 未來十年的芯片路線圖
未來十年的芯片路線圖
Imec 是世界上最先進的半導體研究公司,最近在比利時安特衛普舉行的 ITF 世界活動上分享了其亞 1 納米硅和晶體管路線圖。該路線圖讓我們了解了到 2036 年公司將在其實驗室與臺積電、英特爾、Nvidia、AMD、三星和 ASML 等行業巨頭合作研發下一個主要工藝節點和晶體管架構的時間表,在許多其他人中。該公司還概述了向其所謂的 CMOS 2.0 的轉變,這將涉及將芯片的功能單元(如 L1 和 L2 緩存)分解為比當今基于小芯片的方法更先進的 3D 設計。
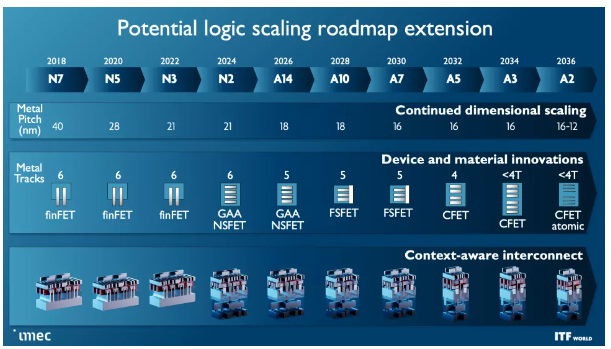
提醒一下,10 埃等于 1 納米,因此 Imec 的路線圖包含亞“1 納米”工藝節點。該路線圖概述了標準 FinFET 晶體管將持續到 3nm,然后過渡到新的全柵 (GAA) 納米片設計,該設計將在 2024 年進入大批量生產。Imec 繪制了 2nm 和 A7(0.7nm)Forksheet設計的路線圖,隨后分別是 A5 和 A2 的 CFET 和原子通道等突破性設計。
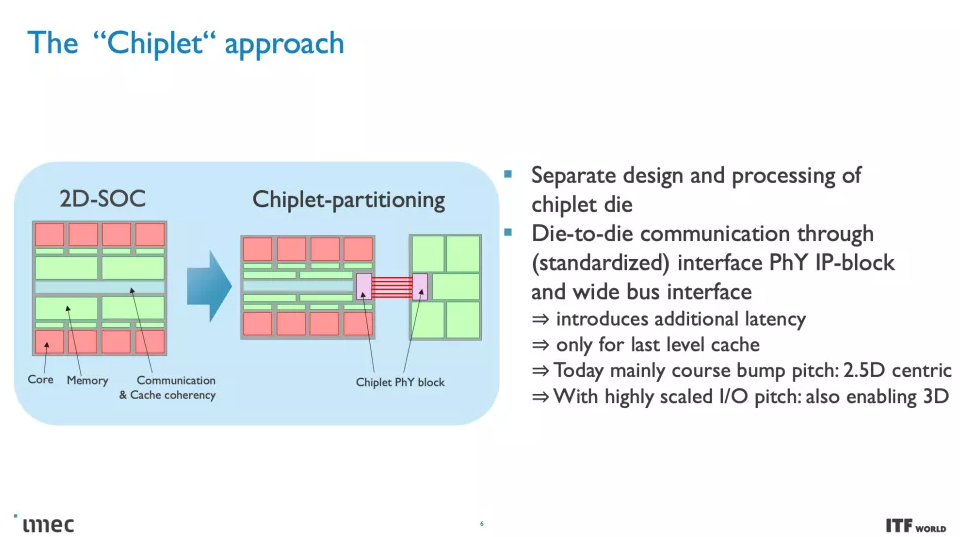
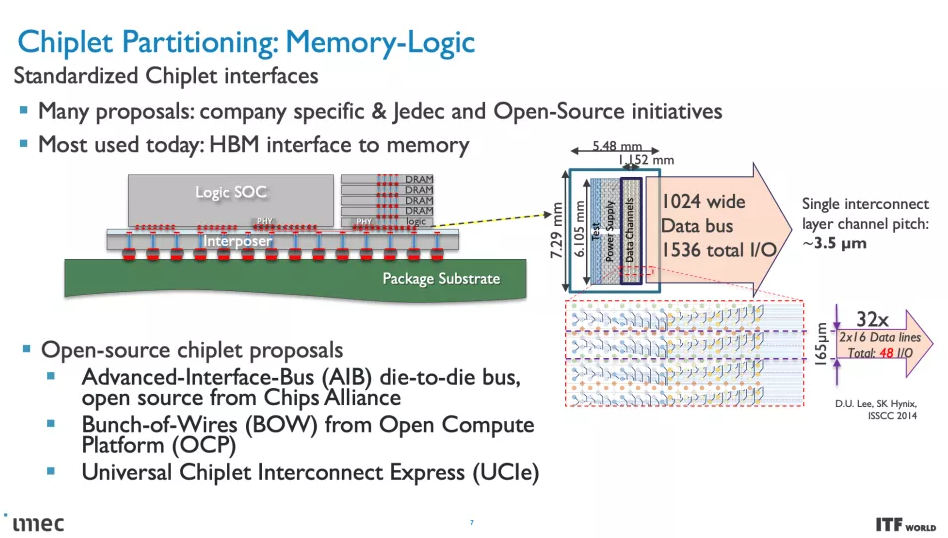
隨著時間的推移,轉移到這些較小的節點變得越來越昂貴,并且使用單個大芯片構建單片芯片的標準方法已經讓位于小芯片。基于小芯片的設計將各種芯片功能分解為連接在一起的不同芯片,從而使芯片能夠作為一個內聚單元發揮作用——盡管需要權衡取舍。
