 State of GPT:大神Andrej揭秘OpenAI大模型原理和訓練過程
State of GPT:大神Andrej揭秘OpenAI大模型原理和訓練過程
前言
OpenAI的創始人之一,大神Andrej Karpthy剛在微軟Build 2023開發者大會上做了專題演講:State of GPT(GPT的現狀)。
在這個樸實無華的題目之下,Andrej帶來的是一場超級精彩的分享。
他詳細介紹了如何從GPT基礎模型一直訓練出ChatGPT這樣的助手模型(assistant model)。作者不曾在其他公開視頻里看過類似的內容,這或許是OpenAI官方第一次詳細闡述其大模型內部原理和RLHF訓練細節。
難能可貴的是,Andrej不僅深入了細節, 還高屋建瓴的抽象了大模型實現中的諸多概念,牛人的洞察就是不一樣。
比如,Andrej非常形象的把當前LLM大語言模型比喻為人類思考模式的系統一(快系統),這是相對于反應慢但具有更長線推理的系統二(慢系統)而言。這只是演講里諸多閃光點的其中一個。
并且,Andrej真的有當導師的潛力,把非常技術的內容講得深入淺出,而又異常透徹。這個演講完全可以讓非專業人士也能理解,并且,認真看完演講后會有一種醍醐灌頂的感覺。
這場主題演講是如此精彩,以至于作者認為,所有關心LLM大語言模型的人都不容錯過。所以,在制作視頻之余,特以此文整理,和大家分享。
此外,在本文最后還有一些拓展閱讀,同樣非常推薦,有興趣的讀者可以自取。
本次演講的精校完整中文版視頻的B站傳送門:
https://www.bilibili.com/video/BV1ts4y1T7UH
(視頻號莫名不讓分享這個視頻,大家移步b站吧)
(演講全文)
大家好。
我很高興在這里向您介紹 GPT 的狀態,更廣泛地介紹大型語言模型快速發展的生態系統。
我想把演講分成兩部分:
在第一部分我想告訴你我們是如何訓練 GPT 助手的;
然后在第二部分中,我們將了解如何將這些助手有效地用于您的應用程序。

首先讓我們看一下如何訓練這些助手的新興秘訣,并記住這一切都是非常新的,并且仍在迅速發展。
但到目前為止,食譜看起來像這樣。這是一張有點復雜的幻燈片,我將逐一介紹它。

粗略地說,我們有四個主要階段:預訓練、有監督微調、獎勵建模、強化學習,依次類推。
現在在每個階段我們都有一個數據集來支持。我們有一個算法,我們在不同階段的目的,將成為訓練神經網絡的目標。然后我們有一個結果模型,然后在上圖底部有一些注釋。
Pretraining 預訓練
我們要開始的第一個階段是預訓練階段。

這個階段在這個圖中有點特殊:這個圖沒有按比例縮放,這個階段實際上是所有計算工作基本上發生的地方,相當于訓練計算時間的 99%。
因此,這就是我們在超級計算機中使用數千個 GPU 以及可能進行數月的訓練來處理互聯網規模數據集的地方。
其他三個階段是微調階段,更多地遵循少量 GPU 和數小時或數天的路線。
那么讓我們來看看實現基礎模型的預訓練階段。
首先,我們要收集大量數據。這是我們稱之為數據混合的示例,該示例來自 Meta 發布的這篇論文,他們發布了這個 Llama 基礎模型。

可以大致看到進入這些集合的數據集的種類,我們有common crawl這只是一個網絡爬取,C4也是common crawl,然后還有一些高質量的數據集。例如,GitHub、維基百科、書籍、ArXiv論文存檔、StackExchange問答網站等。這些都混合在一起,然后根據給定的比例進行采樣,形成 GPT 神經網絡的訓練集。
現在,在我們實際訓練這些數據之前,我們需要再經過一個預處理步驟,即標記化(tokenization)。

這基本上是將我們從互聯網上抓取的原始文本翻譯成整數序列,因為這是 GPT 運行的原生表示。
標記化是文本片段和標記與整數之間的一種無損轉換,這個階段有許多算法。通常您可以使用諸如字節編碼之類的東西,它迭代地合并小文本塊并將它們分組為標記。
在這里我展示了這些標記的一些示例塊,然后這是將實際饋入Transformer的原始整數序列。
現在我在這里展示了兩個類似的例子,用于控制這個階段的超參數。
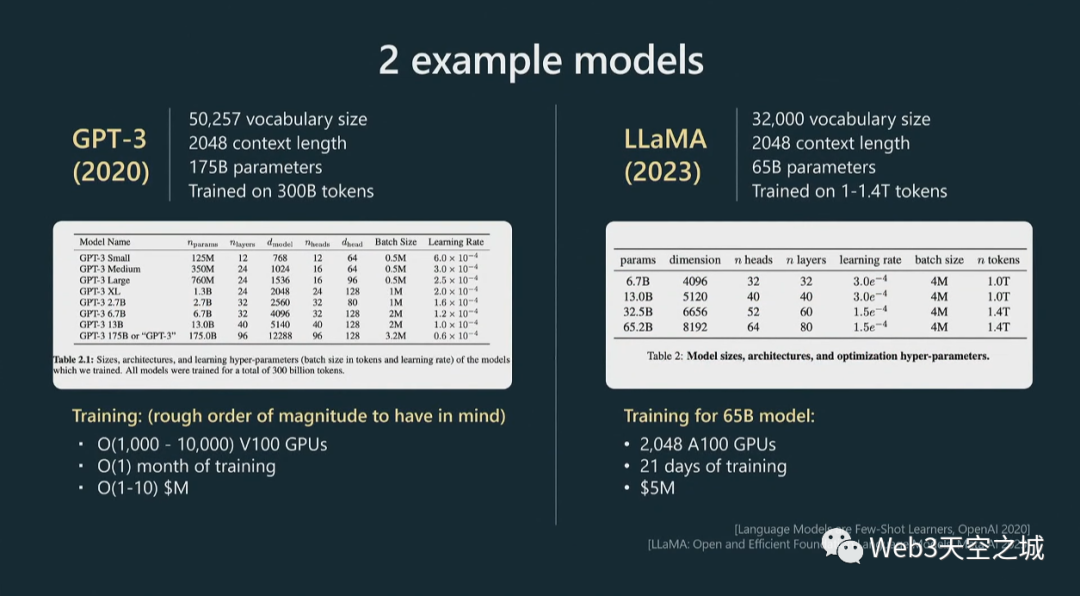
GPT4,我們沒有發布太多關于它是如何訓練的信息,所以我使用 GPT3 的數字;GPT3 現在有點老了,大約三年前。但是Llama是 Meta 的一個相當新的模型。
這些大致是我們在進行預訓練時要處理的數量級:詞匯量通常是幾萬個標記。上下文長度通常是 2,000、4,000,現在甚至是 100,000,這決定了 GPT 在嘗試預測序列中的下一個整數時將查看的最大整數數。
你可以看到,Llama 的參數數量大概是 650 億。現在,盡管與 GPT3 的 1750 億個參數相比,Llama 只有 65 個 B 參數,但 Llama 是一個明顯更強大的模型,直觀地說,這是因為該模型的訓練時間明顯更長,訓練了1.4 萬億標記而不是 3000 億標記。所以你不應該僅僅通過模型包含的參數數量來判斷模型的能力。
這里我展示了一些粗略的超參數表,這些超參數通常用于指定 Transformer 神經網絡。比如頭的數量,尺寸大小,層數等等。
在底部,我展示了一些訓練超參數。例如,為了訓練 65 B 模型,Meta 使用了 2,000 個 GPU,大約訓練了 21 天,大約花費了數百萬美元。
這是您在預訓練階段應該記住的粗略數量級。
現在,當我們實際進行預訓練時,會發生什么?
一般來說,我們將獲取我們的標記并將它們放入數據批次中。

