


在文章Firefly(流螢): 中文對話式大語言模型、中文對話式大語言模型Firefly-2b6開源,使用210萬訓(xùn)練數(shù)據(jù)中,我們介紹了關(guān)于Firefly(流螢)模型的工作。對大模型進行全量參數(shù)微調(diào)需要大量GPU資源,所以我們通過對Bloom進行詞表裁剪,在4*32G的顯卡上,勉強訓(xùn)練起了2.6B的firefly模型。
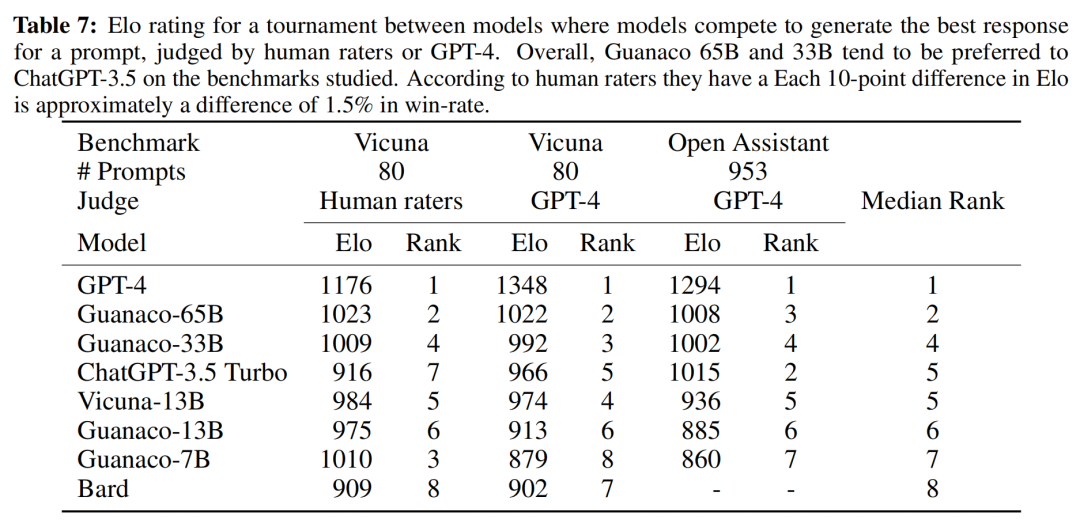
在本文中,我們將介紹QLoRA,由華盛頓大學(xué)提出的一種高效微調(diào)大模型的方法,可在單張A100上對LLaMA-65B進行微調(diào)。在論文中,作者的實驗表明使用QLoRA微調(diào)的LLaMA-65B,可達到ChatGPT性能水平的99.3%(由GPT-4進行評價),并且QLoRA的性能可以逼近全量參數(shù)微調(diào)。作者做了豐富的實驗證明這一結(jié)論。

在本文中我們將對QLoRA的基本原理進行介紹,并且在Firefly項目中進行實踐。我們在bloom-7b1的基礎(chǔ)上,使用QLoRA進行中文指令微調(diào),獲得firefly-7b1-qlora-v0.1模型,具有不錯的效果,生成效果見第三章。QLoRA確實是一種高效訓(xùn)練、效果優(yōu)秀、值得嘗試和深入研究的方法。
論文地址:
https://arxiv.org/pdf/2305.14314.pdf
項目代碼:
https://github.com/yangjianxin1/Firefly
模型權(quán)重:
https://huggingface.co/YeungNLP/firefly-7b1-qlora-v0.1
01
QLoRA簡介
本章節(jié)主要對LoRA與QLoRA進行介紹,如讀者已了解本章節(jié)的內(nèi)容,可直接跳過,閱讀項目實踐部分。
LoRA簡介
