 從大模型中蒸餾腳本知識用于約束語言規劃
從大模型中蒸餾腳本知識用于約束語言規劃
為了實現日常目標,人們通常會根據逐步指令來計劃自己的行動。這些指令被發現是目標導向的腳本,包括一組達成目標的原型事件序列。為了實現目標(例如制作蛋糕),通常需要按照某些指令步驟進行,例如收集材料,預熱烤箱等。這種逐步腳本的規劃會朝著復雜目標的推理鏈條進行。因此,規劃自動化意味著在各個領域中實現更智能和合理的人工智能系統,例如可執行的機器人系統和用于問題解決的推理系統。
最近的研究表明,語言模型(LMs)可以用于計劃腳本。先前的工作已經表明,大型語言模型(LLMs),例如GPT-3、InstructGPT和PaLM,可以以零/少量示例的方式有效地將目標分解為過程步驟。為了訓練專業模型,研究人員提出了自動理解和生成腳本知識的數據集。但是,先前的工作主要關注于針對典型活動的抽象目標進行規劃。針對具有特定約束條件(例如糖尿病患者)目標的規劃仍然未得到充分研究。
本文介紹了復旦大學知識工場實驗室的最新研究論文《Distilling Script Knowledge from Large Language Models for Constrained Language Planning》,該文已經被自然語言處理頂會ACL 2023作為主會長文錄用。本文工作關注約束語言規劃的問題,將語言規劃推向了更具體的目標。