 從這顆3nm AI芯片,看RISC-V用在高性能計算上
從這顆3nm AI芯片,看RISC-V用在高性能計算上
雖然我們此前就多番探討過現階段RISC-V嘗試入侵高性能計算市場的可能性,但起碼現在提到RISC-V,大部分人的第一反應仍然是嵌入式應用。 其實RISC-V在高性能市場的探索,能夠列舉的例證還是比較多樣的,不僅是這個市場前一陣比較熱的Veteran。這次我們來看看另外一家準備在RISC-V高性能計算領域一展拳腳、而且算是含著金湯匙出生的企業Tenstorrent。 這家公司現在的CEO是鼎鼎大名的Jim Keller;另外很多人應該知道,前一陣Raja Koduri從Intel離職后準備搞自己的初創公司,但與此同時他也是Tenstorrent的董事會成員之一;是不是感覺這公司還挺有花頭的?借著Tenstorrent的芯片路線圖及技術規劃,我們也能更進一步搞清楚RISC-V未來在HPC市場的可能性,以及AI芯片的發展趨勢。
01.RISC-V核的超寬微架構
最早聽說Tenstorrent,我們普遍說這是個做AI芯片的公司,但在去年的RISC-V Summit峰會上,Tenstorrent的CPU首席架構師Wei-han Lien特別談到了自家在做的CPU產品,核心代號Ascalon。這是個基于RISC-V指令集、亂序執行超標量CPU,著力于AI與服務器的高性能市場。 其實能看到這家公司出現包括Wei-han Lien和Jim Keller在內的名字,應該就很容易想見,CPU甚至已經是Tenstorrent的重頭戲了。