在介紹QLoRA之前,簡單回顧一下LoRA。LoRA的本質(zhì)是在原模型的基礎(chǔ)上插入若干新的參數(shù),稱之為adapter。在訓(xùn)練時,凍結(jié)原始模型的參數(shù),只更新adapter的參數(shù)。對于不同的基座模型,adapter的參數(shù)量一般為幾百萬~幾千萬。
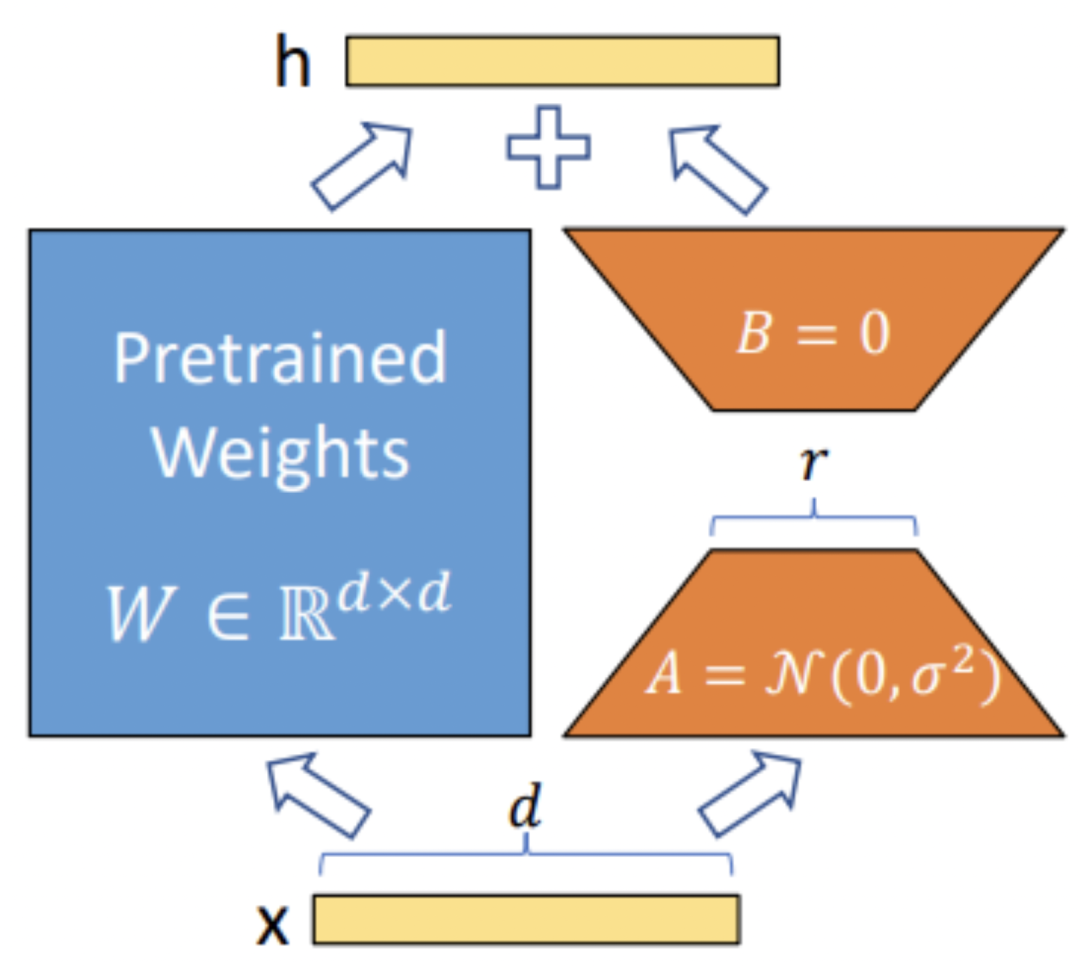
LoRA的優(yōu)勢在于能夠使用較少的GPU資源,在下游任務(wù)中對大模型進行微調(diào)。在開源社區(qū)中,開發(fā)者們使用LoRA對Stable Diffusion進行微調(diào),取得了非常不錯的效果。隨著ChatGPT的火爆,也涌現(xiàn)出了許多使用LoRA對LLM進行指令微調(diào)的工作。
此前,我們也實踐過使用LoRA對LLM進行指令微調(diào),雖然未進行定量分析,但主觀感受LoRA比全量微調(diào)還是有一定的差距。實踐下來,我們發(fā)現(xiàn)LoRA微調(diào)中存在以下三個痛點:
-
參數(shù)空間小:LoRA中參與訓(xùn)練的參數(shù)量較少,解空間較小,效果相比全量微調(diào)有一定的差距。
-
微調(diào)大模型成本高:對于上百億參數(shù)量的模型,LoRA微調(diào)的成本還是很高。
-
精度損失:針對第二點,可以采用int8或int4量化,進一步對模型基座的參數(shù)進行壓縮。但是又會引發(fā)精度損失的問題,降低模型性能。
QLoRA簡介
接下來便引入今天的主角QLoRA。整篇論文讀下來,我們認為QLoRA中比較重要的幾個做法如下:
-
4-bit NormalFloat:提出一種理論最優(yōu)的4-bit的量化數(shù)據(jù)類型,優(yōu)于當(dāng)前普遍使用的FP4與Int4。
-
Double Quantization:相比于當(dāng)前的模型量化方法,更加節(jié)省顯存空間。每個參數(shù)平均節(jié)省0.37bit,對于65B的LLaMA模型,大約能節(jié)省3GB顯存空間。
-
Paged Optimizers:使用NVIDIA統(tǒng)一內(nèi)存來避免在處理小批量的長序列時出現(xiàn)的梯度檢查點內(nèi)存峰值。
