") 開源了!UniControl:可控視覺生成的統(tǒng)一擴散模型
開源了!UniControl:可控視覺生成的統(tǒng)一擴散模型
來自 Salesforce AI、東北大學、斯坦福大學的研究者提出了 MOE-style Adapter 和 Task-aware HyperNet 來實現(xiàn) UniControl 中的多模態(tài)條件生成能力。UniControl 在九個不同的 C2I 任務(wù)上進行訓(xùn)練,展示了強大的視覺生成能力和 zero-shot 泛化能力。

論文地址:https://arxiv.org/abs/2305.11147
代碼地址:https://github.com/salesforce/UniControl
項目主頁:https://shorturl.at/lmMX6
引言:Stable Diffusion 表現(xiàn)出了強大的視覺生成能力。然而,它們在生成具有空間、結(jié)構(gòu)或幾何控制的圖像方面常常表現(xiàn)不足。ControlNet [1] 和 T2I-adpater [2] 等工作實現(xiàn)針對不同模態(tài)的可控圖片生成,但能夠在單一統(tǒng)一的模型中適應(yīng)各種視覺條件,仍然是一個未解決的挑戰(zhàn)。UniControl 在單一的框架內(nèi)合并了各種可控的條件到圖像(C2I)任務(wù)。為了使 UniControl 有能力處理多樣的視覺條件,作者引入了一個任務(wù)感知的 HyperNet 來調(diào)節(jié)下游的條件擴散模型,使其能夠同時適應(yīng)不同的 C2I 任務(wù)。UniControl 在九個不同的 C2I 任務(wù)上進行訓(xùn)練,展示了強大的視覺生成能力和 zero-shot 泛化能力。作者已開源模型參數(shù)和推理代碼,數(shù)據(jù)集和訓(xùn)練代碼也將盡快開源,歡迎大家交流使用。

