") 識別「ChatGPT造假」,效果超越OpenAI:北大、華為的AI生成檢測器來了
識別「ChatGPT造假」,效果超越OpenAI:北大、華為的AI生成檢測器來了
AI 造假的成功率很高,前幾天「10 分鐘騙 430萬」還上了熱搜。在最熱門的大語言模型上,研究人員最近探索了一種識別方法。
隨著生成式大模型的不斷進(jìn)步,它們生成的語料正逐步逼近人類。雖然大模型正在解放無數(shù)文書的雙手,它以假亂真的強(qiáng)勁能力也為一些不法分子所利用,造成了一系列社會問題:



來自北大、華為的研究者們提出了一種識別各式 AI 生成語料的可靠文本檢測器。根據(jù)長短文本的不同特性,提出了一種基于 PU 學(xué)習(xí)的多尺度 AI 生成文本檢測器訓(xùn)練方法。通過對檢測器訓(xùn)練過程的改進(jìn),在同等條件下能取得在長、短 ChatGPT 語料上檢測能力的可觀提升,解決了目前檢測器對于短文本識別精度低的痛點(diǎn)。

-
論文地址:https://arxiv.org/abs/2305.18149
-
代碼地址 (MindSpore):https://github.com/mindspore-lab/mindone/tree/master/examples/detect_chatgpt
-
代碼地址 (PyTorch):https://github.com/YuchuanTian/AIGC_text_detector
引言
隨著大語言模型的生成效果越發(fā)逼真,各行各業(yè)迫切需要一款可靠的 AI 生成文本檢測器。然而,不同行業(yè)對檢測語料的要求不同,例如在學(xué)術(shù)界,普遍需要對大段完整的學(xué)術(shù)文本進(jìn)行檢測;在社交平臺上,需要對相對簡短而較為支離破碎的假消息進(jìn)行檢測。然而,既有檢測器往往無法兼顧各式需求。例如,主流的一些 AI 文本檢測器對較短的語料預(yù)測能力普遍較差。
對于不同長度語料的不同檢測效果,作者觀察到較短的 AI 生成文本可能存在著一部分歸屬上的「不確定性」;或者更直白地說,由于一些 AI 生成短句同時也常常被人類使用,因而很難界定 AI 生成的短文本是否來自于人或 AI。這里列舉了幾個人和 AI 分別對同一問題做出回答的例子:

由這些例子可見,很難對 AI 生成的簡短回答進(jìn)行識別:這類語料與人的區(qū)別過小,很難嚴(yán)格判斷其真實(shí)屬性。因此,將短文本簡單標(biāo)注為人類 / AI 并按照傳統(tǒng)的二分類問題進(jìn)行文本檢測是不合適的。
針對這個問題,本研究將人類 / AI 的二分類檢測部分轉(zhuǎn)化為了一個部分 PU(Positive-Unlabeled)學(xué)習(xí)問題,即在較短的句子中,人的語言為正類(Positive),機(jī)器語言為無標(biāo)記類(Unlabeled),以此對訓(xùn)練的損失函數(shù)進(jìn)行了改進(jìn)。此改進(jìn)可觀地提升了檢測器在各式語料上的分類效果。
