") PyTorch教程-13.4. 硬件
PyTorch教程-13.4. 硬件
構建具有出色性能的系統(tǒng)需要很好地理解算法和模型以捕獲問題的統(tǒng)計方面。同時,對底層硬件至少有一點了解也是必不可少的。當前部分不能替代有關硬件和系統(tǒng)設計的適當課程。相反,它可以作為理解為什么某些算法比其他算法更有效以及如何實現(xiàn)良好吞吐量的起點。一個好的設計可以很容易地產(chǎn)生一個數(shù)量級的差異,反過來,這可以在能夠訓練網(wǎng)絡(例如,在一周內(nèi))和根本不能(在 3 個月內(nèi),從而錯過最后期限)之間產(chǎn)生差異). 我們將從查看計算機開始。然后我們將放大以更仔細地查看 CPU 和 GPU。

圖 13.4.1每個程序員都應該知道的延遲數(shù)。
不耐煩的讀者可以通過 圖 13.4.1來解決。它摘自 Colin Scott 的 互動帖子 ,該帖子很好地概述了過去十年的進展。原始數(shù)字來自 Jeff Dean 2010 年在斯坦福的演講。下面的討論解釋了這些數(shù)字的一些基本原理,以及它們?nèi)绾沃笇覀冊O計算法。下面的討論是非常高層次和粗略的。它顯然不能替代適當?shù)恼n程,而只是為統(tǒng)計建模人員提供足夠的信息以做出適當?shù)脑O計決策。對于計算機體系結構的深入概述,我們建議讀者參閱 (Hennessy 和 Patterson,2011 年)或最近關于該主題的課程,例如Arste Asanovic的課程。
13.4.1。電腦
大多數(shù)深度學習研究人員和從業(yè)者都可以使用具有相當數(shù)量內(nèi)存、計算能力、某種形式的加速器(如 GPU)或其倍數(shù)的計算機。計算機由以下關鍵部件組成:
能夠執(zhí)行我們給它的程序(除了運行操作系統(tǒng)和許多其他東西)的處理器(也稱為 CPU),通常由 8 個或更多內(nèi)核組成。
內(nèi)存 (RAM),用于存儲和檢索計算結果,例如權重向量和激活以及訓練數(shù)據(jù)。
速度范圍為 1 GB/s 到 100 GB/s 的以太網(wǎng)網(wǎng)絡連接(有時是多個)。在高端服務器上可以找到更高級的互連。
用于將系統(tǒng)連接到一個或多個 GPU 的高速擴展總線 (PCIe)。服務器有多達 8 個加速器,通常以高級拓撲連接,而桌面系統(tǒng)有 1 個或 2 個,具體取決于用戶的預算和電源的大小。
耐用存儲設備,例如磁性硬盤驅(qū)動器、固態(tài)驅(qū)動器,在許多情況下使用 PCIe 總線連接。它提供訓練數(shù)據(jù)到系統(tǒng)的高效傳輸,并根據(jù)需要存儲中間檢查點。

圖 13.4.2計算機組件的連接性。
如圖13.4.2所示,大多數(shù)組件(網(wǎng)絡、GPU 和存儲)都通過 PCIe 總線連接到 CPU。它由多個直接連接到 CPU 的通道組成。例如,AMD 的 Threadripper 3 有 64 個 PCIe 4.0 通道,每個通道都能夠在兩個方向上進行 16 Gbit/s 的數(shù)據(jù)傳輸。內(nèi)存直連CPU,總帶寬高達100GB/s。
當我們在計算機上運行代碼時,我們需要將數(shù)據(jù)混洗到處理器(CPU 或 GPU)、執(zhí)行計算,然后將結果從處理器移回 RAM 和持久存儲。因此,為了獲得良好的性能,我們需要確保它可以無縫運行,而不會有任何一個系統(tǒng)成為主要瓶頸。例如,如果我們不能足夠快地加載圖像,處理器將無事可做。同樣,如果我們不能足夠快地將矩陣移動到 CPU(或 GPU),它的處理元素就會餓死。最后,如果我們想通過網(wǎng)絡同步多臺計算機,后者不應該減慢計算速度。一種選擇是交錯通信和計算。讓我們更詳細地了解各種組件。
13.4.2。記憶