圖 1: UniControl 模型由多個預(yù)訓(xùn)練任務(wù)和 zero-shot 任務(wù)組成
動機:現(xiàn)有的可控圖片生成模型都是針對單一的模態(tài)進行設(shè)計,然而 Taskonomy [3] 等工作證明不同的視覺模態(tài)之間共享特征和信息,因此本文認為統(tǒng)一的多模態(tài)模型具有巨大的潛力。
解決:本文提出了 MOE-style Adapter 和 Task-aware HyperNet 來實現(xiàn) UniControl 中的多模態(tài)條件生成能力。并且作者建立了一個新的數(shù)據(jù)集 MultiGen-20M,包含 9 大任務(wù),超過兩千萬個 image-condition-prompt 三元組,圖片尺寸≥512。
優(yōu)點:1) 更緊湊的模型 (1.4B #params, 5.78GB checkpoint),更少的參數(shù)實現(xiàn)多個 tasks。2) 更強大的視覺生成能力和控制的準確性。3) 在從未見過的模態(tài)上的 zero-shot 泛化能力。
1.介紹
生成式基礎(chǔ)模型正在改變人工智能在自然語言處理、計算機視覺、音頻處理和機器人控制等領(lǐng)域的交互方式。在自然語言處理中,像 InstructGPT 或 GPT-4 這樣的生成式基礎(chǔ)模型在各種任務(wù)上都表現(xiàn)優(yōu)異,這種多任務(wù)處理能力是最吸引人的特性之一。此外,它們還可以進行 zero-shot 或 few-shot 的學習來處理未見過的任務(wù)。
然而,在視覺領(lǐng)域的生成模型中,這種多任務(wù)處理能力并不突出。雖然文本描述提供了一種靈活的方式來控制生成的圖像的內(nèi)容,但它們在提供像素級的空間、結(jié)構(gòu)或幾何控制方面往往不足。最近熱門研究例如 ControlNet,T2I-adapter 可以增強 Stable Diffusion Model (SDM) 來實現(xiàn)精準的控制。然而,與可以由 CLIP 這樣的統(tǒng)一模塊處理的語言提示不同,每個 ControlNet 模型只能處理其訓(xùn)練過的特定模態(tài)。
為了克服先前工作的限制,本文提出了 UniControl,一個能同時處理語言和各種視覺條件的統(tǒng)一擴散模型。UniControl 的統(tǒng)一設(shè)計可以享受到提高訓(xùn)練和推理效率以及增強可控生成的優(yōu)點。另一方面,UniControl 從不同視覺條件之間的固有聯(lián)系中獲益,來增強每個條件的生成效果。
UniControl 的統(tǒng)一可控生成能力依賴于兩個部分,一個是 “MOE-style Adapter”,另一個是 “Task-aware HyperNet”。MOE-style Adapter 有 70K 左右的參數(shù),可以從各種模態(tài)中學習低級特征圖,Task-aware HyperNet 可以將任務(wù)指令作為自然語言提示輸入,并輸出任務(wù) embedding 嵌入下游的網(wǎng)絡(luò)中,來調(diào)制下游模型的參數(shù)來適應(yīng)不同模態(tài)的輸入。
該研究對 UniControl 進行預(yù)訓(xùn)練,以獲得多任務(wù)和 zero-shot 學習的能力,包括五個類別的九個不同任務(wù):邊緣 (Canny, HED, Sketch),區(qū)域映射 (Segmentation, Object Bound Box),骨架 (Human Skeleton),幾何圖 (Depth, Normal Surface) 和圖片編輯 (Image Outpainting)。然后,該研究在 NVIDIA A100 硬件上訓(xùn)練 UniControl 超過 5000 個 GPU 小時 (當前新模型仍在繼續(xù)訓(xùn)練)。并且 UniControl 展現(xiàn)出了對新任務(wù)的 zero-shot 適應(yīng)能力。