算法細(xì)節(jié)
在傳統(tǒng)的 PU 學(xué)習(xí)設(shè)定下,一個二分類模型只能根據(jù)正訓(xùn)練樣本和無標(biāo)記訓(xùn)練樣本進(jìn)行學(xué)習(xí)。一個常用的 PU 學(xué)習(xí)方法是通過制定 PU loss 來估計(jì)負(fù)樣本對應(yīng)的二分類損失:
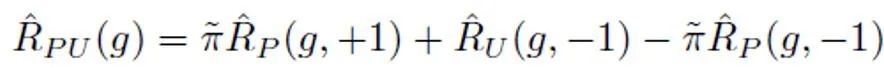
其中,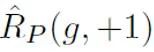 表示正樣本與正標(biāo)簽計(jì)算的二分類損失;
表示正樣本與正標(biāo)簽計(jì)算的二分類損失;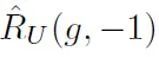 表示將無標(biāo)記樣本全部假定為負(fù)標(biāo)簽計(jì)算的二分類損失;
表示將無標(biāo)記樣本全部假定為負(fù)標(biāo)簽計(jì)算的二分類損失;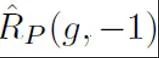 表示將正樣本假定為負(fù)標(biāo)簽計(jì)算的二分類損失;
表示將正樣本假定為負(fù)標(biāo)簽計(jì)算的二分類損失;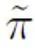 表示的是先驗(yàn)正樣本概率,即正樣本在全部 PU 樣本中的預(yù)估占比。在傳統(tǒng)的 PU 學(xué)習(xí)中,通常將先驗(yàn)設(shè)置為一個固定的超參數(shù)。然而在文本檢測的場景中,檢測器需要處理各式長度不同的文本;而對于不同長度的文本而言,其正樣本在所有和該樣本相同長度的 PU 樣本中的預(yù)估占比也是不同的。因此,本研究對 PU Loss 進(jìn)行了改進(jìn),提出了長度敏感的多尺度 PU(MPU)loss 損失函數(shù)。
表示的是先驗(yàn)正樣本概率,即正樣本在全部 PU 樣本中的預(yù)估占比。在傳統(tǒng)的 PU 學(xué)習(xí)中,通常將先驗(yàn)設(shè)置為一個固定的超參數(shù)。然而在文本檢測的場景中,檢測器需要處理各式長度不同的文本;而對于不同長度的文本而言,其正樣本在所有和該樣本相同長度的 PU 樣本中的預(yù)估占比也是不同的。因此,本研究對 PU Loss 進(jìn)行了改進(jìn),提出了長度敏感的多尺度 PU(MPU)loss 損失函數(shù)。
具體地,本研究提出了一個抽象的循環(huán)模型對較短文本檢測進(jìn)行建模。傳統(tǒng)的 NLP 模型在處理序列時,通常是一個馬爾可夫鏈的結(jié)構(gòu),如 RNN、LSTM 等。此類循環(huán)模型的這個過程通常可以理解為一個逐漸迭代的過程,即每個 token 輸出的預(yù)測,都是由上一個 token 及之前序列的預(yù)測結(jié)果和該 token 的預(yù)測結(jié)果經(jīng)過變換、融合得到的。即以下過程:
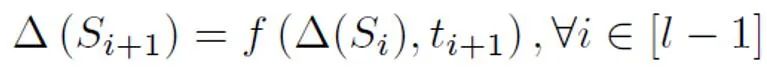
為了根據(jù)這個抽象的模型進(jìn)行先驗(yàn)概率的估計(jì),需要假定該模型的輸出為某個句子為正類(Positive)的置信度,即判定為人說出的樣本的概率。假設(shè)每個 token 的貢獻(xiàn)大小為句子 token 長度的反比,是非正(Positive)即無標(biāo)記(Unlabeled)的,且為無標(biāo)記的概率遠(yuǎn)遠(yuǎn)大于為正的概率。因?yàn)殡S著大模型的詞匯量逐漸逼近人類,絕大部分詞匯會同時出現(xiàn)在 AI 和人類語料中。根據(jù)這個簡化后的模型和設(shè)定好的正 token 概率,通過求出不同輸入情況下模型輸出置信度的總期望,來得到最終的先驗(yàn)估計(jì)。
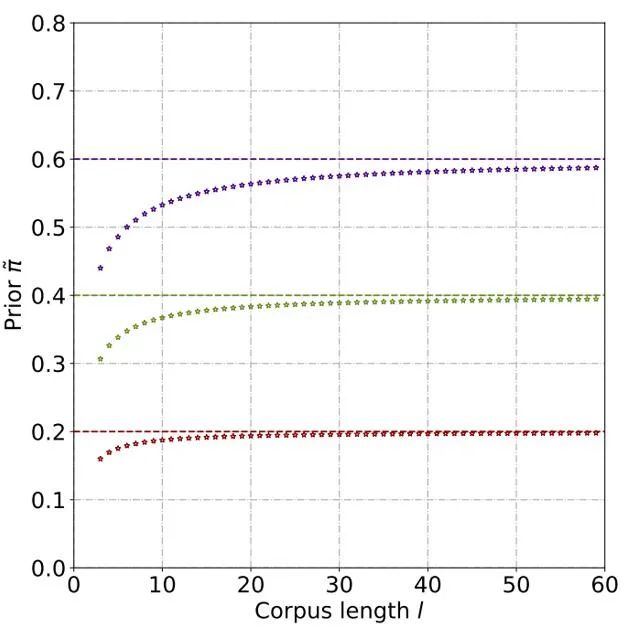
通過理論推導(dǎo)和實(shí)驗(yàn),估計(jì)得到先驗(yàn)概率隨著文本長度的上升而上升,最終逐漸穩(wěn)定。這種現(xiàn)象也符合預(yù)期,因?yàn)殡S著文本變長,檢測器可以捕捉的信息更多,文本的 「來源不確定性」也逐漸減弱:
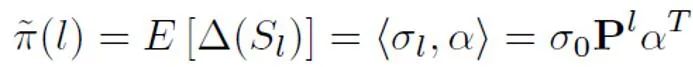
之后,對于每個正樣本,根據(jù)其樣本長度得到的獨(dú)特先驗(yàn)對 PU loss 進(jìn)行計(jì)算。最后,由于較短文本僅有部分 “不確定性”(即較短文本也會含有一些人或者 AI 的文本特征),可以對二分類 loss 和 MPU loss 進(jìn)行加權(quán)相加,作為最終的優(yōu)化目標(biāo):
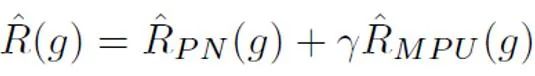
此外需要注意的是,MPU loss 適配的是長度較為多樣的訓(xùn)練語料。倘若既有的訓(xùn)練數(shù)據(jù)單質(zhì)化明顯,大部分語料為大段冗長的文本,則無法全面發(fā)揮 MPU 方法的功效。為了使得訓(xùn)練語料的長度更多樣化,本研究還引入了一個在句子層面進(jìn)行多尺度化的模塊。該模塊隨機(jī)遮蓋訓(xùn)練語料中的部分句子,并對余下句子在保留原有順序的前提下進(jìn)行重組。經(jīng)過訓(xùn)練語料的多尺度化操作,訓(xùn)練文本得到了長度上的極大豐富,從而充分利用了 PU 學(xué)習(xí)進(jìn)行 AI 文本檢測器訓(xùn)練。
實(shí)驗(yàn)結(jié)果

如上表所示,作者先在較短的 AI 生成語料數(shù)據(jù)集 Tweep-Fake 上檢驗(yàn) MPU loss 的效果。該數(shù)據(jù)集中的語料均為推特上較為短小的語段。作者又在傳統(tǒng)的語言模型微調(diào)基礎(chǔ)上將傳統(tǒng)二分類 loss 替換為含有 MPU loss 的優(yōu)化目標(biāo)。改進(jìn)之后的語言模型檢測器效果較為突出,超過了其它基線算法。
