 性能媲美同時成本降低98%,斯坦福提出FrugalGPT,研究卻惹爭議
性能媲美同時成本降低98%,斯坦福提出FrugalGPT,研究卻惹爭議
Game Changer 還是標題黨?
隨著大型語言模型(LLM)的發展,人工智能正處于變革的爆發期。眾所周知,LLM 可用于商業、科學和金融等應用,因而越來越多的公司(OpenAI、AI21、CoHere 等)都在提供 LLM 作為基礎服務。雖然像 GPT-4 這樣的 LLM 在問答等任務中取得了前所未有的性能,但因為其高吞吐量的特質,使得它們在應用中非常昂貴。
例如,ChatGPT 每天的運營成本超過 70 萬美元,而使用 GPT-4 來支持客戶服務可能會讓一個小企業每月花費超過 2.1 萬美元。除了金錢成本外,使用最大的 LLM 還會帶來巨大的環境和能源影響。
現在很多公司通過 API 提供 LLM 服務,它們收費各異。使用 LLM API 的成本通常包括三個組成部分:1)prompt 成本(與 prompt 的長度成比例),2)生成成本(與生成的長度成比例),以及 3)有時還會有對于每個查詢的固定成本。
下表 1 比較了 12 個不同商業 LLM 的成本,這些 LLM 來自主流供應商,包括 OpenAI、AI21、CoHere 和 Textsynth。它們的成本相差高達 2 個數量級:例如,對于 1000 萬個 token,OpenAI 的 GPT-4 的 prompt 成本為 30 美元,而 Textsynth 托管的 GPT-J 僅為 0.2 美元。
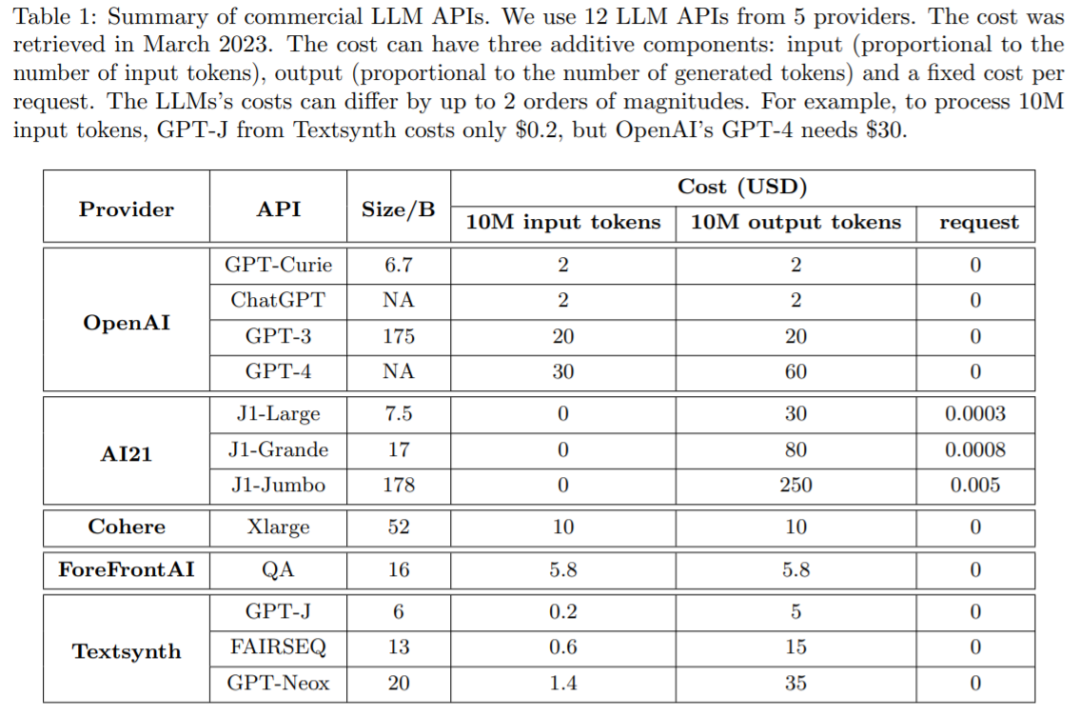
成本和準確性之間的平衡是決策制定的關鍵因素,尤其是在采用新技術時。如何有效和高效地利用 LLM 是從業者面臨的關鍵挑戰:如果任務相對簡單,那么聚合來自 GPT-J (其規模比 GPT-3 小 30 倍)的多個響應可以實現與 GPT-3 類似的性能,從而實現成本和環境上的權衡。然而,在較為困難任務上,GPT-J 的性能可能會大大下降。因此,如何經濟高效地使用 LLM 需要采用新的方法。