Imec 對 CMOS 2.0 范式的設想包括將芯片分解成更小的部分,將緩存和存儲器分成具有不同晶體管的自己的單元,然后以 3D 排列堆疊在其他芯片功能之上。這種方法還將嚴重依賴背面供電網絡 (BPDN),該網絡通過晶體管的背面路由所有電力。
讓我們仔細看看 imec 路線圖和新的 CMOS 2.0 方法。
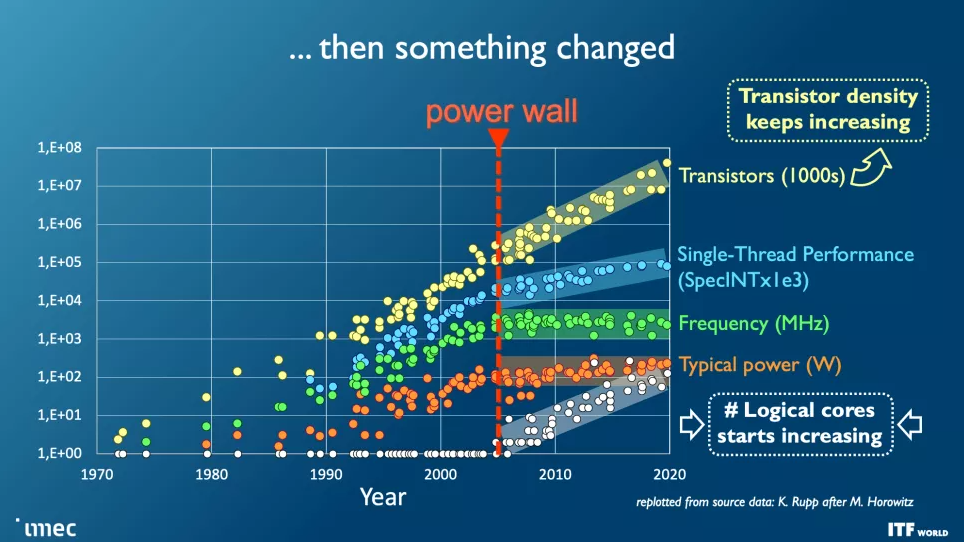
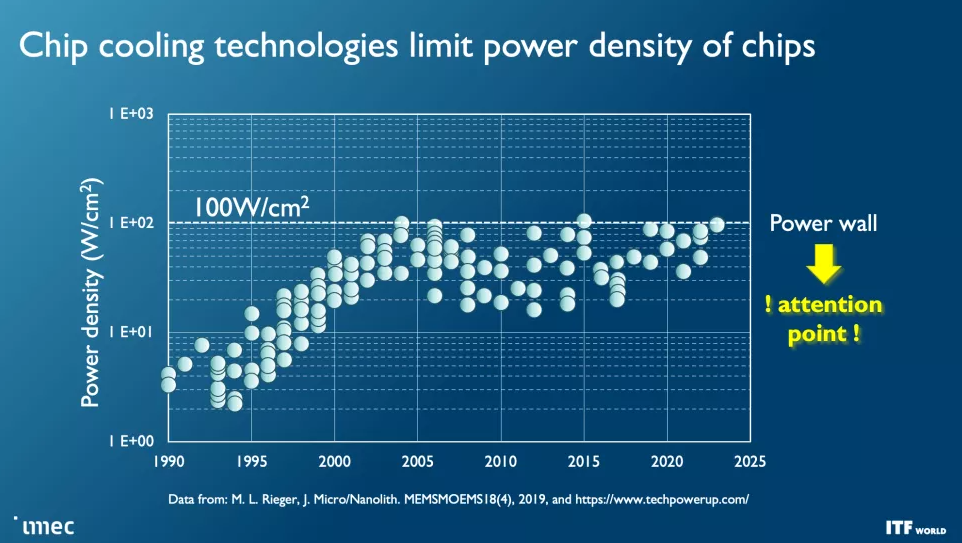
正如您在上面的相冊中看到的那樣,隨著節點的進步,該行業面臨著看似無法克服的挑戰,但對更多計算能力的需求,尤其是對機器學習和人工智能的需求呈指數級增長。這種需求并不容易滿足。成本飆升,而高端芯片的功耗穩步增加——功率縮放仍然是一個挑戰,因為 CMOS 工作電壓頑固地拒絕低于 0.7 伏,并且持續需要擴展到更大的芯片帶來了電源和冷卻挑戰,這將需要全新的規避解決方案。
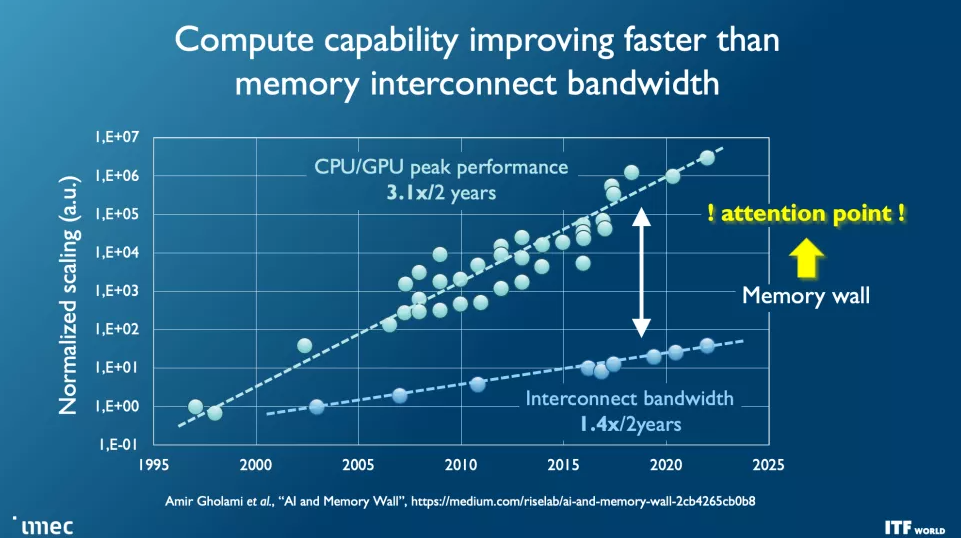
雖然晶體管數量在可預測的摩爾定律路徑上繼續翻倍,但其他基本問題也越來越成為每一代新一代芯片的問題,例如互連帶寬的限制嚴重落后于現代 CPU 和 GPU 的計算能力,從而阻礙了性能并限制這些額外晶體管的有效性。
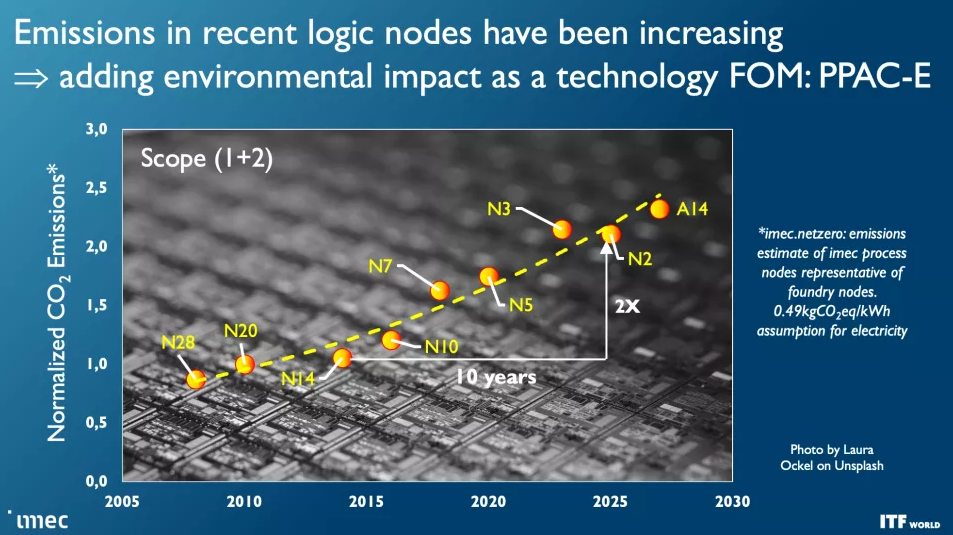
imec 晶體管和工藝節點路線圖
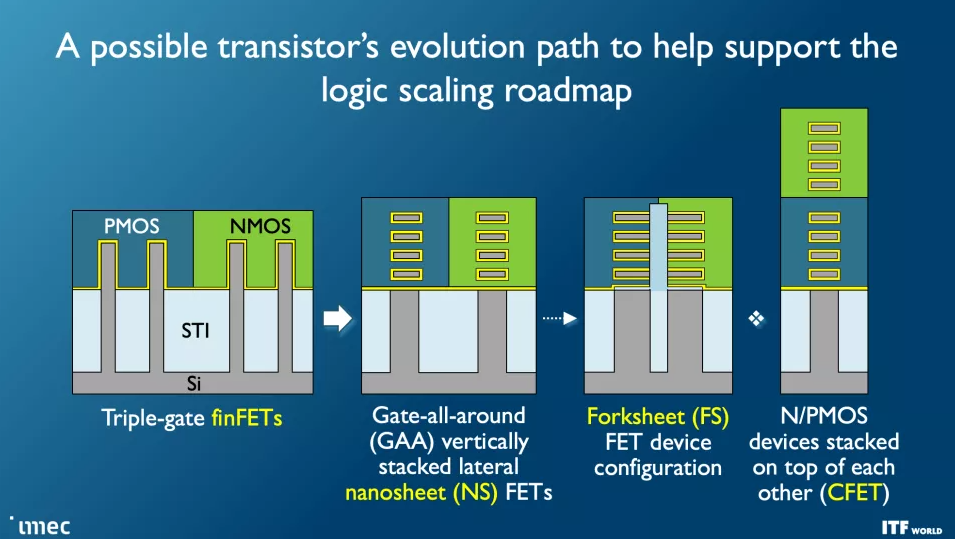