-
增加Adapter:4-bit的NormalFloat與Double Quantization,節(jié)省了很多空間,但帶來了性能損失,作者通過插入更多adapter來彌補這種性能損失。在LoRA中,一般會選擇在query和value的全連接層處插入adapter。而QLoRA則在所有全連接層處都插入了adapter,增加了訓(xùn)練參數(shù),彌補精度帶來的性能損失。
通過上述優(yōu)化,只需要41G顯存即可微調(diào)LLaMA-65B模型。甚至可以直接使用一張1080Ti來微調(diào)LLaMA-13B,手中的舊卡又可以繼續(xù)發(fā)揮余熱了。
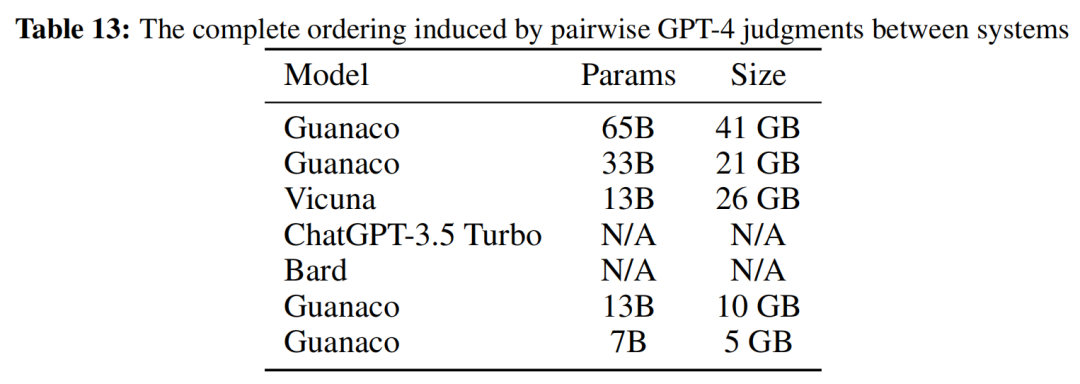
作者使用GPT4對各個模型進行評價,結(jié)果顯示,使用QLoRA在OASST1數(shù)據(jù)集上微調(diào)得到的Guanaco-65B模型達到了ChatGPT的99.3%的性能。
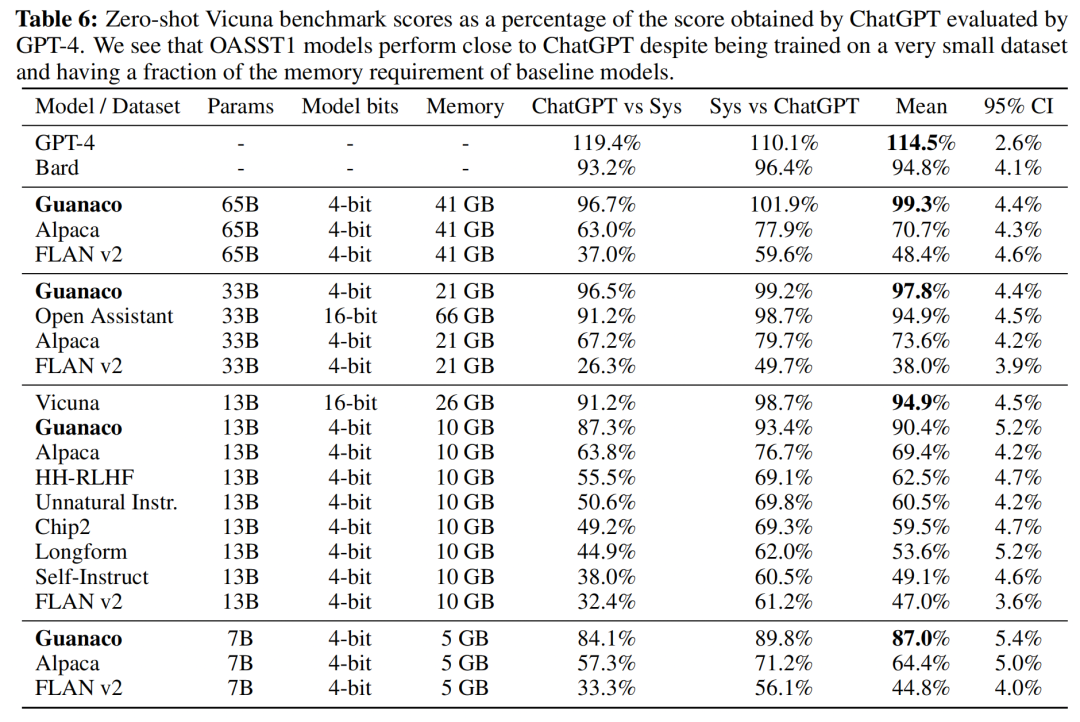
作者進一步采用了Elo等級分制度對各個模型進行評價,裁判為人類或者GPT-4。結(jié)果顯示Guanaco-65B和Guanaco-33B均優(yōu)于ChatGPT-3.5。
實驗分析
QLoRA方法是否有用,其與全量參數(shù)微調(diào)的差距有多大?作者使用LLaMA-7B和Alpaca數(shù)據(jù)集進行了實驗。下圖結(jié)果表明,通過插入更多的adapter,能夠彌補QLoRA量化帶來的性能損失,復(fù)現(xiàn)全量參數(shù)微調(diào)的效果。
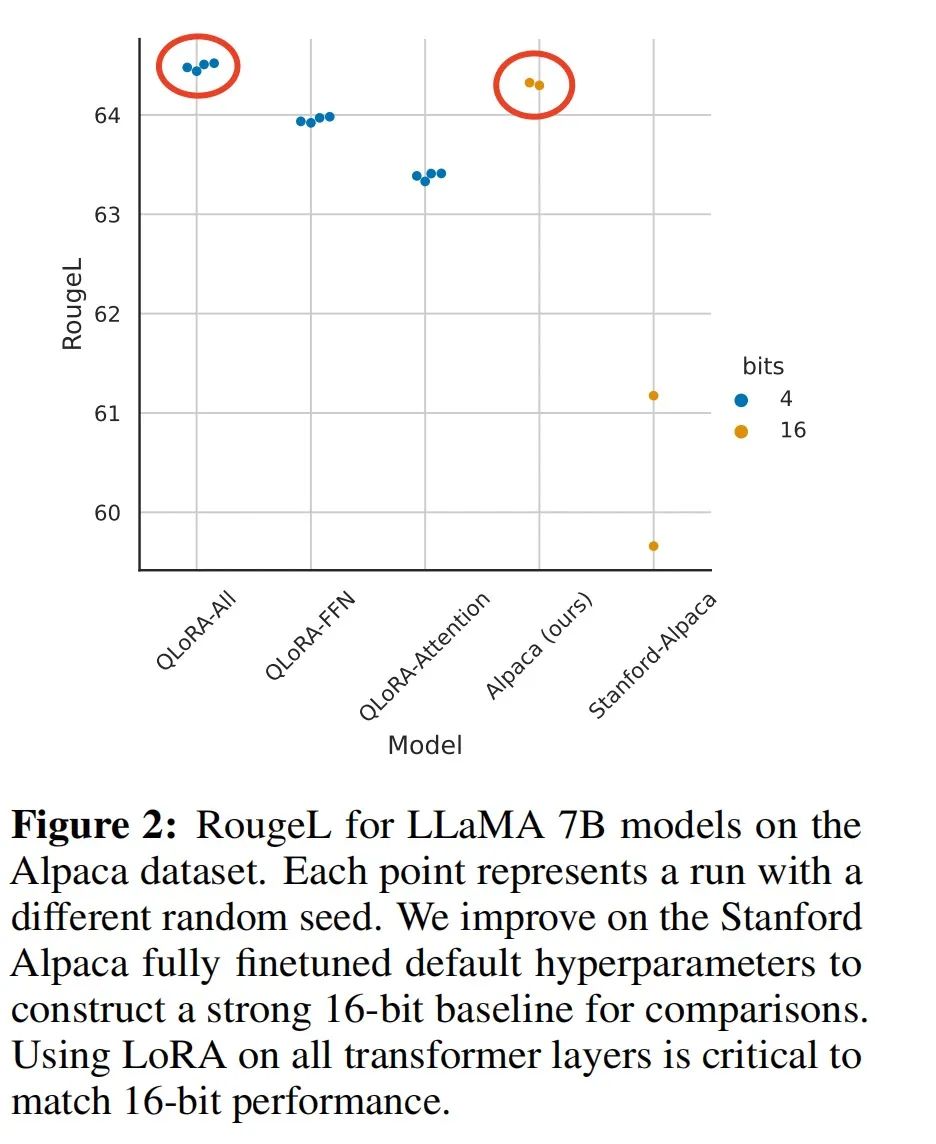
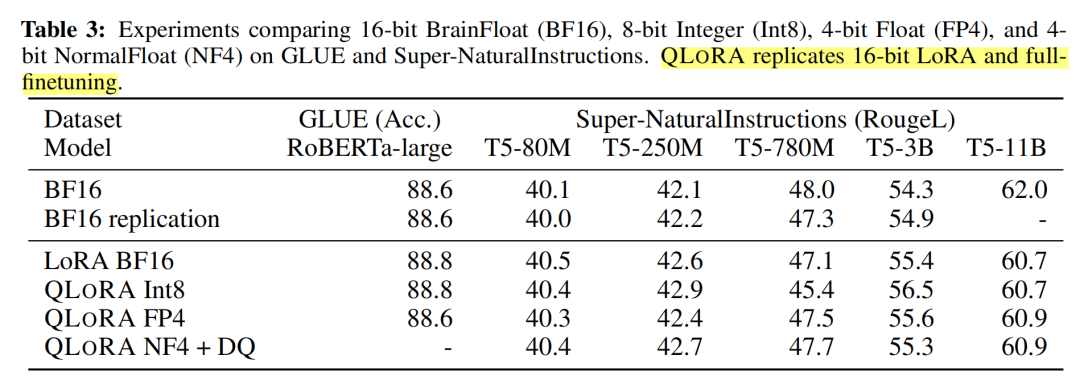
除此之外,作者還將QLoRA應(yīng)用于RoBERTA和T5,評測其在GLUE和Super-NaturalInstructions數(shù)據(jù)集上的表現(xiàn)。從下表中可以看到,QLoRA+NF4+DQ基本上復(fù)現(xiàn)了BF16全量微調(diào)的實驗指標。