我們有這些數組將饋入Transformer,這些數組是 B,批量大小,這些都是按行堆疊的獨立示例,B 乘以 T,T 是最大上下文長度。在我的這個圖里,長度只有十個,實際工作里這可能是 2,000、4,000 等等。這些是非常長的行。
我們所做的是獲取這些文檔并將它們打包成行,然后用這些特殊的文本結束標記將它們分隔開,基本上是為了告訴Transformer新文檔從哪里開始。
這里我有幾個文檔示例,然后將它們擴展到這個輸入中。現在,將把所有這些數字輸入到 Transformer 中。
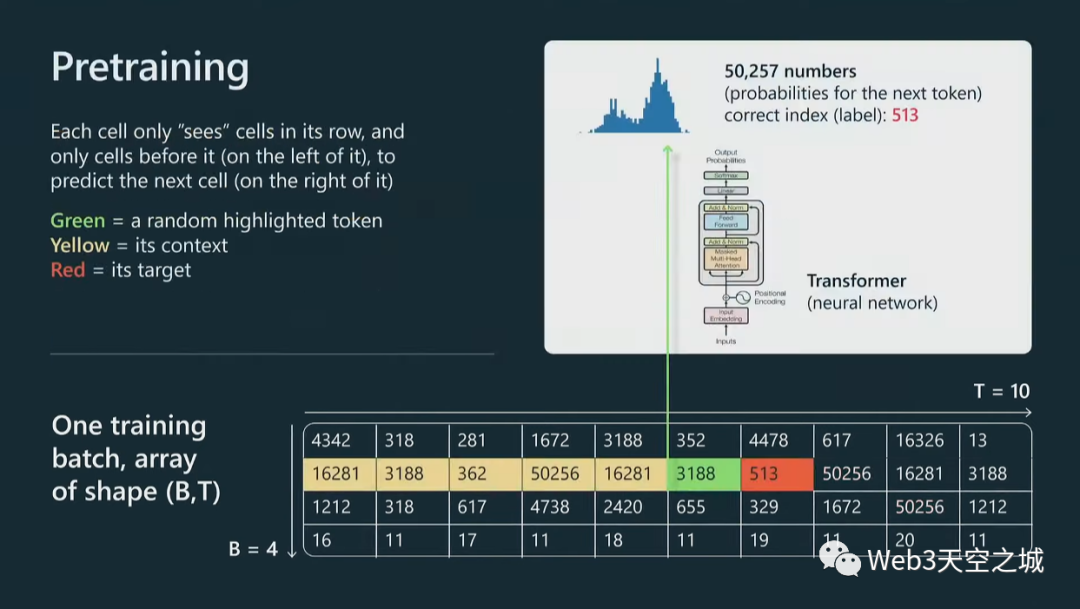
我們只關注一個特定的單元格,但同樣的事情會發生在這個圖中的每個單元格上。
讓我們看看綠色單元格。綠色單元會查看它之前的所有標記,所有標記都是黃色的,我們將把整個上下文輸入到 Transformer 神經網絡中,Transformer 將嘗試預測 序列中的下一個標記,在本例中為紅色。
不幸的是,我現在沒有太多時間來詳細介紹Transformer這個神經網絡架構。(注:特別棒和巧的,Andrej做過一次斯坦福課程,專門深入講解了Transformer神經網絡架構,同樣非常推薦,中文版視頻附在本文結尾)
對于我們的目的來說,Transformer只是一大堆神經網絡的東西,通常有幾百億個參數,或者類似的東西。當然,當您調整這些參數時,您會得到這些單元格中的每一個單元格的預測分布略有不同。
例如,如果我們的詞匯表大小是 50,257 個標記,那么我們將擁有那么多數字,因為我們需要為接下來發生的事情指定概率分布。基本上,我們有可能發生任何事情。
現在,在這個特定的例子中,對于這個特定的單元格,513 將是下一個標記,因此我們可以將其用作監督源來更新Transformer的權重。將同樣的做法應用于并行中的每個單元格,并且不斷交換批次,并且試圖讓Transformer對序列中接下來出現的標記做出正確的預測。
讓我更具體地向您展示當您訓練其中一個模型時的情況。
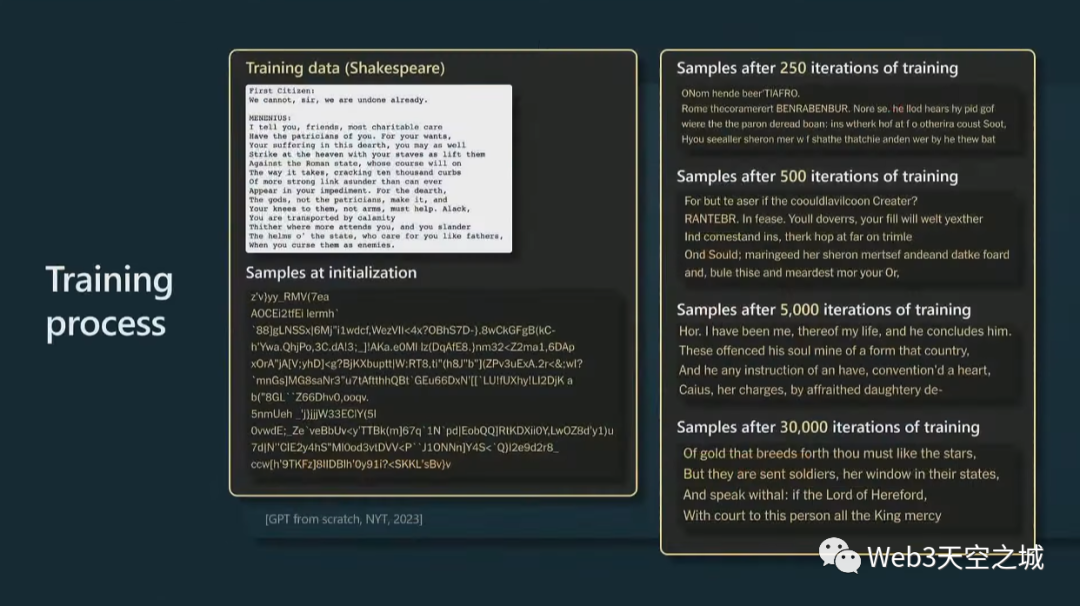
這實際上來自紐約時報,他們在莎士比亞上訓練了一個小的 GPT,這是莎士比亞的一小段,他們在上面訓練了一個 GPT。
一開始,在初始化時,GPT 以完全隨機的權重開始,因此也將獲得完全隨機的輸出。但是,隨著時間的推移,當訓練 GPT 的時間越來越長時,我們會從模型中獲得越來越連貫和一致的樣本。
當然,你從中抽樣的方式是預測接下來會發生什么,你從那個分布中抽樣,然后不斷將其反饋到過程中,基本上就是對大序列進行抽樣。到最后,你會看到 Transformer 已經學會了單詞,以及在哪里放置空格,在哪里放置逗號等等。
隨著時間的推移,模型正在做出越來越一致的預測。
然后以下這些,是您在進行模型預訓練時會查看的圖類型。
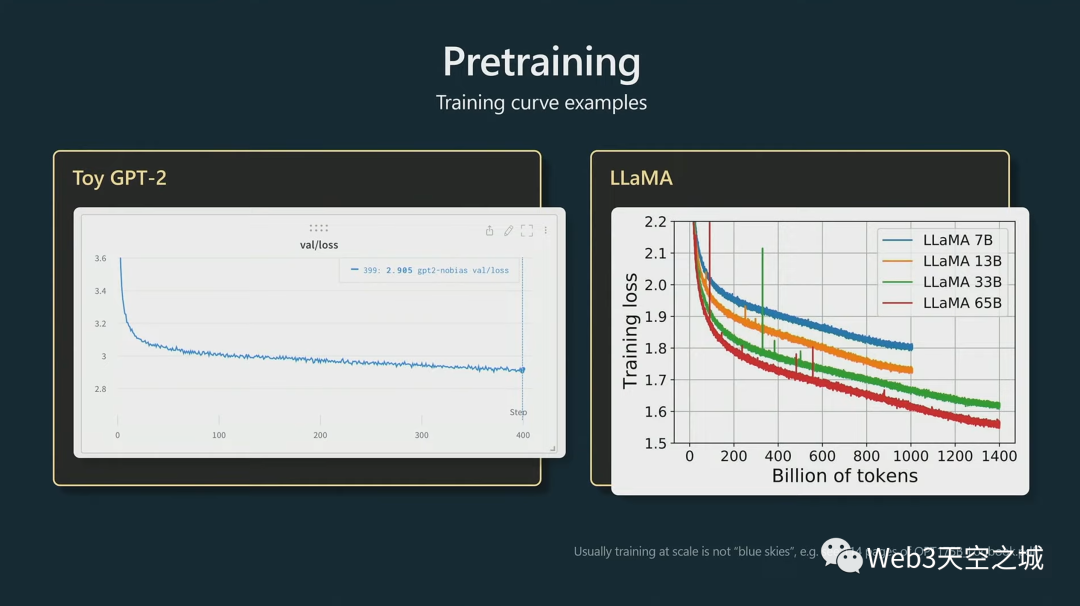
實際上,我們在訓練時查看隨時間變化的損失函數,低損失意味著我們的Transformer正在預測正確 - 為序列中正確的下一個整數提供更高的概率。
訓練一個月后,我們將如何處理這個模型?
我們注意到的第一件事,在這個領域,這些模型基本上在語言建模過程中學習了非常強大的通用表示,并且可以非常有效地微調它們以用于您可能感興趣的任何下游任務 。
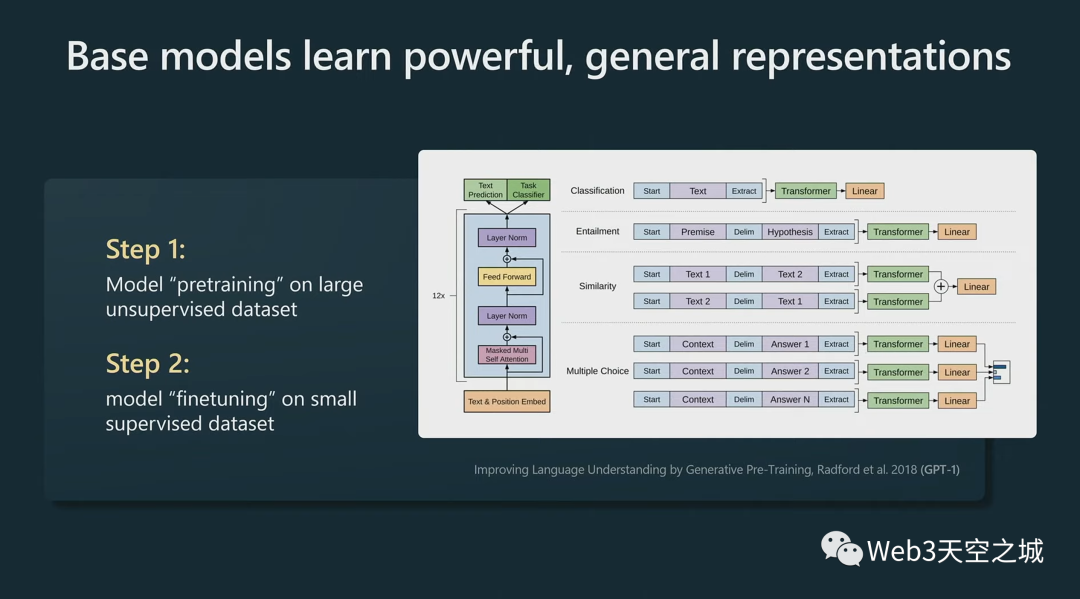
舉個例子,如果對情感分類感興趣,過去的方法是收集一堆正面和負面的信息,然后為此訓練某種 NLP 模型,
但新方法是忽略情感分類,直接去進行大型語言模型預訓練,訓練大型Transformer,然后你可能只有幾個例子,已經可以非常有效地為該任務微調你的模型。
這在實踐中非常有效。
這樣做的原因基本上是 Transformer 被迫在語言建模任務中同時處理大量任務,因為就預測下一個標記而言,它被迫了解很多關于文本的結構和其中所有不同的概念。這就是 GPT-1。
在 GPT-2 前后,人們注意到比微調更好的是,你可以非常有效地提示(prompt)這些模型。
這些是語言模型,它們想要完成文檔,所以你可以通過排列這些假文檔來欺騙它們執行任務。