該研究的貢獻可以概括如下:
該研究提出了 UniControl,一個能處理各種視覺條件的統(tǒng)一模型 (1.4B #params, 5.78GB checkpoint),用于可控的視覺生成。
該研究收集了一個新的多條件視覺生成數(shù)據(jù)集,包含超過 2000 萬個圖像 - 文本 - 條件三元組,涵蓋五個類別的九個不同任務(wù)。
該研究進行了實驗,證明了統(tǒng)一模型 UniControl 由于學習了不同視覺條件之間的內(nèi)在關(guān)系,超過了每個單任務(wù)的受控圖像生成。
UniControl 表現(xiàn)出了以 zero-shot 方式適應(yīng)未見過的任務(wù)的能力,展現(xiàn)了其在開放環(huán)境中廣泛使用的可能性和潛力。
2. 模型設(shè)計
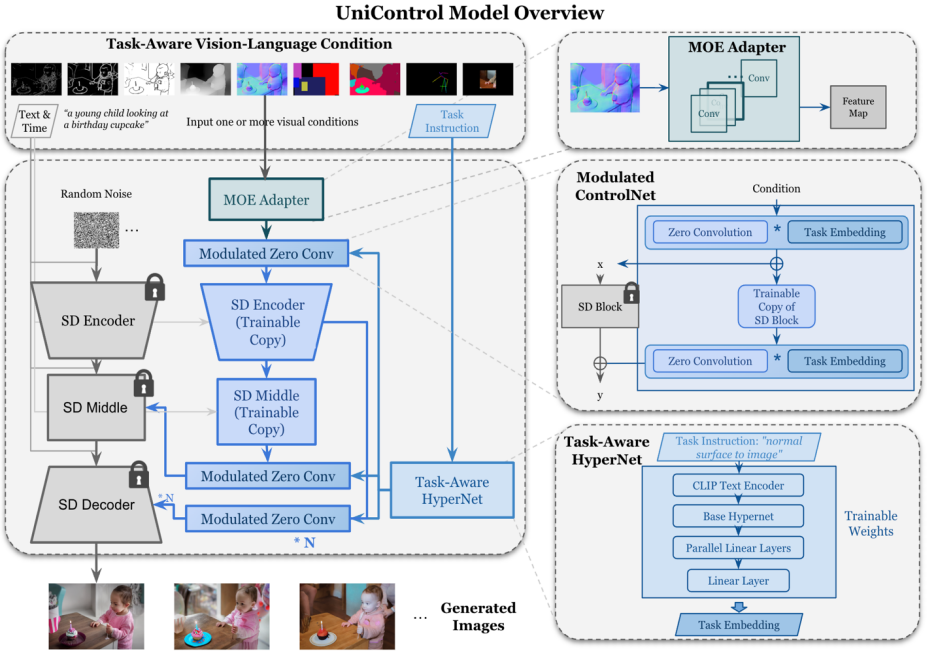
圖 2: 模型結(jié)構(gòu)。為了適應(yīng)多個任務(wù),該研究設(shè)計了 MOE-style Adapter,每個任務(wù)大約有 70K 個參數(shù),以及一個任務(wù)感知 Task-aware HyperNet(約 12M 參數(shù))來調(diào)制 7 個零卷積層。這個結(jié)構(gòu)允許在一個單一的模型中實現(xiàn)多任務(wù)功能,既保證了多任務(wù)的多樣性,也保留了底層的參數(shù)共享。相比于等效的堆疊的單任務(wù)模型(每個模型大約有 1.4B 參數(shù)),顯著地減少了模型的大小。
UniControl 模型設(shè)計確保了兩個性質(zhì):
1) 克服來自不同模態(tài)的低級特征之間的不對齊。這有助于 UniControl 從所有任務(wù)中學習必要的和獨特的信息。例如,當模型將分割圖作為視覺條件時,可能會忽略 3D 信息。
2) 能夠跨任務(wù)學習元知識。這使得模型能夠理解任務(wù)之間的共享知識以及它們之間的差異。
為了提供這些屬性,模型引入了兩個新穎的模塊:MOE-style Adapter 和 Task-aware HyperNet。
MOE-style Adapter 是一組卷積模塊,每個 Adapter 對應(yīng)一個單獨的模態(tài),靈感來自專家混合模型(MOE),用作 UniControl 捕獲各種低級視覺條件的特征。此適配器模塊具有約 70K 的參數(shù),計算效率極高。此后視覺特征將被送入統(tǒng)一的網(wǎng)絡(luò)中處理。
Task-aware HyperNet 則是通過任務(wù)指令條件對 ControlNet 的零卷積模塊進行調(diào)節(jié)。HyperNet 首先將任務(wù)指令投影為 task embedding,然后研究者將 task embedding 注入到 ControlNet 的零卷積層中。在這里 task embedding 和零卷積層的卷積核矩陣尺寸是對應(yīng)的。類似 StyleGAN [4],該研究直接將兩者相乘來調(diào)制卷積參數(shù),調(diào)制后的卷積參數(shù)作為最終的卷積參數(shù)。因此每個 task 的調(diào)制后零卷積參數(shù)是不一樣的,這里保證了模型對于每個模態(tài)的適應(yīng)能力,除此之外,所有的權(quán)重是共享的。
3. 模型訓(xùn)練
不同于 SDM 或 ControlNet,這些模型的圖像生成條件是單一的語言提示,或如 canny 這樣的單一類型的視覺條件。UniControl 需要處理來自不同任務(wù)的各種視覺條件,以及語言提示。因此 UniControl 的輸入包含四部分: noise, text prompt, visual condition, task instruction。其中 task instruction 可以自然的根據(jù) visual condition 的模態(tài)得到。

