 KMP算法詳解
KMP算法詳解
KMP 算法主要用于字符串匹配的,他的時間復雜度 O(m+n) 。常規的字符串匹配我們一般都這樣做,使用兩個指針,一個指向主串,一個指向模式串,如果他倆指向的字符一樣,他倆同時往右移一步,如果他倆指向的字符不一樣,模式串的指針重新指向他的第一個字符,主串的指針指向他上次開始匹配的下一個字符,如下圖所示。
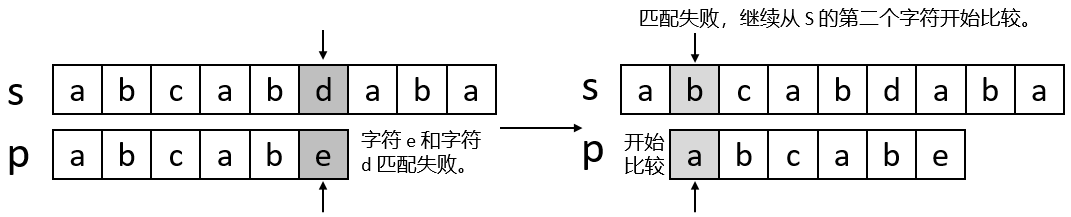
我們看到當模式串和主串匹配失敗的時候,模式串會從頭開始重新匹配,主串也會回退,但我們知道失敗字符之前的子串都是匹配成功的,那么這個信息能不能被我們利用呢?當然可以,這個就是我們這里要講的 KMP 算法,他就是利用匹配失敗后的信息,盡量減少模式串與主串的匹配次數以達到快速匹配的目的。
當使用 KMP 算法的時候,如果某個字符匹配失敗,主串指針不回退,而模式串指針不一定回到他的第一個字符,如下圖所示。

當字符 e 和 d 匹配失敗之后,主串指針不回退,模式串指針指向字符 c ,然后在繼續判斷。主串指針不回退好操作,但模式串指針怎么確定是回到字符 c ,而不是其他位置呢?這是因為在字符 e 匹配失敗后,字符 e 前面有 2 個字符 ab 和最開始的 2 個字符 ab 相同,所以我們可以跳過前 2 個字符。也就是說模式串匹配某一個字符失敗的時候,如果這個失敗的字符前面有 m 個字符和最開始的 m 個字符相同,那么下次比較的時候就可以跳過模式串的前 m 個字符,如下圖所示。
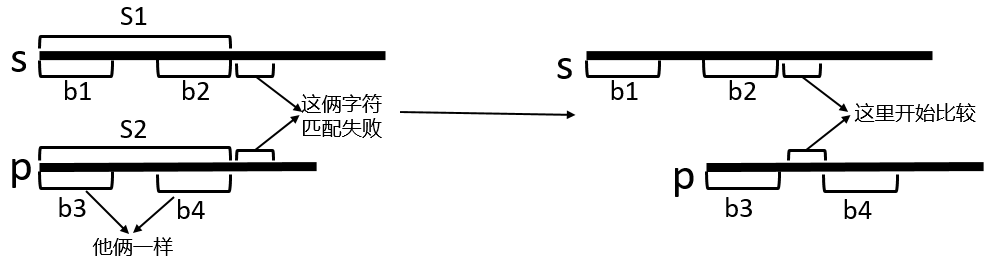
通過上面的圖我們可以知道,當某個字符匹配失敗的時候,他前面的肯定都是成功的,也就是說字符串 s1 和字符串 s2 完全一樣。在模式串中,匹配失敗的字符前面 b4 和 b3 是相同的,所以我們可以得到 b1,b2,b3,b4 都是相同的,也就是說b2 和 b3 也是相同的,既然是相同的,跳過即可,不需要在比較了,直接從他們的下一個字符開始匹配。
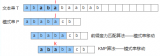
KMP 算法的核心部分就是找出模式串中每個字符前面到底有多少字符和最開始的字符相同,我們用 next 數組表示。有的描述成真前綴和真后綴的相同的數量。這里要注意當前字符前面的字符不包含第 1 個字符,最開始的字符也不能包含當前字符,比如在模式串 abc 中不能說字符 c 前面有 ab 和最開始的 ab 相同,來看下表。

我們看到字符 e 前面有 ab 和最開始的字符 ab 相同,長度是 2 。在看第 2 個 a 前面沒有(不包含自己)和最開始字符有相同的,所以是 0 。在任何模式串的第 2 個字符前面都沒有和最開始字符有相同的,因為前面的是不包含第一個字符,所以 next[1]=0 。如果第 2 個沒有,那么第 1 個就更沒有了,為了區分,可以讓 next[0]=-1 ,當然等于 0 也可以,需要特殊處理下即可。我們先來看下 next 數組怎么求。