在這個例子中,例如,我們有一些段落,然后我們做 QA(問和答),QA,QA,幾次提示,然后我們做 Q,然后,當 Transformer 試圖完成文檔時,它實際上是在回答我們的問題。
這就是一個提示工程(prompt engineering)基礎模型的示例,通過提示工程讓模型相信它正在模仿文檔并讓它執行特定的任務。
這開啟了提示高于微調(prompt over finetuning)的時代。我們看到,即使沒有對任何神經網絡進行微調,它也可以在很多問題上非常有效。
從那時起,我們就看到了每個人都知道的,基礎模型的完整進化樹:
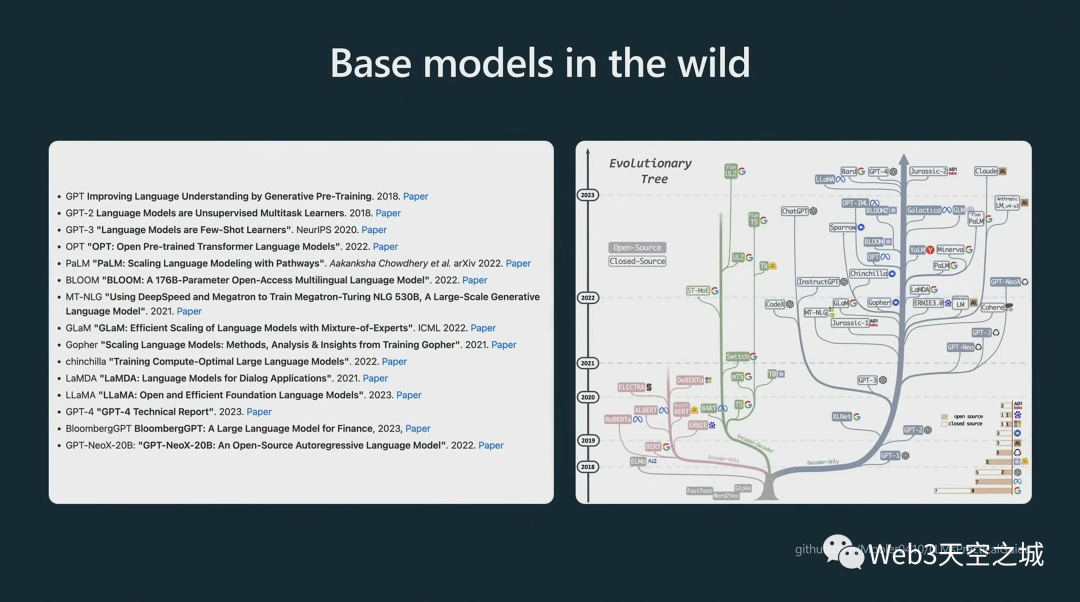
并非所有這些模型型號都可用。
例如,GPT-4 基礎模型從未發布。您可能通過 API 與之交互的 GPT-4 模型不是基礎模型,而是輔助模型,我們稍后將介紹如何獲取這些模型;
GPT-3 基礎模型可通過名為 DaVinci 的 API 獲得;
GPT-2 基礎模型可在我們的 GitHub 存儲庫上作為權重獲得;
目前最好的(可以公開獲得的)基礎模型是 Meta 的 Llama 系列,盡管它沒有商業許可。
需要指出的一件事是,基礎模型不是助手(assistant,即類似ChatGPT的問答助手),它們不想回答你的問題,它們只是想完成文件(笑)。

所以如果你告訴基礎模型:“寫一首關于面包和奶酪的詩”,它會用更多的問題來回答問題。它只是在完成它認為是文檔的內容。
但是,您可以在基礎模型里以特定方式提示以更可能得到結果。例如,“這是一首關于面包和奶酪的詩“。在這種情況下,它將正確地自動完成。
你甚至可以欺騙基礎模型成為助手,你這樣做的方法是創建一個特定的小提示,讓它看起來像是人和助手之間有一份文件,他們正在交換信息。
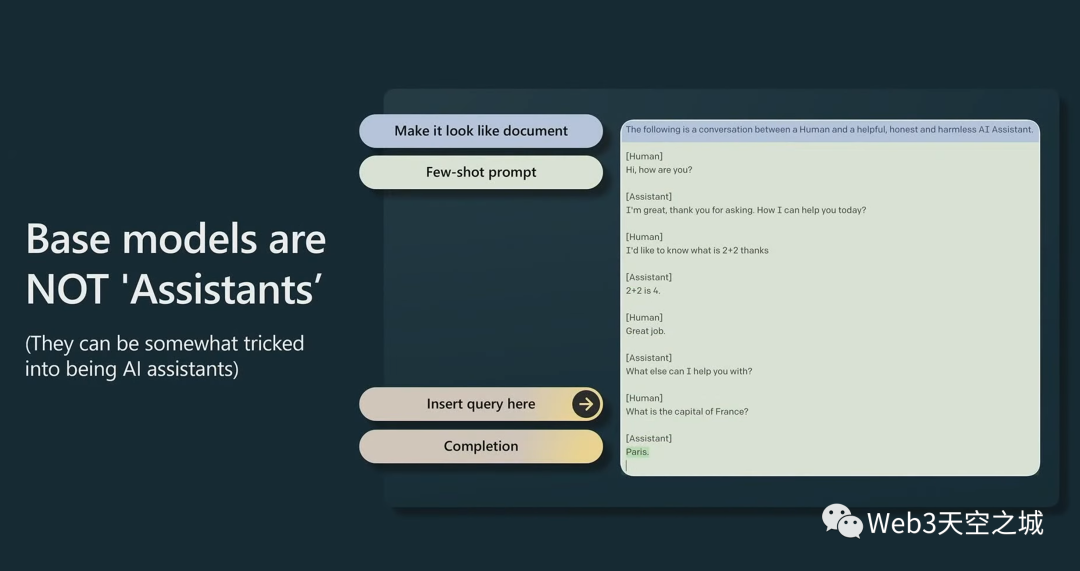
然后,在底部,您將查詢放在最后,基礎模型將自我調整為有用的助手和某種答案(生成這種形式的文檔)。
這不是很可靠,在實踐中也不是很好,盡管它可以做到。
Supervised Finetuning 監督微調
相反,我們有不同的途徑來制作實際的 GPT 助手(GPT Assistant),而不僅僅是基礎模型文檔完成器。
這將我們帶入有監督的微調。

在有監督的微調階段,我們將收集少量但高質量的數據集。在這種情況下,我們要求人工承包商收集及時和理想響應形式的數據。
我們收集很多這樣的東西,通常是類似數萬個這種數量。然后我們仍將對這些數據進行語言建模,因此算法上沒有任何改變。
我們只是換出一個訓練集。它曾經是互聯網文檔,那是一種量很大但質量不高的數據,我們換成用QA即時響應的數據。那是低數量但高質量的。
我們還是做語言建模,然后,訓練之后,我們得到一個SFT(Supervised Finetuning 監督微調)模型。
你可以實際部署這些模型,它們是實際的助手,它們在一定程度上起作用。
讓我向您展示示例演示的樣子。這里有一個人類承包商可能會想出的東西,這是一個隨機的演示:

你寫了一篇關于壟斷一詞的相關性的簡短介紹,或者類似的東西,然后承包商也寫下了一個理想的回應。當他們寫下這些回復時,他們遵循大量的標簽文檔,并且要求他們生成提供幫助、真實且無害的回答。
這是這里的標簽說明。
你可能看不懂,我也看不懂,它們很長,人們按照說明并試圖完成這些提示。
這就是數據集的樣子,你可以訓練這些模型,這在一定程度上是有效的。
Reward Modeling 獎勵建模
現在,我們可以從這里繼續流程,進入 RLHF,即“從人類反饋中強化學習”,它包括獎勵建模和強化學習。

讓我介紹一下,然后我將回過頭來討論為什么您可能想要完成額外的步驟,以及這與 僅有SFT 模型相比如何。
在獎勵建模步驟中,我們現在要做的是將數據收集轉變為比較形式。
下面是我們的數據集的示例。
頂部是相同的提示,它要求助手編寫一個程序或一個函數來檢查給定的字符串是否為回文。
然后我們做的是采用已經訓練過的 SFT 模型,并創建多個補全。在這種情況下,我們有模型創建的三個補全。然后我們要求人們對這些補全進行排名。
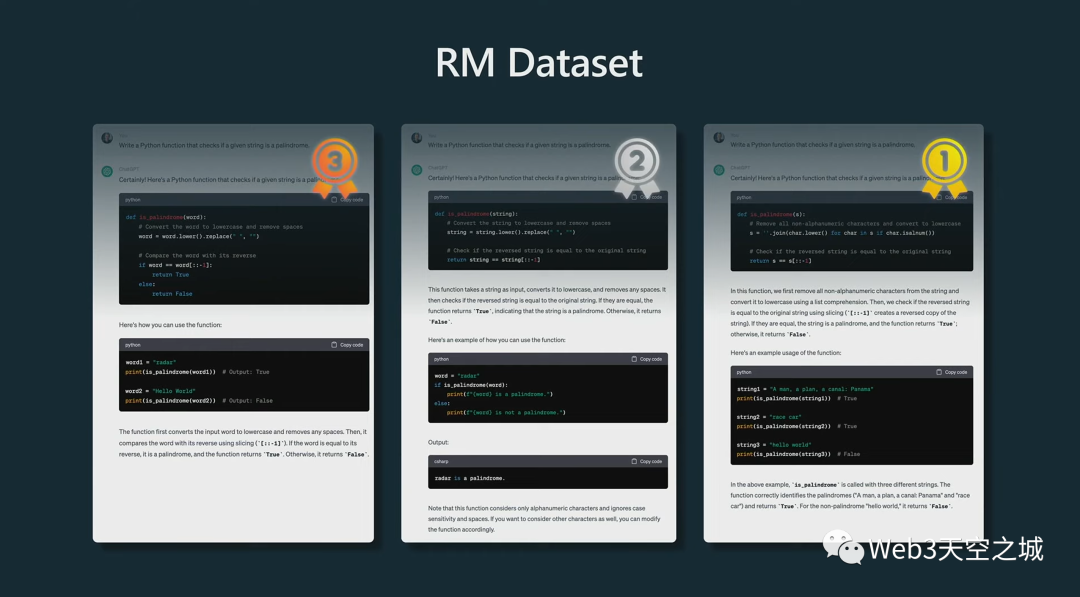
如果你盯著它看一會兒——順便說一下,要比較其中的一些預測是非常困難的事情,而且這可能需要人們甚至幾個小時來完成一個提示補全的比較。但假設我們決定,其中一個比其他的好得多,依此類推,我們對它們進行排名。
然后,我們可以對這些補全之間的所有可能對,進行看起來非常像二元分類的東西(以進行排序)。

接著,要做的是將提示按行排列,這里所有三行的提示都是相同的,但補全方式不同,黃色標記來自 SFT 模型,我們在最后附加另一個特殊的獎勵讀出標記,基本上只在這個單一的綠色標記上監督Transformer。Transformer會根據提示的完成程度預測一些獎勵。
Transformer對每個補全的質量進行了猜測,然后,一旦對每個補全進行了猜測,我們就有了模型對它們排名的基本事實,而我們實際上可以強制其中一些數字應該比其他數字高得多,我們將其制定為損失函數,并訓練我們的模型,使得模型做出與來自人類承包商的比較事實數據相一致的獎勵預測。 這就是我們訓練獎勵模型的方式。這使我們能夠對提示的完成程度進行評分。
Reinforcement Learning 強化學習
現在我們有了獎勵模型,但我們還不能部署它。
因為它本身作為助手不是很有用,但是它對于現在接下來的強化學習階段非常有用。