最基本的內(nèi)存用于存儲需要隨時訪問的數(shù)據(jù)。目前 CPU RAM 通常是 DDR4類型,每個模塊提供 20–25 GB/s 的帶寬。每個模塊都有一個 64 位寬的總線。通常使用成對的內(nèi)存模塊來允許多個通道。CPU 有 2 到 4 個內(nèi)存通道,即它們有 4 0GB/s 到 100 GB/s 的峰值內(nèi)存帶寬。每個通道通常有兩個庫。例如 AMD 的 Zen 3 Threadripper 有 8 個插槽。
盡管這些數(shù)字令人印象深刻,但它們確實只說明了部分情況。當我們想從內(nèi)存中讀取一部分時,我們首先需要告訴內(nèi)存模塊在哪里可以找到信息。也就是說,我們首先需要將地址發(fā)送到RAM。完成此操作后,我們可以選擇只讀取單個 64 位記錄或一長串記錄。后者稱為突發(fā)讀取. 簡而言之,向內(nèi)存發(fā)送地址并設置傳輸大約需要 100 ns(具體取決于所使用的內(nèi)存芯片的具體時序系數(shù)),隨后的每次傳輸僅需 0.2 ns。簡而言之,第一次閱讀的成本是后續(xù)閱讀的 500 倍!請注意,我們每秒最多可以執(zhí)行 10,000,000 次隨機讀取。這表明我們盡可能避免隨機內(nèi)存訪問,而是使用突發(fā)讀取(和寫入)。
當我們考慮到我們有多家銀行時,事情就有點復雜了。每個銀行都可以在很大程度上獨立地讀取內(nèi)存。這意味著兩件事。一方面,隨機讀取的有效數(shù)量高達 4 倍,前提是它們均勻分布在內(nèi)存中。這也意味著執(zhí)行隨機讀取仍然是一個壞主意,因為突發(fā)讀取也快了 4 倍。另一方面,由于內(nèi)存對齊到 64 位邊界,最好將任何數(shù)據(jù)結構對齊到相同的邊界。 當設置了適當?shù)臉酥緯r,編譯器幾乎會 自動執(zhí)行此操作。我們鼓勵好奇的讀者復習一下關于 DRAM 的講座,例如Zeshan Chishti的講座。
GPU 內(nèi)存需要滿足更高的帶寬要求,因為它們的處理元素比 CPU 多得多。總的來說,有兩種選擇可以解決這些問題。首先是使內(nèi)存總線顯著變寬。例如,NVIDIA 的 RTX 2080 Ti 具有 352 位寬的總線。這允許同時傳輸更多信息。其次,GPU 使用特定的高性能內(nèi)存。消費級設備,例如 NVIDIA 的 RTX 和 Titan 系列通常使用GDDR6 總帶寬超過 500 GB/s 的芯片。另一種方法是使用 HBM(高帶寬內(nèi)存)模塊。它們使用非常不同的接口,并直接與專用硅晶圓上的 GPU 連接。這使得它們非常昂貴,而且它們的使用通常僅限于高端服務器芯片,例如 NVIDIA Volta V100 系列加速器。不出所料,GPU 內(nèi)存通常比 CPU 內(nèi)存小得多,因為前者的成本較高。就我們的目的而言,它們的性能特征大體上相似,只是速度快得多。出于本書的目的,我們可以安全地忽略細節(jié)。它們僅在調(diào)整 GPU 內(nèi)核以實現(xiàn)高吞吐量時才重要。
13.4.3。貯存
我們看到 RAM 的一些關鍵特性是帶寬和 延遲。存儲設備也是如此,只是差異可能更加極端。
13.4.3.1。硬盤驅(qū)動器
硬盤驅(qū)動器(HDD) 已經(jīng)使用了半個多世紀。簡而言之,它們包含許多帶有磁頭的旋轉(zhuǎn)盤片,可以定位以在任何給定軌道上讀取或?qū)懭搿8叨舜疟P在 9 個盤片上最多可容納 16 TB。HDD 的主要優(yōu)點之一是它們相對便宜。它們的眾多缺點之一是它們通常的災難性故障模式和相對較高的讀取延遲。
要理解后者,請考慮 HDD 以大約 7,200 RPM(每分鐘轉(zhuǎn)數(shù))旋轉(zhuǎn)的事實。如果它們快得多,它們就會因施加在盤片上的離心力而破碎。在訪問磁盤上的特定扇區(qū)時,這有一個主要的缺點:我們需要等到盤片旋轉(zhuǎn)到位(我們可以移動磁頭但不能加速實際磁盤)。因此,在請求的數(shù)據(jù)可用之前,它可能需要 8 毫秒以上的時間。一種常見的表達方式是 HDD 可以以大約 100 IOP(每秒輸入/輸出操作)的速度運行。這個數(shù)字在過去二十年中基本保持不變。更糟糕的是,增加帶寬同樣困難(大約為 100–200 MB/s)。畢竟,每個磁頭都讀取一條比特軌道,因此,比特率僅與信息密度的平方根成比例。因此,HDD 正迅速降級為非常大的數(shù)據(jù)集的歸檔存儲和低級存儲。