最近的一項研究嘗試提出解決這一成本問題的方法,研究者通過實驗表明,FrugalGPT 可以與最佳個體 LLM(例如 GPT-4) 的性能相媲美,成本降低高達 98%,或者在相同成本下將最佳個體 LLM 的準確性提高 4%。

論文地址:https://arxiv.org/pdf/2305.05176.pdf
來自斯坦福大學的研究者回顧了使用 LLM API(例如 GPT-4,ChatGPT,J1-Jumbo)所需的成本,并發現這些模型具有不同的定價,費用可能相差兩個數量級,特別是在大量查詢和文本上使用 LLM 可能更昂貴。基于這一點,該研究概述并討論了用戶可以利用的三種策略來降低使用 LLM 的推理成本:1)prompt 適應,2)LLM 近似和 3)LLM 級聯。此外,該研究提出了級聯 LLM 一個簡單而靈活的實例 FrugalGPT,它學習在不同查詢中使用哪些 LLM 組合以減少成本并提高準確性。
這項研究提出的思想和發現為可持續高效地使用 LLM 奠定了基礎。如果能夠在不增加預算的情況下采用更高級的 AI 功能,這可能會推動人工智能技術在各個行業的更廣泛采用,即使是較小的企業也有能力在其運營中實施復雜的人工智能模型。
當然,這只是一個角度,FrugalGPT 到底能實現怎樣的影響力,能否成為「AI 行業的游戲規則改變者」,還需要一段時間才能揭曉。在論文發布之后,這項研究也引發了一些爭議:
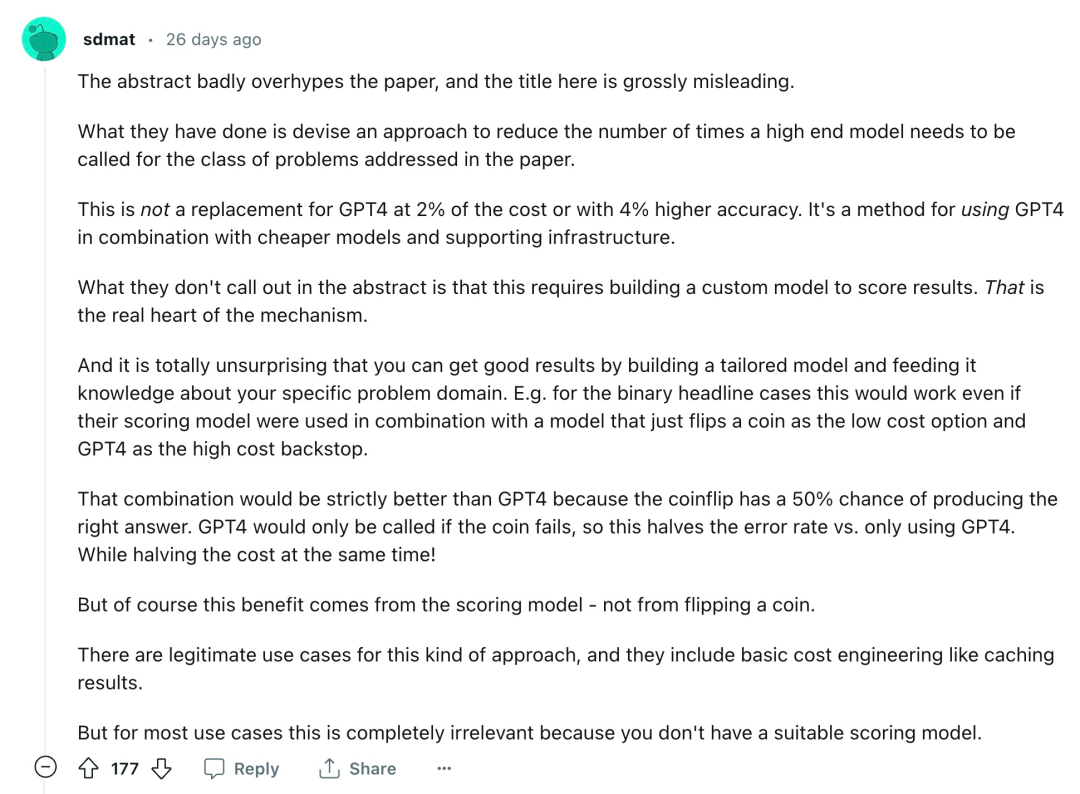
