") Jemalloc 的基本原理
Jemalloc 的基本原理
前言
C++ 語言中提供了大量的類庫和編程接口,雖然可以幫助開發(fā)者提升研發(fā)效率,但在特定場景下,其性能表現(xiàn)仍存在優(yōu)化空間。開發(fā)者往往追求極致的代碼性能邏輯,一點點的優(yōu)化改變就可以幫助業(yè)務(wù)獲得良好的性能收益。在字節(jié)降本提效的過程中,STE 團(tuán)隊在算力監(jiān)控系統(tǒng)中發(fā)現(xiàn) Jemalloc 是業(yè)務(wù)的前五大 CPU 熱點基礎(chǔ)庫,具有很高的潛在性能優(yōu)化空間。因此,從 2019 年開始對 Jemalloc 進(jìn)行深度優(yōu)化,并在字節(jié)內(nèi)部進(jìn)行了大范圍的優(yōu)化落地,幫助業(yè)務(wù)團(tuán)隊取得了較好的收益。本文將主要介紹 Jemalloc 的基本原理以及一些簡單易用的優(yōu)化方法,幫助開發(fā)者在 Jemalloc 的實際應(yīng)用中,獲得更好的性能表現(xiàn)。
內(nèi)存相關(guān)概念簡介
Linux內(nèi)存分配與分配器
當(dāng)代 Linux 系統(tǒng)中可以同時運行多種多樣的進(jìn)程,并且進(jìn)程之間可以做到內(nèi)存互相隔離,這得益于 Linux 的進(jìn)程地址空間管理。
一個進(jìn)程的地址空間中,包含了靜態(tài)內(nèi)存、以及動態(tài)內(nèi)存(常說的堆棧),棧的動態(tài)分配和釋放由編譯器完成,對于堆上內(nèi)存,Linux 提供了 brk、sbrk、mmap、munmap 等系統(tǒng)調(diào)用來進(jìn)行內(nèi)存分配和釋放,但是這些函數(shù)的直接使用會帶來不小的理解門檻和使用復(fù)雜性,如 brk 需要指定堆的上界地址,容易出現(xiàn)內(nèi)存錯誤;mmap 直接申請 pagesize 為單位的內(nèi)存,對于小于此內(nèi)存的分配會造成極大的內(nèi)存浪費。因此需要有內(nèi)存分配器來輔助管理堆的動態(tài)申請和釋放。
通常內(nèi)存分配器如 ptmalloc提供了 malloc 等函數(shù)來進(jìn)行內(nèi)存的分配,free 進(jìn)行內(nèi)存釋放,這些函數(shù)在底層調(diào)用了 brk、mmap 等函數(shù)申請內(nèi)存,并以地址的形式返回給用戶,用戶在 malloc、free 匹配的情況下不必?fù)?dān)心在分配和釋放時出現(xiàn)內(nèi)存錯誤或者內(nèi)存浪費。
內(nèi)存碎片
雖然內(nèi)存分配器在一定程度上保證了內(nèi)存的利用率,但是不可避免地會出現(xiàn)內(nèi)存碎片,包括了內(nèi)存頁內(nèi)碎片和內(nèi)存頁間碎片,碎片的產(chǎn)生會導(dǎo)致部分內(nèi)存不可用,內(nèi)存碎片的大小也是評估一個內(nèi)存分配器好壞的重要指標(biāo)。
常見的內(nèi)存分配管理算法
堆上內(nèi)存以鏈?zhǔn)叫问酱嬖冢詈唵蔚膭討B(tài)內(nèi)存分配算法有:
First fit:尋找找第一個滿足請求 size 的內(nèi)存塊做分配
Next fit:從當(dāng)前分配的地址開始,尋找下一個滿足請求 size 的空閑塊
best fist:對空閑塊進(jìn)行排序,然后找第一個滿足要求的空閑塊