因為我們有一個獎勵模型,所以我們可以對任何給定提示(prompt)的任意完成/補全(completion)質量進行評分。
我們在強化學習期間所做的基本上是再次獲得大量提示,然后針對獎勵模型進行強化學習。
這就是它的樣子:
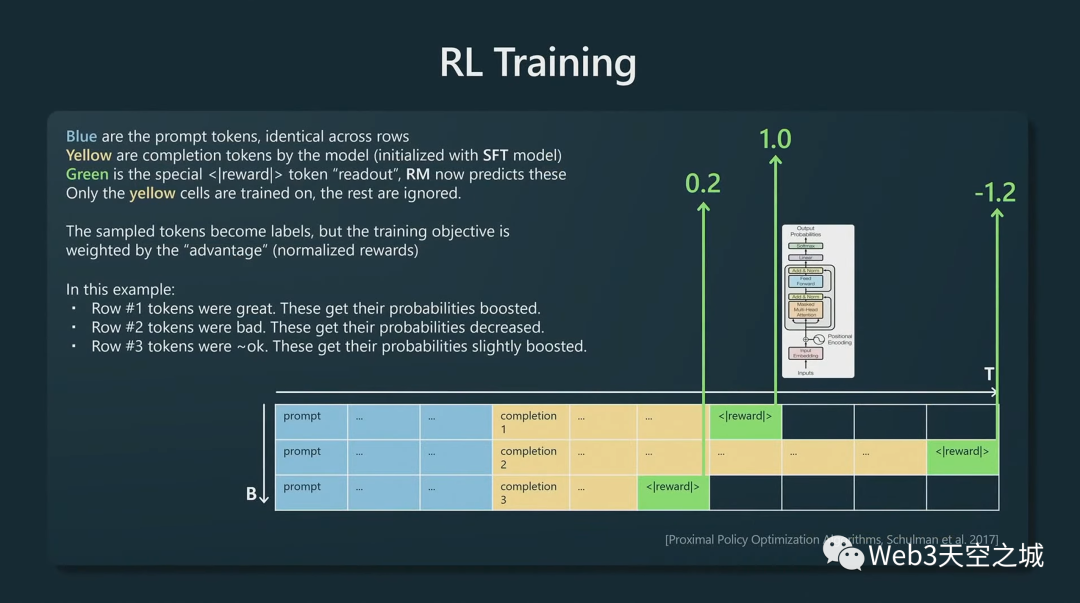
我們接受一個提示,將其排成行,現在我們使用想要訓練的模型,將該模型初始化為 SFT 模型,以創建一些黃色的補全。
然后,再追加獎勵標記,按照已經固定不變的獎勵模型讀出獎勵分數,現在這個獎勵模型的評分不再變化。獎勵模型告訴我們這些提示的每一次完成的質量。
我們現在基本上可以用(和前面)相同的語言建模損失函數,但我們目前正在對黃色標記進行訓練,并且我們正在通過獎勵模型指示的獎勵來權衡語言建模目標。
例如,在第一行中,獎勵模型表示這是一個相當高的完成度,因此我們碰巧在第一行采樣的所有標記都將得到強化,它們將 獲得更高的未來概率。相反,在第二行,獎勵模型真的不喜歡這個完成,負 1.2,因此我們在第二行采樣的每個標記在未來都會有更低的概率。
我們在很多提示、很多批次上一遍又一遍地這樣做,基本上,我們得到一個在這里創建黃色標記的策略,讓所有完成標記都會根據我們在前一階段訓練的獎勵模型獲得高分。
這就是我們訓練的方式——這就是 RLHF 流程。
最后,您得到了一個可以部署的模型。例如,ChatGPT 是 RLHF 模型。您可能會遇到其他一些模型,例如 Kuna 13B 等,這些都是 SFT 模型。
我們有基礎模型、SFT 模型和 RLHF 模型,這基本上是可用模型列表的事物狀態。
你為什么想要做 RLHF?一個不太令人興奮的答案是它的效果更好。
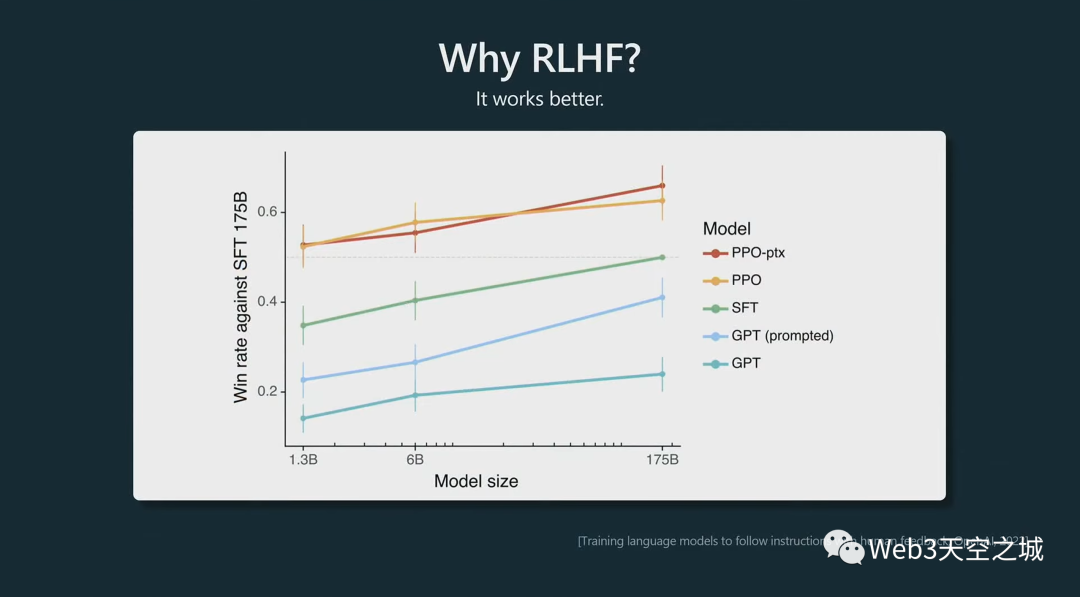
以上這個圖來自instructGPT論文。
這些 PPO 模型是 RLHF,根據前一段時間的這些實驗,我們看到把它們提供給人類時,它們在很多比較中更受歡迎。與提示為助手的基礎模型相比,與 SFT 模型相比,人類基本上更喜歡來自 RLHF 模型的標記(輸出文字)。
它就是工作得更好。
但你可能會問為什么?為什么效果更好?
我不認為社區有一個一致的令人驚奇的答案,但我可能提供一個原因:它與計算比較容易程度與生成容易程度之間的不對稱有關。
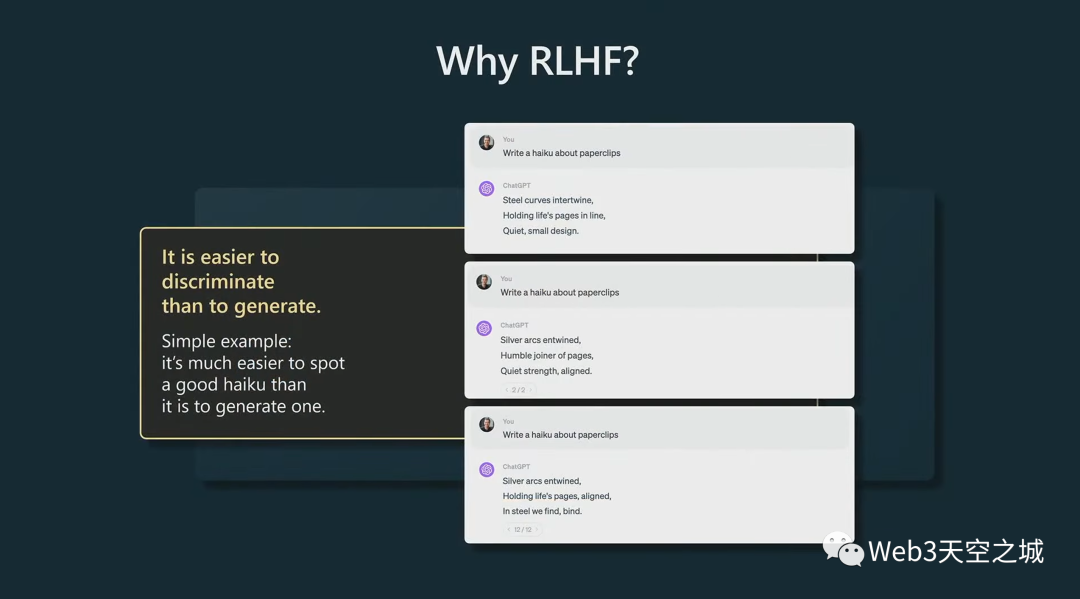
讓我們以生成俳句為例。假設我請模特寫一首關于回形針的俳句。
如果你是一個試圖提供訓練數據的承包商,那么想象一下,作為一個為 SFT 階段收集基本數據的承包商,你應該如何為一個回形針創建一個漂亮的俳句?
你可能不太擅長這個。
但是,如果我給你舉幾個俳句的例子,你可能會比其他人更能欣賞其中的一些俳句。
因此,判斷其中哪一個是好的是一項容易得多的任務。
基本上,這種不對稱性使得比較成為一種更好的方式,可以潛在地利用你作為一個人和你的判斷力來創建一個稍微更好的模型。
但是,RLHF 模型在某些情況下并不是對基礎模型的嚴格改進。
特別是,我們注意到,例如,RLHF模型失去了一些熵,這意味著它們給出了更多的峰值結果。

