 在InnoDB如何選擇從LRU_list
在InnoDB如何選擇從LRU_list
在InnoDB 如何選擇從LRU_list 刷臟還是從flush_list 刷臟, 本質問題就是page replacement policies
fast path: 從LRU_list 刷臟, 依據的是哪些page 最老被訪問過來排序, 由于有些 page 沒有被修改過, 那么釋放page 可以無需IO, 可以快速獲得free page. 但是也有page 被修改, 那么就需要進行IO 了.
slow path: 從flush list 刷臟, 是按照 oldest_modification lsn來排序, 并且flush list 上面的page 都是臟頁, 獲得free page 必須進行一次IO, 但是刷臟下去以后checkpoint 就可以推進, redo 空間就可以釋放, crash recovery 就更快.
另外由于page 的newest_modification lsn 有可能一直在漲, 需要等到redo log log_write_up_to lsn 以后該page 才可以刷下去, 具體函數 buf_flush_write_block_low() 里面, 因此對比LRU list 上刷臟獲得free page 肯定慢很多.
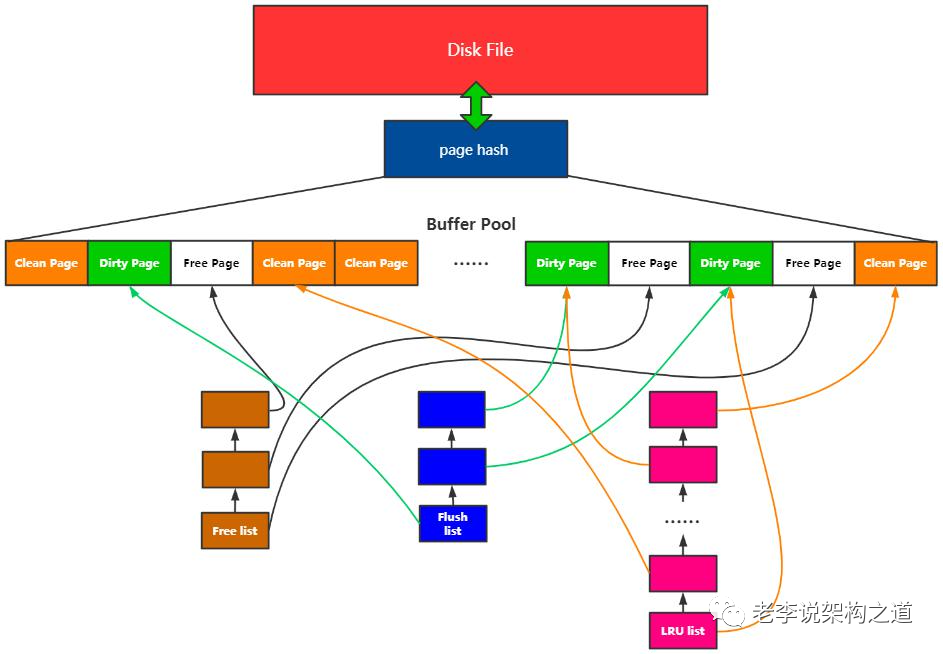
page 從flush_list 上面刷臟以后是不會從lru list 上面刪除, 也就不會釋放, 需要等下一次lru list 刷臟的時候再進行釋放.
所以InnoDB 是完全按照lru list 的順序去獲得free page, 但是不是按照lru list 的順序進行刷臟.
我理解官方單一線程刷flush list 和 lru list 問題是把獲得free page 和刷臟操作放在同一個線程中執行了, 導致在刷臟任務比較重的時候無法獲得free page
buffer pool 對IO 優化很重要的一個作用是寫入聚合, 對一個Page 多次修改合并成一個IO 寫入. 所以對于系統而言保留一定的臟頁率對性能是有收益的.
理論上如果只有不考慮redo log checkpoint 及時推進, 那么最好的推進策略一定是在LRU list 上面一直刷臟, 因為這樣才充分發揮buffer pool IO 聚合以及LRU 策略.
我們提出一個足夠簡單的模型.
如果寫入redo 速度不變, 那么生成page 速度不變, 如果刷臟能力極其快, 那么理論上LRU_scan_depth 的深度設置成用戶每秒最大的page IO 生成能力即可, 那么系統最好的狀態 page dirty pct = (buffer pool size - LRU_scan_depth page) / buffer pool size
進一步添加約束, 刷臟能力不如生成page 速度, 那么隨著用戶的寫入臟頁的百分比肯定最后會100%, 所以這個時候必然需要限制用戶的寫入速度, 使得 page 生成速度 < 刷臟速度, 那么臟頁才可以穩定下來.