Jim Keller暫且不提,Wei-han Lien曾經在AMD、PA-Semi、蘋果都扮演芯片設計的重要角色。Tom's Hardware在報道文章中說,此人參與了蘋果A6、A7,甚至是M1 CPU微架構設計工作。 有興趣的同學可以去油管看一看Wei-han Lien在去年RISC-V Summit峰會上的主題演講。他談到兩個點給我們留下了比較深刻的印象,其一是推出CPU的出發點應當在于輔助AI芯片(所謂companion CPU)。所以Tenstorrent的自研架構CPU最重要職能就是“CPU for AI Computation”。 原因也很簡單,“很多人可能并沒有意識到在AI計算中,CPU扮演著非常非常重要的角色,尤其是在訓練(training)方面。”Lien說,“有人知道數據中心AI訓練過程中,CPU功耗多少嗎?不是10%,也不是20%,時間和功耗都超過了50%,包括CPU對數據的預處理和后處理。”后文會談到,Tenstorrent將Ascalon CPU核心集成到AI芯片上的方案。
其二是Lien談了為什么在指令集上選了RISC-V,而不是Arm。他說在2021年加入公司時,對ML處理器的companion CPU做評估,他去找了Arm詢問能否支持某種特定的數據類型,Arm的答復是不行。據說Arm對于這種程度的支持需要2年時間的內部討論和與合作伙伴之間的磋商。所以RISC-V很快成為新選擇——Tenstorrent的AI芯片選擇的companion CPU IP就來自SiFive。 后續Tenstorrent又需要性能更高的CPU,于是就決定自己設計,也就有了Ascalon。HWcooling前不久發布的評論文章認為,Ascalon的超寬架構設計和蘋果芯片很像。我們來看看Ascalon的一些設計大方向。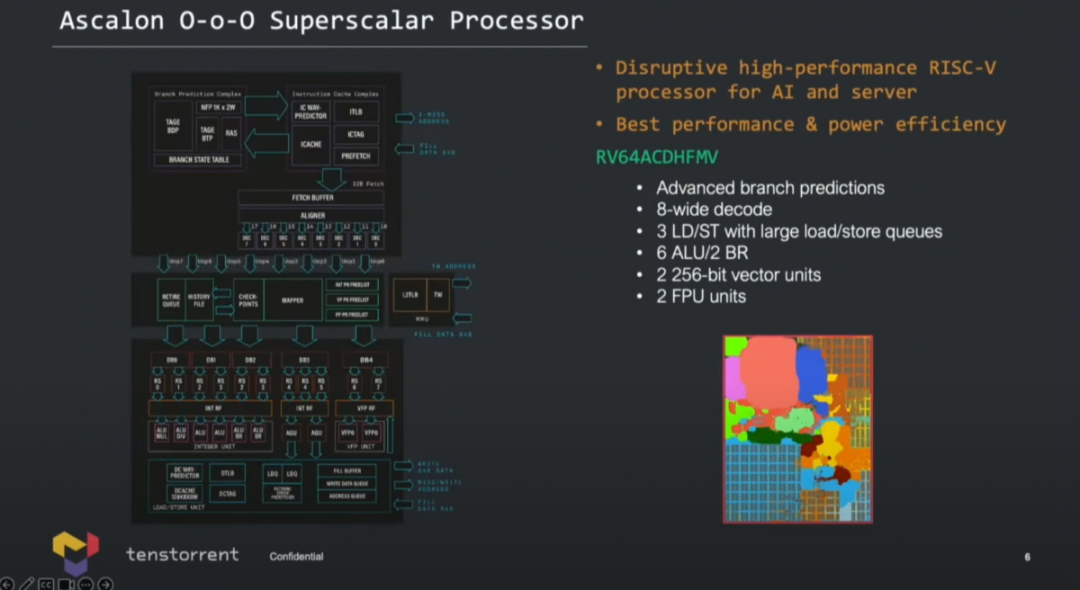