13.4.3.2。固態(tài)硬盤
固態(tài)硬盤 (SSD) 使用閃存來持久存儲信息。這允許更快地訪問存儲的記錄。現(xiàn)代 SSD 可以以 100,000 到 500,000 IOP 的速度運行,即比 HDD 快 3 個數(shù)量級。此外,它們的帶寬可以達到 1–3GB/s,即比 HDD 快一個數(shù)量級。這些改進聽起來好得令人難以置信。實際上,由于 SSD 的設計方式,它們具有以下警告。
SSD 以塊(256 KB 或更大)的形式存儲信息。它們只能作為一個整體來寫,這會花費大量時間。因此,SSD 上的按位隨機寫入性能非常差。同樣,寫入數(shù)據(jù)通常會花費大量時間,因為必須讀取、擦除塊,然后用新信息重寫。到目前為止,SSD 控制器和固件已經(jīng)開發(fā)出算法來緩解這種情況。盡管如此,寫入速度可能會慢得多,尤其是對于 QLC(四級單元)SSD。提高性能的關鍵是維護一個 操作隊列,盡可能在大塊中優(yōu)先讀取和寫入。
SSD 中的存儲單元磨損相對較快(通常在幾千次寫入后就已經(jīng)磨損)。磨損級保護算法能夠?qū)⑼嘶瘋鞑サ皆S多單元上。也就是說,不建議將 SSD 用于交換文件或日志文件的大量聚合。
最后,帶寬的大幅增加迫使計算機設計人員將 SSD 直接連接到 PCIe 總線。能夠處理此問題的驅(qū)動器稱為 NVMe(增強型非易失性內(nèi)存),最多可使用 4 個 PCIe 通道。在 PCIe 4.0 上這相當于高達 8GB/s。
13.4.3.3。云儲存
云存儲提供可配置的性能范圍。也就是說,存儲分配給虛擬機是動態(tài)的,無論是數(shù)量還是速度,都由用戶選擇。我們建議用戶在延遲太高時增加 IOP 的配置數(shù)量,例如,在使用許多小記錄進行訓練期間。
13.4.4。處理器
中央處理器 (CPU) 是任何計算機的核心部件。它們由許多關鍵組件組成:能夠執(zhí)行機器代碼的處理器內(nèi)核、連接它們的總線(特定拓撲在處理器型號、代數(shù)和供應商之間有很大差異),以及允許更高帶寬和更低延遲內(nèi)存的緩存訪問比從主存儲器讀取可能的訪問。最后,幾乎所有現(xiàn)代 CPU 都包含矢量處理單元,以輔助高性能線性代數(shù)和卷積,因為它們在媒體處理和機器學習中很常見。

圖 13.4.3 Intel Skylake 消費者四核 CPU。
圖 13.4.3描繪了 Intel Skylake 消費級四核 CPU。它有一個集成的 GPU、緩存和連接四個內(nèi)核的環(huán)形總線。以太網(wǎng)、WiFi、藍牙、SSD 控制器和 USB 等外圍設備要么是芯片組的一部分,要么直接連接 (PCIe) 到 CPU。
13.4.4.1。微架構
每個處理器內(nèi)核都包含一組相當復雜的組件。雖然各代和供應商之間的細節(jié)有所不同,但基本功能幾乎是標準的。前端加載指令并嘗試預測將采用哪條路徑(例如,用于控制流)。然后將指令從匯編代碼解碼為微指令。匯編代碼通常不是處理器執(zhí)行的最低級別代碼。相反,復雜的指令可以被解碼成一組更底層的操作。這些然后由實際執(zhí)行核心處理。通常后者能夠同時執(zhí)行許多操作。例如, 圖 13.4.4的 ARM Cortex A77 核心能夠同時執(zhí)行多達 8 個操作。

圖 13.4.4 ARM Cortex A77 微架構。