在dirty_page_pct < trigger_slow_user_written 的情況下, 不阻止用戶寫入
在dirty_page_pct > trigger_slow_user_written 的情況下, 那么需要阻止用戶寫入了.
trigger_slow_user_written 設置的越低, 那么越早開始阻止用戶的寫入, 那么能夠容忍偶爾用戶寫入峰值的時間越長.
進一步增加flush list 的考慮, 考慮從flush list 上面刷臟其實降低刷臟能力.
比如redo 寫入10MB, 生成page 100MB, 如果修改的是完全不同page, 也就是buffer pool 沒有起到IO 聚合作用, 那么刷flush list 和 lru list 是一樣的, 但是實際因為有可能有些page 是重復修改, 理論上LRU list 上刷臟效率> flush list 刷臟效率.
所以在引入了flush list 以后, 考慮的策略是:
在dirty_page_pct < trigger_flush_list 的情況下, 應該完全從lru list 上面刷臟
在dirty_page_pct > trigger_flush_list 的情況下, 那么優先從flush list 上面刷臟了
在dirty_page_pct > trigger_slow_user_written 的情況下, 那么需要阻止用戶寫入了.
那么增加考慮flush list 以后, 實際刷臟策略是 lru list + flush list, 實際刷臟效率進一步降低, 那么就需要更早的對用戶的寫入進行阻止.
在PolarDB 上, 由于需要考慮ro 節點盡可能可以將parse buffer 讓出, 會觸發rw 節點盡快刷臟, 降低了buffer pool IO聚合作用, 那么會進一步降低了刷臟的效率.
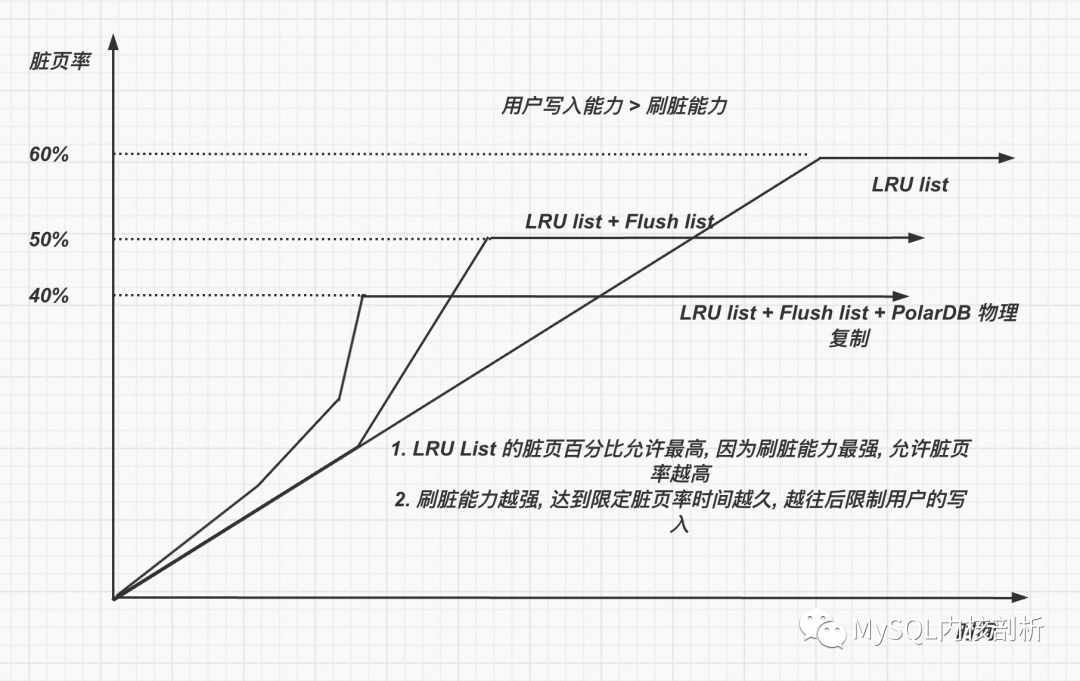
那么這里臟頁率多少合適觸發阻止用戶寫入呢?
觸發trigger_slow_user_writtern 還需要考慮用戶需要使用free page 場景. 如果臟頁百分比特別低, 那么容易在LRU list 上獲得free page, 如果臟頁百分比高, 那么就不容易獲得free page.