另外還有 Buddy 算法和 Slab 算法,也是 jemalloc 中用到的核心算法:
Buddy allocation

Buddy 算法簡單來說如上圖,一般 2 的 n 次冪大小來管理內(nèi)存,當(dāng)申請的內(nèi)存 size 較小,且當(dāng)前空閑內(nèi)存塊均大于 size 的兩倍,那么會將較大的塊分裂,直到分裂出大于size,并小于 size * 2的塊為止;當(dāng)內(nèi)存 size 較大時則相反,會將空閑塊不斷合并。
Buddy 算法沒有塊間內(nèi)存碎片,但是塊內(nèi)內(nèi)存碎片較大,可以看到當(dāng)申請 2KB+1B 的 size 時,需要用 4KB 的內(nèi)存塊,內(nèi)存碎片最壞情況可達(dá) 50%。
Slab allocation
調(diào)用 Linux 系統(tǒng)調(diào)用進(jìn)行內(nèi)存的分配和釋放會讓程序陷入內(nèi)核態(tài),帶來不小的性能開銷,slab 算法應(yīng)運而生。每個 slab 都是一塊連續(xù)內(nèi)存,并將其劃分成大小相同的 slots,用 bitmap 來記錄這些 slots 的空閑情況,內(nèi)存分配時,返回一個 bitmap 中記錄的空閑塊,釋放時,將其記錄忙碌即可,而 slab size 和 slot size 是內(nèi)存碎片大小的關(guān)鍵。
Jemalloc簡介
Jemalloc 是 malloc(3) 的實現(xiàn),在現(xiàn)代多線程、高并發(fā)的互聯(lián)網(wǎng)應(yīng)用中,有良好的性能表現(xiàn),并提供了優(yōu)秀的內(nèi)存分析功能。
Jemalloc 主要有以下幾個特點:
高效地分配和釋放內(nèi)存,可以有效提升程序的運行速度,并且節(jié)省 CPU 資源
盡量少的內(nèi)存碎片,一個長穩(wěn)運行地程序如果不控制內(nèi)存碎片的產(chǎn)生,那么可以預(yù)見地這個程序會在某一時刻崩潰,限制了程序的運行生命周期
支持堆的 profiling,可以有效地用來分析內(nèi)存問題
支持多樣化的參數(shù),可以針對自身地程序特點來定制運行時 Jemalloc 各個模塊大小,以獲得最優(yōu)的性能和資源占用比
下文主要介紹了 Jemalloc 的內(nèi)存分配算法、數(shù)據(jù)結(jié)構(gòu),以及一些針對具體程序的優(yōu)化實踐和建議。
Jemalloc核心算法與數(shù)據(jù)結(jié)構(gòu)
Jemalloc 整體的算法和數(shù)據(jù)結(jié)構(gòu)基于高效和低內(nèi)存碎片的原則進(jìn)行設(shè)計,主要體現(xiàn)在:
隔離了大 Size 和小 Size 的內(nèi)存分配(區(qū)分默認(rèn)閾值為 3.5 個 Pagesize),可以有效地減少內(nèi)存碎片
在內(nèi)存重用時默認(rèn)使用低地址,并將內(nèi)存控制在盡量少的內(nèi)存頁上
制定 size class 和 slab class,以便減少內(nèi)存碎片
嚴(yán)格限制 Jemalloc 自身的元數(shù)據(jù)大小
用一定數(shù)量的 arena 來管理內(nèi)存的單元,每個 arena 管理相當(dāng)數(shù)量的線程,arena 之間獨立,盡量減少多線程時鎖競爭