Tenstorrent的Ascalon核心具體為64bit的RV64ACDHFMV指令集架構,也就是說支持矢量指令集擴展——這在RISC-V世界來得算是比較遲的。 整體微架構前端8-wide解碼(之前在談Veteran的RISC-V超寬微架構時我們就提到了,其RISC-V核前端選配了8-wide取指),每周期能處理8個RISC-V指令——這個寬度和蘋果Firestorm的設計就類似了。
另外Ascalon架構有6個整數ALU,2個分支執行單元;而load/store三條管線還是比蘋果現行方案少了1個的(load/store分配情況未知),load/store隊列深度比較深,但具體是多少未知; 核心有2條FPU管線,用于浮點運算,并同時用作SIMD矢量單元——位寬256bit。其實就這個數字來看,SIMD吞吐仍未達到x86服務器平臺競品的程度——雖然光看紙面位寬和管線數字并不可靠。
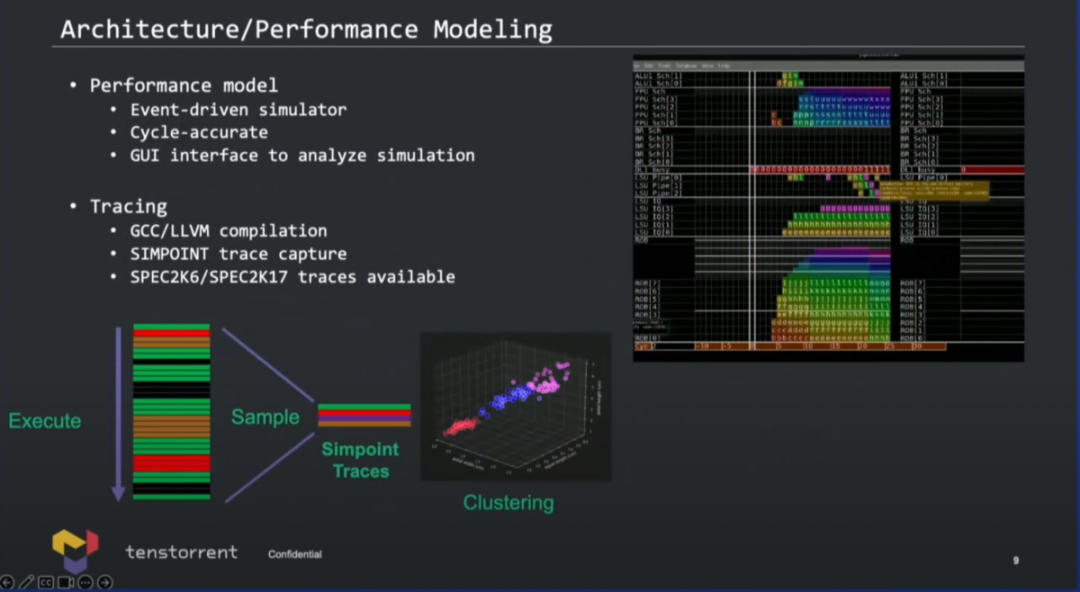
國外媒體還提到Tenstorrent采用了“先進的TAGE分支預測器”;cache容量情況未知,但“L1顯然會和蘋果的128KB, 8-way associativity類似”;“從指令cache取指應當為32bytes/cycle”;還有一些關鍵信息未知,例如ROB深度,有一定概率與蘋果芯片的思路相似,即比較高的亂序度。則核心的IPC理論上就會很理想,不需要太高的頻率。 演講中,Lien提到目前工程師已經在搞RTL和物理設計,右下角那張圖就是die photo。下面兩張圖給出了核心設計的難度、模塊化方案、如何做性能建模等等...本文不再做展開,有興趣的可以去看看演講視頻。
02.128核心的集群組成chiplet