不過,速度更快、密度更大的晶體管是首要任務,而這些晶體管的第一波浪潮將伴隨著 2024 年以 2nm 節點首次亮相的 Gate All Around (GAA)/Nanosheet 器件,取代為當今領先技術提供動力的三柵極 FinFET 。GAA 晶體管賦予晶體管密度和性能改進,例如更快的晶體管開關,同時使用與多個鰭片相同的驅動電流。泄漏也顯著減少,因為溝道完全被柵極包圍,調整溝道的厚度可以優化功耗或性能。
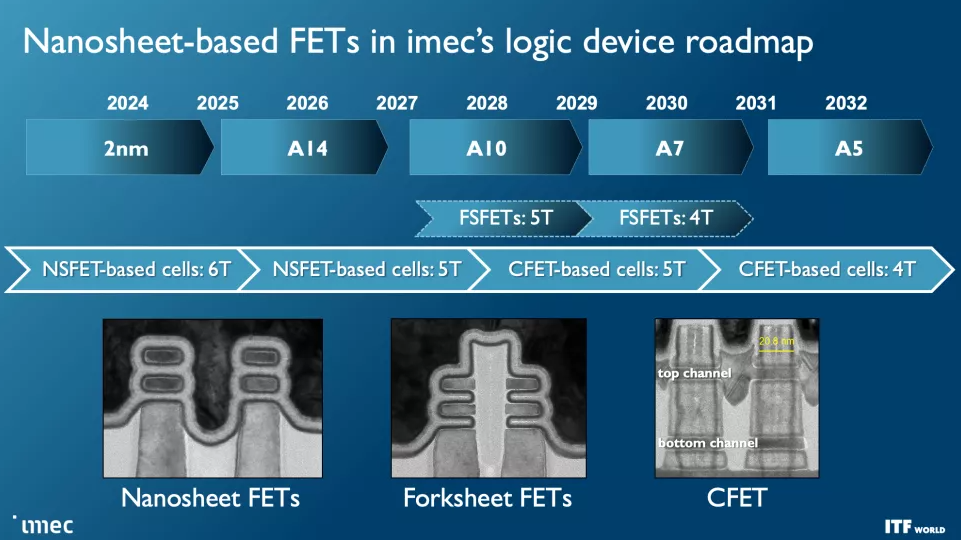
我們已經看到多家芯片制造商采用了這種晶體管技術的不同變體。行業領導者臺積電計劃其帶有 GAA 的 N2 節點將于 2025 年量產,因此它將是最后采用新型晶體管的。英特爾采用“intel 20A”工藝節點的四層 RibbonFET具有四個堆疊的納米片,每個納米片完全由一個門包圍,并將于 2024 年首次亮相。三星是第一家生產用于運輸產品的 GAA,但小批量 SF3E pipe-cleane的節點不會看到大規模生產。相反,該公司將在 2024 年推出其用于大批量制造的先進節點。
提醒一下,10 埃 (A) 等于 1 納米。這意味著 A14 是 1.4 納米,A10 是 1 納米,我們將在 2030 年的時間框架內與 A7 一起進入亞 1 納米時代。但請記住,這些指標通常與芯片上的實際物理尺寸不匹配。
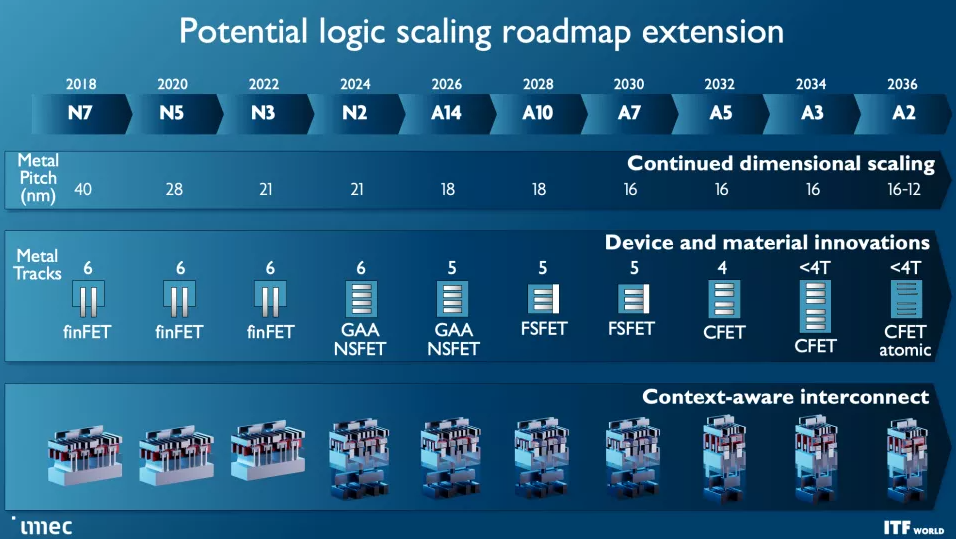