我們來看下 Jemalloc 是如何來實現(xiàn)這些特性的。
Extent
Jemalloc 的內(nèi)存管理結(jié)合了 buddy 算法和 slab 算法。Jemalloc 引入 extent 的概念,extent 是 arena 管理的內(nèi)存對象,在 large size 的 allocation 中充當(dāng) buddy 算法中的 chunk,small size allocation 中,充當(dāng) slab。
每個 extent 的大小是 Pagesize 的整數(shù)倍,不同 size 的 extent 會用 buddy 算法來進(jìn)行拆分和合并,大內(nèi)存的分配會直接使用一整個的 extent 來存儲。小內(nèi)存的分配使用的是 slab 算法,slab size 的計算規(guī)則為 size 和 pagesize 的最小公倍數(shù),因此每個extent總是可以存儲整數(shù)倍個對應(yīng) size。
extent 本身設(shè)置 bitmap,來記錄內(nèi)存占用情況,以及自身的各種屬性,同類型的 extents 用 paring heap 存儲。
此外,arena 將 extent 分為多種類型,有當(dāng)前正在使用未被填滿的extent,有一段時間未使用的dirty extent,還有長時間未使用的muzzy extent,以及開啟retained功能后的retained extent,extent分類的作用相當(dāng)于多級緩存,當(dāng)線程內(nèi)存分配壓力較小時,空余的extent會被緩存,以備壓力增大時使用,可以避免與操作系統(tǒng)的交互。
Small size align and Slab size
為了減少頁內(nèi)內(nèi)存碎片,Jemalloc 對 small size 進(jìn)行了對齊,對于每一個 size,以二進(jìn)制的視角來看,將其分為兩個數(shù):group、mod。group 表示 size 的二進(jìn)制最高位,如果 size 正好為 2 的冪次,則將其分在上一個 group 中;mod 表示最高位的后兩位,有 0、1、2、3 共 4 種可能。這樣構(gòu)成的 align 后的 size 在同一個 group 中步長(即兩個相鄰 mod 計算得到的 size 之間的差值)相同,group 越大,步長會呈 2 的倍數(shù)增長。
如下圖,框中的 4個是同一個 group 中 4 種 mod 在 align 后的 size,其中 160 表示包含了 129B 到 160B 在對齊后的大小:
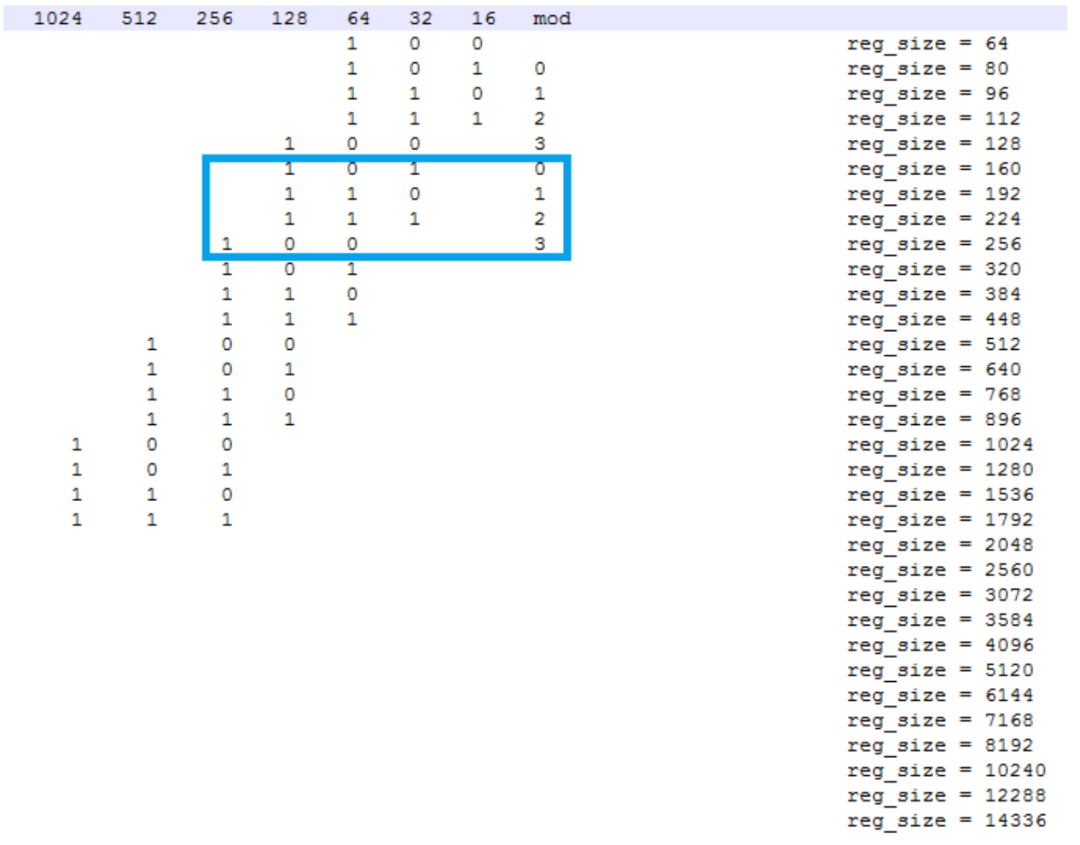
計算出 aligned size 后,就需要計算 slab size,每個 slab size 為 pagesize 和 aligned size 的最小公倍數(shù),以防止跨 slab 的 size 或者 slab 無法被填滿的情況出現(xiàn)。以 4K page 為例,128B 的 slab size 即 4K,160B 的 slab size 為 20K。
Tcache and arena
為了減少多線程下鎖的競爭,Jemalloc 參考 lkmalloc 和 tcmalloc,實現(xiàn)了一套由多個 arena 獨立管理內(nèi)存加 thread cache 的機(jī)制,形成 tcache 有空余空間時不需要加鎖分配,沒有空余空間時將鎖控制在線程所屬 arena 管理的幾個線程之間的模式。