下表中LoRA+BF16基本上也復(fù)現(xiàn)了BF16全量微調(diào)的實驗指標,如果作者能加上LoRA+FP4或者LoRA+int4的實驗結(jié)果,則可以更清晰地展現(xiàn)LoRA與QLoRA的性能差異。
在指令微調(diào)階段,數(shù)據(jù)質(zhì)量和數(shù)據(jù)數(shù)量,哪一個更重要?作者使用三種不同的訓(xùn)練集,每個數(shù)據(jù)集分別使用5萬、10萬、15萬的數(shù)據(jù)量進行訓(xùn)練。對于下表,縱向來看,隨著數(shù)據(jù)量的增加,指標并沒有明顯的提升,說明數(shù)據(jù)量不是關(guān)鍵因素。橫向來看,對于不同的數(shù)據(jù)集,指標差距甚大,說明數(shù)據(jù)質(zhì)量更關(guān)鍵。
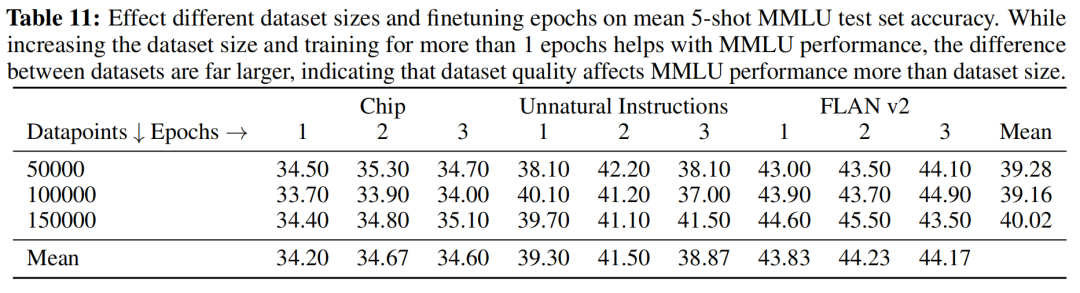
值得一提的是,在論文中,作者僅使用了9千多條OASST1的數(shù)據(jù)訓(xùn)練得到Guanaco-65B,這進一步驗證了,數(shù)據(jù)質(zhì)量遠比數(shù)量重要,模型的知識來源于預(yù)訓(xùn)練階段。
模型的知識來源于預(yù)訓(xùn)練階段,指令微調(diào)目的是和人類指令進行對齊。在指令微調(diào)階段,數(shù)據(jù)的質(zhì)量與豐富度,遠比數(shù)量更重要。這是最近一段時間,開源社區(qū)以及各個論文強調(diào)的一個結(jié)論,在我們的實踐中也深有體會。
02
項目實踐
在本項目中,我們使用bloom-7b1作為基座模型。數(shù)據(jù)集為moss-003-sft-no-tools,這是由MOSS項目開源的中文指令微調(diào)數(shù)據(jù)集,我們隨機抽取了29萬條作為訓(xùn)練數(shù)據(jù),訓(xùn)練得到firefly-7b1-qlora-v0.1。