Imec 預計 forksheet 晶體管從 1nm (A10) 開始,一直到 A7 節點 (0.7nm)。正如您在第二張幻燈片中看到的那樣,該設計分別堆疊 NMOS 和 PMOS,但使用電介質勢壘將它們分開,從而實現更高的性能和/或更好的密度。
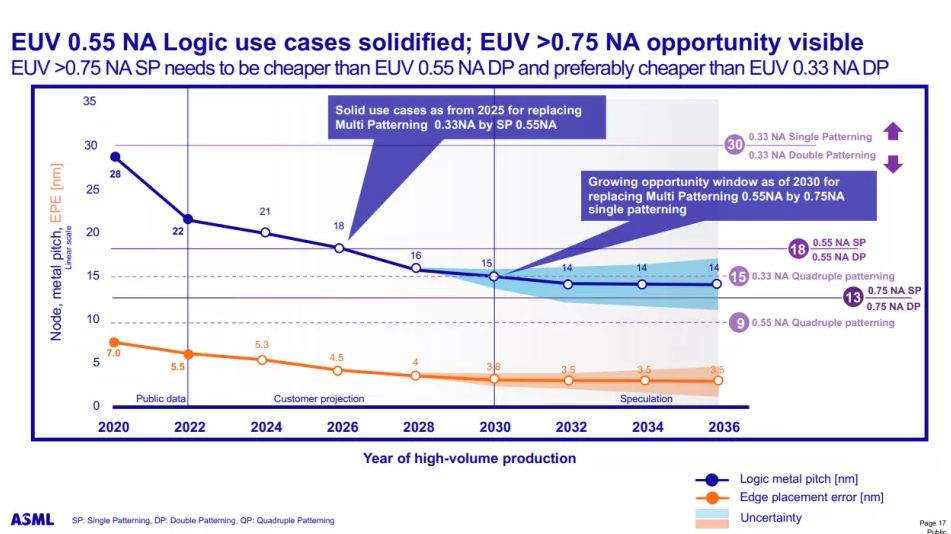
互補 FET (CFET:Complementary FET) 晶體管在 2028 年首次以 1nm 節點 (A10) 出現時將進一步縮小占位面積,從而允許更密集的標準單元庫。最終,我們將看到帶有原子通道的 CFET 版本,進一步提高性能和可擴展性。CFET 晶體管(您可以 在此處閱讀更多相關信息)將 N 型和 PMOS 器件堆疊在一起以實現更高的密度。CFET 應該標志著納米片器件縮放的結束,以及可見路線圖的結束。
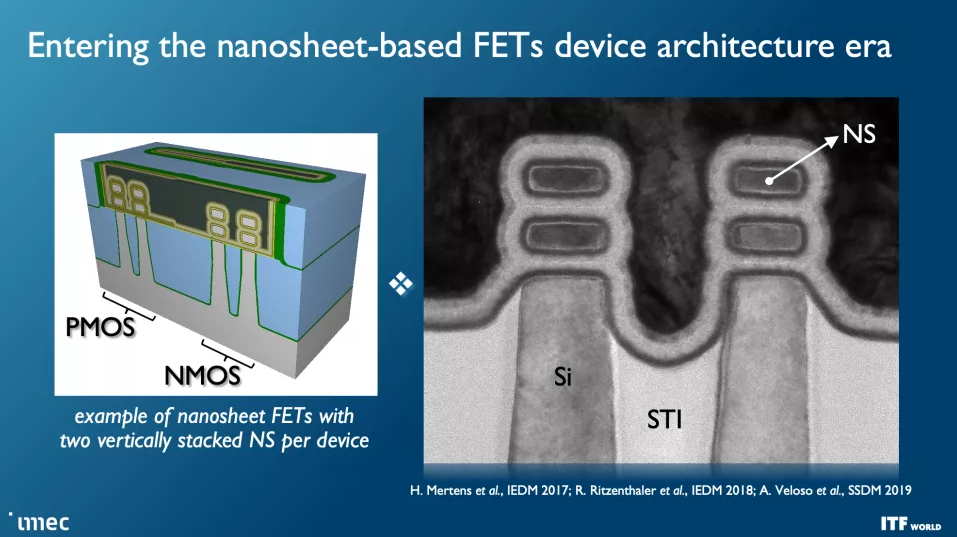
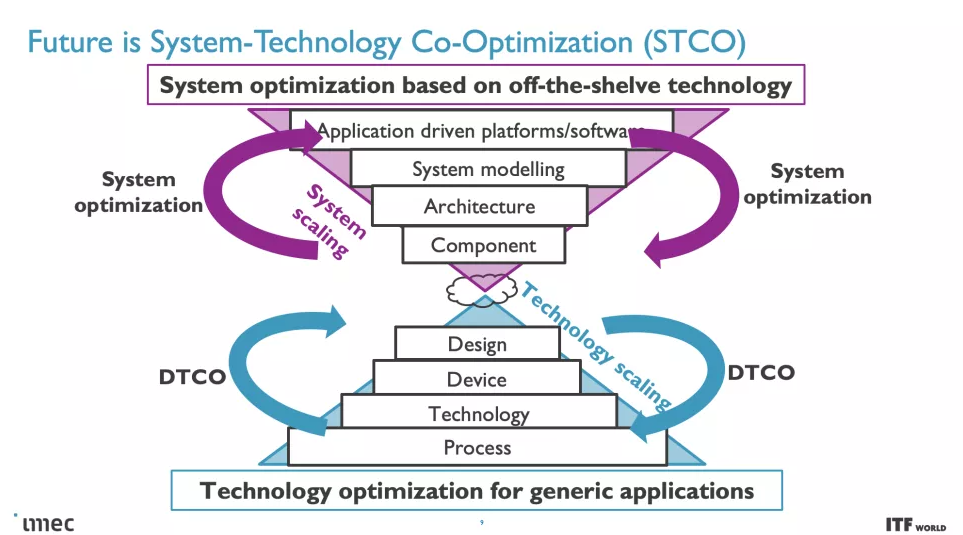
然而,將需要其他重要技術來打破性能、功率和密度縮放障礙,imec 設想這將需要新的 CMOS 2.0 范例和系統技術協同優化 (SCTO)。
STCO 和背面供電
在最高級別,系統技術協同優化 (STCO:system technology co-optimization) 需要通過對系統和目標應用程序的需求建模來重新思考設計過程,然后使用這些知識來為創建芯片的設計決策提供信息。這種設計方法通常會導致“分解”通常作為單片處理器的一部分的功能單元,例如供電、I/O 和高速緩存,并將它們拆分為單獨的單元,以通過使用不同的方法針對所需的性能特性優化每個單元類型的晶體管,然后也提高了成本。