「摘要嚴重夸大了論文的內容,這里的標題也有嚴重的誤導性。他們所做的是設計了一種方法,以減少在論文中所涉及的一類問題中需要調用高端模型的次數。這不是以 2% 的成本替代 GPT-4,也不是以 4% 的精度替代 GPT-4。它是一種將 GPT-4 與更低廉的模型和支持性基礎設施相結合的方法。摘要中沒有指出的是,這需要建立一個自定義模型來對結果進行評分,而這是該機制的真正核心。…… 這種方法有合法的用例,其中包括基本的成本工程,如緩存結果。但對于大多數用例來說,這完全不相關,因為你沒有一個合適的評分模型。」

「他們只在三個(小的)數據集上評估了這一點,并且沒有提供關于 FrugalGPT 選擇各自模型的頻率的信息。另外,他們報告說較小的模型取得了比 GPT-4 更高的準確性,這使我對這篇論文總體上非常懷疑。」
具體如何判斷,讓我們看一下論文內容。
如何經濟、準確地使用 LLM
接下來論文介紹了如何在預算范圍內高效的使用 LLM API。如圖 1 (b) 所示,該研究討論了三種降低成本的策略,即 prompt 適應、LLM 近似和 LLM 級聯。
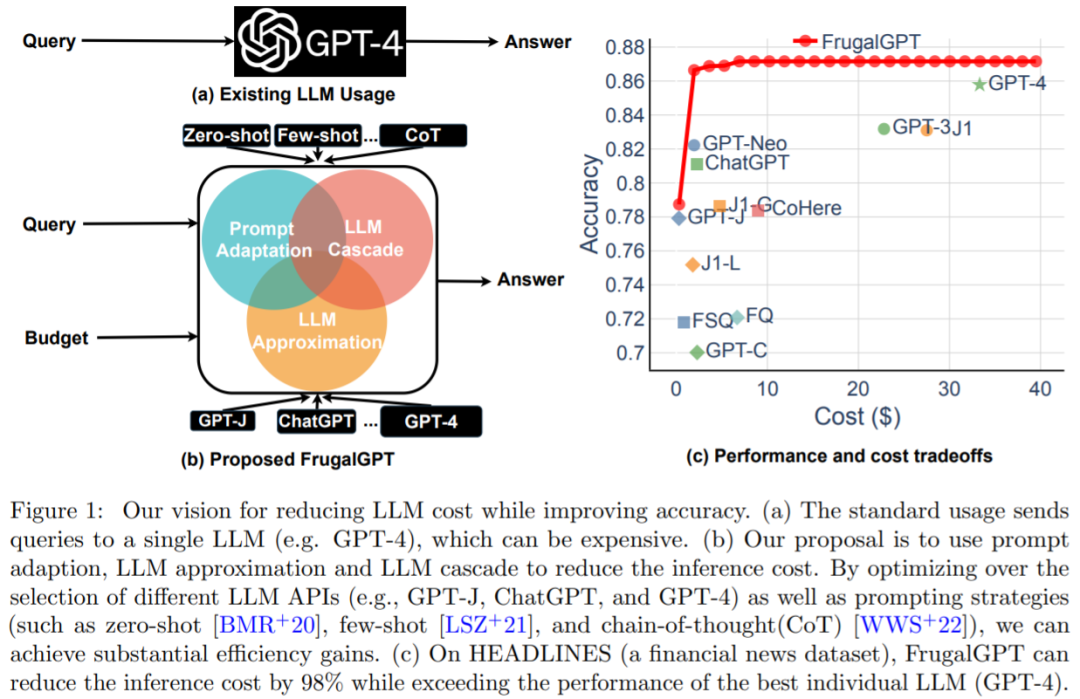
策略 1:prompt 適應。LLM 查詢的成本與 prompt 的大小呈線性增長。因此,降低使用 LLM API 成本的一個合理方法包括減小 prompt 大小,該研究將這個過程稱為 prompt 適應。prompt 選擇如圖 2(a)所示:與使用包含許多示例以演示如何執行任務的 prompt 相比,可以只保留 prompt 中的一個小子集示例。這將導致更小的 prompt 和更低的成本。另一個例子是查詢串聯(圖 2(b)所示)。
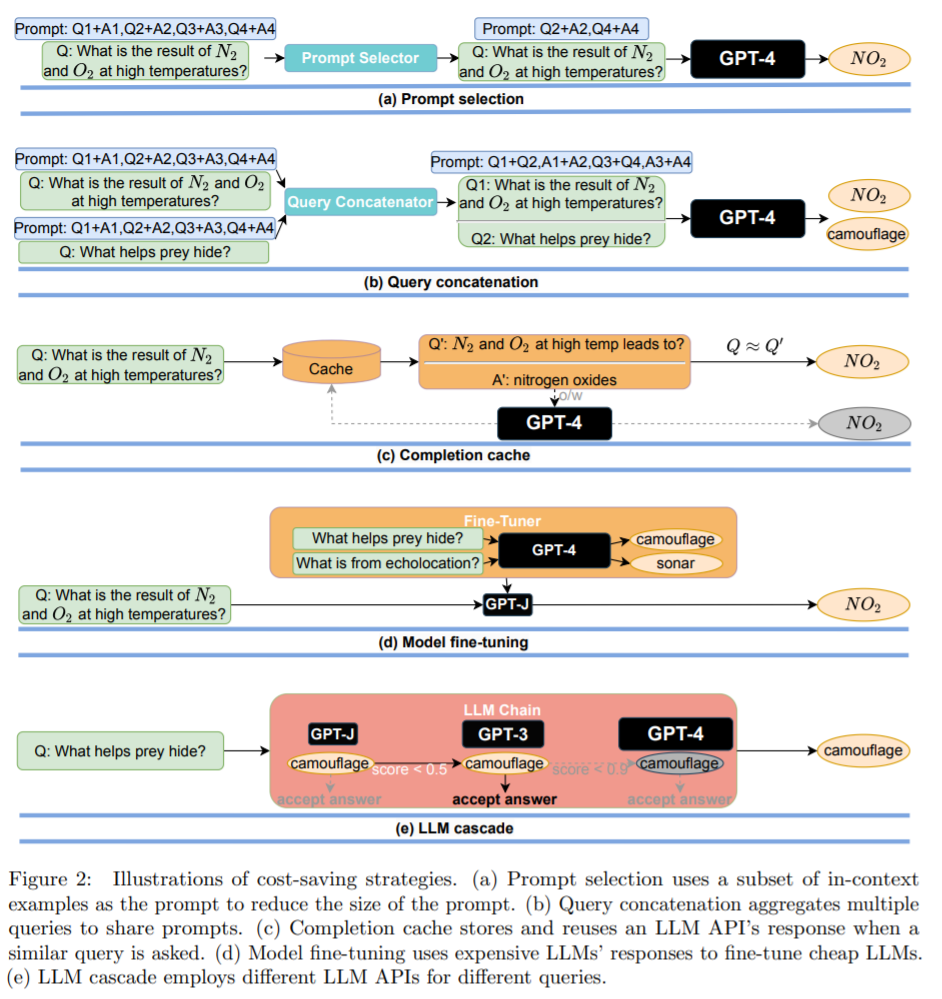
策略 2:LLM 近似。LLM 近似的概念非常簡單:如果使用 LLM API 成本太高,可以使用更實惠的模型或基礎設施進行近似。其中一個例子如圖 2(c)所示,其基本思想是在向 LLM API 提交查詢時將響應存儲在本地緩存(例如數據庫)中。LLM 近似的另一個例子是模型微調,如圖 2 (d) 所示。