這意味著高效的程序可能能夠在每個時鐘周期執(zhí)行多條指令,前提是它們可以獨立執(zhí)行。并非所有單位生而平等。一些專注于整數(shù)指令,而另一些則針對浮點性能進行了優(yōu)化。為了增加吞吐量,處理器還可以在分支指令中同時遵循多個代碼路徑,然后丟棄未采用的分支的結果。這就是為什么分支預測單元(在前端)很重要,以至于只追求最有希望的路徑。
13.4.4.2。矢量化
深度學習非常需要計算。因此,要使 CPU 適合機器學習,需要在一個時鐘周期內(nèi)執(zhí)行許多操作。這是通過矢量單元實現(xiàn)的。它們有不同的名稱:在 ARM 上它們被稱為 NEON,在 x86 上它們(最近一代)被稱為 AVX2 單元。一個共同點是它們能夠執(zhí)行 SIMD(單指令多數(shù)據(jù))操作。圖 13.4.5顯示了在 ARM 上如何在一個時鐘周期內(nèi)添加 8 個短整數(shù)。

圖 13.4.5 128 位 NEON 矢量化。
根據(jù)體系結構的選擇,此類寄存器的長度可達 512 位,最多可組合 64 對數(shù)字。例如,我們可能將兩個數(shù)字相乘并將它們與第三個數(shù)字相加,這也稱為融合乘加。英特爾的 OpenVino使用這些在服務器級 CPU 上實現(xiàn)深度學習的可觀吞吐量。但請注意,這個數(shù)字與 GPU 能夠?qū)崿F(xiàn)的目標相比完全相形見絀。例如,NVIDIA 的 RTX 2080 Ti 擁有 4,352 個 CUDA 核心,每個核心都可以隨時處理這樣的操作。
13.4.4.3。緩存
考慮以下情況:如上圖 13.4.3所示,我們有一個普通的 4 核 CPU 核,運行頻率為 2 GHz。此外,假設我們的 IPC(每時鐘指令數(shù))計數(shù)為 1,并且這些單元啟用了 256 位寬度的 AVX2。我們進一步假設至少有一個用于 AVX2 操作的寄存器需要從內(nèi)存中檢索。這意味著 CPU 消耗 4×256bit=128bytes每個時鐘周期的數(shù)據(jù)。除非我們能夠轉(zhuǎn)移 2×109×128=256×109每秒向處理器發(fā)送的字節(jié)數(shù),處理元素將餓死。不幸的是,這種芯片的內(nèi)存接口僅支持 20–40 GB/s 的數(shù)據(jù)傳輸,即低一個數(shù)量級。解決方法是盡可能避免從內(nèi)存加載新數(shù)據(jù),而是將其緩存在 CPU 本地。這是緩存派上用場的地方。通常使用以下名稱或概念:
寄存器嚴格來說不是緩存的一部分。他們幫助階段性指示。也就是說,CPU 寄存器是 CPU 可以以時鐘速度訪問而不會造成任何延遲損失的內(nèi)存位置。CPU 有幾十個寄存器。有效地使用寄存器取決于編譯器(或程序員)。例如 C 編程語言有一個register關鍵字。
L1 緩存是抵御高內(nèi)存帶寬需求的第一道防線。L1 緩存很小(典型大小可能為 32–64 KB)并且通常分為數(shù)據(jù)和指令緩存。當在一級緩存中找到數(shù)據(jù)時,訪問速度非常快。如果在那里找不到它們,搜索將沿著緩存層次結構向下進行。
二級緩存是下一站。根據(jù)體系結構設計和處理器大小,它們可能是獨占的。它們可能只能由給定的核心訪問或在多個核心之間共享。L2 緩存比 L1 更大(通常每個內(nèi)核 256–512 KB)并且更慢。此外,要訪問 L2 中的某些內(nèi)容,我們首先需要檢查以了解數(shù)據(jù)不在 L1 中,這會增加少量的額外延遲。
L3 緩存在多個內(nèi)核之間共享,并且可能非常大。AMD 的 Epyc 3 服務器 CPU 擁有分布在多個小芯片上的高達 256 MB 的緩存。更典型的數(shù)字在 4–8 MB 范圍內(nèi)。
預測接下來需要哪些存儲元件是芯片設計中的關鍵優(yōu)化參數(shù)之一。例如,建議以正向遍歷內(nèi)存,因為大多數(shù)緩存算法將嘗試提前讀取而不是向后讀取。同樣,將內(nèi)存訪問模式保持在本地是提高性能的好方法。