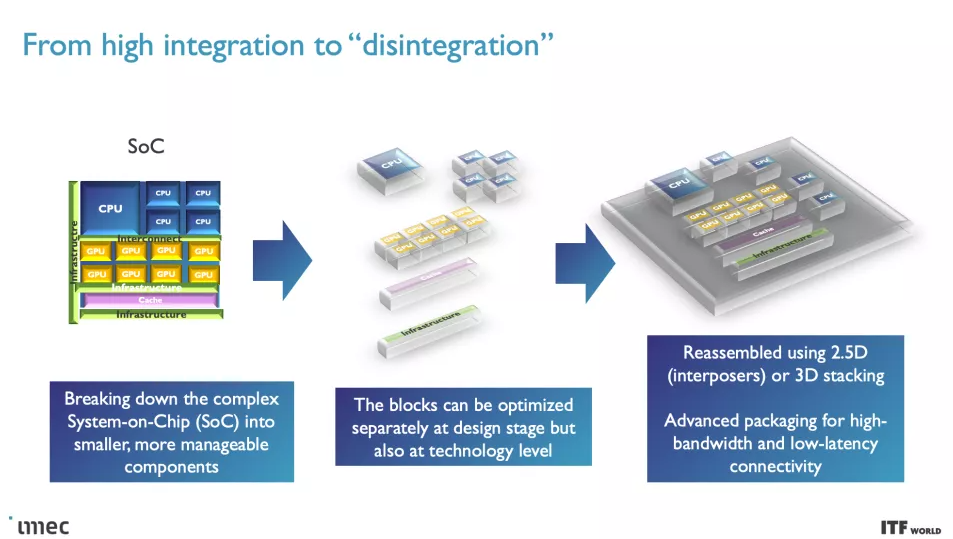
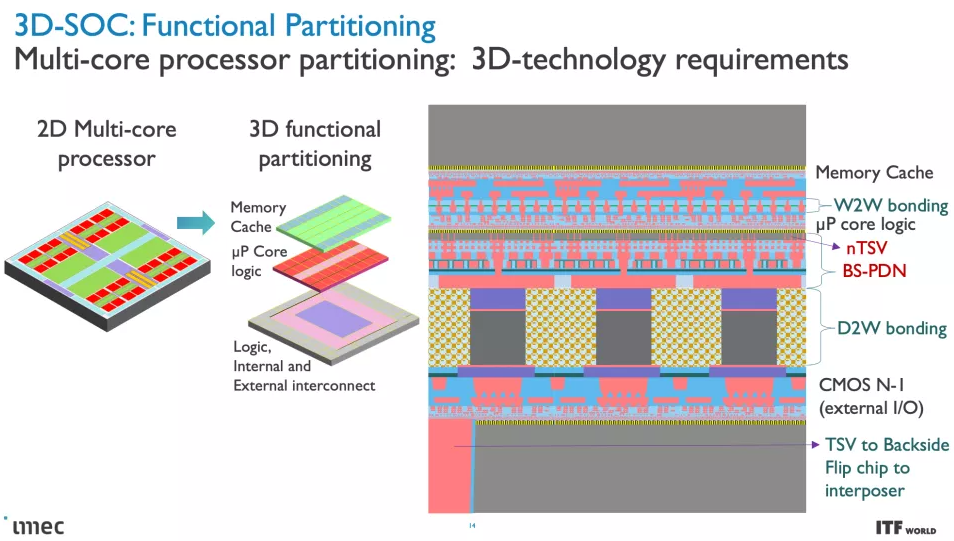
完全分解標準芯片設計的目標之一是將高速緩存/內存拆分到 3D 堆疊設計中它們自己的不同層(更多內容見下文),但這需要降低芯片堆棧頂部的復雜性。改造后端生產線 (BEOL:Back End of Line) 流程,重點是將晶體管連接在一起并實現通信(信號)和電力傳輸,是這項工作的關鍵。
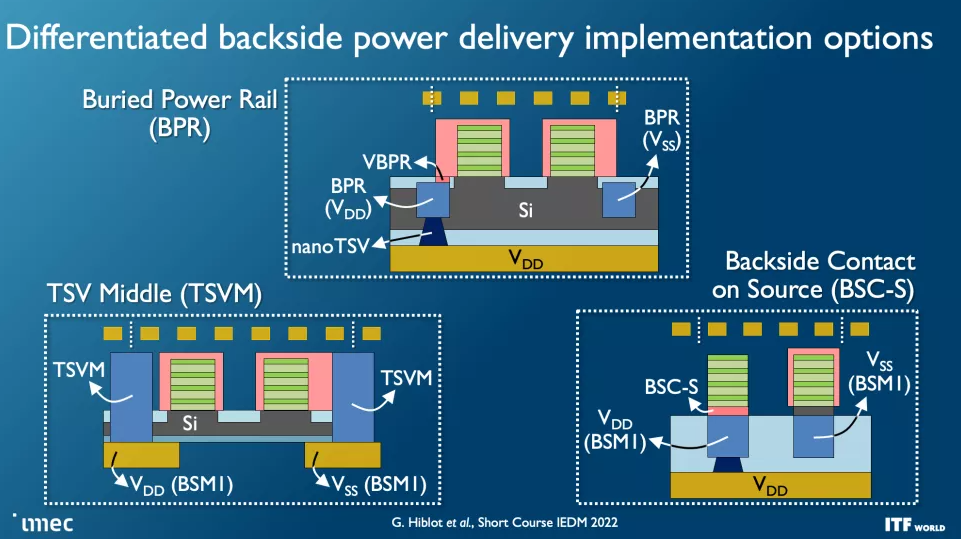
與當今從芯片頂部向下向晶體管傳輸功率的設計不同,背面配電網絡 (BPDN:backside power distribution networks ) 使用 TSV 將所有功率直接路由到晶體管的背面,從而將功率傳輸與保留在其內部的數據傳輸互連分開另一邊的正常位置。將電源電路和數據傳輸互連分開可改善壓降特性,從而實現更快的晶體管開關,同時在芯片頂部實現更密集的信號路由。信號完整性也有好處,因為簡化的布線可以更快地連接電阻和電容。
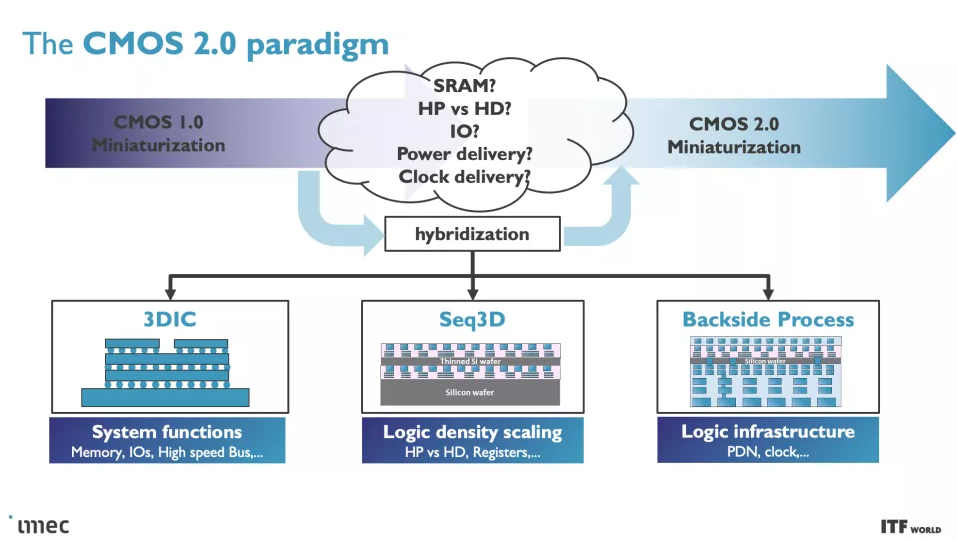
將供電網絡移至芯片底部可以更輕松地在裸片頂部進行晶圓到晶圓的鍵合,從而釋放在存儲器上堆疊邏輯的潛力。Imec 甚至設想可能將其他功能轉移到晶圓的背面,例如全局互連或時鐘信號。