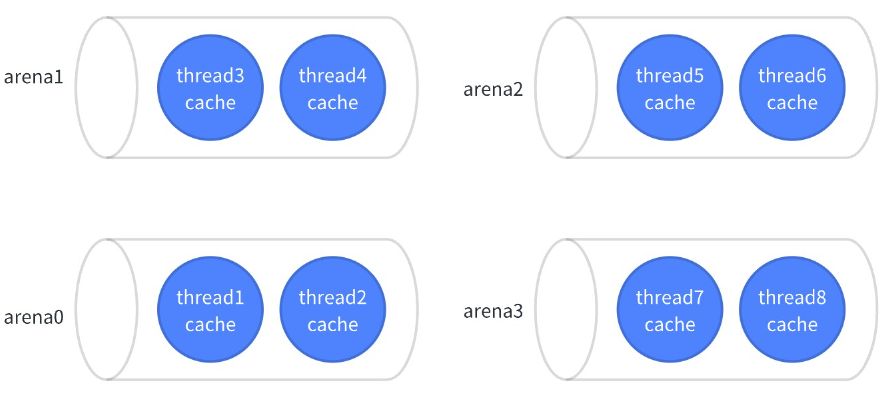
tcache 中每一個 size 對應(yīng)一個 bin,當(dāng) tcache 需要填充時,在 arena 中發(fā)生的如下圖:
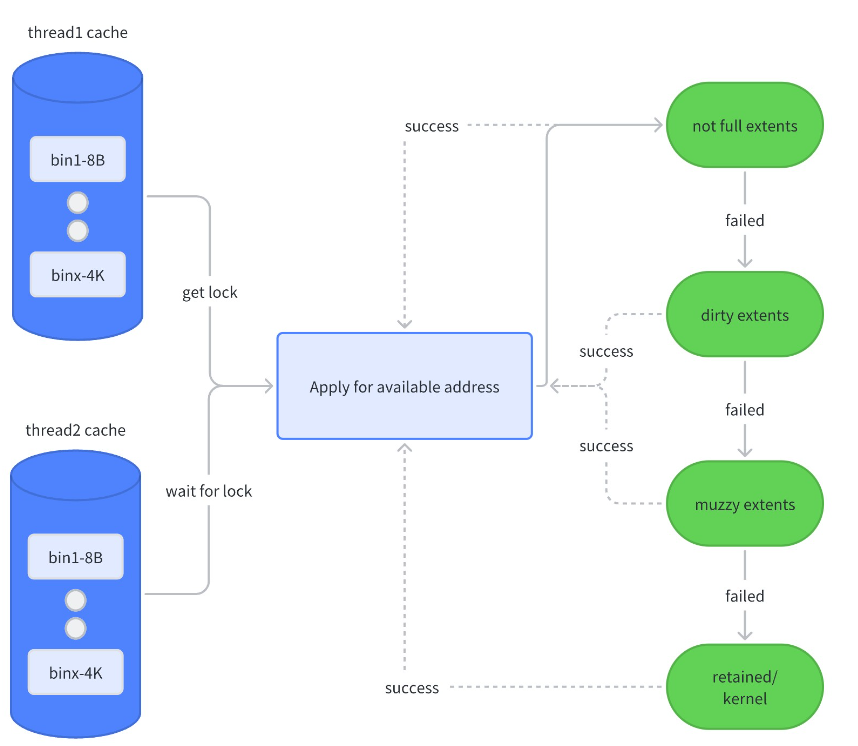
allocation/dallocation in tcache
tcache 以 thread local storage對象的形式存儲,主要服務(wù)于 small size 和一小部分 large size。
當(dāng) tcache 中有空閑時,一次 malloc 的過程很簡單:
對 size 做 align 得到 usize
查找 usize 對應(yīng)的 bin,bin 為 tcache 中針對不同 size 設(shè)置的 slots
bin 有空閑地址則直接返回,沒有空閑地址則會向 arena 請求填充
每個 bin 的結(jié)構(gòu)如下圖,avail 指向 bin 的起始地址,ncached 初始為 bin 的最大值 ncached_max (與 slab size 相關(guān),最小為 20 最大為 200),每次申請內(nèi)存會返回 ncached 指向的地址并自減1,直到小于限制值。
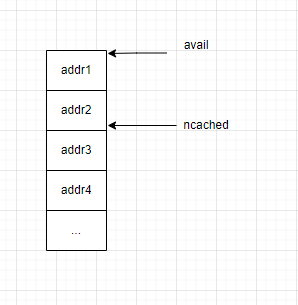
釋放的時候相反,當(dāng) tcache 不為空,即 ncached 不等于 bin 的 ncached_max 時,ncached 自加1,并且將 free 的地址填入 bin 中。
Tcache fill
上面的 allocation 過程是 tcache 中有足夠的空閑塊供分配,當(dāng) tcache 中已經(jīng)沒有空閑塊時,會向其所屬的 arena 申請 fill,此時 arena 中會加鎖去分級 extent 取空閑塊,并把當(dāng)前使用的 extent 移入full extent。
Tcache flush
當(dāng) dallocate 觸發(fā) tcache 中又沒有分配任何內(nèi)存,即 ncached_max 等于 ncached_max 時,tcache 會觸發(fā) flush,flush 會將 tcache 中一半的內(nèi)存釋放回原 extent,即將 tache 的可用空間壓縮到原來的一半,這個過程中也會加對應(yīng) extent 的鎖以保證同步。
Jemalloc優(yōu)化思路
從上一章節(jié)可以看到,jemalloc 對于內(nèi)存用的是多級緩存的思路,tcache 的代價最小,無須加鎖可以直接返回;其次是 arena 的 bin->extent,鎖的粒度在對應(yīng)的 bin 上,會是 bin 對應(yīng)的 size 在這個 arena 中無法再做 fill 或 flush;然后是 dirty extent、muzzy extent,這部分是 arena 全局加鎖,會鎖住其他線程的 fill 或者 purge,那么在多線程下,我們可以用幾個思路來優(yōu)化鎖的競爭。
arena優(yōu)化
