

在嵌入式領(lǐng)域,代碼體積(code size)優(yōu)化能夠減少內(nèi)存的使用,對產(chǎn)品的競爭力至關(guān)重要。對當(dāng)代產(chǎn)品而言, code size優(yōu)化可以為產(chǎn)品放入更多特性,增強競爭力;對下一代產(chǎn)品而言,code size優(yōu)化能夠帶來產(chǎn)品功耗和成本的競爭力提升。LLVM Machine Outliner是一種編譯器優(yōu)化技術(shù),可以識別重復(fù)代碼片段,將其提取出來并轉(zhuǎn)換成一個獨立的函數(shù),從而降低程序code size。
示例
通過以下代碼示例,描述是否開啟Machine Outliner優(yōu)化的效果:
int div(int x) {
int a = x / 2;
int b = x;
return b / a;
}
int sub(int x) {
int a = x / 2;
int b = x;
return b - a;
}
以上代碼片段由div和sub兩個函數(shù)組成,通過函數(shù)參數(shù)x,對變量a和b賦值,然后分別返回b和a相除,以及b和a相減的結(jié)果。其中,關(guān)于變量a、b賦值部分為重復(fù)代碼片段。
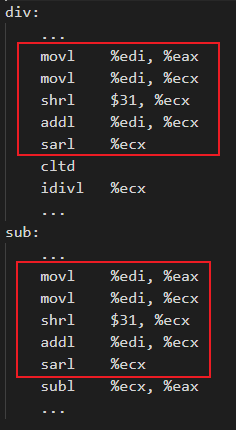
是否開啟Machine Outliner優(yōu)化,在匯編層面的區(qū)別如下表所示:

如果不開啟Machine Outliner優(yōu)化,則會分別在標(biāo)簽div和sub下生成相關(guān)的重復(fù)匯編指令。開啟Machine Outliner優(yōu)化,則會將重復(fù)指令提取為單獨的函數(shù),并且在重復(fù)指令初始位置添加函數(shù)調(diào)用,從而降低程序code size。在編譯階段,可以通過使用 -mllvm -enable-machine-outliner=always 選項開啟Machine Outliner優(yōu)化,提取出的函數(shù)統(tǒng)一以“OUTLINED_FUNCTION_n”的形式命名。
后綴樹
Machine Outliner優(yōu)化依靠后綴樹(Suffix Tree)的形式進(jìn)行重復(fù)指令序列的識別,后綴樹的構(gòu)造和重復(fù)字符串查詢操作均可在線性時間復(fù)雜度內(nèi)完成,從而實現(xiàn)了Machine Outliner優(yōu)化的效率提升。
后綴樹是一種將字符串所有后綴存儲在一棵樹中的數(shù)據(jù)結(jié)構(gòu),目的是用來支持快速搜索和大量字符串匹配和查詢,能高效解決很多關(guān)于字符串的問題[2]。字符串S對應(yīng)的后綴樹,也就是由該字符串所有后綴所共同構(gòu)成的壓縮字典樹。
字典樹(Trie)是一種樹形數(shù)據(jù)結(jié)構(gòu),其中每條邊用來表示一個字符,且每個節(jié)點出邊對應(yīng)的字符都不相同,將根節(jié)點到某一節(jié)點路徑上所經(jīng)過的字符拼接起來,即為該節(jié)點所表示的字符串。壓縮字典樹(Compressed Trie)由字典樹演變而來,將字典樹中的單節(jié)點鏈條壓縮為一個節(jié)點,即將相鄰的具有相同前綴的節(jié)點合并,可得到對應(yīng)的壓縮字典樹。字符串“ABD$0”對應(yīng)的字典樹和壓縮字典樹如下所示:

后綴樹的構(gòu)建需要經(jīng)過字符串后綴生成和壓縮字典樹構(gòu)建兩步:
- 生成字符串S的所有后綴,以“ABCAB$0”(“$0”是結(jié)束字符)為例,該字符串的所有后綴為:
ABCAB$0 BCAB$0 CAB$0 AB$0 B$0 $0 - 為以上所有后綴生成字典樹,并且合并節(jié)點生成相應(yīng)的壓縮字典樹:

