處理。作者使用在線校準和校準算法估計外部和內部參數進行準確的校準,使用相對視差來創建深度計算攝影效果,并通過共享數據集訓練兩個網絡以實現相同的下游處理。最終,預測的視差和相應的圖像被傳遞到渲染流水線,以創建最終的三維效果。
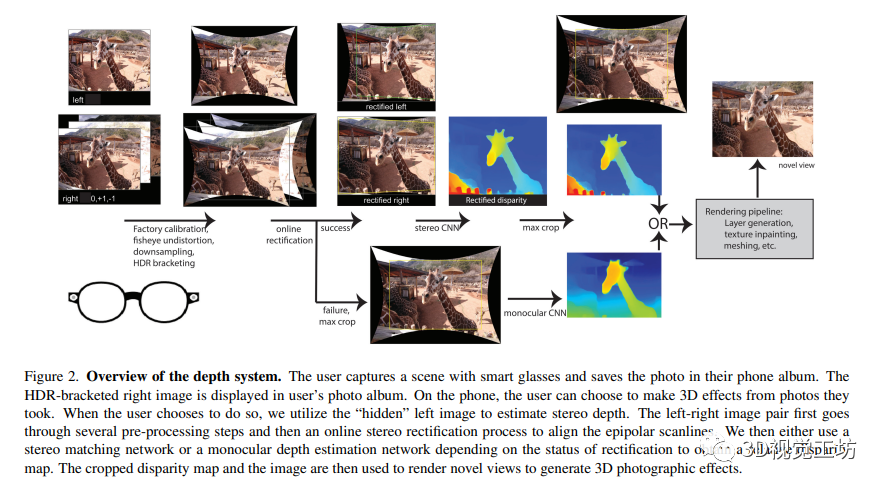
4 在線校正
根據輸入的魚眼圖像,通過計算精確的對應特征點,然后在原始圖像和重新校正后的圖像中保持世界坐標系與立體系統相對,來估計兩個攝像機的旋轉角度,從而進行在線校正。此方法通過估計相對尺度來補償焦距隨溫度的變化,最終使得雙視圖立體算法更加準確和魯棒。其中,相對俯仰角是相對的,而絕對俯仰角是一個自由參數。