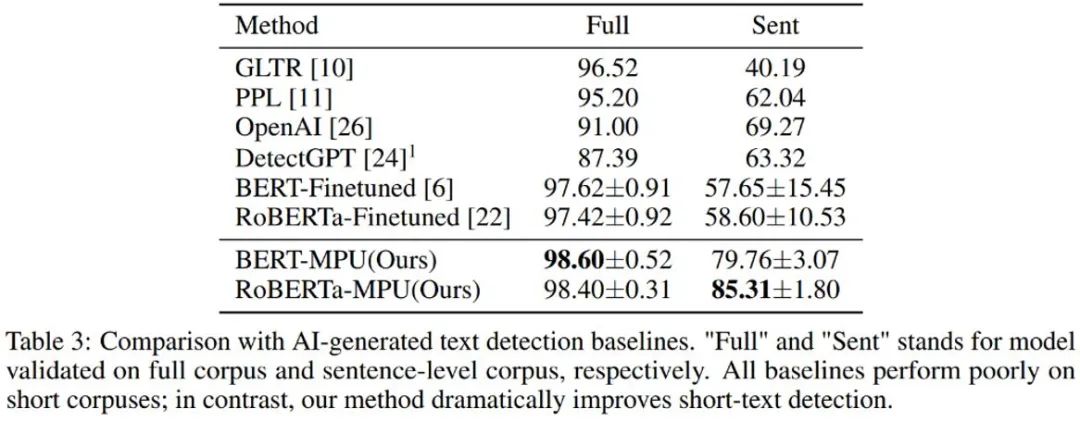
作者又對 chatGPT 生成文本進(jìn)行了檢測,經(jīng)過傳統(tǒng)微調(diào)得到的語言模型檢測器在短句上表現(xiàn)較差;經(jīng)過 MPU 方式在同等條件下訓(xùn)練得到的檢測器在短句上表現(xiàn)良好,且同時能夠在完整語料上取得可觀的效果提升,F(xiàn)1-score 提升了 1%,超越了 OpenAI 和 DetectGPT 等 SOTA 算法。
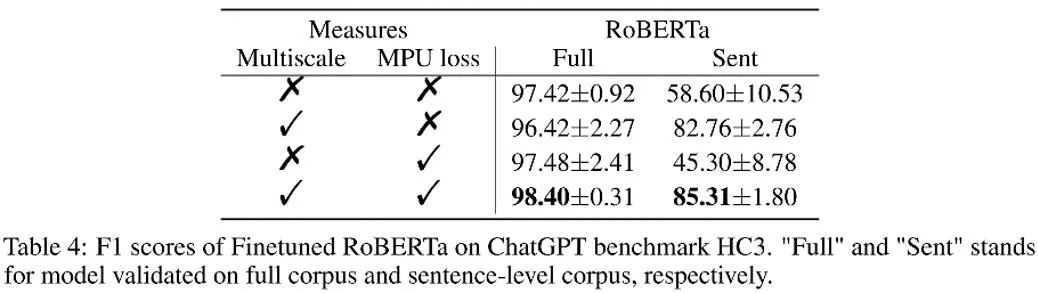
如上表所示,作者在消融實(shí)驗(yàn)中觀察了每個部分帶來的效果增益。MPU loss 加強(qiáng)了長、短語料的分類效果。

作者還對比了傳統(tǒng) PU 和 Multiscale PU(MPU)。由上表可見 MPU 效果更勝一籌,能更好地適配 AI 多尺度文本檢測的任務(wù)。
總結(jié)
作者通過提出基于多尺度 PU 學(xué)習(xí)的方案,解決了文本檢測器對于短句識別的難題,隨著未來 AIGC 生成模型的泛濫,對于這類內(nèi)容的檢測將會越來越重要。這項(xiàng)研究在 AI 文本檢測的問題上邁出了堅(jiān)實(shí)的一步,希望未來會有更多類似的研究,把 AIGC 內(nèi)容進(jìn)行更好的管控,防止 AI 生成內(nèi)容的濫用。
原文標(biāo)題:識別「ChatGPT造假」,效果超越OpenAI:北大、華為的AI生成檢測器來了
文章出處:【微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2909文章
44578瀏覽量
372863
原文標(biāo)題:識別「ChatGPT造假」,效果超越OpenAI:北大、華為的AI生成檢測器來了
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
OpenAI推出AI視頻生成模型Sora
OpenAI推出Windows桌面版ChatGPT應(yīng)用
OpenAI推出ChatGPT搜索功能
OpenAI承認(rèn)正研發(fā)ChatGPT文本水印
OpenAI推出ChatGPT Edu,助力教育及學(xué)術(shù)領(lǐng)域AI應(yīng)用普及
微波檢測器的原理是什么 微波檢測器的工作原理和用途
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來了
微軟Copilot:與OpenAI ChatGPT類似的AI助手
請問移動端生成式AI如何在Arm CPU上運(yùn)行呢?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論