它們可以輸出更低的變化,可以輸出比基礎模型變化更少的樣本。
基礎模型有更多熵,會給出很多不同的輸出。我仍然更喜歡使用基礎模型的一種地方是。。。比如有 n 個東西并且想要生成更多類似東西的場景中。
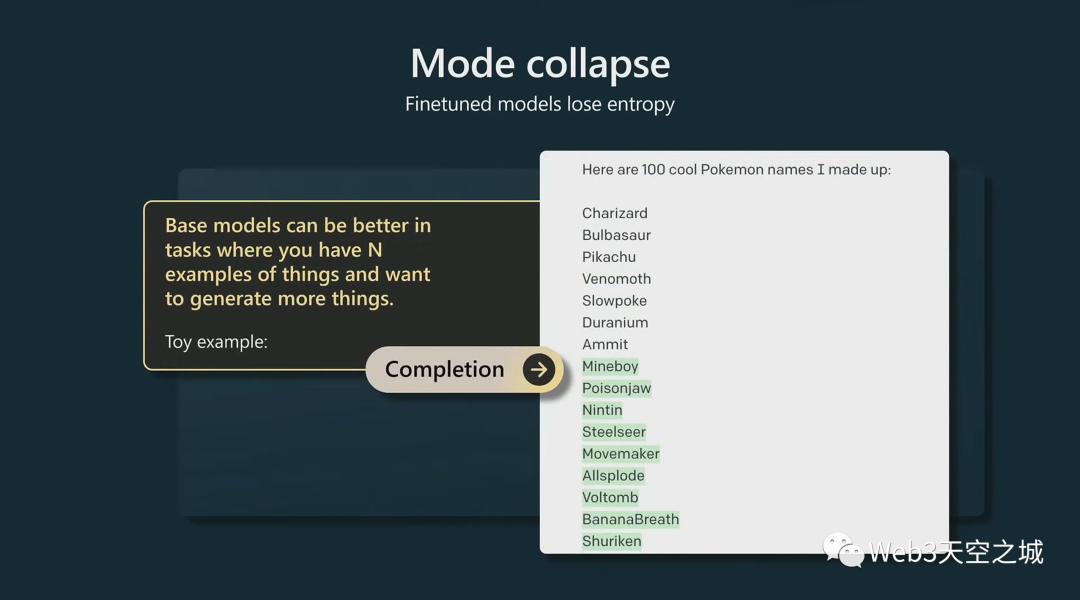
這是我剛剛編造的一個例子。
我想生成很酷的口袋妖怪名字。我給了它七個口袋妖怪的名字,讓基礎模型完成了文檔。它給了我更多的口袋妖怪名字。
這些都是虛構的,我還試圖查找它們,確定它們不是真正的口袋妖怪。
這是我認為基礎模型擅長的任務,因為它仍然有很多熵,并且會給你很多不同的、很酷的、更多的東西,看起來像你以前給它的任何東西。
說了這么多,這些是你現在可以使用的輔助模型,有一些數字:

伯克利有一個團隊對許多可用的助手模型進行排名,并基本上給了它們 ELO 評級。
目前最好的模型毫無疑問是 GPT-4,其次是 Claude,GPT-3.5,然后是一些模型,其中一些可能作為權重提供,比如 Kuna、Koala 等。
這里排名前三的是 RLHF 模型,據我所知,我相信所有其他模型都是 SFT 模型。
將GPT助手模型應用于問題
以上是我們在高層次上訓練這些模型的方式。
現在我要換個方向,讓我們看看如何最好地將 GPT 助手模型應用于您的問題。
現在我想在一個具體示例的場景里展示。讓我們在這里使用一個具體示例。
假設你正在寫一篇文章或一篇博客文章,你打算在最后寫這句話。

加州的人口是阿拉斯加的 53 倍。因此出于某種原因,您想比較這兩個州的人口。
想想我們自己豐富的內心獨白和工具的使用,以及在你的大腦中實際進行了多少計算工作來生成這最后一句話。
這可能是你大腦中的樣子:
好的。對于下一步,讓我寫博客——在我的博客中,讓我比較這兩個人群。
好的。首先,我顯然需要得到這兩個人群。
現在我知道我可能根本不了解這些人群。
我有點,比如,意識到我知道或不知道我的自我知識;正確的?
我去了——我做了一些工具的使用,然后我去了維基百科,我查找了加利福尼亞的人口和阿拉斯加的人口。
現在我知道我應該把兩者分開。
同樣,我知道用 39.2 除以 0.74 不太可能成功。
那不是我腦子里能做的事情。
因此,我將依靠計算器。
我打算用一個計算器,把它打進去,看看輸出大約是 53。
然后也許我會在我的大腦中做一些反思和理智檢查。
那么53有意義嗎?
好吧,這是相當大的一部分,但是加利福尼亞是人口最多的州,也許這看起來還可以。
這樣我就有了我可能需要的所有信息,現在我開始寫作的創造性部分了。
我可能會開始寫類似,加利福尼亞有 53 倍之類的東西,然后我對自己說,這實際上是非常尷尬的措辭,讓我刪除它,然后再試一次。
在我寫作的時候,我有一個獨立的過程,幾乎是在檢查我正在寫的東西,并判斷它是否好看。
然后也許我刪除了,也許我重新構造了它,然后也許我對結果感到滿意。
基本上,長話短說,當你創造這樣的句子時,你的內心獨白會發生很多事情。
但是,當我們在其上訓練 GPT 時,這樣的句子是什么樣的?
從 GPT 的角度來看,這只是一個標記序列。
因此,當 GPT 讀取或生成這些標記時,它只會進行分塊、分塊、分塊,每個塊對每個標記的計算工作量大致相同。
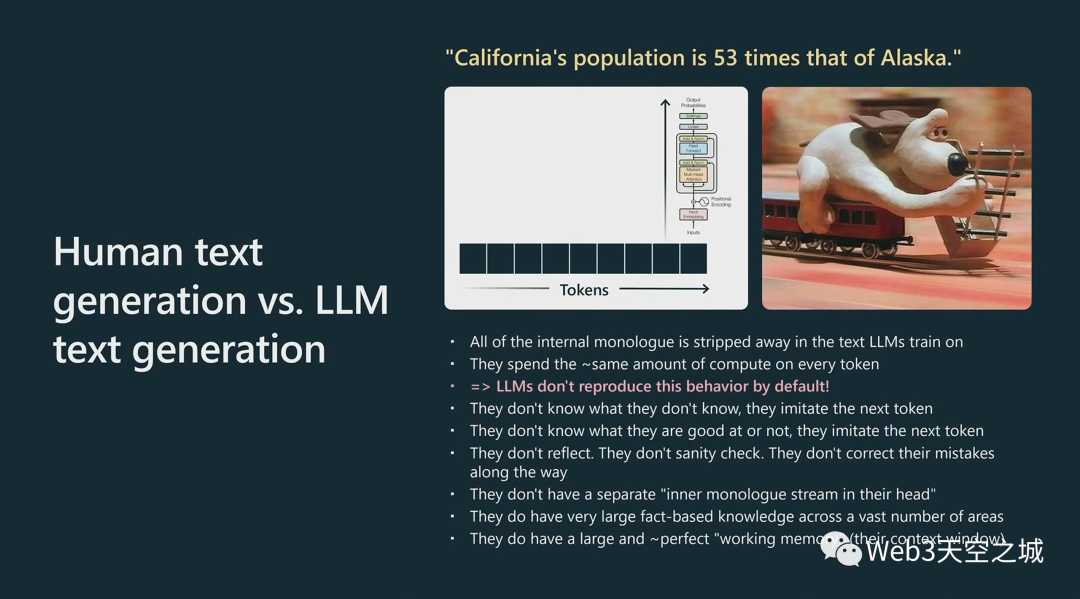
這些 Transformer 都不是很淺的網絡,它們有大約 80 層的推理,但 80 仍然不算太多。
這個Transformer將盡最大努力模仿。..但是,當然,這里的過程看起來與你采用的過程非常非常不同。
特別是,在我們最終的人工制品中,在創建并最終提供給 LLM 的數據集中,所有內部對話都被完全剝離(只給出最后結果作為訓練數據)。
并且與您不同的是,GPT 將查看每個標記并花費相同的算力去計算它們中的每一個,實際上,你不能指望它對每個標記做太多的工作。
基本上,這些Transformer就像標記模擬器。它們不知道自己不知道什么,它們只是模仿(預測)下一個標記;它們不知道自己擅長什么,不擅長什么,只是盡力模仿(預測)下一個標記。
它們不反映在循環中,它們不檢查任何東西,它們在默認情況下不糾正它們的錯誤,它們只是對標記序列進行采樣。
它們的頭腦中沒有單獨的內心獨白流,它們正在評估正在發生的事情。
現在它們確實有某種認知優勢,我想說,那就是它們實際上擁有大量基于事實的知識,涵蓋大量領域,因為它們有幾百億個參數,這是大量存儲和大量事實。
而且我認為,它們也有相對大而完美的工作記憶。
因此,任何適合上下文窗口的內容都可以通過其內部自注意機制立即供Transformer使用,它有點像完美的記憶。它的大小是有限的,但Transformer可以非常直接地訪問它,它可以無損地記住其上下文窗口內的任何內容。
這就是我比較這兩者的方式。
我之提出所有這些,是因為我認為在很大程度上,提示只是彌補了這兩種架構之間的這種認知差異。就像我們人類大腦和 LLM 大腦(的比較),你可以這么看。
人們發現有一件事,在實踐中效果很好。