添加緩存是一把雙刃劍。一方面,它們確保處理器內(nèi)核不會缺少數(shù)據(jù)。同時,它們增加了芯片尺寸,占用了本來可以用于提高處理能力的面積。此外,高速緩存未命中的代價可能很高。考慮最壞的情況,錯誤共享,如圖13.4.6所示。當處理器 1 上的線程請求數(shù)據(jù)時,內(nèi)存位置緩存在處理器 0 上。為了獲得它,處理器 0 需要停止它正在做的事情,將信息寫回主內(nèi)存,然后讓處理器 1 從內(nèi)存中讀取它。在此操作期間,兩個處理器都在等待。這樣的代碼很可能運行 得更慢與高效的單處理器實現(xiàn)相比,在多個處理器上。這是緩存大小存在實際限制(除了它們的物理大小)的另一個原因。

圖 13.4.6虛假共享(圖片由英特爾提供)。
13.4.5。GPU 和其他加速器
可以毫不夸張地說,如果沒有 GPU,深度學習就不會成功。出于同樣的原因,GPU 制造商的財富因深度學習而大幅增加的說法也十分合理。硬件和算法的這種共同進化導致了這樣一種情況,即無論好壞,深度學習都是更可取的統(tǒng)計建模范例。因此,有必要了解 GPU 和相關加速器(如 TPU)的具體優(yōu)勢 (Jouppi等人,2017 年)。
值得注意的是在實踐中經(jīng)常出現(xiàn)的區(qū)別:加速器針對訓練或推理進行了優(yōu)化。對于后者,我們只需要計算網(wǎng)絡中的前向傳播。反向傳播不需要存儲中間數(shù)據(jù)。此外,我們可能不需要非常精確的計算(FP16 或 INT8 通常就足夠了)。另一方面,在訓練期間,所有中間結果都需要存儲以計算梯度。此外,累積梯度需要更高的精度以避免數(shù)值下溢(或溢出)。這意味著 FP16(或與 FP32 的混合精度)是最低要求。所有這些都需要更快、更大的內(nèi)存(HBM2 與 GDDR6)和更強的處理能力。例如,英偉達的 圖靈 T4 GPU 針對推理進行了優(yōu)化,而 V100 GPU 更適合訓練。
回憶一下圖 13.4.5中所示的矢量化。將矢量單元添加到處理器內(nèi)核使我們能夠顯著提高吞吐量。例如,在圖 13.4.5的示例中,我們能夠同時執(zhí)行 16 個操作。首先,如果我們添加不僅優(yōu)化向量之間的操作而且優(yōu)化矩陣之間的操作會怎樣?這種策略導致了張量核(稍后將介紹)。其次,如果我們添加更多的內(nèi)核會怎樣?簡而言之,這兩種策略總結了 GPU 中的設計決策。 圖 13.4.7給出基本處理塊的概述。它包含 16 個整數(shù)和 16 個浮點單元。除此之外,兩個張量核心可加速一小部分與深度學習相關的附加操作。每個流式多處理器由四個這樣的塊組成。
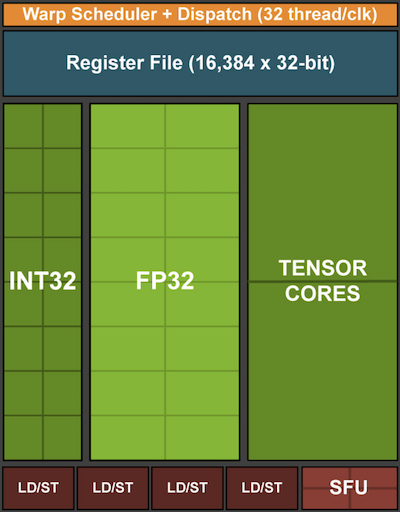
圖 13.4.7 NVIDIA 圖靈處理塊(圖片由 NVIDIA 提供)。
接下來,將 12 個流式多處理器組合成圖形處理集群,組成高端 TU102 處理器。充足的內(nèi)存通道和 L2 緩存補充了設置。圖 13.4.8 有相關的細節(jié)。設計這種設備的原因之一是可以根據(jù)需要添加或刪除單個塊,以允許更緊湊的芯片并處理良率問題(有故障的模塊可能不會被激活)。幸運的是,在 CUDA 和框架代碼層下,對此類設備進行編程對于隨意的深度學習研究人員來說是隱藏的。特別是,如果有可用資源,多個程序可能會在 GPU 上同時執(zhí)行。盡管如此,了解設備的局限性以避免選擇不適合設備內(nèi)存的模型是值得的。

圖 13.4.8 NVIDIA 圖靈架構(圖片由 NVIDIA 提供)
最后一個值得更詳細地提及的方面是張量核。它們是最近趨勢的一個例子,即添加對深度學習特別有效的更優(yōu)化電路。例如,TPU 添加了一個脈動陣列( Kung, 1988 )用于快速矩陣乘法。那里的設計是為了支持極少數(shù)(第一代 TPU 中的一個)大型操作。張量核在另一端。它們針對涉及之間的小型操作進行了優(yōu)化4×4和16×16 矩陣,取決于它們的數(shù)值精度。 圖 13.4.9給出了優(yōu)化的概覽。