使用兩個指針 i 和 j ,其中 j 是字符 p[i] 前面與最開始字符相同的數量,也是 next[i] 。如果 p[j]==p[i],也就是說字符 p[i+1] 前面有 j+1 個字符和最開始的 j+1 個字符相同,所以可以得到 next[i+1]=j+1 ,這個很容易理解。如果 p[j]!=p[i],我們讓指針 j 等于 next[j] ,然后重新和 p[i] 比較,這就是回退,這個回退也是 KMP 算法的最核心部分,我們來分析下為什么要這樣回退。
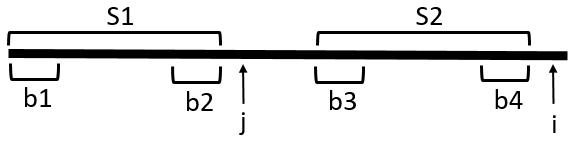
如上圖所示,如果 nxet[j] 大于 0 ,那么 j 前面的 b2 和 b1 是相同的,我們知道 S1 和 S2 也是相同的,所以我們可以得出 b1,b2,b3,b4 都是相同的,如果 p[i]!=p[j] ,只需要讓 j 回退到 next[j] ,然后 i 和 j 在重新比較,這個 next[j] 就是 b1 的長度,因為 b1 和 b4 是相同的,所以不需要再比較了。如果還不相同, j 繼續回退,直到回退到 -1 為止,我們拿個真實的字符串看下,如下圖所示。

我們看到 b1,b2,b3,b4 是相同的,他們都是字符串 "abc" ,如果 p[i]!=p[j] ,我們就讓 j 回退到 next[j] ,因為他們前面 b1 和 b4 是相同的,沒必須要在比較了,最后再來看下代碼。
public int strStr(String s, String p) {
int i = 0;// 主串S的下標。
int j = 0;// 模式串P的下標。
int[] next = new int[p.length()];
getNext(p, next);// 計算next數組。
while (i < s.length() && j < p.length()) {
// 如果j為-1或者p[i]==p[j],i和j都往后移一步。當j為-1時,
// 說明p[i]!=p[0],然后i往后移一步,j也往后移一步指向p[0]。
if (j == -1 || s.charAt(i) == p.charAt(j)) {
i++;
j++;
if (j == p.length())// 匹配成功。
return i - j;
} else {
// 匹配失敗,j回退,跳過模式串P前面相同的字符繼續比較。
j = next[j];
}
}
return -1;
}
private void getNext(String p, int next[]) {
int length = p.length();
int i = 0;
int j = -1;
next[0] = -1;// 默認值。
// 最后一個字符不需要比較。
while (i < length - 1) {
// 如果j為-1或者p[i]==p[j],i和j都往后移一步。
if (j == -1 || p.charAt(i) == p.charAt(j)) {
i++;
j++;
// j是字符p[i]前面和最開始字符相同的數量。
next[i] = j;
} else {
j = next[j];// 回退,KMP的核心代碼。
}
}
}
KMP優化
我們來看下表 ,當模式串在下標為 4 的位置匹配失敗的時候,下一步 j 會回退到下標為 1 的位置,但這兩個位置的字符是一樣的,既然一樣,拿過來比較也是不會成功,所以如果字符一樣,我們可以優化一下,往前查找相同的子串。

來看下代碼:
private void getNext(String p, int next[]) {
int length = p.length();
int i = 0;
int j = -1;
next[0] = -1;// 默認值。
// 最后一個字符不需要比較。
while (i < length - 1) {
// 如果j為-1或者p[i]==p[j],i和j都往后移一步。
if (j == -1 || p.charAt(i) == p.charAt(j)) {
i++;
j++;
// 這里要注意,i和j都已經執行了自增操作。
if (p.charAt(i) == p.charAt(j))
next[i] = next[j];
else
next[i] = j;
} else {
j = next[j];// 回退,KMP的核心代碼。
}
}
}
如果前面查找的還是相同的,我們該怎么辦呢?是不是需要寫個遞歸,繼續往前找?實際上是不需要的,比如模式串 "aaaaaaaaaab" ,如果沒優化他是這樣的。

如果優化之后,當最后一個 a 匹配不成功的時候,他會回退到前面一個 a ,實際上前一個 a 在計算的時候已經回退過了,就是 -1 ,所以不需要遞歸,直接賦值就行。

-
kmp算法
+關注
關注
0文章
4瀏覽量
1447
發布評論請先 登錄
相關推薦
字符串的KMP算法和BM算法





 工商網監
工商網監
評論