在我們上述的模型里面只考慮到了用戶的寫入和刷臟之間的關系, 并沒有考慮到在有一定臟頁比例的情況, 用戶讀取請求如何獲得 free page 的問題.
如果沒有合理實現, 那么用戶請求讀取的時候需要遍歷大量dirty page 才可以找到空閑頁, 影響用戶訪問性能.
另外這里為了找free page 性能, 也不能把dirty_page_pct 設置的過高.
這里的topic 是, 在有一定臟頁的情況下, 如何合理組織page 使得能夠高效獲得free page.
目前InnoDB 的做法是:
分兩種情況:
-
在系統正常運行的過程中, 后臺page cleaner 線程不斷通過 buf_flush_LRU_list_batch() 函數對LRU list 上面old page 進行回收, 添加到free list 里面.
-
在用戶發現free list 沒有free page 以后, 通過buf_LRU_get_free_block() 主動從LRU list 上面獲取free page
還有一個問題: 用戶線程從LRU_list 上獲得free page 需要持有LRU_list_mutex, 但是后臺的page cleaner 線程也同樣需要持有LRU_list_mutex 進行清理操作, 這里就會有一個爭搶.
并且 LRU_list 釋放block 的過程并不是一直持有LRU_list_mutex, 是對于每一個block 而言, 持有LRU_list_mutex, 釋放 mutex, 進行具體的IO 操作, IO操作完又加上LRU_list_mutex.
為什么這樣操作, 而不是一直持有LRU_list_mutex 釋放完指定number block 以后, 再釋放LRU_list_mutex?
這樣的話用戶線程就獲得不到LRU_list_mutex 了, 那么就會導致用戶請求卡主, 但是這里用戶請求大部分是從free list 上面獲得page, 只有free page 上面沒有page 的時候才會從LRU_list 上面去獲得page.
具體代碼 buf_page_free_stale => buf_LRU_free_page() 在進行IO 操作之前, 釋放 LRU_list_mutex, 結束之后退出buf_page_free_stale() 重新加LRU_list_mutex.
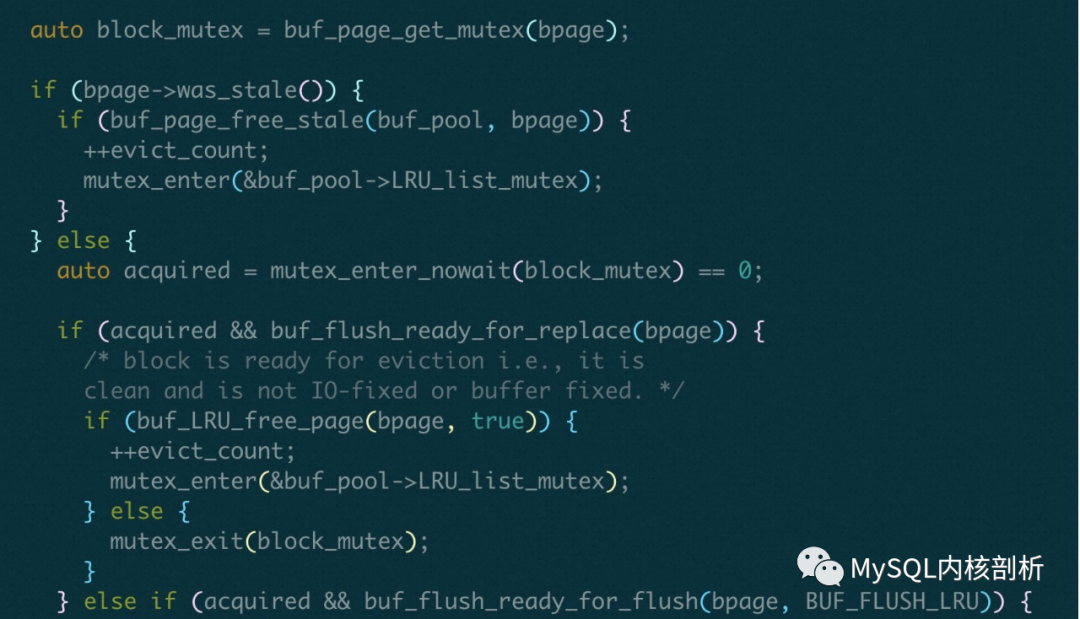
另外, 這里嘗試釋放某一個block 的時候是用mutex_enter_nowait(pthread_mutex_trylock), 不會去等待, 也就是如果某一個page_block 被別人使用, 是不會去釋放這個block 的. 也可以理解, 這個mutex被人持有, 那么大概率這個block 正在使用, 那么可能又是一個新的page 了, 不需要被釋放
1. buf_flush_LRU_list_batch()
后臺對LRU_list 的批量刷臟只會只會掃描 srv_LRU_scan_depth 深度, 在LRU list 末尾 srv_LRU_scan_depth 長度內, 遇到的page 如果是dirty page, 那么就執行 buf_flush_page_and_try_neighbors() 進行刷臟操作, 如果是non-dirty page, 那么就直接踢除就可以.