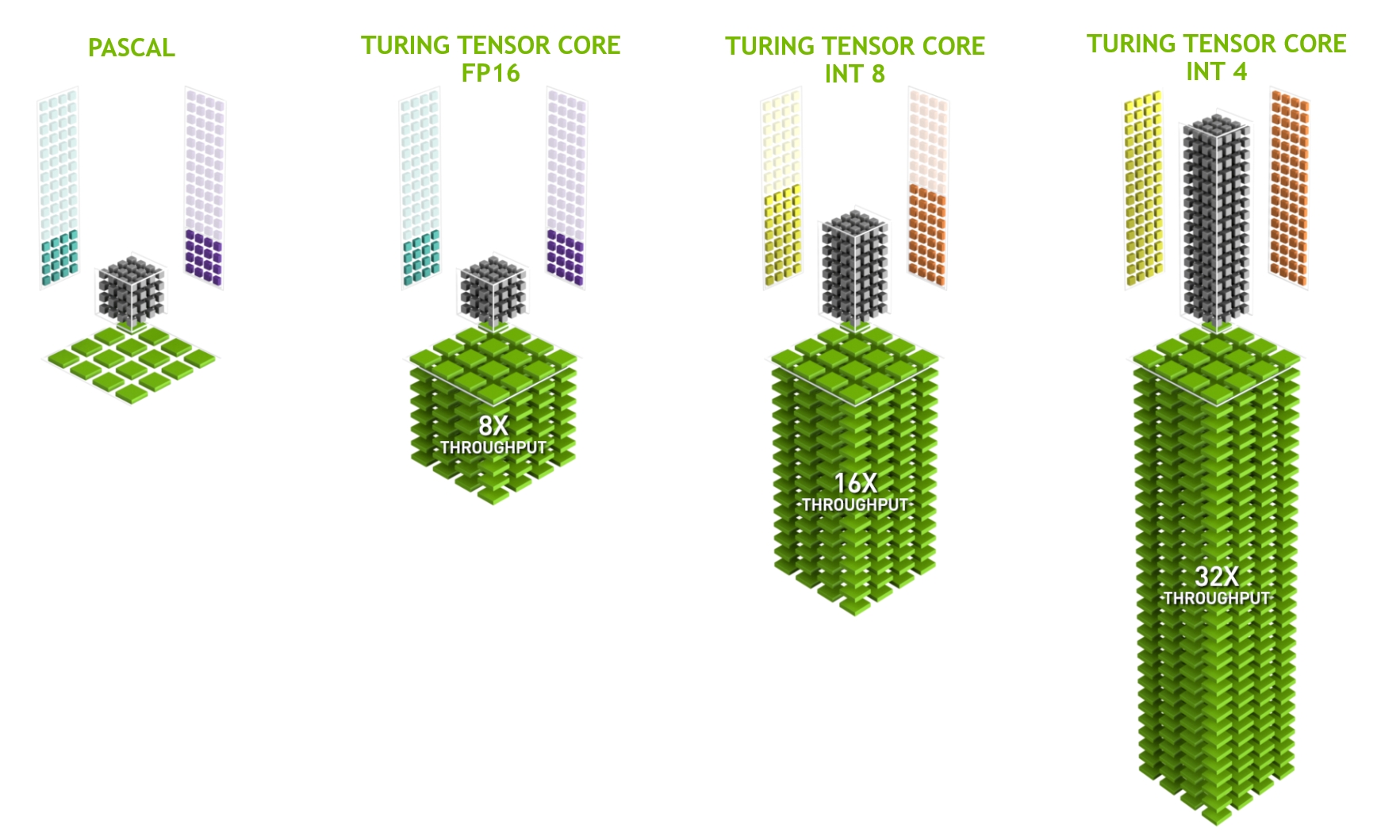
圖 13.4.9圖靈中的 NVIDIA 張量核心(圖片由 NVIDIA 提供)。
顯然,在優(yōu)化計算時,我們最終會做出某些妥協(xié)。其中之一是 GPU 不太擅長處理中斷和稀疏數(shù)據(jù)。雖然也有明顯的例外,例如 Gunrock (Wang等人,2016 年),但稀疏矩陣和向量的訪問模式并不適合 GPU 擅長的高帶寬突發(fā)讀取操作。匹配這兩個目標是一個活躍的研究領域。參見例如DGL,這是一個為圖形深度學習而調(diào)整的庫。
13.4.6。網(wǎng)絡和總線
每當單個設備不足以進行優(yōu)化時,我們需要將數(shù)據(jù)傳輸?shù)剿驈乃鼈鬏敂?shù)據(jù)以同步處理。這就是網(wǎng)絡和總線派上用場的地方。我們有許多設計參數(shù):帶寬、成本、距離和靈活性。一方面,我們的 WiFi 范圍很廣,非常易于使用(畢竟沒有電線),價格便宜,但它提供的帶寬和延遲相對一般。頭腦正常的機器學習研究人員不會使用它來構建服務器集群。在下文中,我們將重點關注適合深度學習的互連。
PCIe是一種專用總線,用于每條通道的超高帶寬點對點連接(在 16 通道插槽中的 PCIe 4.0 上高達 32 GB/s)。延遲大約為個位數(shù)微秒 (5 μs)。PCIe 鏈接很寶貴。處理器數(shù)量有限:AMD 的 EPYC 3 有 128 條通道,Intel 的 Xeon 每個芯片最多有 48 條通道;在桌面級 CPU 上,數(shù)字分別為 20 (Ryzen 9) 和 16 (Core i9)。由于 GPU 通常有 16 條通道,這限制了可以全帶寬連接到 CPU 的 GPU 數(shù)量。畢竟,它們需要與存儲和以太網(wǎng)等其他高帶寬外圍設備共享鏈路。就像 RAM 訪問一樣,由于減少了數(shù)據(jù)包開銷,大容量傳輸更可取。
以太網(wǎng)是最常用的計算機連接方式。雖然它比 PCIe 慢得多,但它非常便宜且安裝靈活,并且覆蓋的距離更長。低檔服務器的典型帶寬為 1 GBit/s。高端設備(例如,云中的C5 實例)提供 10 到 100 GBit/s 的帶寬。與之前的所有情況一樣,數(shù)據(jù)傳輸具有顯著的開銷。請注意,我們幾乎從不直接使用原始以太網(wǎng),而是使用在物理互連之上執(zhí)行的協(xié)議(例如 UDP 或 TCP/IP)。這進一步增加了開銷。與 PCIe 一樣,以太網(wǎng)旨在連接兩個設備,例如計算機和交換機。
交換機允許我們以任意一對設備可以同時執(zhí)行(通常是全帶寬)點對點連接的方式連接多個設備。例如,以太網(wǎng)交換機可能以高截面帶寬連接 40 臺服務器。請注意,交換機并不是傳統(tǒng)計算機網(wǎng)絡所獨有的。甚至可以 切換PCIe 通道。這發(fā)生在例如將大量 GPU 連接到主機處理器時,如P2 實例的情況。
在超高帶寬互連方面,NVLink是 PCIe 的替代方案。它提供每條鏈路高達 300 Gbit/s 的數(shù)據(jù)傳輸速率。服務器 GPU (Volta V100) 有六個鏈接,而消費級 GPU (RTX 2080 Ti) 只有一個鏈接,以降低的 100 Gbit/s 速率運行。我們建議使用 NCCL來實現(xiàn) GPU 之間的高數(shù)據(jù)傳輸。
13.4.7。更多延遲數(shù)字
第 13.4.7 節(jié)和 第 13.4.7 節(jié)中的摘要來自Eliot Eshelman,他將數(shù)字的更新版本維護為GitHub 要點。
| 行動 | 時間 | 筆記 |
|---|---|---|
| 一級緩存引用/命中 | 1.5納秒 | 4個周期 |
| 浮點加法/乘法/FMA | 1.5納秒 | 4個周期 |
| L2 緩存引用/命中 | 5納秒 | 12 ~ 17 周期 |