4.1 Projection model - 投影模型
該部分內容介紹了通過投影模型計算兩張圖片中點的相對位置和姿態。其中,對內參矩陣和徑向畸變進行了校正。通過將點投影到不同的相機中并估計其在兩張圖片中的深度,可以計算相機之間的相對方向和絕對的旋轉和偏航。通過引入尺度修正,可以進一步約束相機之間的相對高度。
4.2 Rectification algorithm - 矯正算法
該算法通過使用Harris角點和層次亞像素ZSSD特征匹配器在圖像間匹配特征點,并配合使用魯棒最小二乘法求解方程組來實現對圖像的矯正。該算法能夠可靠地提取到特征點并計算出矯正角度。算法采用四個參數模型,包括?ωx、?ωy、?ωz和?f ,并且通過內點控制實現超約定系統的求解。對于每個匹配,它的表現很穩定并產生了很好的結果。
5 Co-design of monocular and stereo networks - 單目和立體網絡的聯合設計
本文提出了一種新的方法來協同設計立體和單目深度網絡,以使其輸出具有一致性,輕量級并且盡可能精確。該方法通過將單目深度網絡訓練為預測相對深度和相機運動,而不是絕對深度,來保持輸出格式的一致性。接著,作者設計了一個立體網絡,使用相同的特征提取器來預測相對視差。為了保持一致性,作者還使用了可訓練的縮放和偏移參數,并使用一個損失函數來同時考慮單目和立體網絡的輸出。該方法在聯合訓練中表現出很好的穩定性和精度。
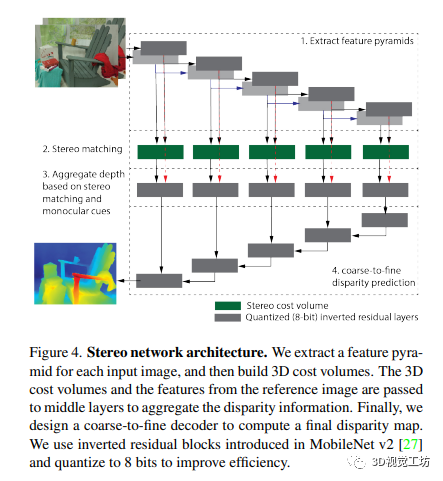
5.1 Stereo network - 立體網絡
作者設計了一個立體視網絡,其組件靈感來源于經典的和深度的立體視方法:
一個編碼器,從輸入的立體圖像中獨立提取多分辨率特征和特征 ,其中 l = 1 … L,用于 L 層特征金字塔。
利用余弦距離比較左右特征距離的三維代價體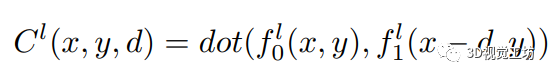
使用許多中間層將代價體和參考圖像的圖像特征作為輸入,并匯總視差信息。因為中間層直接從代價體和參考圖像獲取信息,所以它們可以在立體匹配線索較弱(例如在無紋理區域)或缺失時(例如在半遮擋區域)更好地利用單眼深度線索。
粗到細解碼器以預測輸出視差圖。輸出視差圖的分辨率與輸入右圖像相同。每個解碼器模塊結合低分辨率解碼器模塊的輸出和相同分辨率中間層的輸出。
5.2 Monocular network - 單目網絡
我們設計了一個單目深度估計網絡,其包含三個組件:
用于提取多分辨率圖像特征f_l=1...L的編碼器;
中間層用于聚合深度信息;
粗到細的解碼器用于預測視差圖。
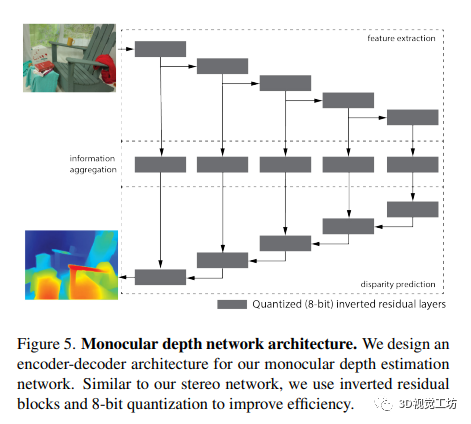
5.3 Shared network components - 共享網絡組件
作者研究了單目深度估計和立體視覺之間的聯合訓練,從而提高了深度估計的質量。在共享網絡組件方面,該文使用相同的編碼器、中間層和解碼器,同時使用立體代價體模塊,從而提高網絡的表現。為了提高效率,文章使用反向殘差模塊進行所有層的量化,并將權重和激活量化為8位。同時,輸出層保持為32位來獲得亞像素分辨率。其損失函數使用平滑L1損失和梯度損失項來訓練網絡。
5.4 Novel training datasets - 新型訓練數據集
本文提出了一種通過渲染內部單目數據集來獲得立體數據集以進行聯合訓練的方法。為了使立體數據集具有逼真性和挑戰性,作者對其進行了數據增強(亮度、對比度、色相、飽和度、jpeg壓縮等),并在遇到高光反射和無效區域(由深度流水線中的變形和矯正引起)時進行了訓練,使網絡能夠忽略這些干擾。文章還探討了簡化立體數據集生成的方法,使得該數據集比任何現有的訓練數據集都更具多樣性。