論文作者評估了LLMs的少量示例約束語言規劃能力,并為LLMs開發了一種超生成然后過濾的方法,使準確性提高了26%。基于本文的方法,作者還使用LLMs生成了一個約束語言規劃的高質量腳本數據集(CoScript)。利用CoScript,可為專業化和小型模型提供具有約束語言規劃能力的能力,其性能可媲美LLMs。

一、研究背景
為了實現日常目標,人們通常會根據逐步指令來計劃自己的行動。這些指令被發現是目標導向的腳本,包括一組達成目標的原型事件序列。為了實現目標(例如制作蛋糕),通常需要按照某些指令步驟進行,例如收集材料,預熱烤箱等。這種逐步腳本的規劃會朝著復雜目標的推理鏈條進行。因此,規劃自動化意味著在各個領域中實現更智能和合理的人工智能系統,例如可執行的機器人系統和用于問題解決的推理系統。

圖1:InstructGPT生成了一系列“為糖尿病患者做蛋糕”的目標規劃步驟
最近的研究表明,語言模型(LMs)可以用于計劃腳本。先前的工作已經表明,大型語言模型(LLMs),例如GPT-3、InstructGPT和PaLM,可以以零/少量示例的方式有效地將目標分解為過程步驟。為了訓練專業模型,研究人員提出了自動理解和生成腳本知識的數據集。但是,先前的工作主要關注于針對典型活動的抽象目標進行規劃。針對具有特定約束條件(例如糖尿病患者)的目標的規劃仍然未得到充分研究。