如果page non-dirty page, 在buf_flush_ready_for_replace() 函數中進行判斷, 然后執行 buf_LRU_free_page() 邏輯
這里判斷一個page 是否能夠被replace, 也就是被釋放的方法
如果這個page 是被寫過, 那么oldest_modification == 0, 表示這個page已經被flush 到磁盤了.
bpage->buf_fix_count 表示的是記錄這個bpage 被引用次數, 每次訪問bpage,都對引用計數buf_fix_count + 1, 釋放的時候 -1. 也就是這個bpage 沒有其他人訪問以后,才可以被replace
并且這個page 的io_fix 狀態是 BUF_IO_NONE, 表示的是page 要從LRU list 中刪除, 在page 用完以后, 都會設置成 BUF_IO_NONE.如果是BUF_IO_READ, BUF_IO_WRITE 表示的是這個page 要從底下文件中讀取或者寫入, 肯定還在使用, 所以不能被replace
如果可以replace, 則執行 buf_LRU_free_page()
如果page 是dirty page, 在 buf_flush_ready_for_flush() 中判斷, 最后執行buf_flush_page() 邏輯.
這個page 的oldest_modification != 0, 表示這個page 肯定已經被修改過了, 并且 io_fix == NONE, 不然這個page 可能正要被read/write
如果可以flush, 則執行 buf_flush_page()
這里掃描LRU list 末尾 srv_LRU_scan_depth長度, 如果末尾的page 都是dirty page, 那么獲取free page 就不夠高效.
2. 具體用戶請求獲得free page 的策略方法在函數 buf_LRU_get_free_block() 中. 具體策略
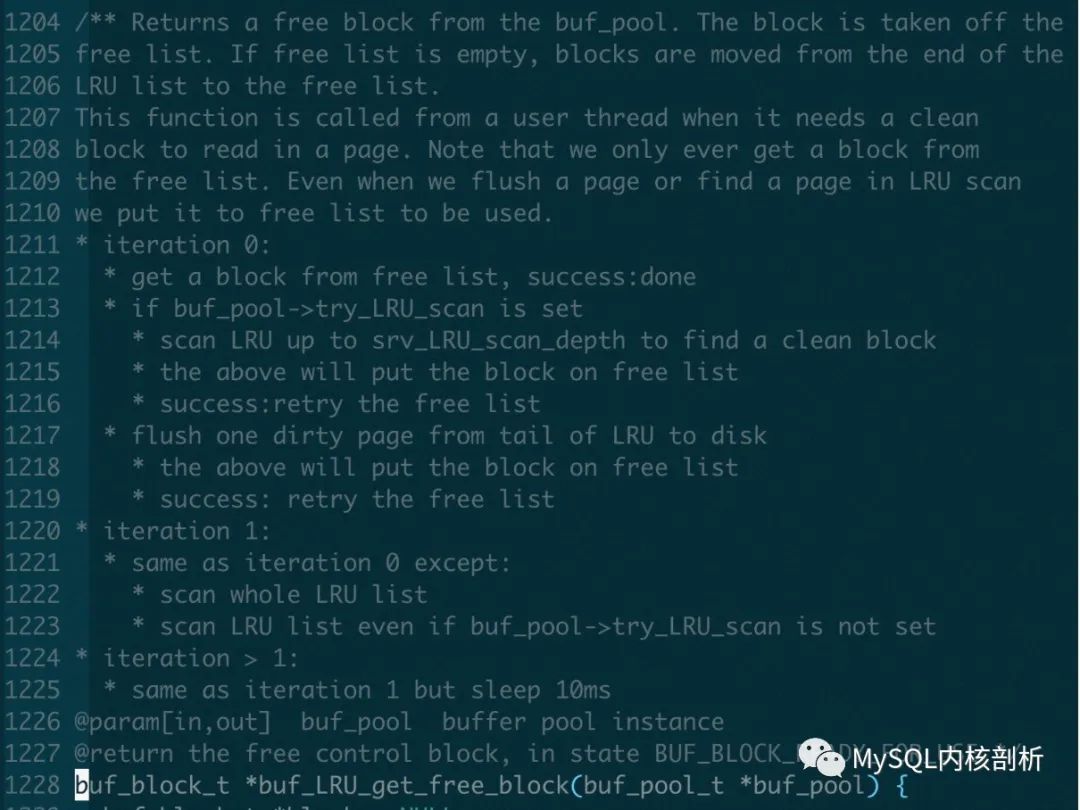
和page cleaner 刷臟區別的地方在于 第2次scan 的時候會掃描整個LRU list 去獲得free page, 在第2次scan 以后, 會sleep 10ms, 并且超過20次以后會打印沒有free page 信息.