訓(xùn)練時,我們將多輪對話拼接成如下格式,然后進行tokenize。
<s>input1s>target1s>input2s>target2s>...我們在一張32G顯卡上使用QLoRA進行訓(xùn)練,在所有全連接層處都插入adapter,最終參與訓(xùn)練的參數(shù)量超過1億,相當(dāng)于一個bert-base的參數(shù)量。訓(xùn)練時只計算target部分的損失函數(shù)。
訓(xùn)練超參數(shù)如下所示:
| max length | 1024 |
| lr_scheduler_type | cosine |
| batch size | 16 |
| lr | 2e-4 |
| warmup step | 3000 |
| optimizer | paged_adamw_32bit |
| training step | 18萬 |
模型的訓(xùn)練損失的變化趨勢如下圖所示:
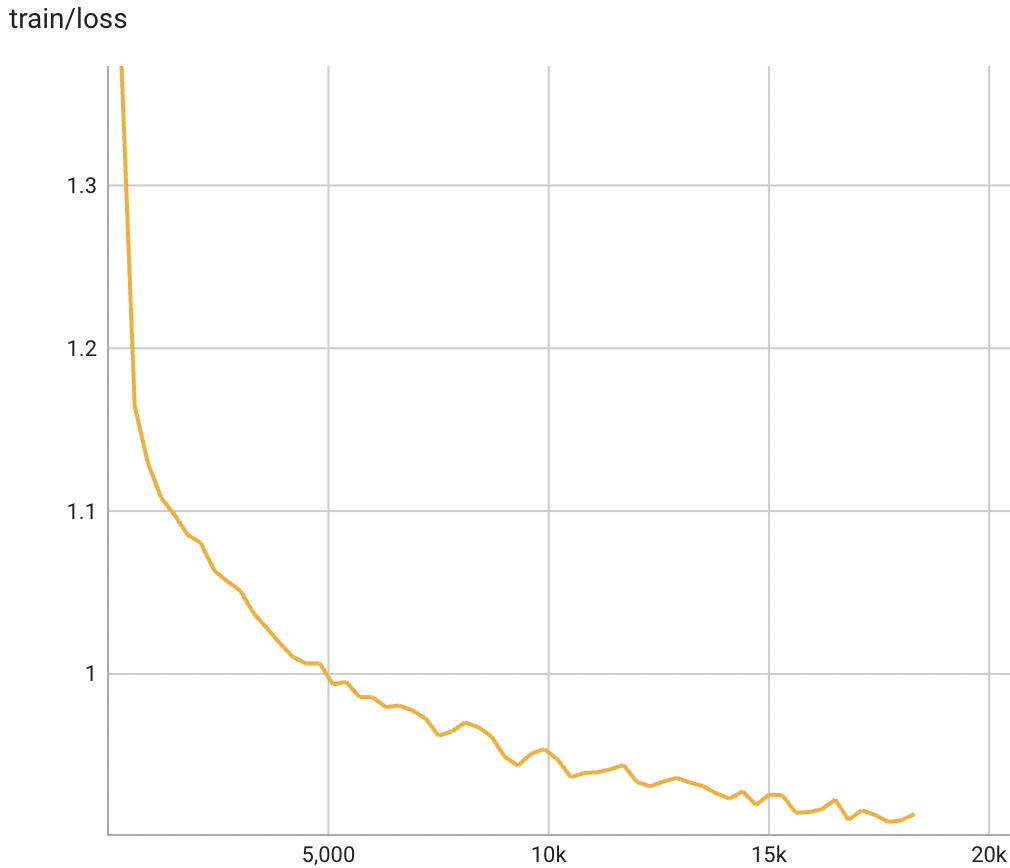
firefly-7b1-qlora-v0.1的使用方式如下:
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaTokenizer, BitsAndBytesConfig
import torch
model_name = 'bigscience/bloom-7b1'
adapter_name = 'YeungNLP/firefly-7b1-qlora-v0.1'
device = 'cuda'
input_pattern = '{}'
model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map='auto'
)
model = PeftModel.from_pretrained(model, adapter_name)
model.eval()
model = model.to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name)
text = input('User:')