從上一章節(jié)可知,jemalloc 將鎖的范圍都控制在 arena 中,每個 arena 會管理一系列線程,線程在 arena 中是平均分配的,arena 默認(rèn)數(shù)量是 CPU 個數(shù) * 4。因此,當(dāng)我們在一臺 8 核的機(jī)器上運行 256 個線程時,意味著每個arena 需要管理 8 個線程,這些線程在內(nèi)存任務(wù)繁重時會產(chǎn)生嚴(yán)重的鎖競爭,從而影響性能。此時可選擇使用 malloc_conf128,增加 arena 數(shù)量到 128 個,每個 arena 只需管理 2 個線程,線程之間產(chǎn)生鎖競爭的概率就會大大減小。
此外還可以選擇用 mallocx 隔離線程,讓內(nèi)存分配任務(wù)較重的線程獨占 arena。
Slab size優(yōu)化
Slab size 的大小如上所述,為 usize 大小和 pagesize 的最小公倍數(shù),這一機(jī)制可以保證減少內(nèi)存碎片,但是tcache 的 fill 與 flush 都與 slab size 相關(guān),一個和業(yè)務(wù)內(nèi)存模型匹配的 slab class 才可以得到最好的性能效果。
下面是一張 jemalloc 和 ptmalloc 的對比圖,可以看到在 1024 以下的性能 jemalloc 都優(yōu)于 ptmalloc,但是jemalloc 自身的性能明顯存在波動,幾個波動出現(xiàn)在 128B、256B、512B 以及 1024B 周圍,因為這些 size 本身就是 pagesize 的因子或者公因子較多,所以 slab size 占用的 page 數(shù)也相對較少,fill 和 flush 所需要的slab數(shù)也越多。
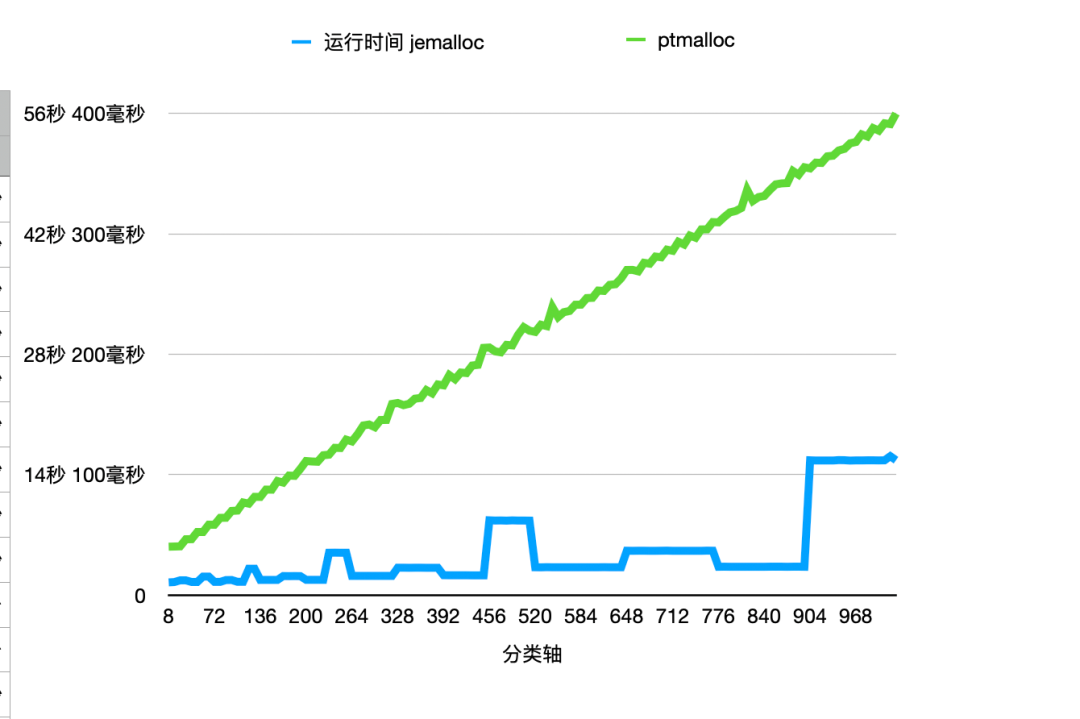
dirty decay & muzzy decay
盡管我們希望將所有的 malloc、free 內(nèi)存都可以放在 tcache 中或者 bin 中,這樣可以最大化執(zhí)行效率,但是實際的程序中這很難做到,因為每個線程都需要增加內(nèi)存,會造成不小的內(nèi)存壓力,而且內(nèi)存的申請釋放往往會有波峰,dirty extents 和 muzzy extents 就可以來應(yīng)對這些內(nèi)存申請的波峰,而避免需要轉(zhuǎn)入內(nèi)核態(tài)來重新申請內(nèi)存頁。
dirty_decay_ms 和 muzzy_decay_ms 是 jemalloc 中用來控制長時間空閑內(nèi)存衰變的時間參數(shù),適當(dāng)?shù)財U(kuò)大 dirty decay 的時間可以有效地解決性能劣化的尖刺。
Tcache ncached_max
tcache 中每一個 bin 的 slots 數(shù)量由 ncached_max 決定,當(dāng) tcache 中 ncached_max 耗盡時會觸發(fā) arena 的 fill tcache 而產(chǎn)生鎖,而 ncached_max 的大小默認(rèn)為 2 * slab size,最小為 20,最大為 200,適當(dāng)?shù)財U(kuò)大 ncached_max 值可以在一些線程上形成更優(yōu)的 allocation/deallocation 循環(huán)(5.3版本已支持用malloc_conf進(jìn)行更改)。
優(yōu)化方法:調(diào)優(yōu)三板斧
結(jié)合以上優(yōu)化思路,通過以下步驟對應(yīng)用進(jìn)行調(diào)優(yōu):