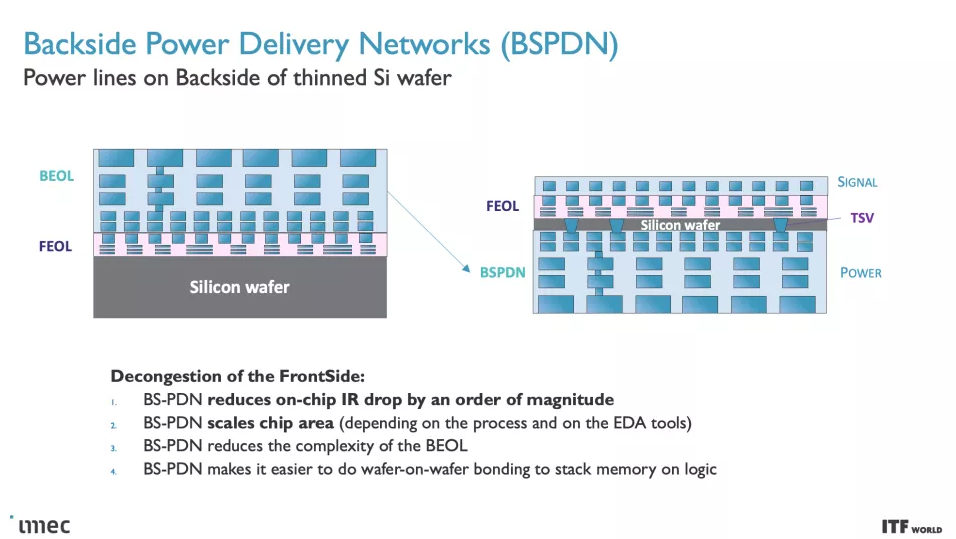
英特爾已經宣布了自己的 BPDN 技術版本,稱為PowerVIA,將于 2024 年以intel 20A 節點首次亮相。英特爾將在即將舉行的 VLSI 活動中透露有關該技術的更多細節。同時,臺積電也宣布將BPDN引入其2026年量產的N2P節點,因此這項技術將落后于英特爾相當長的一段時間。也有傳言稱三星將在其 2nm 節點采用該技術。

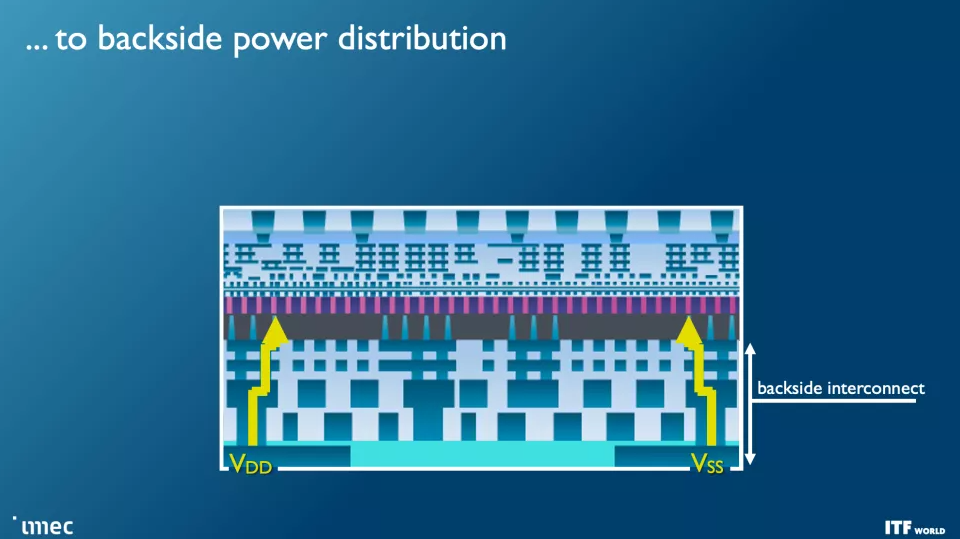
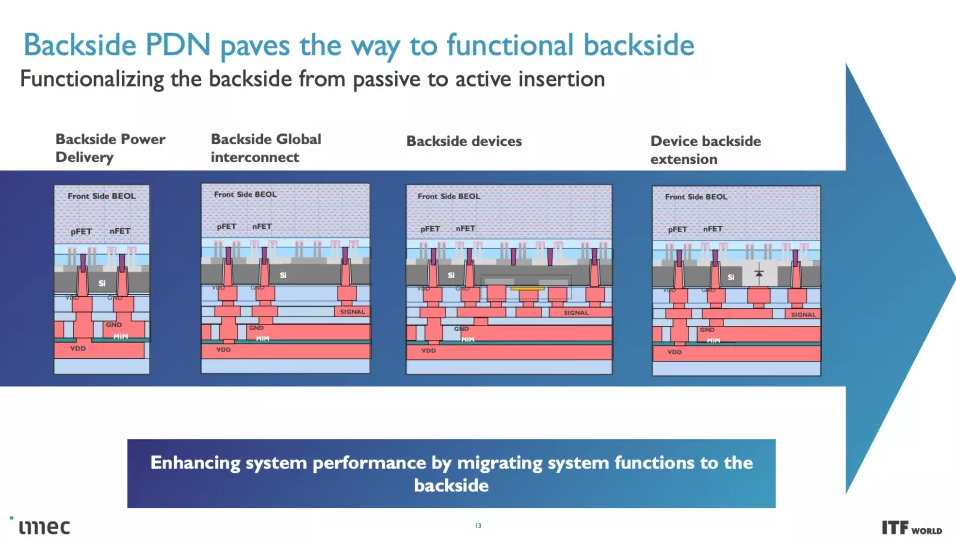
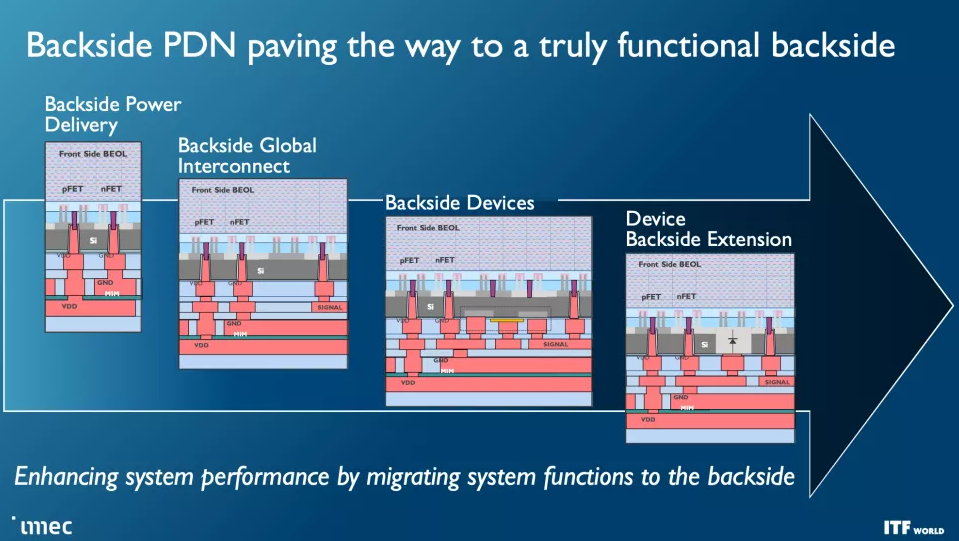
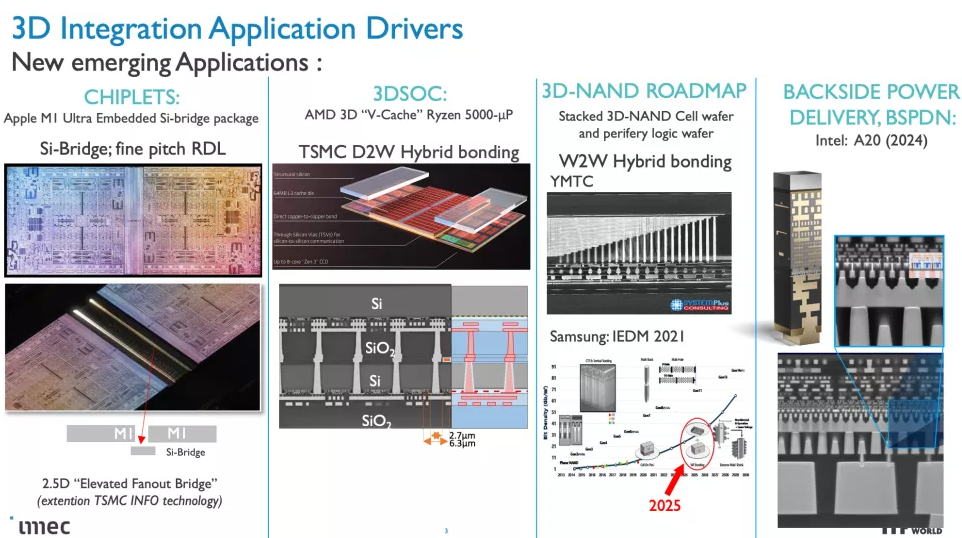
CMOS 2.0 是 imec 對未來芯片設計愿景的巔峰之作,涵蓋了全 3D 芯片設計。我們已經看到 AMD 第二代 3D V-Cache 的內存堆疊,將 L3 內存堆疊在處理器之上以提高內存容量,但 imec 設想整個緩存層次結構包含在其自己的層中,具有 L1、L2 和 L3 緩存垂直堆疊在構成處理核心的晶體管上方的自己的芯片上。每個級別的緩存都將使用最適合該任務的晶體管創建,這意味著 SRAM 的舊節點,隨著SRAM 縮放速度開始大幅放緩,
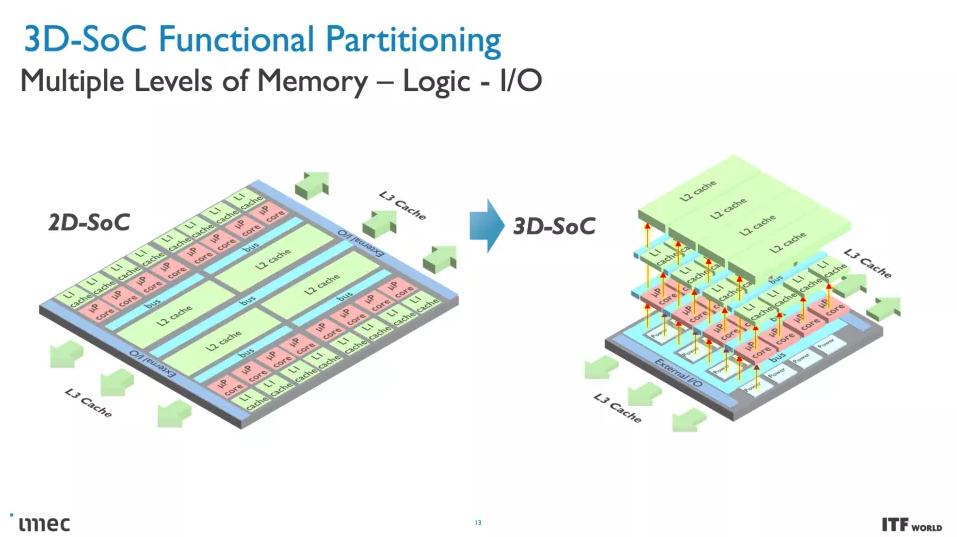