while True:
text = input_pattern.format(text)
input_ids = tokenizer(text, return_tensors="pt").input_ids
input_ids = input_ids.to(device)
outputs = model.generate(input_ids=input_ids, max_new_tokens=250, do_sample=True, top_p=0.75, temperature=0.35,
repetition_penalty=1.2, eos_token_id=tokenizer.eos_token_id)
rets = tokenizer.batch_decode(outputs)
output = rets[0].strip().replace(text, "").replace('', "")
print("Firefly:{}".format(output))
text = input('User:')
03
生成效果
下面的樣例均為firefly-7b1-qlora-v0.1模型所生成,未經(jīng)修改,僅供參考。
多輪對話
對話示例1:

對話示例2:

郵件生成



商品文案生成


醫(yī)療問答


創(chuàng)意性寫作





其他例子




04
結(jié)語
在本文中,我們介紹了QLoRA的基本原理,以及論文中一些比較重要的實驗結(jié)論。并且使用QLoRA對bloom-7b1模型進行中文指令微調(diào),獲得了非常不錯的效果。
從firefly-7b1-qlora-v0.1的生成效果來看,雖然沒有做定量的評測(對LLM做評測確實比較困難),但就生成效果來看,絲毫不遜色于全量微調(diào)的firefly-2b6-v2。
一些碎碎念:
-
論文中表明QLoRA能夠媲美全量參數(shù)微調(diào)的效果,雖然可能需要更豐富、多角度的實驗進行驗證,但如果【增大基座模型的參數(shù)量+QLoRA】能夠優(yōu)于【全量微調(diào)較小的模型】,也是非常有意義的。