Dump stats
在 long exist 的程序中可調(diào)用 jemalloc 的 malloc_stats_print 函數(shù),dump 出應(yīng)用當(dāng)前內(nèi)存分配信息:
// reference: https://jemalloc.net/jemalloc.3.html
void malloc_stats_print(void (*write_cb)(void *, const char *), // 回調(diào)函數(shù),可以寫入文件
void *cbopaque, // 回調(diào)函數(shù)參數(shù)
const char *opts); // stats的一些選項,如"J"是導(dǎo)出json格式
或通過設(shè)置 malloc_conf,在程序運行結(jié)束后自動 dump stats:
export MALLOC_CONF=stats_print:truestats 分析
用 Json 格式 dump stats 后,可以得到如下圖所示結(jié)構(gòu)的 json 文件:
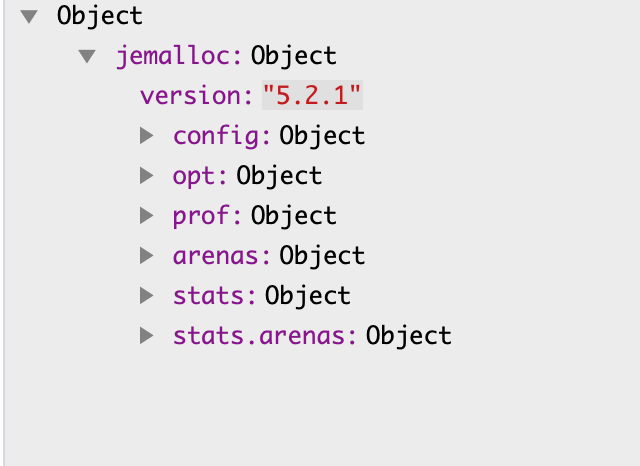
各字段含義可參考:
https://jemalloc.net/jemalloc.3.html
按上一章節(jié)思路,可主要關(guān)注以下幾點: (1)arena 數(shù)量與 threads 數(shù)量比例
arena 數(shù):jemalloc->arenas->narenas
threads 數(shù):jemalloc->stats.arenas->merged->nthreads
分析:
threads : arenas 比例代表了單個 arena 中管理的線程數(shù),將 malloc、free 較多,并且有可能產(chǎn)生競爭的線程盡量獨占 arena。
(2)各個 extent 中 mutex 開銷
jemalloc->stats.arenas->merged->mutexes
分析:
該節(jié)點中的 mutex 操作次數(shù)、等鎖時間可以反映出該類型 extent 的鎖競爭程度,若 extent_retained 鎖競爭嚴(yán)重,可適當(dāng)調(diào)大 muzzy_decay_ms;同理,當(dāng) extents_muzzy 鎖競爭嚴(yán)重,可適當(dāng)調(diào)大 diry_decay_ms;extents_dirty 鎖競爭嚴(yán)重,可適當(dāng)調(diào)大 ncached_max,讓malloc 盡量可以在 tcache 中完成
(3)arena 中各個 bin 的 malloc、free 次數(shù)
jemalloc->stats.arenas->merged->bins
分析:
bin 中的 nfills 可以反映該 slab 填充的次數(shù),針對 regions 本身較少,nfill 次數(shù)又多的 size,如 521B、1024B、2048B、4096B 等,可適當(dāng)調(diào)大 slab size 來減小開銷
添加MALLOC_CONF參數(shù)或修改代碼
MALLOC_CONF 是 jemalloc 中用來動態(tài)設(shè)置參數(shù)的途徑,無須重新編譯二進(jìn)制,可以通過 MALLOC_CONF 環(huán)境變量或者 /etc/malloc_conf 軟鏈接形式設(shè)置,參數(shù)之間用 ',' 分割。除需要使用線程獨占的 arena 外,以上其他優(yōu)化均可通過 MALLOC_CONF 配置來完成。