實際上,根據decode解碼寬度,Tenstorrent準備了5個不同的CPU IP,面向不同的應用:是同一方案的不同規模實施。按照解碼寬度和性能,做了如下切分: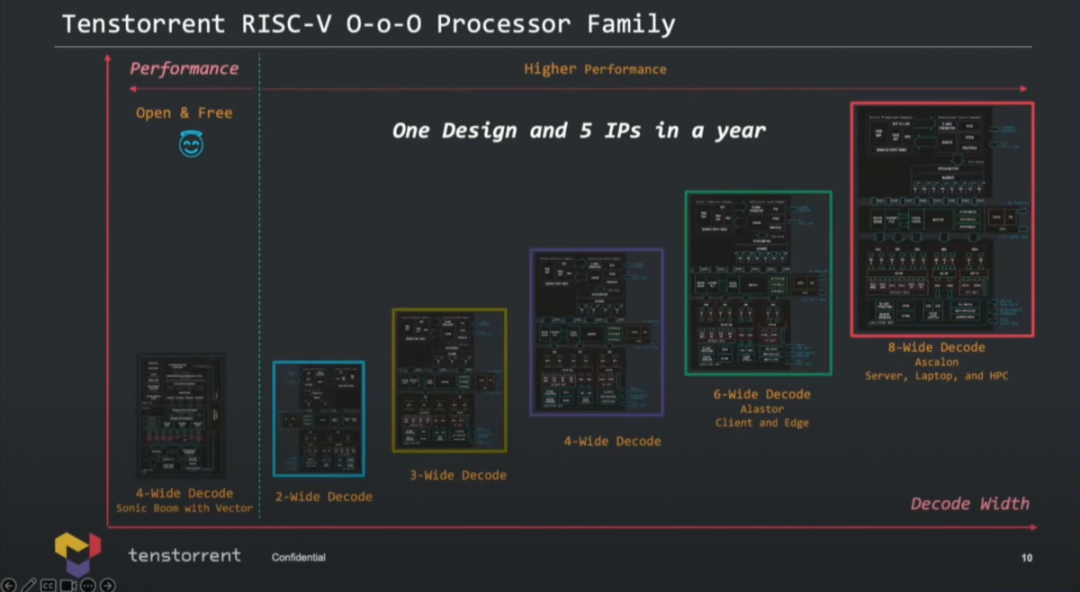
從2-wide解碼,到8-wide解碼,達成不同的PPA目標,也就面向不同的應用:涵蓋了邊緣設備、客戶端PC、HPC高性能計算等,似乎還有一些更基礎的應用。其實就核心層面就做這么多種設計,多少就有點IP公司的意思了——授權IP的確也是這家公司的盈利模式之一,后文會談到。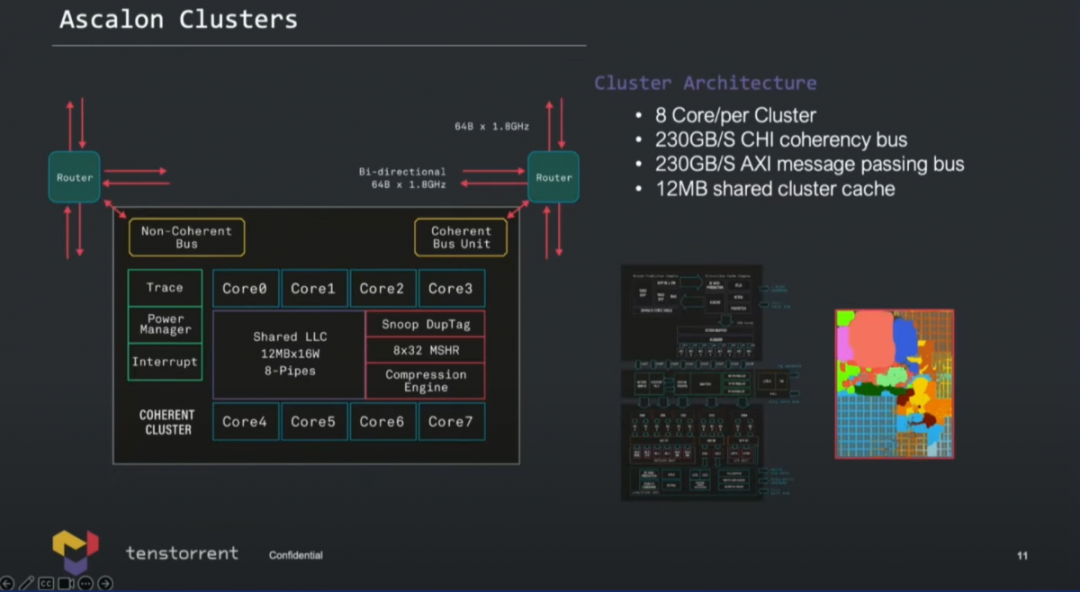
當Ascalon核心組成集群(cluster),多核方案形如上圖所示——一個集群可以配8個Ascalon核心(也就是最大8-wide的那個核心);集群內12MB共享集群cache;此外走向集群外部fabric的CHI coherency bus帶寬230GB/s;也有non-coherency bus,230GB/s,面向加速單元。 Lien特別提到,共享集群cache和scratchpad memory相關的存儲一致性方案,“不僅讓Ascalon核心非常適用于常規服務器的高性能核心,而且很適合用于AI計算”。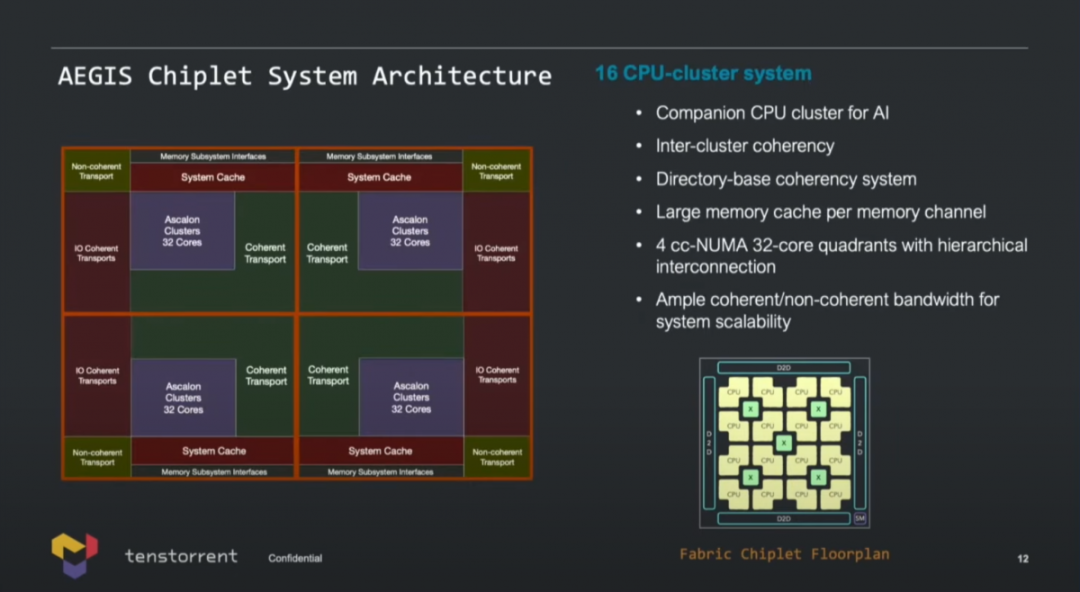
基于核心集群可以構成128個核心的設計(AEGIS Chiplet系統架構),作為AI的companion CPU集群。整個系統切分成了4塊,每一塊都是cc-NUMA(cache coherency non-uniform memory access)結構,Lien的原話是“fully coherency system”。