二、基于大規模語言模型的限制約束語言規劃
在本文中,作者定義了約束語言規劃問題,該問題對規劃目標施加不同的約束。例如,抽象目標(制作蛋糕)可以由具有多方面約束的不同現實特定目標所繼承。蛋糕可以用1)不同的配料(例如巧克力或香草);2)各種工具(例如使用微波爐或烤箱);或3)不同的用途(例如用于婚禮或生日派對)來制作。
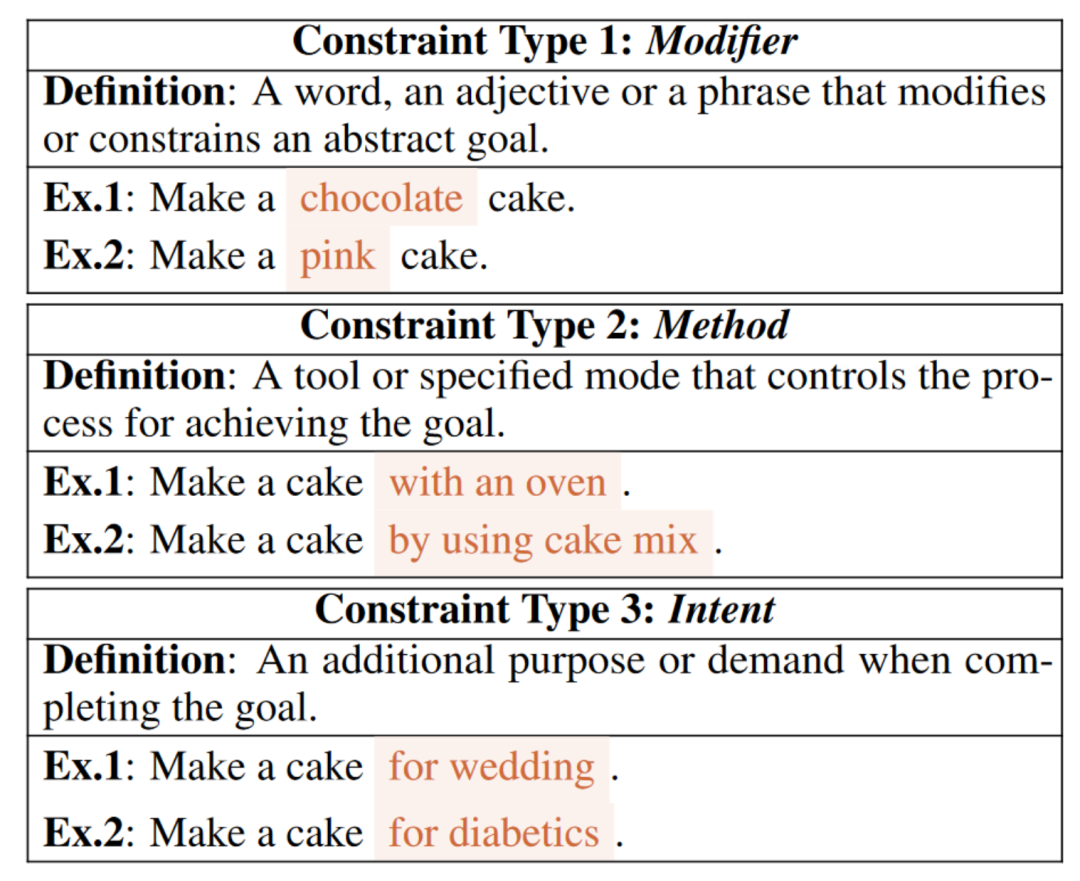
表1:促進特定目標新實例生成的三種約束類型及其定義
一個好的規劃者應編寫合理并忠實于約束的腳本。為此,作者探究了LLMs是否會忠實于約束地進行規劃。由于沒有特定目標的數據集支持本文的研究,必須首先獲取這些目標。如表1所述,作者使用InstructGPT對抽象目標進行了多方面約束的人在環數據采集進行擴展。首先,作者手動準備了一個示例池,從中使用約束從抽象目標中推導出具體目標。每個示例都附帶有一個約束類型(即修飾符、方法或意圖),并包含多個約束和特定目標,以便InstructGPT為一個抽象目標生成多個具體目標。
接下來,作者枚舉wikiHow的每個抽象目標,以確保數據多樣性。然后,從池中隨機抽取約束類型的多個示例。最后,將任務提示、示例和抽象目標輸入InstructGPT中,以完成具體目標。表2(I)中的一個示例顯示了InstructGPT針對抽象目標(“制作蛋糕”)和約束類型修飾符以及一些示例生成了約束“巧克力”和“香草”,并完成了特定目標(“制作巧克力蛋糕”和“制作香草蛋糕”)。獲取帶有約束的具體目標后,可以測試LLM實現這些目標的能力。