| 分支預測錯誤 | 6納秒 | 15 ~ 20 次循環(huán) |
| L3 緩存命中(非共享緩存) | 16納秒 | 42個周期 |
| L3緩存命中(在另一個核心共享) | 25納秒 | 65個周期 |
| 互斥鎖定/解鎖 | 25納秒 | |
| L3緩存命中(在另一個核心修改) | 29納秒 | 75個周期 |
| L3 緩存命中(在遠程 CPU 插槽上) | 40納秒 | 100 ~ 300 次循環(huán) (40 ~ 116 ns) |
| QPI 跳到另一個 CPU(每跳) | 40納秒 | |
| 64MB 內(nèi)存參考。(本地 CPU) | 46納秒 | Broadwell E5-2690v4 上的 TinyMemBench |
| 64MB 內(nèi)存參考。(遠程 CPU) | 70 納秒 | Broadwell E5-2690v4 上的 TinyMemBench |
| 256MB 內(nèi)存參考。(本地 CPU) | 75 納秒 | Broadwell E5-2690v4 上的 TinyMemBench |
| 英特爾傲騰隨機寫入 | 94納秒 | UCSD 非易失性系統(tǒng)實驗室 |
| 256MB 內(nèi)存參考。(遠程 CPU) | 120納秒 | Broadwell E5-2690v4 上的 TinyMemBench |
| 英特爾傲騰隨機讀取 | 305納秒 | UCSD 非易失性系統(tǒng)實驗室 |
| 通過 100 Gbps HPC 結構發(fā)送 4KB | 1微秒 | 基于 Intel Omni-Path 的 MVAPICH2 |
| 使用 Google Snappy 壓縮 1KB | 3微秒 | |
| 通過 10 Gbps 以太網(wǎng)發(fā)送 4KB | 10微秒 | |
| 隨機寫入 4KB 到 NVMe SSD | 30微秒 | DC P3608 NVMe SSD(QOS 99%為500μs) |
| 向/從 NVLink GPU 傳輸 1MB | 30微秒 | 在 NVIDIA 40GB NVLink 上約為 33GB/s |
| 向/從 PCI-E GPU 傳輸 1MB | 80微秒 | 在 PCIe 3.0 x16 鏈路上約為 12GB/s |
| 從 NVMe SSD 隨機讀取 4KB | 120微秒 | DC P3608 NVMe SSD (QOS 99%) |
| 從 NVMe SSD 順序讀取 1MB | 208微秒 | ~4.8GB/s DC P3608 NVMe SSD |
| 隨機寫入 4KB 到 SATA SSD | 500微秒 | DC S3510 SATA 固態(tài)硬盤 (QOS 99.9%) |
| 從 SATA SSD 隨機讀取 4KB | 500微秒 | DC S3510 SATA 固態(tài)硬盤 (QOS 99.9%) |
| 同一數(shù)據(jù)中心內(nèi)的往返 | 500微秒 | 單向 ping 約為 250μs |
| 從 SATA SSD 順序讀取 1MB | 2 毫秒 | ~550MB/s DC S3510 SATA SSD |
| 從磁盤順序讀取 1MB | 5 毫秒 | ~200MB/s 服務器硬盤 |
| 隨機磁盤訪問(查找+旋轉(zhuǎn)) | 10 毫秒 | |
| 發(fā)包 CA->Netherlands->CA | 150 毫秒 |
表:常見的延遲數(shù)字。
| 行動 | 時間 | 筆記 |
|---|---|---|
| GPU 共享內(nèi)存訪問 | 30納秒 | 30~90 個周期(bank 沖突增加延遲) |
| GPU 全局內(nèi)存訪問 | 200納秒 | 200~800次循環(huán) |
| 在 GPU 上啟動 CUDA 內(nèi)核 | 10微秒 | 主機 CPU 指示 GPU 啟動內(nèi)核 |