策略 3:LLM 級聯。不同的 LLM API 在各種查詢中都有自己的優勢和劣勢。因此,適當選擇要使用的 LLM 既能降低成本又能提高性能。如圖 2(e)所示為 LLM 級聯的一個例子。
成本的降低與精度的提高
研究者進行了一項關于 FrugalGPT LLM 級聯的實證研究,目標有三個:
了解 LLM 級聯的簡單實例所學習的內容;
量化 FrugalGPT 在匹配最佳的單個 LLM API 的性能時實現的成本節約;
衡量 FrugalGPT 所實現的性能和成本之間的 trade-off。
實驗設置分為幾方面:LLM API(表 1)、任務、數據集(表 2)和 FrugalGPT 實例。
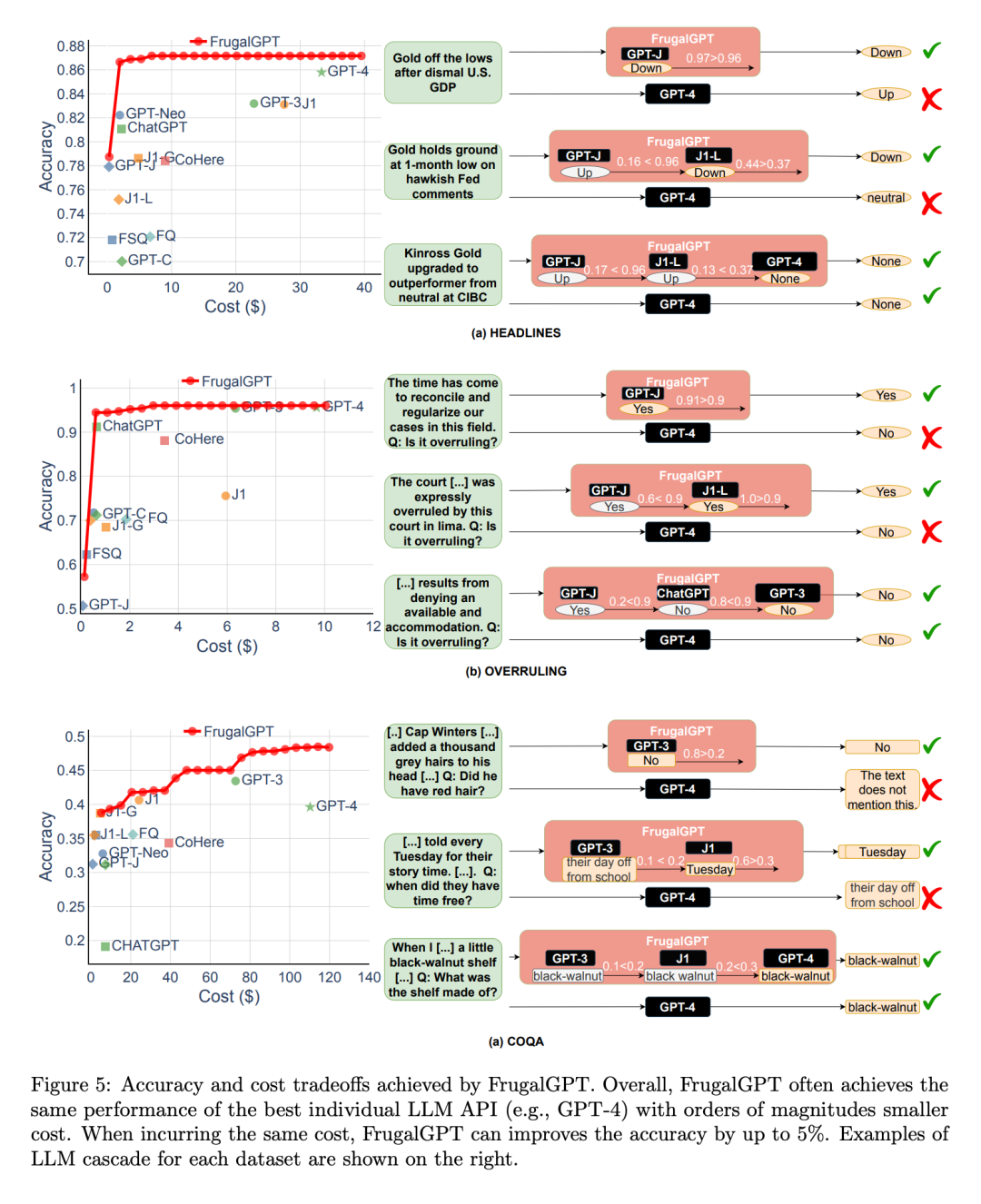
FrugalGPT 是在上述 API 之上開發的,并在一系列屬于不同任務的數據集上進行了評估。其中,HEADLINES 是一個金融新聞數據集,目標是通過閱讀金融新聞標題來確定金價趨勢(上升、下降、中性或無),這對于過濾金融市場的相關新聞特別有用;OVERRULING 是一個法律文件數據集,其目標是確定一個給定的句子是否是一個「overruling」,即推翻以前的法律案件;COQA 是一個在對話環境中開發的閱讀理解數據集,研究者將其改編為一個直接查詢回答任務。 他們專注于 LLM 級聯方法,級聯長度為 3,因為這簡化了優化空間,并且已經展示了良好的結果。每個數據集被隨機分成一個訓練集來學習 LLM 級聯和一個測試集進行評估。
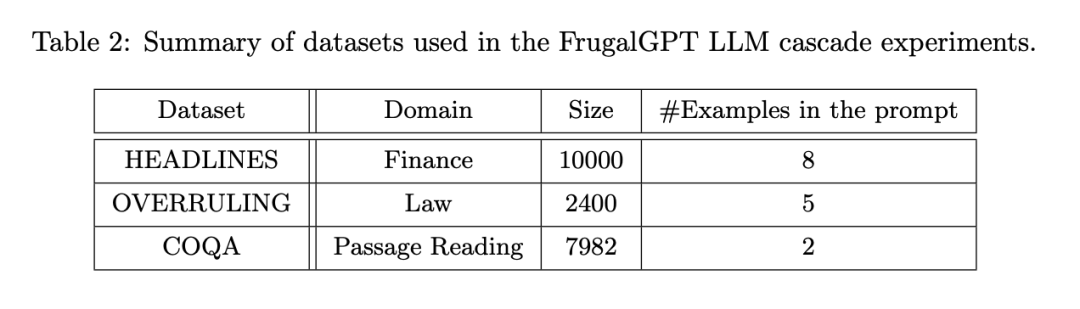