為什么不直接從LRU list 上面拿出一個被modify 并且未執行flush 的page 執行flush 呢?
因為在LRU list 上是按照access_time 排序的, 所有有可能page 被修改以后, 又有讀, 因為這個page 被排在了很前面. 但是有可能這個page 很早被修改, 但是一直沒有讀, 反而排在了后面了, 因此從flush_list 里面找page 進行flush 是更靠譜的, 保證flush 的是最早修改過的page
那么什么時候會從flush_list 上面去執行flush page 操作呢?
在系統正常運行的過程中, 就不斷會有page clean 線程對page 執行 flush 操作, 這樣可以觸發用戶從LRU list 里面找page 的時候, 只需要replace 操作, 不需要flush single page 操作, 因為flush single page 操作如果觸發, 對用戶的請求性能影響很大.
所以在page cleaner thread 執行flush 操作以后, 在寫IO 完成以后, 是否會把page 同時從flush_list, LRU list 同時刪除, 還是只是將oldest_modification lsn 設置成0 就可以了?
這里分兩種場景考慮:
-
如果這個page 是從flush_list 上面寫IO 完成, 那么就不需要從flush_list上面刪除, 因為從flush list 上面刪除要完成的操作是刷臟,既然只是為了刷臟, 那么就沒必要讓他從lru list 上面刪除, 有可能這個page 被刷臟了, 還是一個熱page 是需要訪問的
-
如果這個page 是從lru_list 上面寫IO 完成, 那就需要從lru list 上面刪除
原因: 從lru_list 上面刪除的page 肯定說明這個page 不是hot page 了,更大的原因可能是buffer pool 空間不夠, 需要從lru list 上面淘汰一些page了, 既然這些page 是要從lru list 上面淘汰的, 那么肯定就需要從LRU list 上面移除
具體代碼在buf_page_io_complete() 中
Q&A
另外在刷臟里面最大的一個問題是InnoDB 刷臟過程是需要持有page sx lock, 有兩個地方導致可能持有page latch 時間過長
-
進行刷臟的時候有可能page newest_modification lsn 比較大, 那么刷臟的時候需要等redo log 已經寫入到 log_write_up_to 到這個lsn 才可以, 那么加鎖的時間就大大加長了
-
進行刷臟的時候持有latch 的時間是加入到simulated AIO 隊列就算上了, 因此整體持有latch 的時間是 在simulated AIO 上等待的時間 + IO 時間
通過Single Page flush 或者通過用戶Thread wait LRU manager thread 獲得空閑Page區別?
通過Single Page flush 或者通過用戶Thread wait LRU manager thread 獲得空閑Page, 解決的都是在臟頁百分比較高情況下, 獲得free page 的工程上的方法, 只不過Single page flush 在用戶線程比較多的情況下, 非常多個用戶線程去搶占同一個LRU list mutex, 而通過wait LRU manager thread 的方法, 因為thread number 有限, 不會有過多的線程搶占同一個LRU list mutex, 所以在工程上會更好一些.
但是其實用戶用Single Page flush 和引入不引入LRU manager thread 其實是無關的.
審核編輯 :李倩
-
磁盤
+關注
關注
1文章
375瀏覽量
25201 -
模型
+關注
關注
1文章
3226瀏覽量
48809 -
線程
+關注
關注
0文章
504瀏覽量
19675
原文標題:InnoDB page replacement policies
文章出處:【微信號:inf_storage,微信公眾號:數據庫和存儲】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
LRU緩存模塊最佳實踐
Redis的LRU實現和應用
基于修正LRU的壓縮Cache替換策略
關于InnoDB的內存結構及原理詳解
innodb究竟是如何存數據的
MySQL5.6 InnoDB支持全文檢索
剖析MySQL InnoDB存儲原理(下)
什么是list?
設計并實現一個滿足LRU約束的數據結構
redis的lru原理
關于LRU(Least Recently Used)的邏輯實現






 工商網監
工商網監
評論