-
對基座模型進行量化壓縮,通過增加adapter來彌補量化導(dǎo)致性能損失,是一個非常不錯的idea,論文中的實驗也證實了這一點。并且從我們的實踐效果看來,確實驚艷,效果遠勝LoRA。
-
最后,如果你手邊的訓(xùn)練資源不足,QLoRA非常值得一試。
-
gpu
+關(guān)注
關(guān)注
28文章
4956瀏覽量
131432 -
開源
+關(guān)注
關(guān)注
3文章
3715瀏覽量
43902 -
語言模型
+關(guān)注
關(guān)注
0文章
562瀏覽量
10811
原文標題:QLoRA實戰(zhàn) | 使用單卡高效微調(diào)bloom-7b1,效果驚艷
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
帶增益的 RX 分集 FEM(B26、B8、B20、B1/4、B3 和 B7) skyworksinc

明晚開播 |數(shù)據(jù)智能系列講座第7期:面向高泛化能力的視覺感知系統(tǒng)空間建模與微調(diào)學(xué)習(xí)

帶增益的 RX 分集 FEM(B3、B39、B1、B40、B41 和 B7) skyworksinc
在阿里云PAI上快速部署NVIDIA Cosmos Reason-1模型
Sky5? NR MB/HB LNA 前端模塊(B3、B39、B2/25、B34、B1、B66、B40、B30、B41 和 B7) skyworksinc
具有載波聚合的 RX 分集 FEM(B26、B8、B20、B1/4、B3 和 B7) skyworksinc
沐曦加速DeepSeek滿血版單卡C500異構(gòu)推理
TPS7B69-Q1 汽車類 150mA、無電池 (40V)、高 PSRR、低 IQ、低壓差穩(wěn)壓器數(shù)據(jù)手冊

TONELUCK B7-1系列水位壓力傳感器原理圖
chatglm2-6b在P40上做LORA微調(diào)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論