有了這樣生成的訓(xùn)練配對,該研究采用 DDPM [5] 對模型進行訓(xùn)練。
4. 實驗結(jié)果

圖 6: 測試集視覺對比結(jié)果。測試數(shù)據(jù)來自于 MSCOCO [6] 和 Laion [7]
與官方或該研究復(fù)現(xiàn)的 ControlNet 對比結(jié)果如圖 6 所示,更多結(jié)果請參考論文。
5.Zero-shot Tasks 泛化
模型在以下兩個場景中測試 zero-shot 能力:
混合任務(wù)泛化:該研究考慮兩種不同的視覺條件作為 UniControl 的輸入,一個是分割圖和人類骨骼的混合,并在文本提示中添加特定關(guān)鍵詞 “背景” 和 “前景”。此外,該研究將混合任務(wù)指令重寫為結(jié)合的兩個任務(wù)的指令混合,例如 “分割圖和人類骨骼到圖像”。
新任務(wù)泛化:UniControl 需要在新的未見過的視覺條件上生成可控制的圖像。為了實現(xiàn)這一點,基于未見過的和見過的預(yù)訓(xùn)練任務(wù)之間的關(guān)系估計任務(wù)權(quán)重至關(guān)重要。任務(wù)權(quán)重可以通過手動分配或計算嵌入空間中的任務(wù)指令的相似度得分來估計。MOE-style Adapter 可以與估計的任務(wù)權(quán)重線性組裝,以從新的未見過的視覺條件中提取淺層特征。
可視化的結(jié)果如圖 7 所示,更多結(jié)果請參考論文。

