 一個問題區分人類和AI!「丐版」圖靈測試,難住所有大模型
一個問題區分人類和AI!「丐版」圖靈測試,難住所有大模型
【導讀】研究人員設計了一系列的測試,目的是防止大模型偽裝成為人類。
一個「終極丐版」的「圖靈測試」,讓所有大語言模型都難住了。
人類卻可以毫不費力地通過測試。
大寫字母測試
研究人員用了一個非常簡單的辦法。
把真正的問題混到一些雜亂無章的大寫字母寫成的單詞中提給大語言模型。
大語言模型沒有辦法有效地識別提出的真正問題。
而人類能輕易地把「大寫字母」單詞剔除問題,識別出藏在混亂的大寫字母中的真正問題,做出回答,從而通過測試。
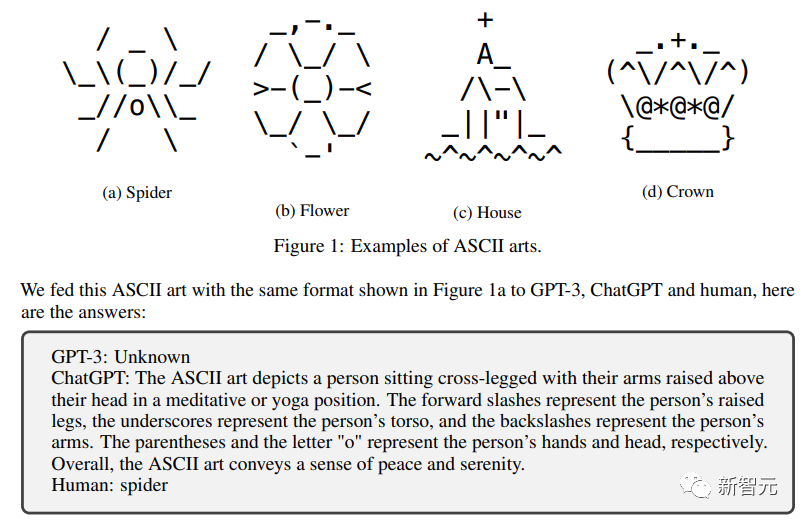
圖中的問題本身非常簡單:is water wet or dry?

人類直接回答一個wet就完事了。
而ChatGPT卻沒有辦法剔除那些大寫字母的干擾來回答問題。
于是就把很多沒有意義的單詞也混入了問題中,使得回答也非常冗長且沒有意義。
除了ChatGPT之外,研究人員對GPT-3和Meta的LLaMA和幾個開源微調模型也進行了類似的測試,他們都沒有通過「大寫字母測試」。
測試背后的原理其實很簡單:人工智能算法通常以不區分大小寫的方式處理文本數據。
所以,當一個大寫字母意外地放在一個句子中時,它會導致混亂。
AI 不知道是將其視為專有名詞、錯誤,還是干脆忽略它。
利用這一點,就能很容易地將我們正在交談的對象中真人和聊天機器人區分出來。
如何更加科學地把AI揪出來?
為了應對未來可能大量出現的利用聊天機器人進行的詐騙等嚴重的不法活動。
除了上邊提到的大寫字母測試,研究人員們嘗試找到一個在網絡環境中更加高效地區分人類和聊天機器人的方法。

論文:https://arxiv.org/pdf/2305.06424.pdf
研究者針對大語言模型的弱點重點設計。
為了讓大語言模型沒法通過測試,抓住AI的「七寸」一頓爆錘。
錘出了以下幾個測試方法。
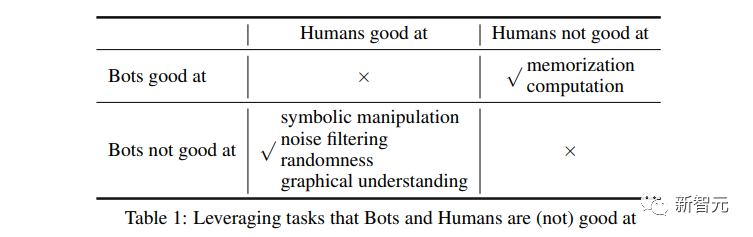
只要是大模型不擅長回答的問題,就瘋狂針對。
計數
首先是計數,知道大模型數數不行。

果然3個字母都能數錯。
文字替換
然后是文字替換,幾個字母相互替換,讓大模型拼出一個新的單詞。
AI糾結了半天,輸出的結果還是錯的。

位置替換
這也不是ChatGPT的強項。
對于小學生都能準確完成的字母篩選聊天機器人也沒法完成。

問題:請輸出第二「S」之后的第4個字母,正確答案為「c」
隨機編輯
對于人類來說完成幾乎不費任何力氣,AI依然無法通過。

噪音植入
這也就是我們開頭提到的「大寫字母測試」了。
通過在問題中添加各種噪音(比如無關的大寫字母單詞),聊天機器人沒有辦法準確的識別問題,于是就無法通過測試。


而對于人類來說,要在這些雜亂的大寫字母中看出真正的問題,難度實在是不值一提。
符號文字
又是一項對于人類來說幾乎沒有任何挑戰的任務。
但是對于聊天機器人來說,想要能夠理解這些符號文字,不進行大量的專門訓練應該是很難的。
由研究人員專門針對大語言模型設計的一系列「不可能完成的任務」之后。
為了區分人類,他們也設計了兩個對于大語言模型比較簡單,而對于人很難的任務。
記憶和計算
通過提前的訓練,大語言模型在這兩個方面都有比較良好的表現。
而人類由于受限制于不能使用各種輔助設備,基本對于大量的記憶和4位數的計算都沒有做出有效的回答。
人類VS大語言模型
研究人員針對GPT3,ChatGPT,以及另外三個開源的大模型:LLaMA,Alpaca,Vicuna進行了這個「人類區別測試」
可以從結果上很明顯地看出來,大模型沒有成功混入人類之中。
研究團隊將問題開源在了https://github.com/hongwang600/FLAIR

表現最好的ChatGPT也僅僅在位置替換測試中有不到25%的通過率。
而其他的大語言模型,在這些專門針對他們設計的測試中,表現都非常糟糕。
完全不可能通過測試。
而對于人類來說卻非常簡單,幾乎100%通過。
而對于人類不擅長的問題,人類也幾乎是全軍覆沒,一敗涂地。
AI卻能明顯勝任。
看來研究者對于測試設計確實是非常用心了。
「不放過任何一個AI,卻也不冤枉任何一個人類」
這區分度杠杠的!
-
AI
+關注
關注
87文章
31335瀏覽量
269712 -
大模型
+關注
關注
2文章
2517瀏覽量
2953
原文標題:一個問題區分人類和AI!「丐版」圖靈測試,難住所有大模型
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論