(1)arena優(yōu)化方法 narenas 設(shè)置:
export MALLOC_CONF=narenas:xxx # xxx最大為1024
或
ln -s "narenas:xxx" /etc/malloc_conf
設(shè)置線程獨占的 arena:
unsigned thread_set_je_exclusive_arena() {
unsigned arena_old, arena_new;
size_t sz = sizeof(unsigned);
/* Bind to a manual arena. */
if (mallctl("arenas.create", &arena_new, &sz, NULL, 0)) {
std::cout << "Jemalloc arena create error
";
return 0;
}
if (mallctl("thread.arena", &arena_old, &sz, &arena_new, sizeof(arena_new))) {
std::cout << "Thread bind to jemalloc arena error
";
return 0;
}
return arena_new;
}
(2)各類大小優(yōu)化方法
dirty extents:
export MALLOC_CONF=dirty_decay_ms:xxx # -1為不釋放dirty extents,易發(fā)生OOM
muzzy extents:
export MALLOC_CONF=muzzy_decay_ms:xxx # -1為不釋放muzzy extents,易發(fā)生OOM
tcache ncached_max 調(diào)整,ncached_max 與 slab size 相關(guān),計算方式為
(slab_size / region_size) << lg_tcache_nslots_mul (默認(rèn)值1)最大限值為 tcache_nslots_small_max(默認(rèn)200),最小限值為 tcache_nslots_small_min(默認(rèn)20)。
如調(diào)整 32B 的 ncached_max,當(dāng)前系統(tǒng) page size 為 4K,計算默認(rèn)的 ncached_max 的方法:
(slab_size / region_size) << lg_tcache_nslots_mul = (4096 / 32) << 1 = 256超過了 tcache_nslots_small_max,所以 32B 的 ncache_max 默認(rèn)即為 200。
調(diào)整 ncached_max 默認(rèn)值相關(guān)參數(shù):
export MALLOC_CONF=tcache_nslots_small_min:xxx,tcache_nslots_small_max:xxx,lg_tcache_nslots_mul:xxx
Slab size 設(shè)置方法:
export MALLOC_CONF="slab_sizes17|100-200:1|128-128:2" # -左右表示size范圍,:后設(shè)置page數(shù),|分割各個不同的size范圍