圖 7: UniControl 在 Zero-shot tasks 上的可視化結(jié)果
6.總結(jié)
總的來說,UniControl 模型通過其控制的多樣性,為可控視覺生成提供了一個新的基礎(chǔ)模型。這種模型能夠為實現(xiàn)圖像生成任務(wù)的更高水平的自主性和人類控制能力提供可能。該研究期待和更多的研究者討論和合作,以進一步推動這一領(lǐng)域的發(fā)展。
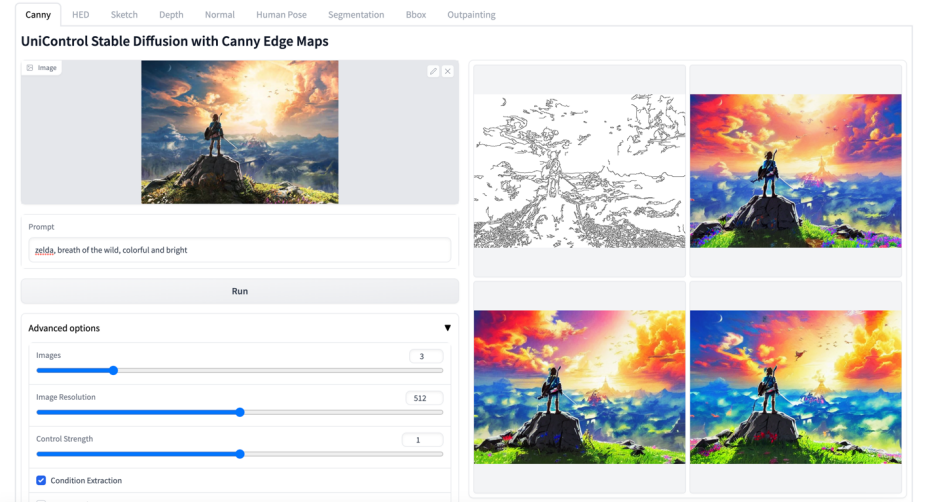
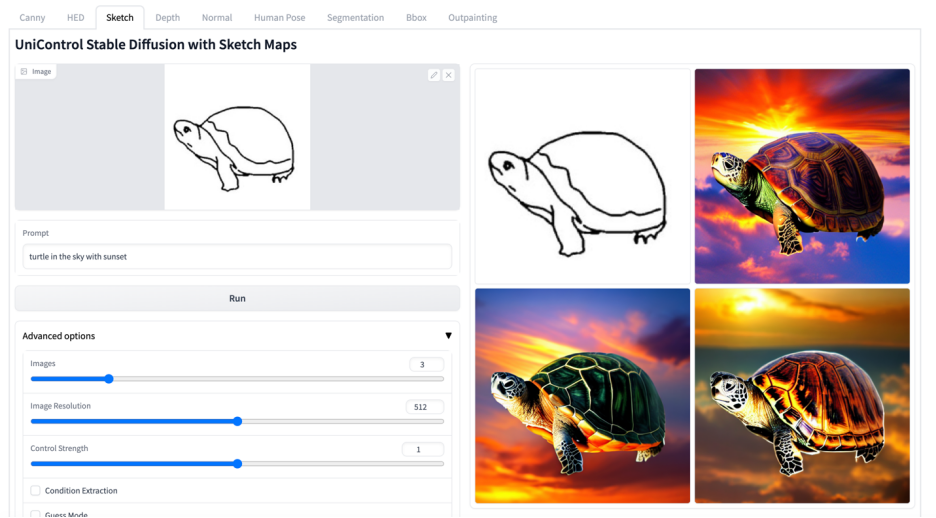
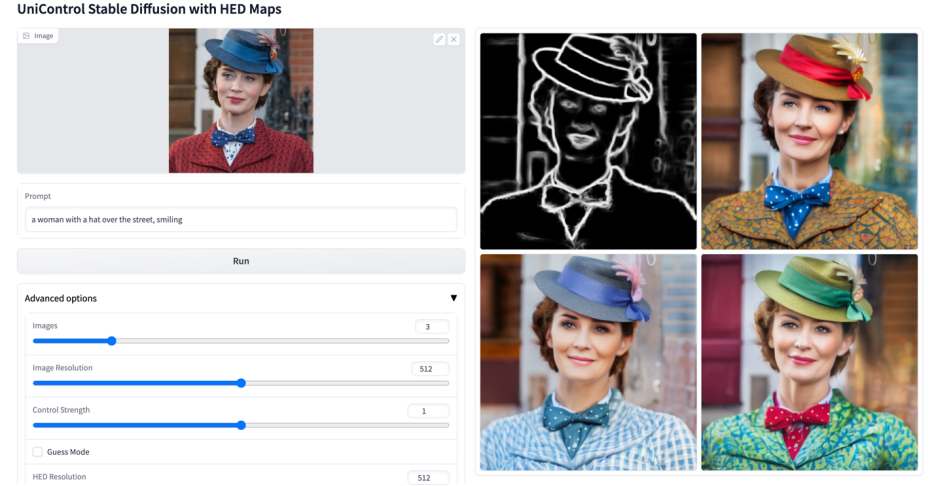
更多視覺效果
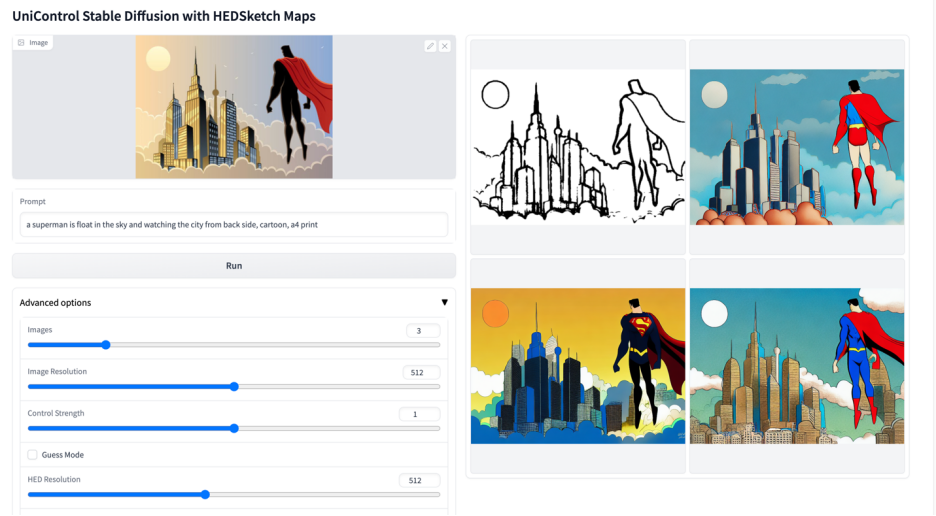
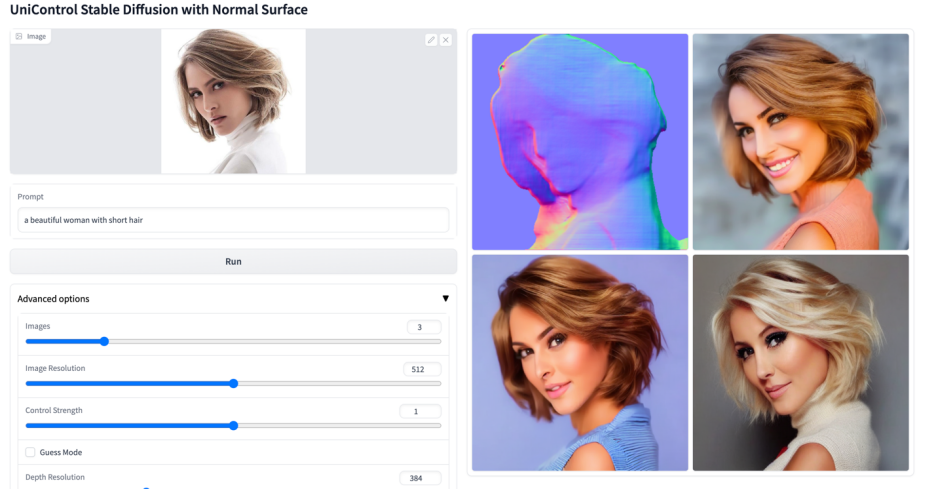
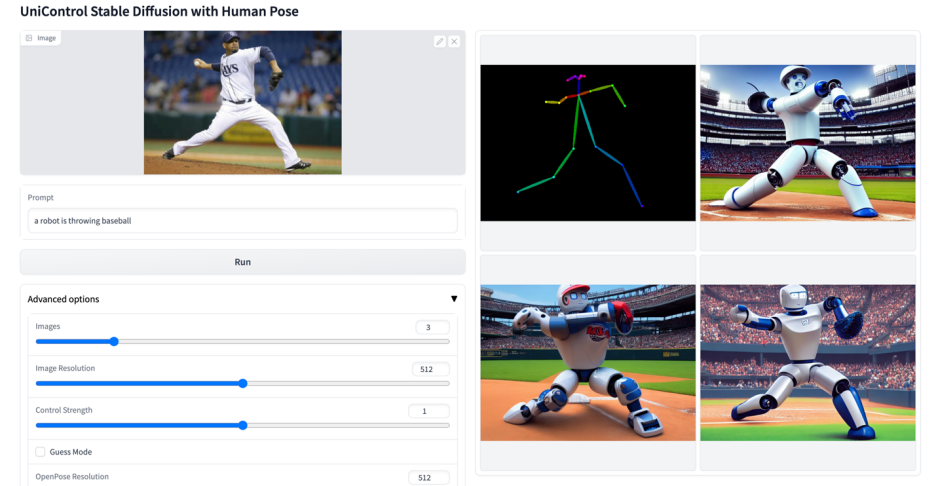
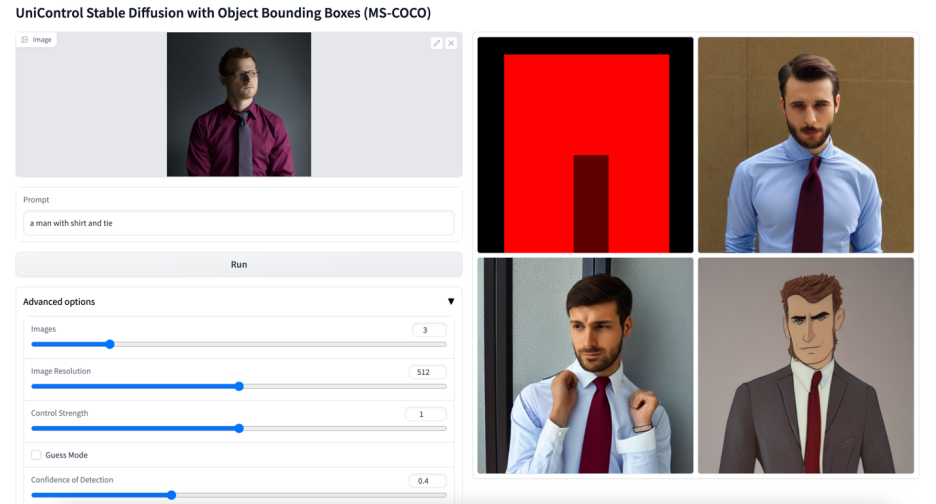
-
圖像
+關(guān)注
關(guān)注
2文章
1091瀏覽量
40669 -
模型
+關(guān)注
關(guān)注
1文章
3406瀏覽量
49457 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1212瀏覽量
24964
原文標題:開源了!UniControl:可控視覺生成的統(tǒng)一擴散模型
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于擴散模型的圖像生成過程

如何在PyTorch中使用擴散模型生成圖像

視覺詞袋模型生成方法
擴散模型在視頻領(lǐng)域表現(xiàn)如何?
如何改進和加速擴散模型采樣的方法2
蒸餾無分類器指導(dǎo)擴散模型的方法
基于文本到圖像模型的可控文本到視頻生成

CLE Diffusion:可控光照增強擴散模型

基于DiAD擴散模型的多類異常檢測工作

機器人基于開源的多模態(tài)語言視覺大模型

擴散模型的理論基礎(chǔ)

浙大、微信提出精確反演采樣器新范式,徹底解決擴散模型反演問題

基于移動自回歸的時序擴散預(yù)測模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論