表2: InstructGPT的提示示例,用于通過上下文學習生成特定目標和腳本。生成的文本已經被突出顯示
表3報告了結果的整體準確度,從中可以發現:1)總體而言,所有基準模型在特定目標的規劃上都取得了不令人滿意的結果,其中InstructGPT表現最佳。“讓我們一步一步思考”并不能幫助太多;2)從wikiHow檢索不會導致所需的腳本。
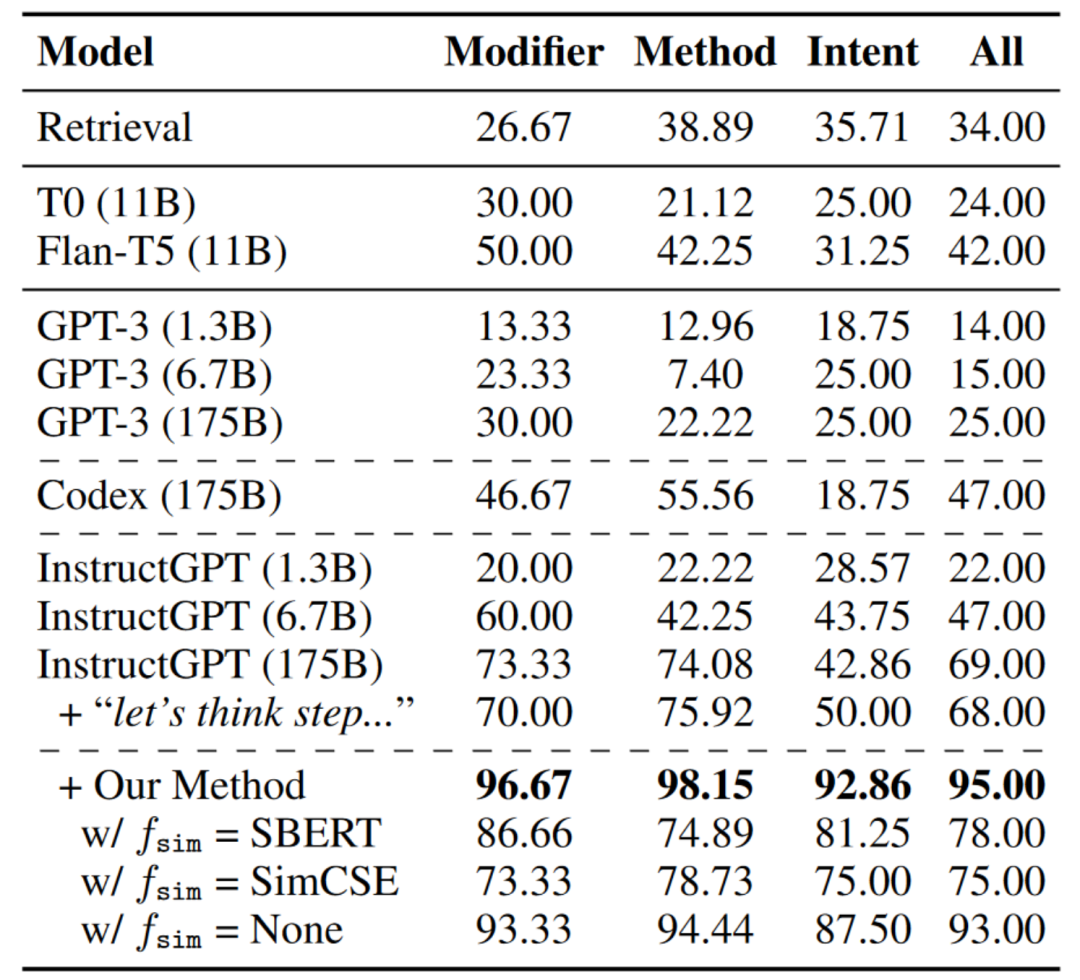
表3:不同約束類型的生成腳本準確率(%),通過人工評估得出。
為了回應本文方法的動機,作者進行了詳細的分析,以研究為何LLM會失敗。圖3的結果表明:1)生成的腳本的語義完整性是可以接受的,但約束的忠實度無法保證;2)本文的方法在語義完整性和約束忠實度方面都極大地提高了規劃質量。
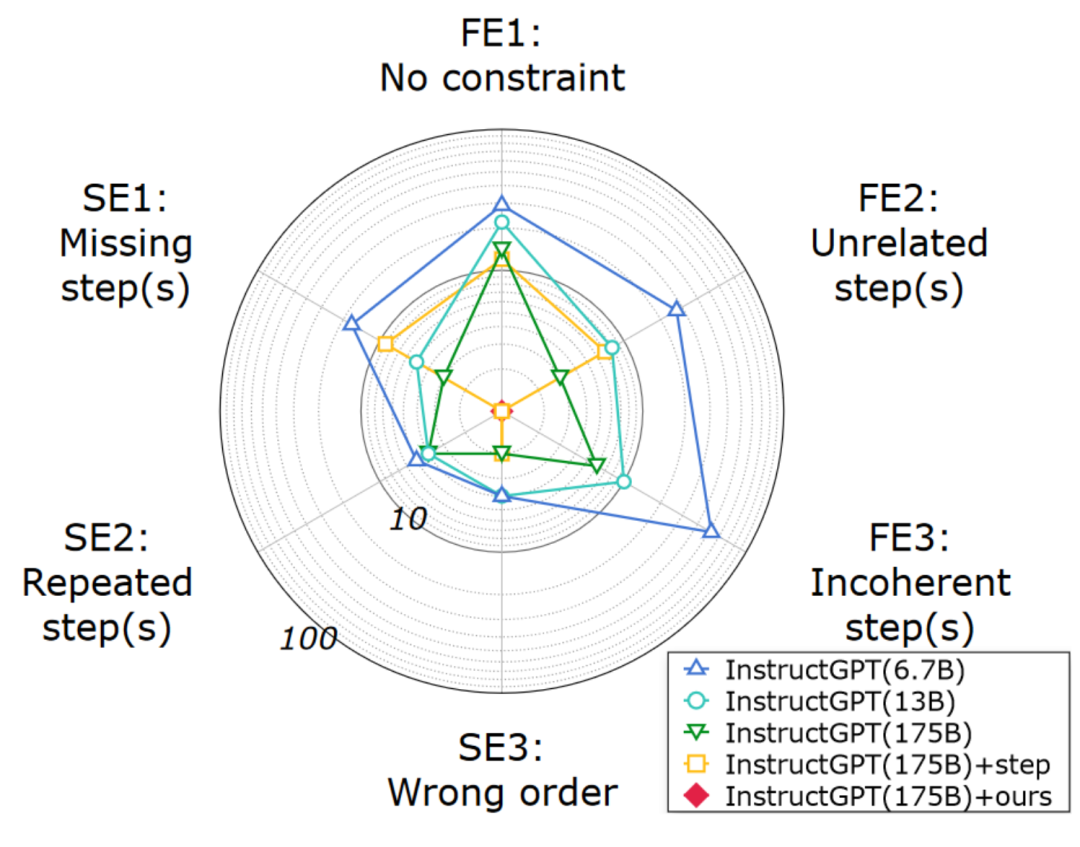
圖2:通過人工評估生成的腳本的錯誤
因此,作者采用了過度生成然后過濾的思路來提高生成質量。正如圖3所示,作者從InstructGPT中過度生成K個樣本,然后開發一個過濾模型來選擇忠實的腳本。由于語言表達方式多樣,作者依賴于目標和腳本之間的語義相似性進行過濾,而不是規則和模式(即,必須在腳本中出現約束詞)。