這里是一個 HEADLINES 數據集案例研究:設定預算為 6.5 美元,是 GPT-4 成本的五分之一。采用針對回歸的 DistilBERT [SDCW19] 作為評分函數。值得注意的是,DistilBERT 比這里考慮的所有 LLM 都要小得多,因此成本較低。如圖 3(a)所示,學習的 FrugalGPT 順序調用 GPT-J、J1-L 和 GPT-4。對于任何給定的查詢,它首先從 GPT-J 中提取一個答案。如果這個答案的分數大于 0.96,這個答案就被接受為最終的響應。
否則,將對 J1-L 進行查詢。如果 J1-L 的答案得分大于 0.37,則被接受為最終答案;否則,將調用 GPT-4 來獲得最終答案。有趣的是,這種方法在許多查詢中都優于 GPT-4。例如,基于納斯達克的頭條新聞「美國 GDP 數據慘淡,黃金脫離低點」,FrugalGPT 準確地預測了價格將下跌,而 GPT-4 提供了一個錯誤的答案(如圖 3(b)所示)。
總體來說,FrugalGPT 的結果是既提高了準確率又降低了成本。如圖 3 (c) 所示,其成本降低了 80%,而準確率甚至高出 1.5%。
LLM 的多樣性
為什么多個 LLM API 有可能產生比最好的單個 LLM 更好的性能?從本質上講,這是由于生成的多樣性:即使是一個低成本的 LLM 有時也能正確地回答更高成本的 LLM 所不能回答的查詢。為了衡量這種多樣性,研究者使用最大的性能改進,也可以成為 MPI。LLM A 相對于 LLM B 的 MPI 是指 LLM A 產生正確答案而 LLM B 提供錯誤答案的概率。這個指標實質上是衡量在調用 LLM B 的同時調用 LLM A 所能達到的最大性能提升。
圖 4 顯示了所有數據集的每一對 LLM API 之間的 MPI。在 HEADLINES 數據集上,GPT-C、GPT-J 和 J1-L 都可以將 GPT-4 的性能提高 6%。在 COQA 數據集上,有 13% 的數據點 GPT-4 出現了錯誤,但 GPT-3 提供了正確的答案。盡管這些改進的上界可能并不總是可以實現的,但它們確實證明了利用更低廉的服務來實現更好性能的可能性。