整顆chiplet本身配有die-to-die接口,ppt上只提到了針對可擴展性達成“充足的帶寬”。后面Lien在介紹Black Hole系統的時候,似乎有提到雙芯(dual-chip)的2TB/s die-to-die帶寬。 上述方案以IP的方式對外提供授權(包括RTL、hard macro,甚至GDS(Graphic Data Stream));另外從國外媒體的報道來看,Tenstorrent也出售chiplet、機器學習加速卡,或者包含CPU和ML加速單元的解決方案,而且還賣服務器系統。
就說這個業務模式還真是多樣化,作為IP供應商,又自己賣chiplet、賣芯片,還做系統,那是和不同層級的客戶達成了競爭關系的。不過這也不是咱要討論的重點。 實際上,就Tenstorrent出售的芯片和系統,上述CPU核心主要還是為AI服務的。
03.用作AI芯片的companion CPU
所以接下來我們談談Tenstorrent的AI芯片。過去2年,這家公司分別推出過Grayskull和Wormhole,詳細配置情況如下圖所示。這兩款AI處理器很自然地需要搭配主CPU,系統層面產品形態是作為板卡插在Tenstorrent自己的服務器里面的。在Wormhole這代產品上,4U的Nebula服務器內有32塊Wormhole板卡,6KW功率達成Int8的12 PFLOP算力。
不過這兩顆芯片不是我們要關注的重點,上圖中的Black Hole是這家公司的首款“CPU+ML解決方案”。注意看圖中,除了標記“T”的加速單元(名為Tensix),右邊還有標記為綠色“C”的CPU核心——這部分就是companion CPU。 不過Black Hole所用的14個CPU核心,用的是SiFive的X280——外圍的8通道GDDR6、1200Gb/s以太網連接、32 lane PCIe Gen 5就不多談了。