作者首先收集了一組目標,包括所求目標作為正樣本以及從相同的抽象目標生成的其他目標作為負樣本。然后,將腳本和目標轉換為InstructGPT嵌入,并計算余弦相似性作為相似性分數來衡量語義相似性。此外,作者獎勵明確包含目標約束關鍵字的腳本,只有所求目標在目標集合得分最高時才會保留該腳本。
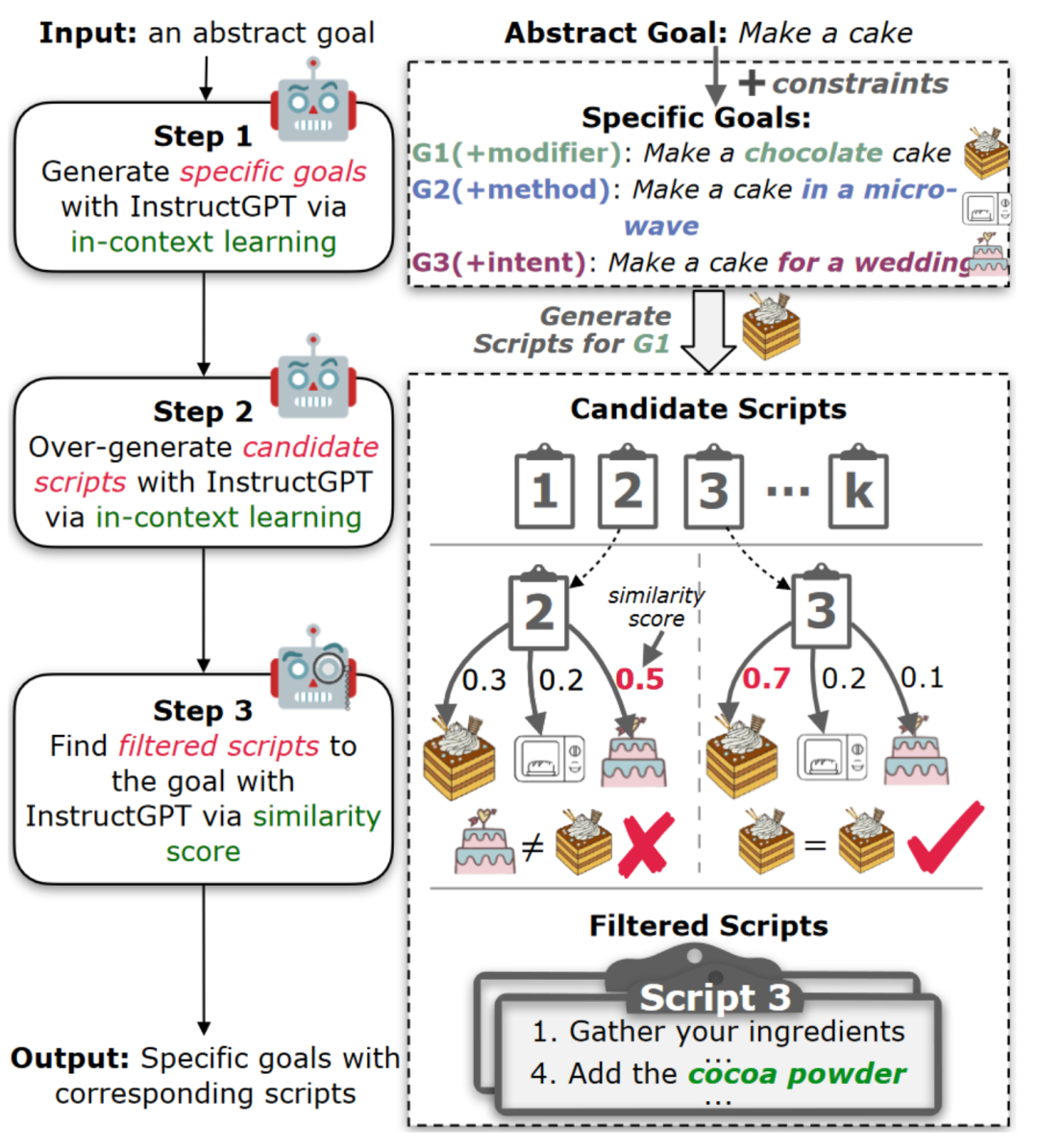
圖3:使用InstructGPT生成具體目標并使用超生成-過濾框架進行目標規劃的工作流程。
結果如表3所示。使用本文的方法,InstructGPT可以大幅提高腳本的質量。將相似度函數替換為來自其他預訓練模型的嵌入會導致性能下降。
三、從大模型中獲取腳本知識
LLMs成本高,需為更小、專業化模型添加語言規劃能力。為實現此目標,創建數據集是必要步驟,但以前的數據集不支持特定目標的規劃,手動注釋成本高。為此,作者使用符號知識蒸餾從LLMs中提取受限制的語言規劃數據集。作者使用超生成-過濾框架為受限制的語言規劃腳本數據集CoScript構建了高質量的具體目標和腳本,總共生成了55,000個具體目標和相應的腳本。