令字符串S的長度為n,通過構(gòu)建字符串S所對應(yīng)的后綴樹,即可在O(n)時間復(fù)雜度內(nèi),完成字符串重復(fù)次數(shù),以及重復(fù)字符串長度的檢索[3]。
重復(fù)次數(shù)搜索: 假設(shè)字符串T在字符串S中重復(fù)次數(shù)為m,則字符串S應(yīng)有m個后綴以字符串T為前綴,即字符串T所對應(yīng)節(jié)點的葉節(jié)點數(shù)量為其重復(fù)次數(shù)。
重復(fù)字符串長度搜索: 由于重復(fù)字符串出現(xiàn)次數(shù)大于1,所以字符串T在后綴樹中一定以非葉節(jié)點的形式表示,字符串T的長度為該非葉節(jié)點到根節(jié)點所經(jīng)過的字符總數(shù)。
編譯器實現(xiàn)
LLVM對于Machine Outliner的實現(xiàn)在寄存器分配之后,主要集中在MachineOutliner.cpp中,基于機器指令表示(MIR)進(jìn)行函數(shù)的分析和提取,以實現(xiàn)程序code size優(yōu)化。
編譯器側(cè)的實現(xiàn)過程可劃分為指令映射、后綴樹構(gòu)建和函數(shù)提取三個階段:
- 將指令映射成特定的無符號數(shù),并以指令-無符號數(shù)對的形式存儲在Map中;
- 以無符號數(shù)組為輸入構(gòu)建指令序列對應(yīng)的后綴樹,并且找出所有長度大于2的重復(fù)指令序列;
- 遍歷后綴樹并進(jìn)行收益計算,從而得到包含正收益序列的候選列表,對于具備收益的候選項進(jìn)行函數(shù)外提。
指令映射
首先需要遍歷源文件對應(yīng)的所有指令,將所有合法指令映射為無符號數(shù)(InstrNumber),并以指令-無符號數(shù)對的形式存儲在Map中,如果兩條指令的操作碼和操作數(shù)均相同,則認(rèn)為兩條指令相同。對于所訪問的每條指令,首先應(yīng)該在Map中查詢是否已經(jīng)存儲了相同的指令,如果是,則返回對應(yīng)的InstrNumber;否則,將該指令插入到Map中,InstrNumber自加。
至此,所有指令均以無符號數(shù)的形式進(jìn)行唯一標(biāo)識,以作為構(gòu)建后綴樹的輸入。而對于讀寫棧指針、PC相關(guān),以及其他與call、ret指令有數(shù)據(jù)依賴的指令,將被判定為非法指令,為保證程序運行的正確性,這些指令不參與上述映射過程。

后綴樹構(gòu)建
假定將無符號數(shù)以字符形式表示,以指令映射輸出的無符號數(shù)組為輸入,通過添加終結(jié)符和構(gòu)建后綴樹,即可在線性時間復(fù)雜度內(nèi),完成字符串S的所有重復(fù)子字符串長度、重復(fù)次數(shù)和起始下標(biāo)的計算,這些重復(fù)字符串將以候選列表的形式輸出。
- 以第2節(jié)所示匯編指令為例,經(jīng)過指令映射和添加終結(jié)符后可得到字符串S:
ABCDEFG$0ABCDEH$1,其中添加終結(jié)符可避免跨函數(shù)指令序列提取。

- 以字符串S為輸入,構(gòu)建后綴樹:

令A(yù)BCDE所指向的節(jié)點為P,單個字符所表示的距離為1,則節(jié)點P到根節(jié)點的距離為5,大于其他非葉節(jié)點到根節(jié)點的距離,因此ABCDE為字符串S中的最長重復(fù)子字符串T。節(jié)點P有兩個子節(jié)點,因此字符串T的重復(fù)次數(shù)為2,且T在S中的起始下標(biāo)分別為[0,4],[8,12]。
函數(shù)提取
完成后綴樹構(gòu)建和重復(fù)字符串解析后,還需要對提取該重復(fù)字符串對應(yīng)的指令序列進(jìn)行code size收益計算,計算公式如下:
codesize_benefit = codesize_before - codesize_after
codesize_before = 指令序列重復(fù)次數(shù) * 指令序列codesize
codesize_after = 插入call指令的codesize + 指令序列codesize + 插入ret指令的codesize
如果收益大于1,則提取同一重復(fù)字符串對應(yīng)的所有指令序列,以構(gòu)造outline函數(shù),并在函數(shù)末尾額外添加ret指令。而對于重復(fù)字符串指向的下標(biāo)位置,需要刪除初始指令序列,并且通過call指令增加對outline函數(shù)的調(diào)用。

總結(jié)
本文對Machine Outliner的基本概念和實現(xiàn)方法進(jìn)行了簡單介紹,通過將所有指令映射成為無符號數(shù),并且以后綴樹的形式對重復(fù)指令序列進(jìn)行高效識別,最后提取具有正收益的指令序列作為outline函數(shù),實現(xiàn)程序code size優(yōu)化,從而提高代碼的可讀性并且減少程序的內(nèi)存占用。
在源碼中大量使用宏、模板,以及循環(huán)展開的場景下,開啟Machine Outliner優(yōu)化將會獲得明顯的code size收益;而對于程序本身code size很小、結(jié)構(gòu)化設(shè)計良好,或者包含大量違反外提約束的情況,Machine Outliner對code size的優(yōu)化效果不顯著。此外,在LLVM14及更高版本上,完成了多次outline的實現(xiàn),相比于本文所述的單次outline,能夠進(jìn)一步實現(xiàn)code size提升。
-
編譯器
+關(guān)注
關(guān)注
1文章
1663瀏覽量
50276 -
嵌入式系統(tǒng)中
+關(guān)注
關(guān)注
0文章
2瀏覽量
5732 -
DIV
+關(guān)注
關(guān)注
0文章
6瀏覽量
10723 -
sub函數(shù)
+關(guān)注
關(guān)注
0文章
3瀏覽量
1060
發(fā)布評論請先 登錄
Coke Machine State Machine
JKI-State-Machine-Objects(SMO)框架講解
Brain Machine腦機器套件解析
vipm中 jki state machine
Finite State Machine Datapath
Research on Human Machine Inte
Design Safe Verilog State Machine(Synplicity)

State Machine Coding Styles for Synthesis
繪圖案例【Circuit Simulation】State_Machine
解析在CentOS7上安裝docker-machine的過程

EcoStruxure Machine Expert編程指南
Machine Outliner簡介
使用Teachable Machine和Python輕松進(jìn)行對象檢測






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論