這變得越來越重要. SRAM 縮小的規模導致緩存占用了更高比例的裸片,從而導致每 MB 成本增加,并阻礙了芯片制造商使用更大的緩存。因此,將 3D 堆疊的緩存轉移到密度較低的節點所帶來的成本降低也可能導致比我們過去看到的緩存更大的緩存。如果實施得當,3D 堆疊還可以幫助緩解與較大緩存相關的延遲問題。
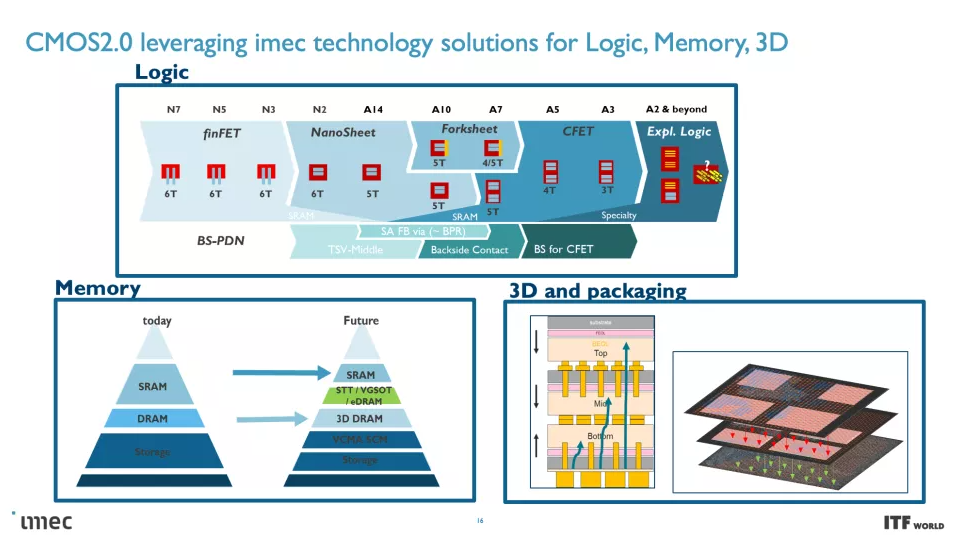
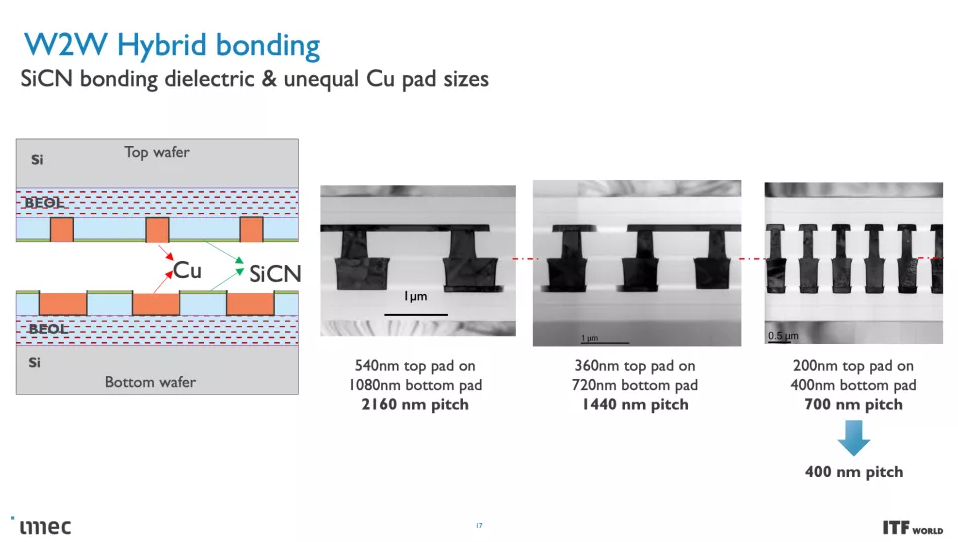
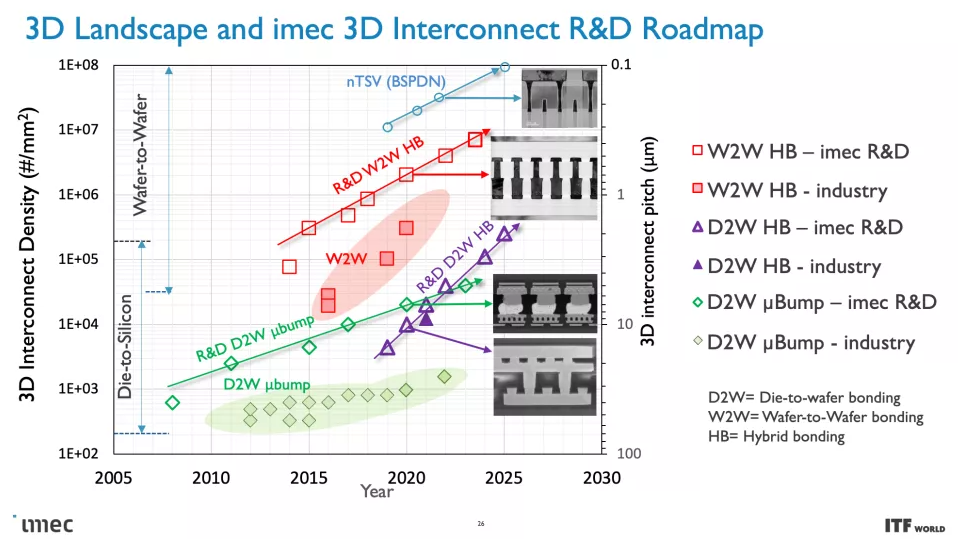
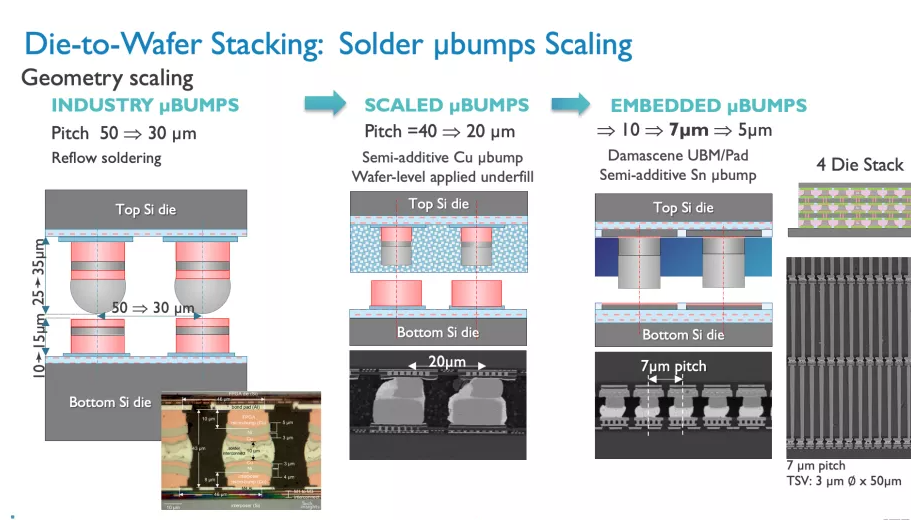
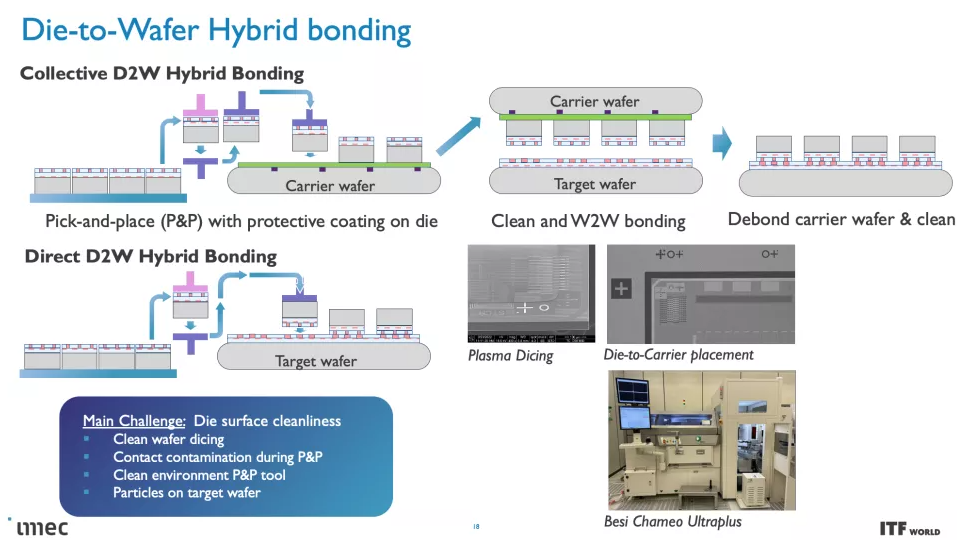
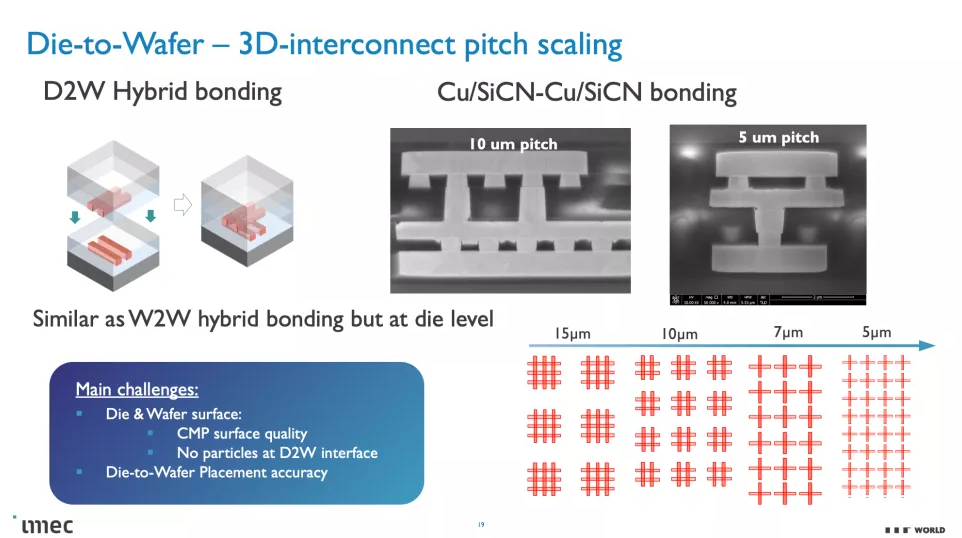
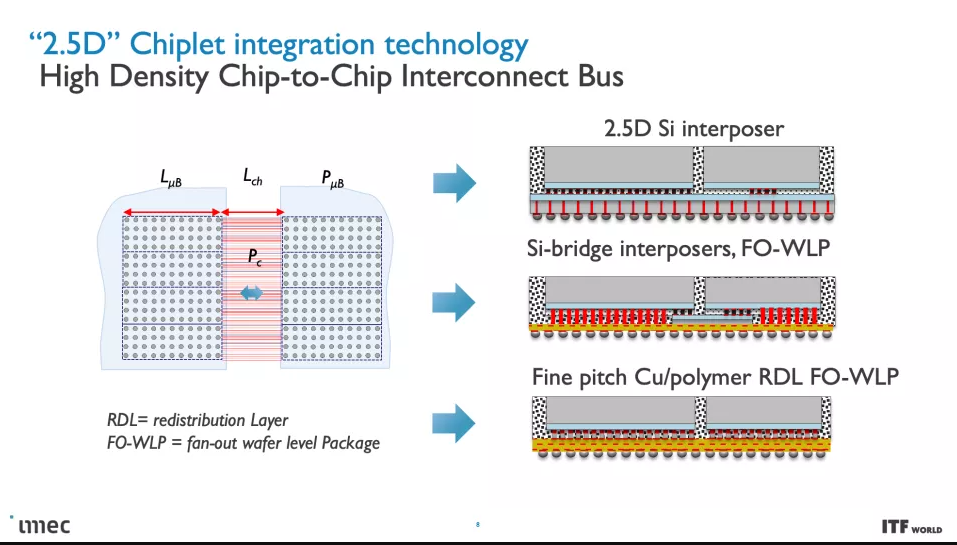
這些 CMOS 2.0 技術將利用 3D 堆疊技術(如晶圓到晶圓混合鍵合)來形成直接的芯片到芯片 3D 互連。
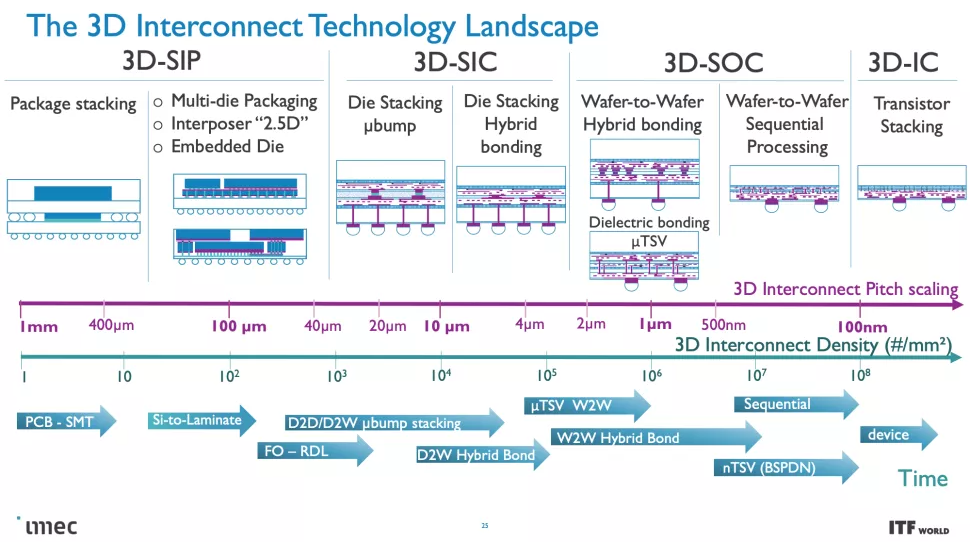
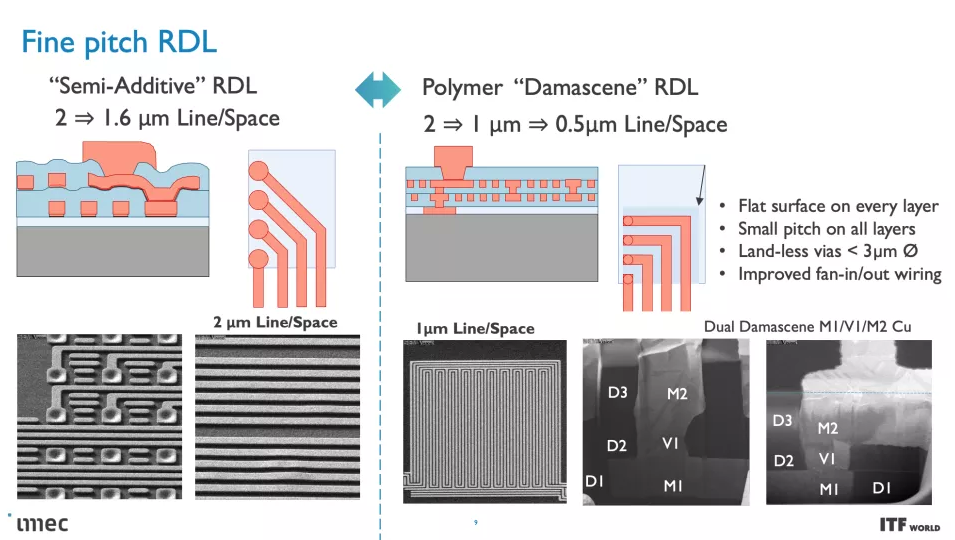
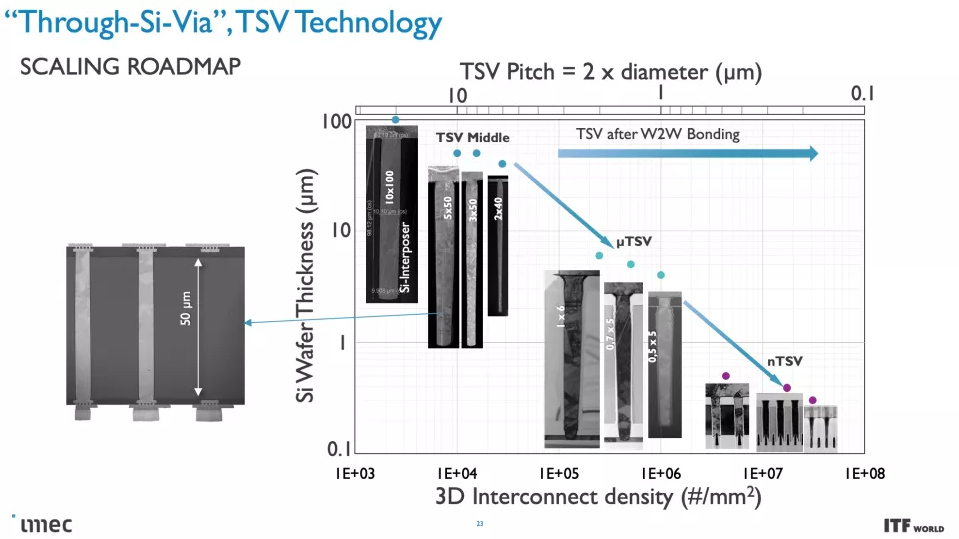