作者還隨機選擇2,000個數據作為驗證集,3,000個數據作為測試集。為確保驗證集和測試集的質量,作者要求眾包工作者查找和修正不正確的樣本。通過收集這5,000個樣本的注釋數據進行錯誤識別,估計出具體目標的準確率為97.80%,受限腳本生成的準確率為94.98%,與表3中的結果一致。
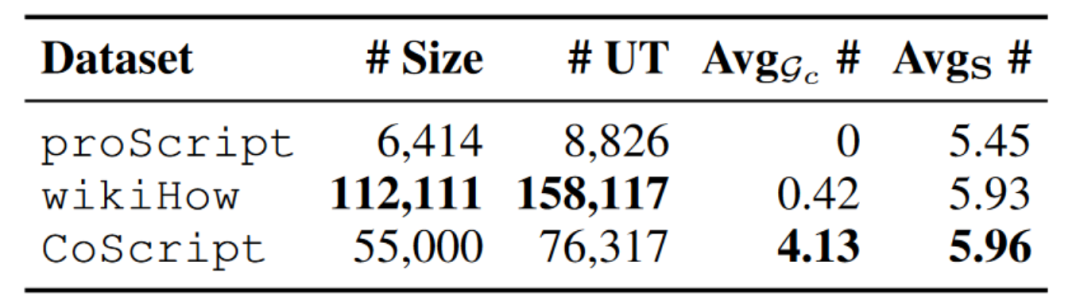
表4:Coscript和之前數據集的對比
并與其他數據集進行了比較,如表4所示,發現CoScript比proScript規模更大,具有更多的腳本和更高的每個腳本步驟數,并且CoScript具有高度的詞匯多樣性。
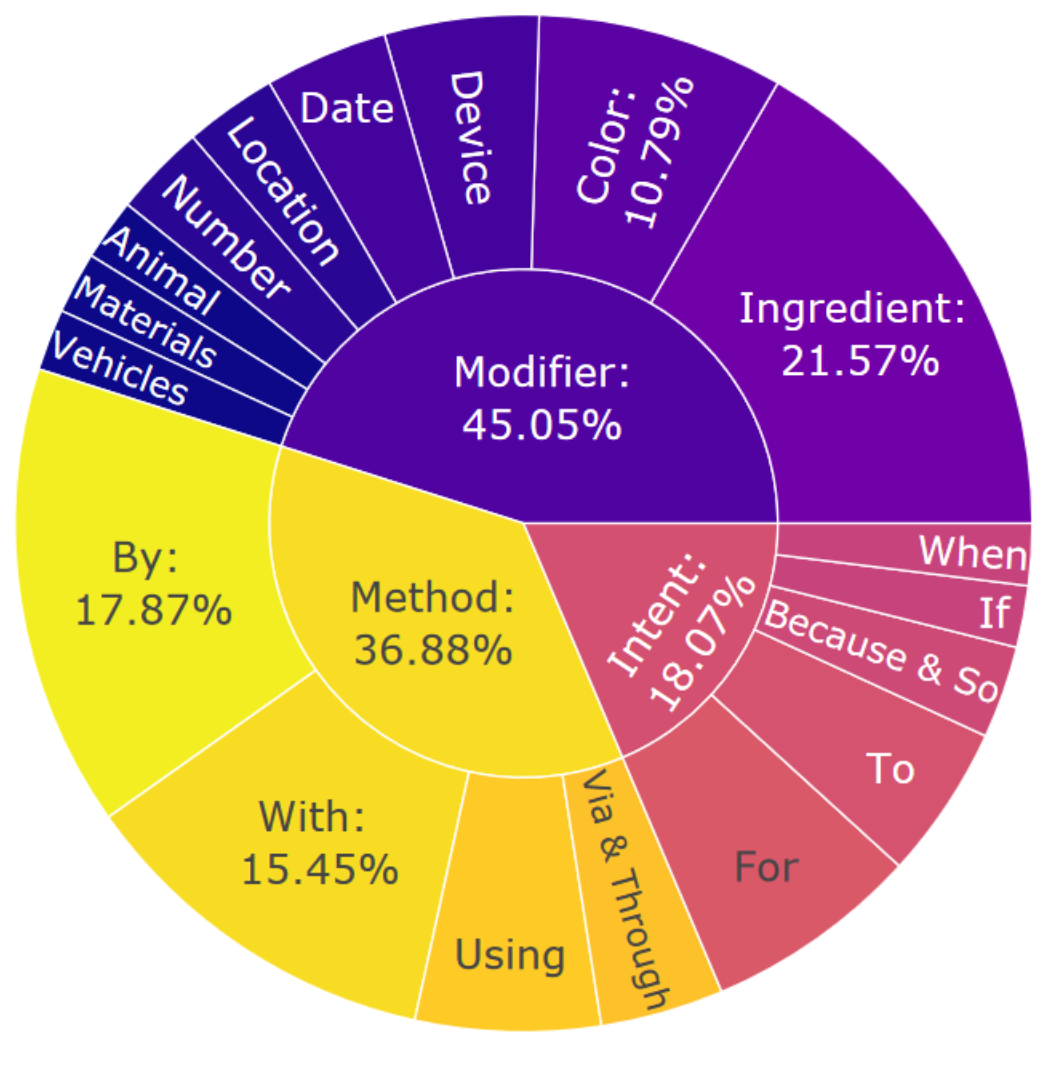
圖4:CoScript的約束分布
圖4顯示了CoScript的約束分布,發現CoScript在生成的具體目標中顯示出高度的異質性和多元化。有趣的是,InstructGPT傾向于以“if”或“when”這樣的詞語開始假設性約束(例如,“如果有人對乳糖不耐受,則制作蛋糕”),這表明未來在語言規劃中進行反事實推理的研究潛力。
四、小模型的約束規劃能力
有了CoScript,可以為受限制的語言規劃訓練更小但更專業化的模型。表5顯示了在wikiHow和CoScript上訓練的模型的比較。一般而言,CoScript訓練的LMs表現優于wikiHow。T5在忠實度上優于GPT-2,可能是由于其編碼器-解碼器框架更擅長處理輸入信息。