| 向/從 NVLink GPU 傳輸 1MB | 30微秒 | 在 NVIDIA 40GB NVLink 上約為 33GB/s |
| 向/從 PCI-E GPU 傳輸 1MB | 80微秒 | ~12GB/s 在 PCI-Express x16 鏈路上 |
表:NVIDIA Tesla GPU 的延遲數(shù)。
13.4.8。概括
設備有操作開銷。因此,重要的是要針對少量的大額轉(zhuǎn)賬而不是許多小額轉(zhuǎn)賬。這適用于 RAM、SSD、網(wǎng)絡和 GPU。
矢量化是性能的關鍵。確保您了解加速器的特定功能。例如,某些 Intel Xeon CPU 特別適合 INT8 運算,NVIDIA Volta GPU 擅長 FP16 矩陣-矩陣運算,而 NVIDIA Turing 在 FP16、INT8 和 INT4 運算方面表現(xiàn)出色。
由于小數(shù)據(jù)類型導致的數(shù)值溢出可能是訓練期間的一個問題(并且在推理期間的程度較小)。
別名會顯著降低性能。例如,64 位 CPU 上的內(nèi)存對齊應該按照 64 位邊界進行。在 GPU 上,保持卷積大小對齊是個好主意,例如,與張量核心對齊。
將您的算法與硬件相匹配(例如,內(nèi)存占用和帶寬)。當將參數(shù)裝入緩存時,可以實現(xiàn)很大的加速(數(shù)量級)。
我們建議您在驗證實驗結果之前先在紙上勾勒出新算法的性能。數(shù)量級或更多的差異是令人擔憂的原因。
使用分析器調(diào)試性能瓶頸。
訓練和推理硬件在價格和性能方面有不同的優(yōu)勢。
13.4.9。練習
編寫C代碼測試訪問相對于外部存儲器接口對齊或未對齊的內(nèi)存是否存在速度差異。提示:注意緩存效果。
測試按順序訪問內(nèi)存或以給定步幅訪問內(nèi)存之間的速度差異。
您如何測量 CPU 上的高速緩存大小?
您將如何在多個內(nèi)存通道中布置數(shù)據(jù)以獲得最大帶寬?如果你有很多小線程,你會如何布局?
企業(yè)級 HDD 的轉(zhuǎn)速為 10,000 rpm。HDD 在讀取數(shù)據(jù)之前需要花費最壞情況的絕對最短時間是多少(您可以假設磁頭幾乎是瞬間移動)?為什么 2.5 英寸 HDD 越來越受商業(yè)服務器歡迎(相對于 3.5 英寸和 5.25 英寸驅(qū)動器)?
假設 HDD 制造商將存儲密度從每平方英寸 1 Tbit 提高到每平方英寸 5 Tbit。您可以在 2.5 英寸 HDD 的環(huán)上存儲多少信息?內(nèi)軌和外軌有區(qū)別嗎?
從 8 位到 16 位數(shù)據(jù)類型增加了大約四倍的硅數(shù)量。為什么?為什么 NVIDIA 會在其 Turing GPU 中添加 INT4 運算?
通過內(nèi)存向前閱讀與向后閱讀相比快多少?這個數(shù)字在不同的計算機和 CPU 供應商之間是否不同?為什么?編寫 C 代碼并進行試驗。
你能測量你的磁盤的緩存大小嗎?典型的 HDD 是什么?SSD 需要緩存嗎?
測量通過以太網(wǎng)發(fā)送消息時的數(shù)據(jù)包開銷。查看 UDP 和 TCP/IP 連接之間的區(qū)別。
直接內(nèi)存訪問允許 CPU 以外的設備直接寫入(和讀取)內(nèi)存。為什么這是個好主意?
查看 Turing T4 GPU 的性能數(shù)據(jù)。為什么當您從 FP16 到 INT8 和 INT4 時,性能“僅”翻了一番?
在舊金山和阿姆斯特丹之間往返,一個包裹最短需要多長時間?提示:您可以假設距離為 10,000 公里。
Discussions
-
硬件
+關注
關注
11文章
3348瀏覽量
66303 -
pytorch
+關注
關注
2文章
808瀏覽量
13249
發(fā)布評論請先 登錄
相關推薦






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論