特別是如果您的任務需要推理,您不能指望Transformer對每個標記進行太多推理,因此您必須真正將推理分散到越來越多的標記上。
例如,您不能向Transformer提出一個非常復雜的問題并期望它在一個標記中得到答案。(用于計算的)時間不夠。
這些Transformer需要標記來思考,我有時喜歡這樣說。
這是一些實踐中運作良好的事情:
例如,您可能有一個few-shot prompt提示,向Transformer顯示它在回答問題時應該展示其工作,如果您給出幾個示例,Transformer將模仿該模板,然后它就會在評估方面做得更好。
此外,您可以通過說“let‘s think step by step”從Transformer中引發這種行為,因為這使Transformer變得有點像展示它的工作。
而且,因為它有點進入一種顯示其工作的模式,它會為每個標記做更少的計算工作,因此它更有可能成功,因為隨著時間的推移,它的推理速度會變慢。
這是另一個例子。這稱為自我一致性。
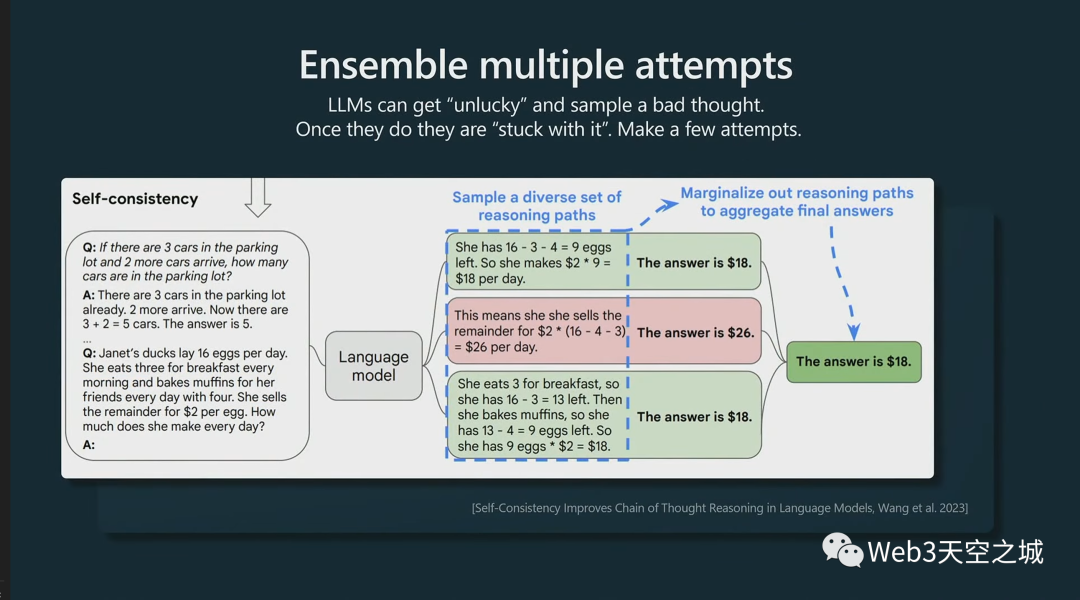
我們看到我們有能力開始寫,然后如果沒有成功,我可以再試一次,我可以多次嘗試,也許會選擇一個最好的。
因此,在這些類型的實踐中,您可能不僅會抽樣一次,還會抽樣多次,然后有一些過程來找到好的樣本,只保留這些樣本或者進行多數表決,類似這樣的事情。
而在這個過程中,這些 Transformer 在預測下一個標記時,就像你一樣,它們可能會倒霉,它們可能會采樣到一個不太好的標記,它們可能會在推理方面像死胡同一樣走下坡路。
因此,與您不同,它們無法從中恢復過來。
它們被它們采樣的每一個標記所困,所以它們會繼續這個序列,即使它們知道這個序列不會成功。
讓它們有某種能力能夠回顧、檢查或嘗試。。基本上圍繞它進行抽樣,這也是一種技術。
事實證明,實際上LLM像是知道什么時候搞砸了一樣。
例如,假設您要求模型生成一首不押韻的詩:
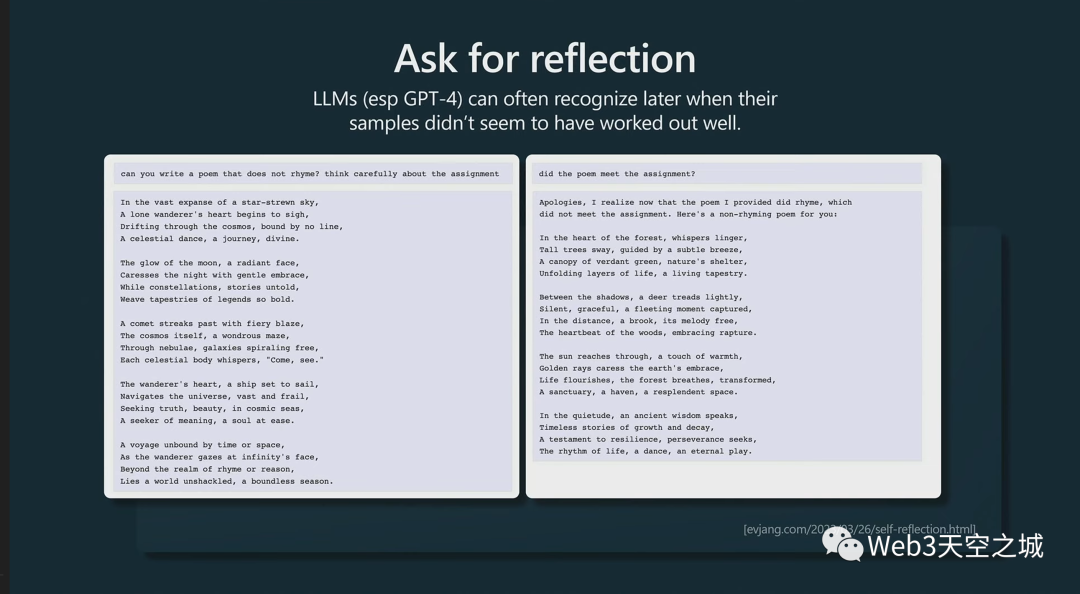
它可能會給你一首詩,但它實際上是押韻的。
事實證明,特別是對于更大的模型,比如 GPT-4,你可以問它,“你完成任務了嗎?”
實際上,GPT-4 很清楚自己沒有完成任務。它只是在采樣方面有點不走運。它會告訴你,“不,我沒有完成任務。讓我再嘗試一次。”
但是如果你不提示它,它甚至不會——就像它不知道要重新訪問等等,你必須在你的提示中彌補這一點。
你必須推動它來檢查。如果你不要求它檢查,它不會自己檢查。它只是一個標記模擬器。
我認為更一般地說,很多這些技術都屬于我所說的重建我們人類的系統二的范圍。
你可能熟悉人類思考的系統一和系統二模式。
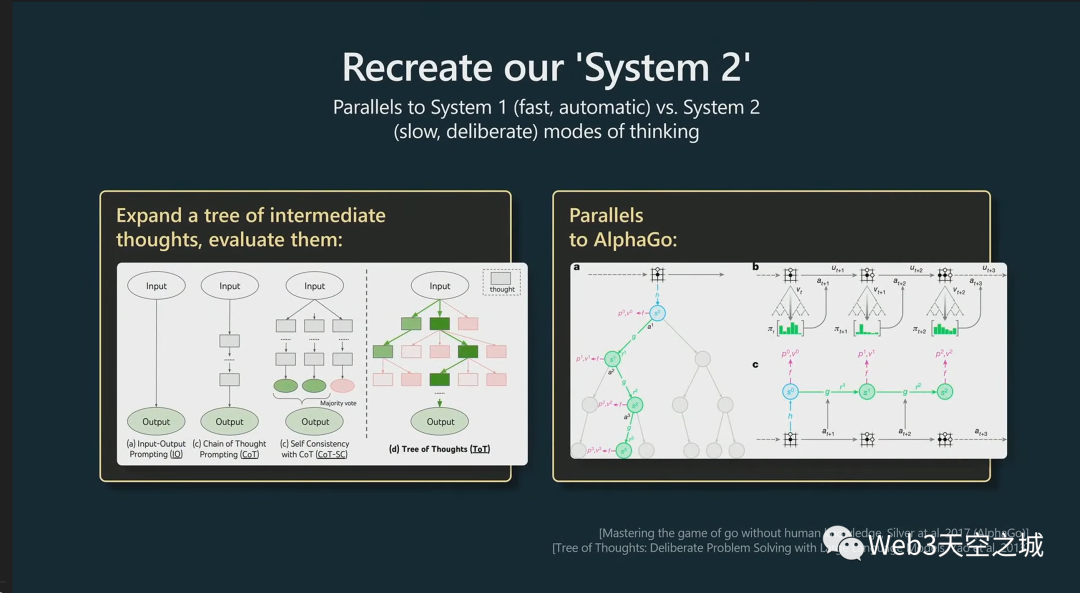
系統一是一個快速的自動過程,我認為有點對應于 LLM,只是對標記進行抽樣。
系統二是大腦中較慢的、經過深思熟慮的計劃部分。
這實際上是上周的一篇論文,這個領域正在迅速發展。它被稱為思想樹(Tree of Thought)。
在思想樹中,這篇論文的作者建議為任何給定的提示維護多個完成,然后也會在整個過程中對它們進行評分,并保留那些進展順利的。大家看看這是否有意義。
很多人真的在把玩一些prompt工程,基本上是希望讓LLM恢復一些我們大腦中具有的能力。
我想在這里指出的一件事是,這不僅僅是一個提示。這實際上是與一些 Python 膠水代碼一起使用的提示,因為你實際上要維護多個提示,你還必須在這里做一些樹搜索算法來找出擴展哪個提示等等。
因此,它是 Python 膠水代碼和在 while 循環或更大算法中調用的各個提示的共生體。
我還認為這里與 AlphaGo 有一個非常酷的相似之處。
AlphaGo下圍棋有一個放下一塊棋子的策略,這個策略本來就是模仿人訓練出來的。
但是除了這個策略之外,它還會做蒙特卡洛搜索,它會在圍棋中打出多種可能性并評估所有這些,只保留那些運作良好的。
我認為這有點類似于AlphaGo,但是針對于文本。
就像思想樹一樣,我認為更普遍的是,人們開始真正探索更通用的技術,不僅僅是簡單的問答提示,而是看起來更像是將許多提示串在一起的 Python 膠水代碼。

在右邊,我有一個來自這篇論文的例子,叫做 React,他們將提示的答案構造為一系列思考、行動、觀察、思考、行動、觀察,這是一個完整的展開,一種思考 回答查詢的過程。在這些動作中,模型也被允許使用工具。
在左邊,我有一個AutoGPT 的例子。
順便說一句,AutoGPT 是一個我認為最近炒得沸沸揚揚的項目,但我仍然覺得它有點鼓舞人心。它是一個允許 LLM 保留任務列表并繼續遞歸分解任務的項目,我認為目前效果不是很好,不建議人們在實際應用中使用它。
但我認為,隨著時間的推移,這是可以從中汲取靈感的東西。AutoGPT有點像讓我們的模型系統思考。
接下來一件事,我覺得有點意思的是 ,LLM 有種不想成功的心理怪癖。
它們只是想模仿。如果你想成功,你應該要求它。