然而,在其他文本生成指標上,GPT-2優于T5。這可能是因為CoScript是從InstructGPT蒸餾而來,導致數據分布存在偏差,偏向于僅解碼的因果語言模型,例如GPT系列。而且我們發現使用檢索示例來增強模型可以提高語義完整性。
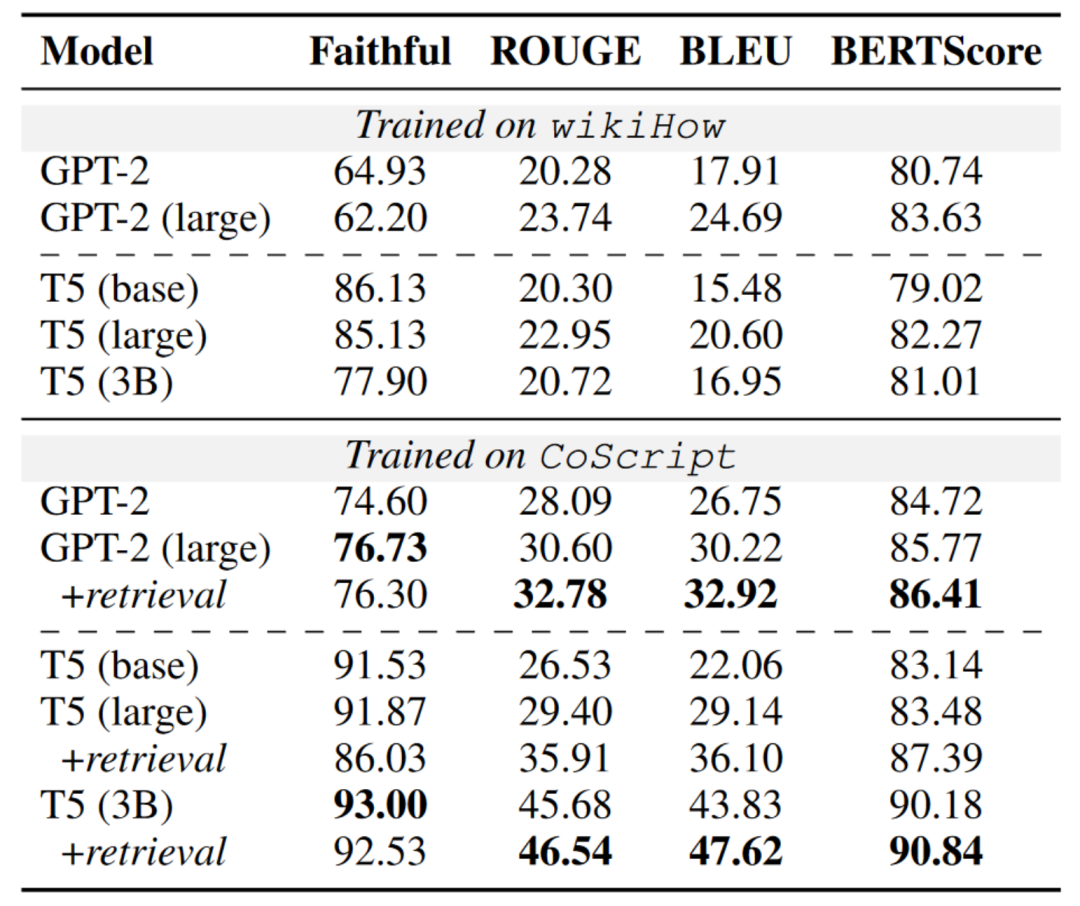
表5:不同訓練集上模型的總體腳本生成性能。請注意,所有模型的測試集相同。
作者進一步在CoScript和wikiHow上微調T5(3B),以生成§4.4中保留在訓練集之外的具體目標的腳本。表7顯示,使用檢索增強微調的T5可以生成比表3中大多數LLMs質量更高的腳本,這表明當適當地在適當的數據集上進行訓練時,較小的模型也可以超越較大的模型。
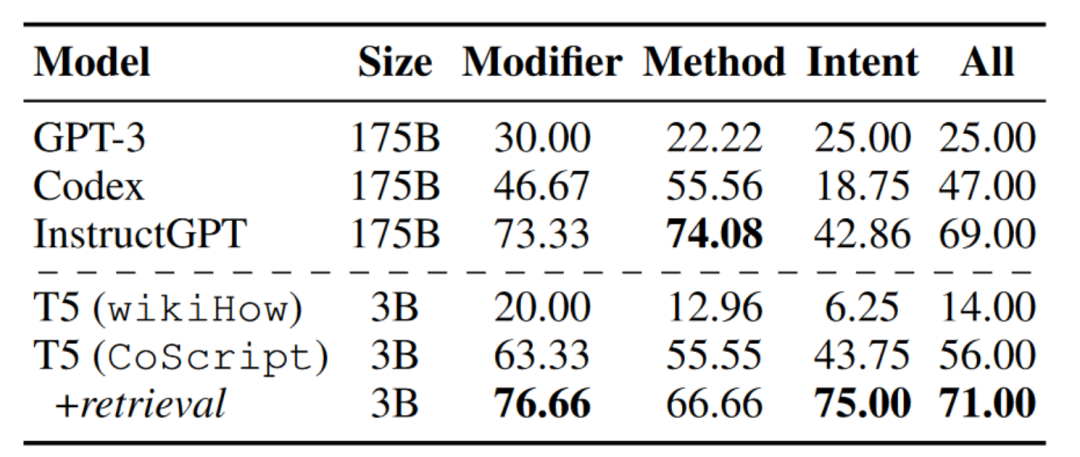
表6:不同模型生成的腳本準確率(%)。我們在wikiHow和CoScript上微調了T5(3B),同時通過少樣本上下文學習來部署LLMs。
五、總 結
本文旨在定義在特定約束條件下朝著特定目標進行規劃。本文作者提出了一種更好的提示方法,用以改進LLMs的受約束語言規劃能力,并從LLMs中提煉出了一個新的數據集(CoScript)。實驗表明,本文的方法提高了LLMs針對特定目標的規劃質量,而在CoScript上訓練的較小模型甚至優于LLMs。希望CoScript數據集能成為推進更加復雜和多樣化目標和約束條件下的語言規劃研究的寶貴資源。
審核編輯:劉清
-
機器人
+關注
關注
211文章
28418瀏覽量
207084 -
人工智能
+關注
關注
1791文章
47274瀏覽量
238468 -
過濾器
+關注
關注
1文章
429瀏覽量
19612 -
GPT
+關注
關注
0文章
354瀏覽量
15372
原文標題:從大模型中蒸餾腳本知識用于約束語言規劃
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文詳解知識增強的語言預訓練模型
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】大語言模型的應用
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
有用于調試的MCU Xpresso IDE調試腳本語言嗎?
深度學習:知識蒸餾的全過程

關于快速知識蒸餾的視覺框架
用于NAT的選擇性知識蒸餾框架
如何度量知識蒸餾中不同數據增強方法的好壞?
如何將ChatGPT的能力蒸餾到另一個大模型

TPAMI 2023 | 用于視覺識別的相互對比學習在線知識蒸餾

任意模型都能蒸餾!華為諾亞提出異構模型的知識蒸餾方法






 工商網監
工商網監
評論