今年Tenstorrent最新的PPT似乎更新了時間線,即上述所有產品均延后一年,所以Black Hole對應于2023年,Grendel對應于2024年。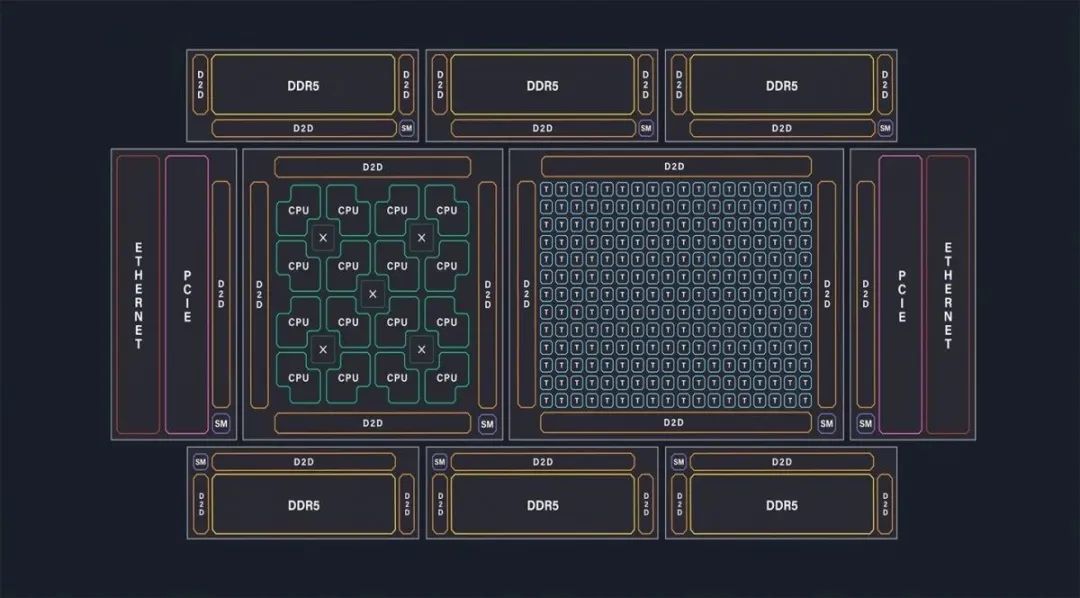
規劃中的Grendel就會用上前文提到的來自Tenstorrent自己的Ascalon核心,也就是自研RISC-V CPU,前端8-wide解碼那個。這顆芯片的AI和CPU chiplet都會選擇3nm工藝——這可能是目前已知最早的應用尖端制造工藝的RISC-V芯片。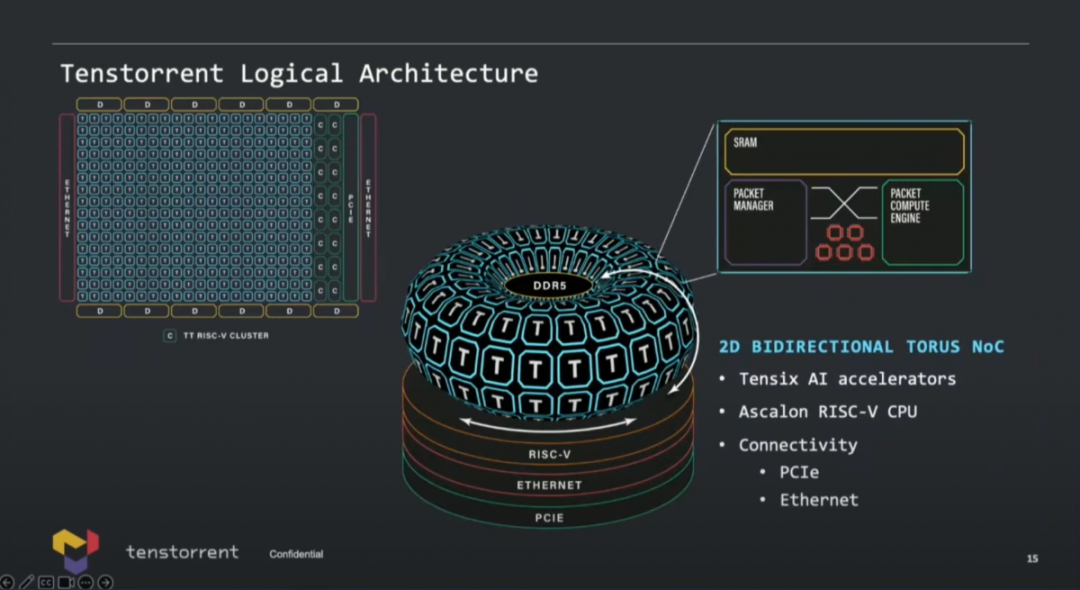
這張示意圖畫得還是挺有趣,AI加速單元是基于2D torus NoC互聯,連接DDR內存(不支持HBM),連接RISC-V CPU,以太網用于擴展,當然還有PCIe連接。值得一提的是,因為Tenstorrent的角色定位,可能最終產品選擇不同IP是存在靈活性的,比如說DRAM控制器、PHY之類的選配,據說Tenstorrent未來準備開發自己的內存控制器,現在用的還是三方的方案。
從今年Tenstorrent公布的框圖來看,多chiplet方案的確讓Grendel看起來就是個大規模芯片。Tom's Hardware在文章中說,實則基于業務需求以及經濟性考量,這顆芯片的AI chiplet部分(也就是那一堆Tensix單元)可以用3nm工藝,或者也可以用Black Hole的chiplet,甚至也可能CPU部分就繼續用SiFive X280。chiplet之間通訊如前所述可達成2TB/s的帶寬。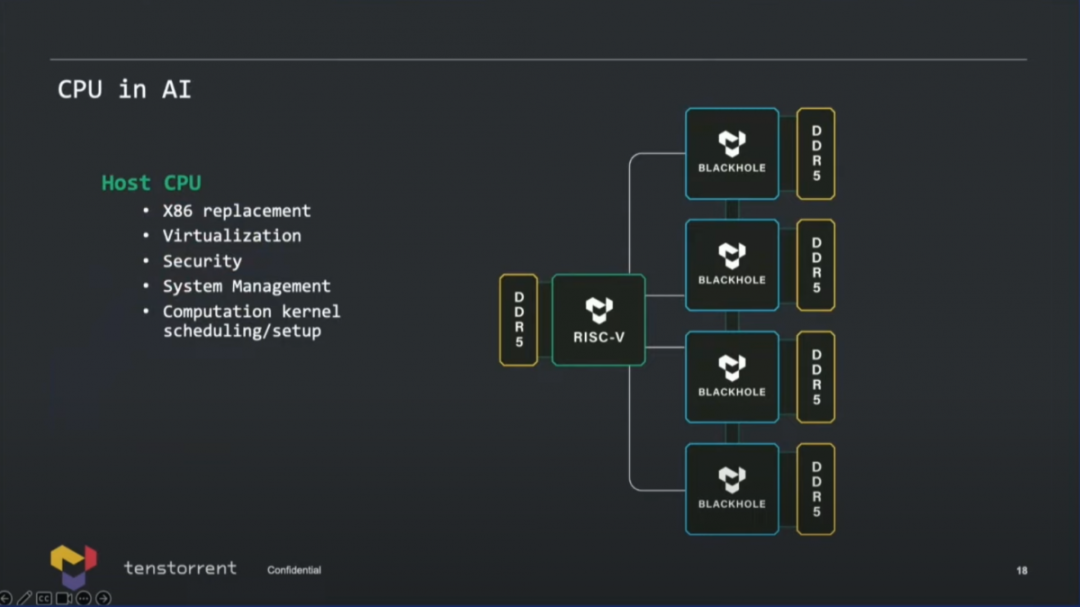