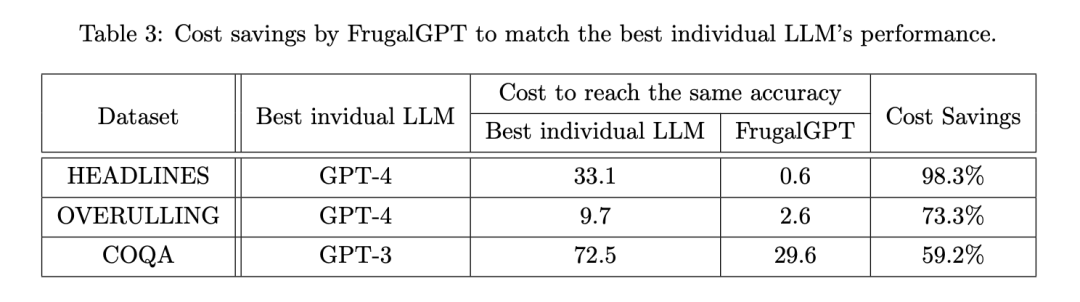
成本節約
隨后,研究者考察了 FrugalGPT 是否能在保持準確性的同時降低成本,如果能,又能降低多少。表 3 顯示了 FrugalGPT 的總體成本節約,范圍從 50% 到 98%。這是可行的,因為 FrugalGPT 可以識別那些可以由較小的 LLM 準確回答的查詢,因此只調用那些具有成本效益的 LLM。而強大但昂貴的 LLM,如 GPT-4,只用于由 FrugalGPT 檢測到的挑戰性查詢。
性能和成本的權衡
接著,研究者探討了 FrugalGPT 實現的性能和成本之間的權衡,如圖 5 所示,得出了幾個有趣的觀察結果。
首先,不同 LLM API 的成本排名并不是固定的。此外,更昂貴的 LLM APIs 有時會導致比其更便宜的同類產品更差的性能。這些觀察結果強調了適當選擇 LLM API 的重要性,即使在沒有預算限制的情況下。
接下來,研究者還注意到,FrugalGPT 能夠在所有被評估的數據集上實現平滑的性能 - 成本權衡。這為 LLM 用戶提供了靈活的選擇,并有可能幫助 LLM API 供應商節約能源和減少碳排放。事實上,FrugalGPT 可以同時降低成本和提高精確度,這可能是因為 FrugalGPT 整合了來自多個 LLM 的知識。
圖 5 所示的例子查詢進一步解釋了為什么 FrugalGPT 可以同時提高性能和降低成本。GPT-4 在一些查詢上犯了錯誤,比如例如(a)部分的第一個例子,但一些低成本的 API 提供了正確的預測。FrugalGPT 準確地識別了這些查詢,并完全依賴低成本的 API。例如,GPT-4 錯誤地從法律陳述「現在是協調和規范我們在這個領域的案件的時候了」中推斷出沒有推翻,如圖 5(b)所示。