字節(jié)業(yè)務(wù)優(yōu)化案例
Jemalloc 的 stats dump 已經(jīng)集成到監(jiān)控系統(tǒng)中,經(jīng)過分析發(fā)現(xiàn),字節(jié)內(nèi)部的應(yīng)用普遍線程數(shù)量較多,在 arena 中的鎖競爭比較激烈,并且 allocte/deallocte 集中在某些線程中,因此可以通過讓核心線程獨占 arena 來完成優(yōu)化。以其中一個業(yè)務(wù)在平臺上的 stats 數(shù)據(jù)為例:
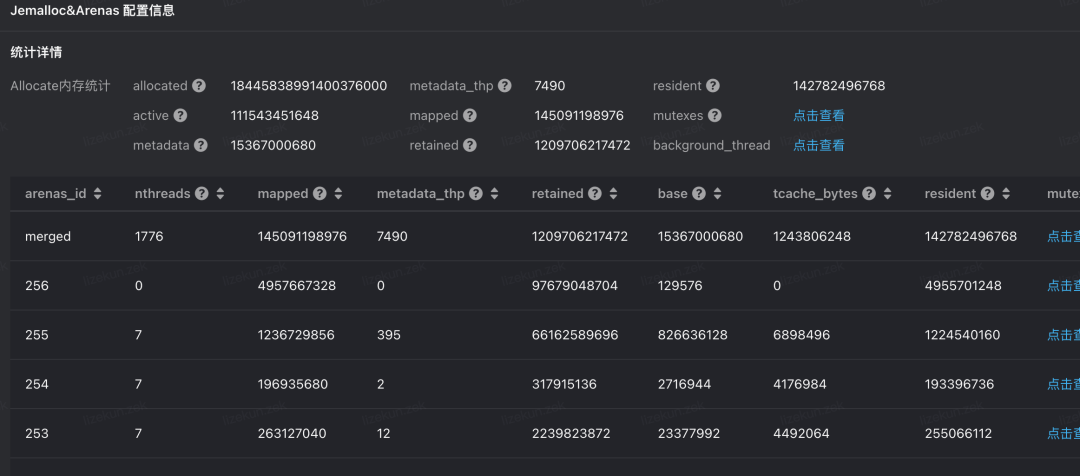 可以看到進(jìn)程總線程數(shù)為 1776 個,arenas 數(shù)量為 256 個,平均每個 arena 中的內(nèi)存需要有 7-8 個線程共享,再查看 mutexs 的 stats :
可以看到進(jìn)程總線程數(shù)為 1776 個,arenas 數(shù)量為 256 個,平均每個 arena 中的內(nèi)存需要有 7-8 個線程共享,再查看 mutexs 的 stats : 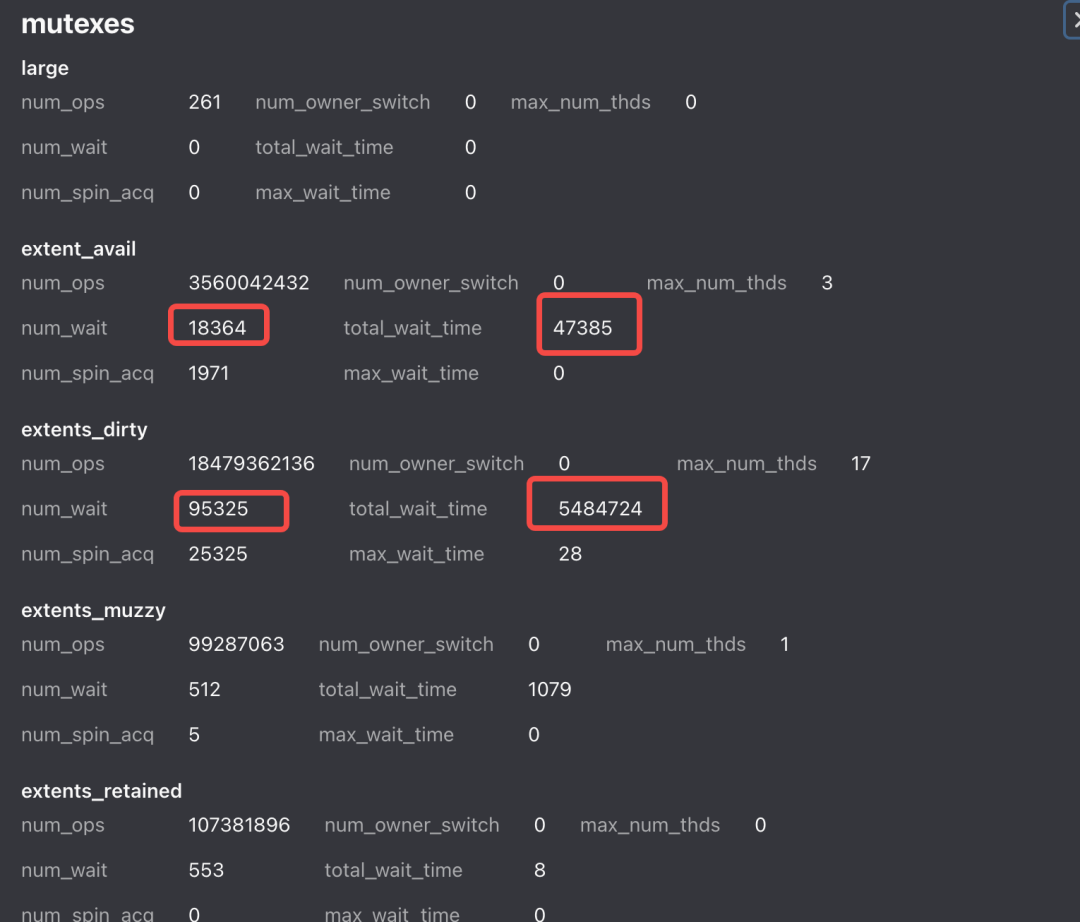
可以看到在 extents 中產(chǎn)生鎖的開銷并不小,首先選擇擴(kuò)大 arenas 的數(shù)量,從 256 擴(kuò)大到 1024 個,發(fā)現(xiàn) CPU 相對下降了 4.5%,但是相對的內(nèi)存上漲了 10%,在分析代碼后,發(fā)現(xiàn) allocate/deallocate 較多的線程總數(shù)量只有80+,針對這些線程通過 mallctl 單獨創(chuàng)建了 arena,并綁定 tcache,并調(diào)小其他線程的 muzzy_decay_ms,最終為該業(yè)務(wù)節(jié)省了 4% 的 CPU 收益,內(nèi)存基本持平。
總結(jié)
最好的基礎(chǔ)庫總是通用的,最適合的基礎(chǔ)庫總是最個性化的。對于 jemalloc 在業(yè)務(wù)上的優(yōu)化與實踐,STE團(tuán)隊進(jìn)行不斷探索,采集內(nèi)存信息并進(jìn)行平臺化展示,以便業(yè)務(wù)及時發(fā)現(xiàn)自身程序在 jemalloc 上的性能瓶頸,并做出針對性地調(diào)優(yōu),目前已在 10+ 業(yè)務(wù)上進(jìn)行參數(shù)優(yōu)化,平均幫助各業(yè)務(wù)團(tuán)隊節(jié)省了 3% 的 CPU(jemalloc 在部分業(yè)務(wù)中平均占用 10% ~ 15% 的CPU)。未來 STE 團(tuán)隊將繼續(xù)深入 jemalloc 性能優(yōu)化,探索定制化的業(yè)務(wù)內(nèi)存分配和管理方案,以獲得更好的優(yōu)化成果。
-
接口
+關(guān)注
關(guān)注
33文章
8626瀏覽量
151351 -
C++
+關(guān)注
關(guān)注
22文章
2110瀏覽量
73697 -
malloc
+關(guān)注
關(guān)注
0文章
52瀏覽量
73
原文標(biāo)題:Jemalloc內(nèi)存分配與優(yōu)化實踐
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論