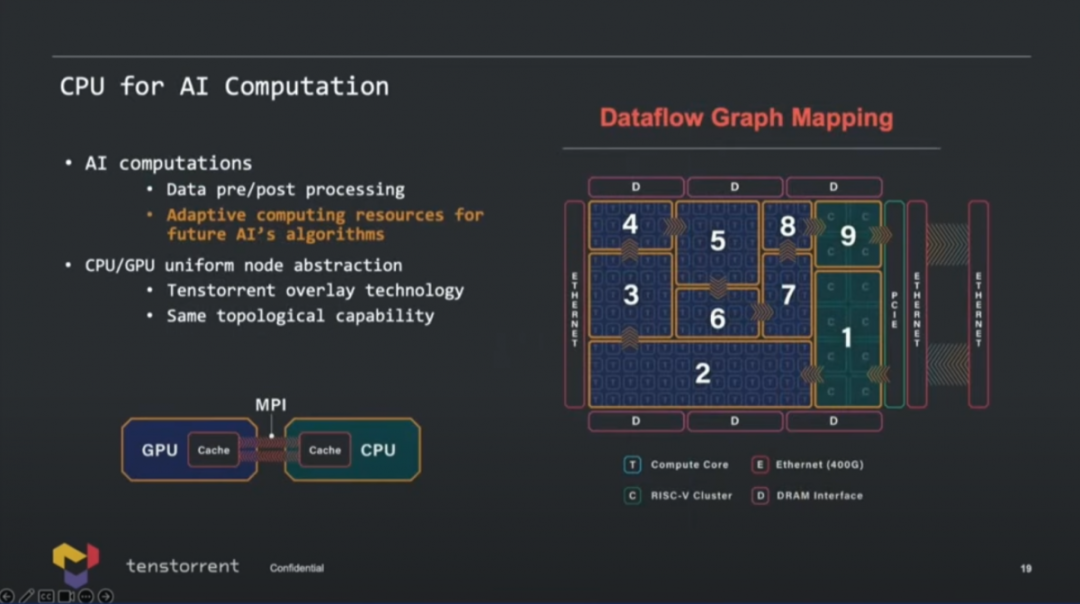
最后來談一下Ascalon或者其他RISC-V CPU用在這樣的AI芯片里,具體要干什么。實際上,Tenstorrent的CPU并不是單純用于AI流程控制的,而是可以替代x86的主CPU。其職能涵蓋了虛擬化、安全、系統管理、計算內核調度設置。 在用作輔助AI計算時,價值自然就包括了數據預處理,預防訓練數據overfeeding之類的問題;還有當CPU的矢量單元比較強悍時,對于整個處理器適配未來的算法會很有價值,或者說CPU是整顆芯片彈性化的體現方式之一。另外兩者之間的協同,也體現在了包括互連通訊與存儲等的CPU微架構設計里,那么compiler要在加速器和CPU之間做計算遷移也會很容易。
這都是Tenstorrent自己要做CPU,且基于RISC-V的原因所在。 軟件棧,以及系統搭建為服務器產品的部分這里就不談了,畢竟我們這篇文章其實就是看一看當RISC-V指令集用于HPC時,CPU架構大概會長什么樣的。不過其實在系統層面,Tenstorrent還考慮到大規模集群計算,需要做數據遷移勢必要用到DPU的問題——畢竟這已經是個共識了;Tenstorrent就說RISC-V在此也成為相當棒的選擇...
整體上,看一遍Tenstorrent的RISC-V CPU設計,仍有種對于具體應用而言,技術層面究竟選擇何種“指令集”都不是什么重點,而在于設計和實施方案的感覺。而阻斷x86和Arm成為其選擇的原因并不在于指令集本身,而在于RISC-V開源體現出的靈活性。這大概也更便于Jim Keller這類人去施展拳腳。雖然就外圍存儲、互聯的堆料看來,可能還是不能直接與英偉達硬碰硬,但靈活性和成本可能會是重要優勢項。