然而,FrugalGPT 接受了 GPT-J 的正確答案,避免了昂貴的 LLM 的使用,提高了整體性能。當然,單一的 LLM API 并不總是正確的;LLM 級聯通過采用一連串的 LLM API 克服了這一點。例如,在圖 5 (a) 所示的第二個例子中,FrugalGPT 發現 GPT-J 的生成可能不可靠,于是轉向鏈中的第二個 LLM J1-L,以找到正確的答案。同樣,GPT-4 提供了錯誤的答案。FrugalGPT 并不完美,仍有足夠的空間來減少成本。例如,在圖 5 (c) 的第三個例子中,鏈中所有的 LLM API 都給出了相同的答案。然而,FrugalGPT 不確定第一個 LLM 是否正確,導致需要查詢鏈中的所有 LLM。確定如何避免這種情況仍然是一個開放的問題。
-
API
+關注
關注
2文章
1505瀏覽量
62183 -
GPT
+關注
關注
0文章
354瀏覽量
15439 -
ChatGPT
+關注
關注
29文章
1564瀏覽量
7823
原文標題:GPT-4 API平替?性能媲美同時成本降低98%,斯坦福提出FrugalGPT,研究卻惹爭議
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
斯坦福開發過熱自動斷電電池
突破:提升性能的同時降低電池體積和重量!
關于斯坦福的CNTFET的問題
回收新舊 斯坦福SRS DG645 延遲發生器
DG645 斯坦福 SRS DG645 延遲發生器 現金回收
長期銷售回收Stanford Research SR830斯坦福SR830鎖相放大器
美國 原裝 斯坦福 SR830+SR850鎖定放大器
"現代愛迪生"鎳氫反應電池發明者斯坦福逝世
斯坦福提出基于目標的策略強化學習方法——SOORL






 工商網監
工商網監
評論