正如您在上面的專輯中看到的那樣,Imec 也有一個 3D-SOC 路線圖,概述了將 3D 設計結合在一起的互連的持續縮小,從而在未來實現更快、更密集的互連。這些進步將在未來幾年通過使用更新類型的互連和處理方法來實現。
審核編輯 :李倩
-
芯片
+關注
關注
455文章
50775瀏覽量
423437 -
3D
+關注
關注
9文章
2878瀏覽量
107514 -
晶體管
+關注
關注
77文章
9687瀏覽量
138142
原文標題:未來十年的芯片路線圖
文章出處:【微信號:IC學習,微信公眾號:IC學習】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
關于RISC-V學習路線圖推薦
未來10年智能傳感器怎么發展?美國發布最新MEMS路線圖

哪種嵌入式處理器架構將引領未來十年的發展?

2024學習生成式AI的最佳路線圖

三星電子公布2024年異構集成路線圖,LP Wide I/O移動內存即將面世
三星芯片制造技術路線圖出爐,意強化AI芯片代工市場競爭力
英飛凌為AI數據中心提供先進的高能效電源裝置產品路線圖

聯發科談未來十年的戰略布局
iPhone升級路線圖曝光:1年后才配12G內存,2026年有折疊屏
事關衛星物聯網!LoRaWAN 2027 發展路線圖重磅公布

安霸發布5nm制程的CV75S系列芯片,進一步拓寬AI SoC產品路線圖
美國公布3D半導體路線圖
納微半導體發布最新AI數據中心電源技術路線圖
納微半導體發布最新AI數據中心電源技術路線圖

未來十年的傳感器發展路線圖






 工商網監
工商網監
評論