當然Grendel這顆3nm AI芯片畢竟也還沒有做出來,目前也還不清楚CPU的IP授權業務開展情況如何——其實就像前文提到的Tenstorrent的業務模式比較奇特,他們的上游供應商和下游客戶又同時是競爭對手。比如SiFive既為其CPU提供IP,同時后代產品又直接形成了競爭對手關系。所以業務開展如何還有待觀察。 不過那么多大佬入局,還是讓Tenstorrent這家公司在開局成為了惹人注目的焦點。起碼RISC-V未來成為市場競爭的主要角色之一已經不會再有疑問,而且絕對不光是低功耗和嵌入市場。
審核編輯:劉清
-
ARM處理器
+關注
關注
6文章
360瀏覽量
41722 -
HPC
+關注
關注
0文章
315瀏覽量
23754 -
RISC-V
+關注
關注
45文章
2270瀏覽量
46131 -
AI芯片
+關注
關注
17文章
1879瀏覽量
34992
原文標題:從這顆3nm AI芯片,看RISC-V用在高性能計算上
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
SiFive 推出高性能 Risc-V CPU 開發板 HiFive Premier P550

直播預約 |開源芯片系列講座第25期:RISC-V架構在高性能領域的進展與挑戰

RISC-V,即將進入應用的爆發期
希姆計算與開芯院簽署生態合作伙伴協議,共同打造高性能RISC-V AI大算力芯片

RISC-V+AI是大方向,國產芯片進展如何?
RISC-V適合什么樣的應用場景
RISC-V在中國的發展機遇有哪些場景?
國產RISC-V MCU推薦
Rivos完成2.5億美元A輪融資,用于研發AI工作負載 RISC-V計算加速
RISC-V廠商正在AI領域積極布局!






 工商網監
工商網監
評論