我的意思是,當 Transformer 被訓練時,它們有訓練集,并且它們的訓練數據中可以有一個完整的性能質量范圍。
例如,可能有一些物理問題或類似問題的提示,可能有一個學生的解決方案完全錯誤,但也可能有一個非常正確的專家答案。
Transformer無法區分它們之間的區別——它們知道低質量解決方案和高質量解決方案,但默認情況下,它們想要模仿所有這些,因為它們只是接受過語言建模方面的訓練。
在測試的時候,你必須要求一個好的表現。
上面論文中的這個例子,他們嘗試了各種提示,“let’s think step by step”非常強大,因為它把推理分散到許多標記上
但更好的提示方法是:“讓我們一步一步地解決這個問題 確定我們有正確的答案”。
這就像獲得正確答案的條件一樣,這實際上使Transformer工作得更好,因為Transformer現在不必在低質量解決方案上對沖其概率質量,盡管這聽起來很荒謬。。。
基本上,請隨意尋求一個強有力的解決方案,說出您是該主題的領先專家之類的話,假裝你有 IQ 120,等等。
不要試圖要求太多的智商,因為如果你要求 400 的智商,你可能會在數據分布之外;或者更糟糕的是,你可能會在一些科幻的數據分布中,它會開始 進行一些科幻角色扮演,或類似的事情。
我認為你必須找到合適的智商設定。那里有一些U形曲線。
接下來,正如我們所看到的,當我們試圖解決問題時,我們知道自己擅長什么,不擅長什么,并且我們在計算上依賴工具。
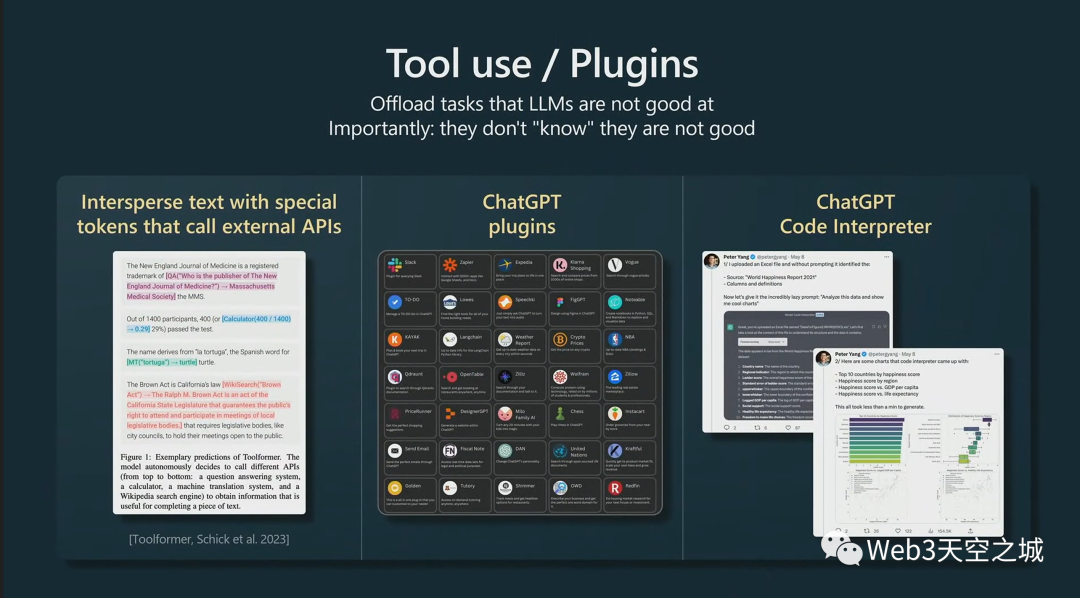
你想對你的LLM做同樣的事情。特別是,我們可能希望為它們提供計算器、代碼解釋器等,以及進行搜索的能力,并且有很多技術可以做到這一點。
再次要記住的一件事是,默認情況下這些Transformer可能不知道它們不知道的事情,你甚至可能想在提示中告訴Transformer,“你的心算不太好。每當您需要進行大數加法、乘法或其他操作時,請使用此計算器。以下是您如何使用計算器。使用這個標記組合,等等,等等。”
你必須把它拼出來,因為默認情況下模型不知道它擅長什么或不擅長什么,就像你和我一樣。
接下來,我認為一件非常有趣的事情是,我們從一個只有檢索的世界走到鐘擺擺動的另一個極端,那里只有LLM的記憶
但實際上,在這兩者之間有檢索增強模型的整個空間,這在實踐中非常有效。
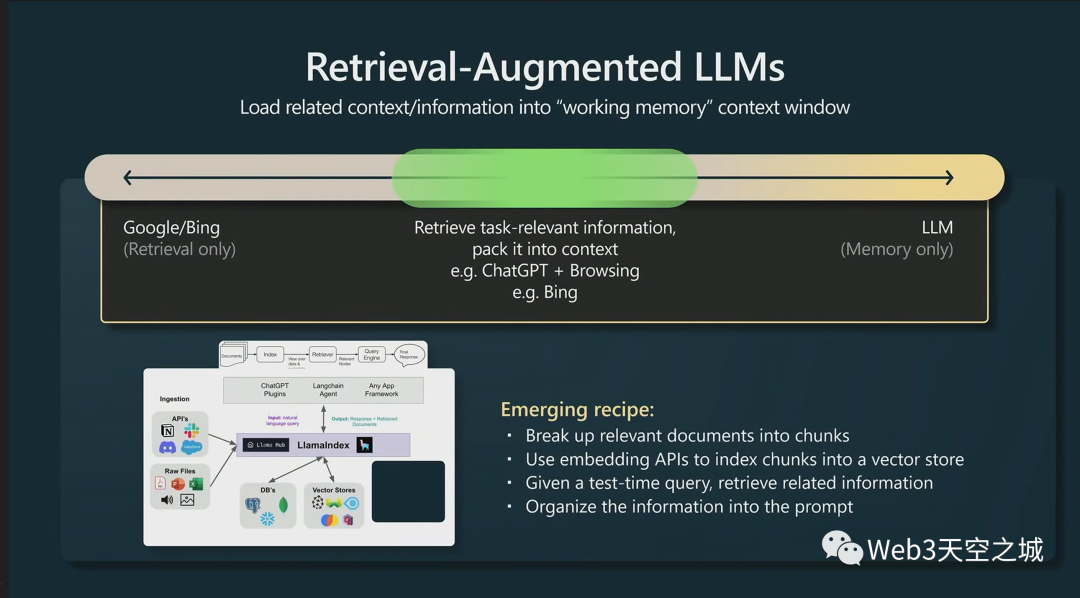
正如我所提到的,Transformer的上下文窗口是它的工作內存。如果您可以將與任務相關的任何信息加載到工作內存中,那么該模型將運行得非常好,因為它可以立即訪問所有內存。
我認為很多人對基本上檢索增強生成非常感興趣,在上圖底部,我有一個Llama索引的例子,它是許多不同類型數據的一個數據連接器,你可以索引所有這些數據,讓 LLM 訪問它。
新興的秘訣是獲取相關文檔,將它們分成塊,將它們全部嵌入,得到表示該數據的嵌入向量,將其存儲在向量存儲中;然后在測試時,對矢量存儲進行某種查詢,獲取可能與您的任務相關的塊,然后將它們填充到提示中,然后生成。這在實踐中可以很好地工作。
這類似于你我解決問題的時候,你可以憑記憶做任何事情,Transformer的記憶力非常大,但它有助于參考一些主要文件。
無論何時,您發現自己要回到教科書上找東西,或者每當您發現自己要回到圖書館的文檔中查找東西時,Transformer肯定也想這樣做。您對庫的某些文檔如何工作有一定的記憶,但最好查找一下。同樣的事情也適用于LLM。
接下來,我想簡單說一下約束提示。我也覺得這很有趣。
這是在 LLM 的輸出中強制使用特定模板的技術,實際上這是 Microsoft 的一個示例。
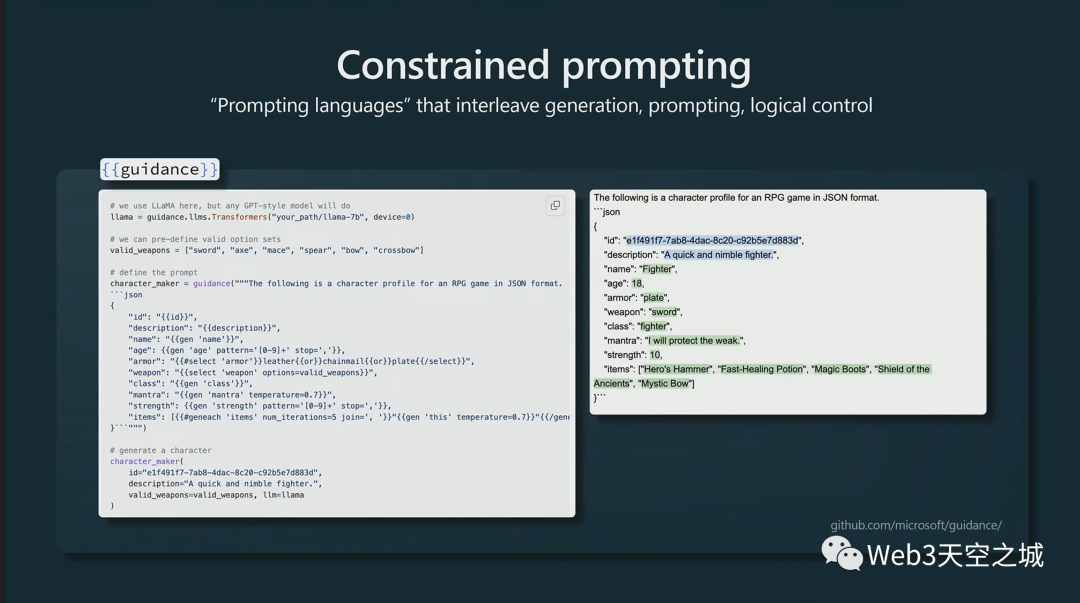
在這里,我們強制 LLM 的輸出將是 JSON,這實際上將保證輸出將采用這種形式,因為它們進入并擾亂了來自Transformer的所有不同標記的概率,并且固定住這些標記。
然后Transformer只填充此處的空白,然后可以對可能進入這些空白的內容實施額外的限制。這可能真的很有幫助,我認為這種約束抽樣也非常有趣。
我還想說幾句微調。
您可以通過快速prompt工程取得很大進展,但也可以考慮微調您的模型。
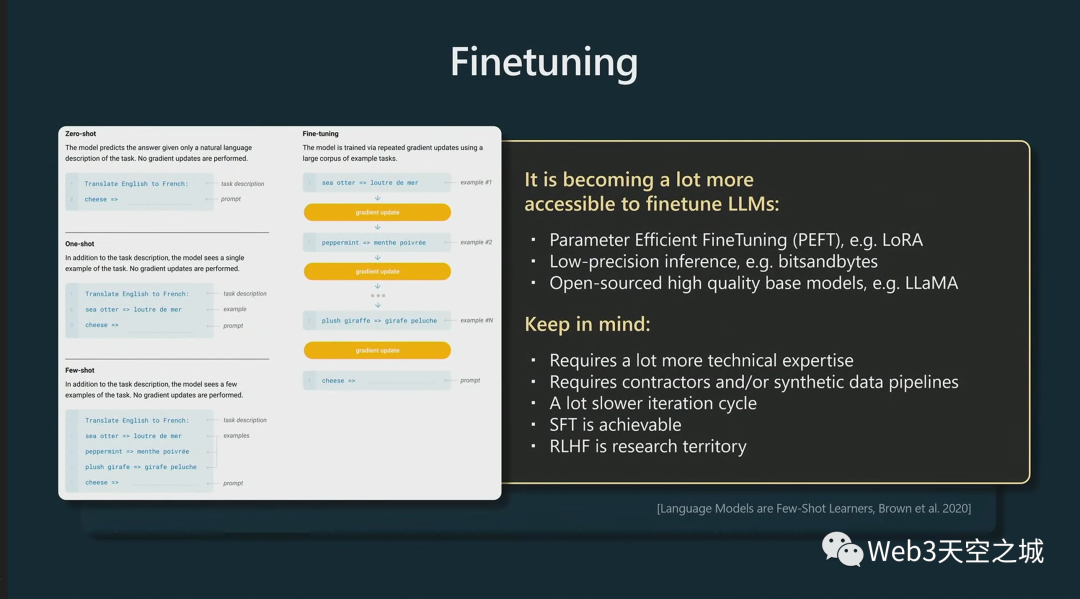
微調模型意味著你實際上要改變模型的權重。現在在實踐中做到這一點變得越來越容易,這是因為最近開發了許多技術并擁有庫調用。
例如,像 Lora 這樣的參數高效微調技術可確保您只訓練模型的小而稀疏的部分。因此大部分模型都保持在基礎模型上,并且允許更改其中的一些部分, 這在經驗上仍然很有效,并且使得僅調整模型的一小部分成本更低。
這也意味著,因為你的大部分模型都是固定的,你可以使用非常低的精度推理來計算這些部分,因為它們不會被梯度下降更新,這也使得一切都更加高效。
此外,我們還有許多開源的高質量基礎模型。目前,正如我提到的,我認為 Llama 相當不錯,盡管我認為它現在還沒有獲得商業許可。
需要記住的是,微調在技術上涉及更多,它需要更多的技術專長才能做對。它需要數據集和/或可能非常復雜的合成數據流程的人工數據承包商。這肯定會大大減慢你的迭代周期。
我想在較高的層次上說,SFT 是可以實現的,因為你只是在繼續語言建模任務。它相對簡單;但 RLHF 是一個非常多的研究領域,而且它更難開始工作。
我可能不建議有人嘗試推出他們自己的 RLHF 實現。這些東西非常不穩定,很難訓練,現在對初學者來說不是很友好,而且它也有可能變化得非常快。
我認為以下這些是我現在的默認建議。