6 Novel view synthesis - 新視角合成
本文采用基于LDI的方法來實現新視角合成。對于立體數據集的創建,使用單目真實深度和彩色圖像來創建紋理網格,并渲染第二個視角。對于3D效果,使用來自立體系統的預測和預定義的軌跡來生成平滑的新視角視頻。其中LDI是層深度圖,可以通過LDI修復插值法推測被遮擋的幾何形狀。
7 實驗
在本文中,作者介紹了一種新的立體視覺深度估計方法,即使用共享編碼器、中間層和解碼器的高效單目網絡Tiefenrausch和附加的成本體積模塊來構建立體網絡Argos。對于生產模型,作者使用4M內部iPhone數據集重新訓練了Tiefenrausch,并使用FBGEMM后端進行量化感知訓練(QAT),從而實現了高精度。作者還使用Sceneflow數據集進行了對比實驗。
作者在三星Galaxy S8 CPU上對流水線進行了基準測試。校正流水線需要300-400ms,立體網絡需要大約965ms。流水線的其他部分總共需要比這兩個步驟更低的延遲。作者的模型經過了移動CPU優化,但將SotA模型轉換為移動友好的格式并不容易,也不是非常有意義,因為它們并不是為移動設備設計的。為了權衡,作者在Intel(R) Xeon(R) Gold 6138 CPU @ 2.00GHz的計算機服務器上比較所有模型的運行時間。
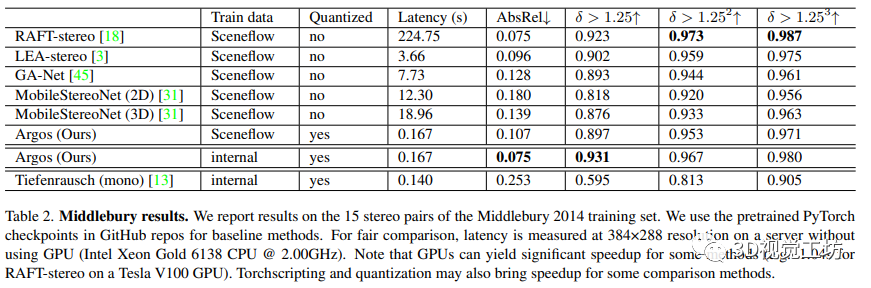
本文在Middlebury 2014數據集上對作者的方法與幾種SotA立體方法進行了定量比較。作者的方法在速度上快于其他方法,并且實現了與SotA方法相當的性能。通過使用內部渲染的立體數據集進行訓練,作者的性能進一步提高,并實現了最佳的絕對相對誤差。作者新設計有效地從單目數據集呈現了立體數據集以訓練模型。雖然作者的設計選擇可能在Middlebury等基準測試上導致精度下降,但作者追求的是設計一個穩健的端到端深度系統。作者的量化8位立體模型是首次提出的,比較模型都使用32位權重和激活。盡管存在一些不利因素,但作者還是實現了與SotA方法相當的性能,并且運行速度更快。
本文描述了一項針對3D照片質量的調查。通過渲染深度系統的新視角視頻進行調查,參與者對視頻質量進行評分。研究結果表明,立體聲得分的平均分數為3.44,單目深度得分的平均分數為2.96。結果顯示,深度圖質量有時與渲染的新視角視頻的質量并不直接相關。作者強調了僅使用標準指標來比較方法是不足以評價立體聲方法在實踐中的表現的
8 結論
本文介紹了一種端到端的立體深度感知系統的設計,可以在智能手機上高效運行。該系統包括了一個在線矯正算法、單目和立體視差網絡的協同設計,以及從單目數據集中提取大型立體數據集的新方法。作者還提出了一個8位量化的立體模型,與最先進的方法相比,在標準立體基準測試中具有競爭性能。
-
智能手機
+關注
關注
66文章
18477瀏覽量
180110 -
感知系統
+關注
關注
1文章
70瀏覽量
15940 -
智能眼鏡
+關注
關注
8文章
651瀏覽量
72792
原文標題:CVPR2023 I 一種實用的智能眼鏡深度感知系統
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何通過立體視覺構建小巧輕便的深度感知系統

移動協作機器人的RGB-D感知的端到端處理方案
一種基于端到端基于語音的對話代理
基于深度神經網絡的端到端圖像壓縮方法

端到端的深度學習網絡人體自動摳圖算法

一種對紅細胞和白細胞圖像分類任務的主動學習端到端工作流程

Sparse4D-v3:稀疏感知的性能優化及端到端拓展







 工商網監
工商網監
評論