我會把你的任務分成兩個主要部分。
第一,實現你的最佳表現,第二,按照這個順序優化你的費用。
首先,目前最好的性能來自 GPT4 模型。它是迄今為止功能最強大的模型。
然后, 讓提示里包含詳細的任務內容、相關信息和說明。想想如果它們不能給你回郵件你會告訴它們什么。要記住任務承包商是人,他們有內心獨白,他們非常聰明;而LLM不具備這些品質。因此,請務必仔細考慮LLM的心理,并迎合這一點。甚至向這些提示添加任何相關的上下文和信息。
多參考很多提示工程技術。我在上面的幻燈片中突出顯示了其中一些,但這是一個非常大的空間,我只建議您在線尋找快速的Prompt工程技術。那里有很多內容。
嘗試使用少樣本few-shots示例提示。這指的是你不只是想問,你還想盡可能地展示(你想要的),給它舉例子,如果可以的話,幫助它真正理解你的意思。
嘗試使用工具和插件來分擔 LLM 本身難以完成的任務。
然后不僅要考慮單個提示和答案,還要考慮潛在的鏈條和反射,以及如何將它們粘合在一起,以及如何制作多個樣本等。
最后,如果你認為你已經最大化了提示工程的效果,我認為你應該堅持一段時間,看看一些可能對你的應用程序的模型微調,但預計這會更慢并且涉及更多。
然后這里有一個脆弱的專家研究區,我想說的是 RLHF,如果你能讓它工作的話。它目前確實比 SFT 好一點,但是,我想說的是,這非常復雜。
為了優化您的成本,請嘗試探索容量較低的模型或更短的提示等。
我還想談談我認為 LLM 目前非常適合的用例。
特別要注意的是,今天的 LLM 有很多限制,我會在所有應用中牢記這一點。

模型,順便說一句,這可能是一個完整的演講,我沒有時間詳細介紹它。
模型可能有偏見,它們可能捏造、產生幻覺信息,它們可能有推理錯誤,它們可能在整個類別的應用程序中都掙扎,它們有知識截止日期,比如說,2021 年 9 月。Twitter 每天都在發生大量對LLM的攻擊,包括即時注入、越獄攻擊、數據中毒攻擊等。
我現在的建議是在低風險應用程序中使用 LLM,將它們與始終與人工監督結合起來,將它們用作靈感和建議的來源,并考慮副駕駛而不是在某處執行任務的完全自主的代理。目前尚不清楚這些模型是否合適。
最后我想說,GPT-4 是一個了不起的人工制品,我非常感謝它的存在。
它很漂亮,它在很多領域都有大量的知識,它可以做數學、代碼等等。此外,還有一個蓬勃發展的生態系統,包括正在構建并納入生態系統的其他所有事物,其中一些我已經談到了。
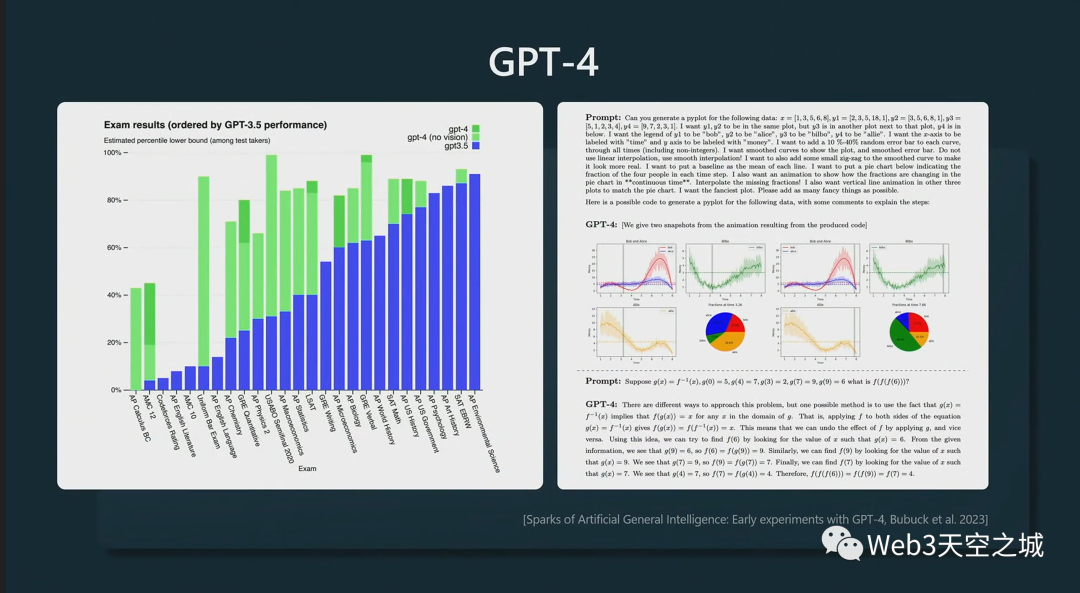
所有這些功能都觸手可及。
我和GPT-4說,“你能說些什么來激勵 Microsoft Build 2023 的觀眾嗎?”
我將其輸入 Python 并逐字記錄,GPT-4 說了以下內容。
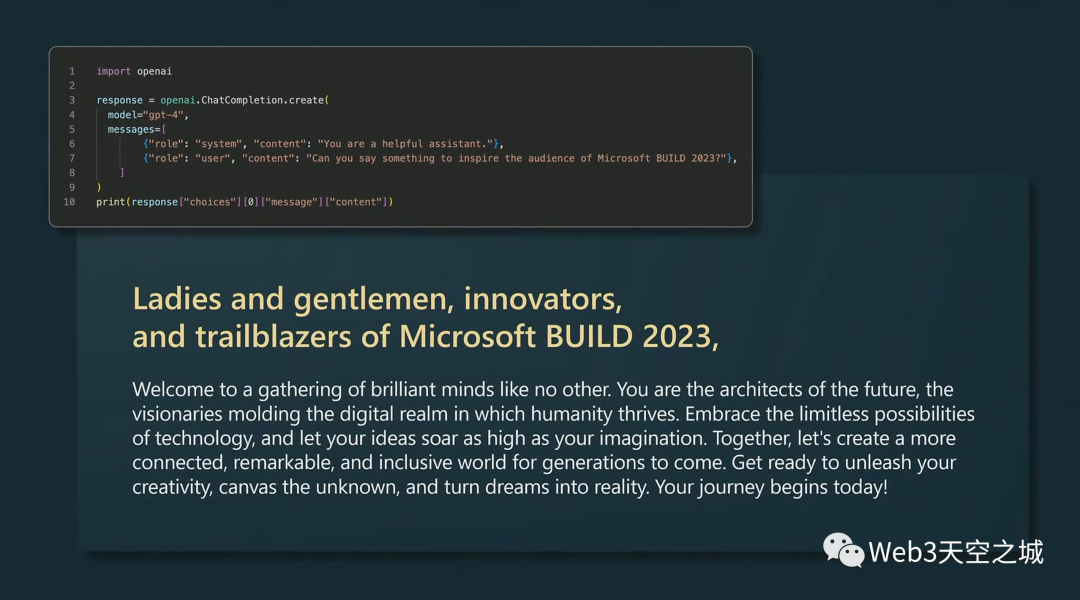
順便說一句,我不知道它們在主題演講中使用了這個技巧,我以為我很聰明,但它真的很擅長這個。
它說:
“女士們,先生們,微軟 Build 2023 的創新者和開拓者,歡迎來到與眾不同的聰明才智的聚會。
你們是未來的建筑師,是塑造人類蓬勃發展的數字領域的遠見者。
擁抱技術的無限可能性,讓您的想法像您的想象一樣飛翔。
讓我們一起為子孫后代創造一個聯系更緊密、更卓越、更具包容性的世界。
準備好釋放您的創造力,探索未知,將夢想變為現實。
你的旅程從今天開始。”。
謝謝!
審核編輯 :李倩
-
生態系統
+關注
關注
0文章
702瀏覽量
20723 -
OpenAI
+關注
關注
9文章
1079瀏覽量
6482
原文標題:State of GPT:大神Andrej揭秘OpenAI大模型原理和訓練過程
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
GPU是如何訓練AI大模型的
OpenAI宣布啟動GPT Next計劃
BP神經網絡的基本結構和訓練過程
解讀PyTorch模型訓練過程
深度學習的典型模型和訓練過程
CNN模型的基本原理、結構、訓練過程及應用領域
OpenAI揭秘CriticGPT:GPT自進化新篇章,RLHF助力突破人類能力邊界
OpenAI發布全新GPT-4o模型
OpenAI推出面向所有用戶的AI模型GPT-4o
OpenAI有望在年中推出全新GPT-5模型
OpenAI預計最快今年夏天發布GPT-5
OpenAI迎戰紐約時報指控 非法使用其內容訓練人工智能模型
OpenAI推出GPT商店
OpenAI GPT 商店即將亮相,SpaceX 新型 Starlink 衛星發射上天






 工商網監
工商網監
評論