


在我們的印象中,mysql數據表里無非就是存儲一行行的數據。跟個excel似的。
直接遍歷這一行行數據,性能就是O(n),比較慢。為了加速查詢,使用了B+樹來做索引,將查詢性能優化到了O(lg(n))。
但問題就來了,查詢數據性能在 lg(n) 級別的數據結構有很多,比如redis的zset里用到的跳表,也是lg(n),并且實現還賊簡單。
那為什么mysql的索引,不使用跳表呢?
我們今天就來聊聊這個話題。
B+樹的結構
在這里,為了混點字數,我簡單總結下B+樹的結構。
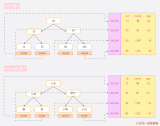
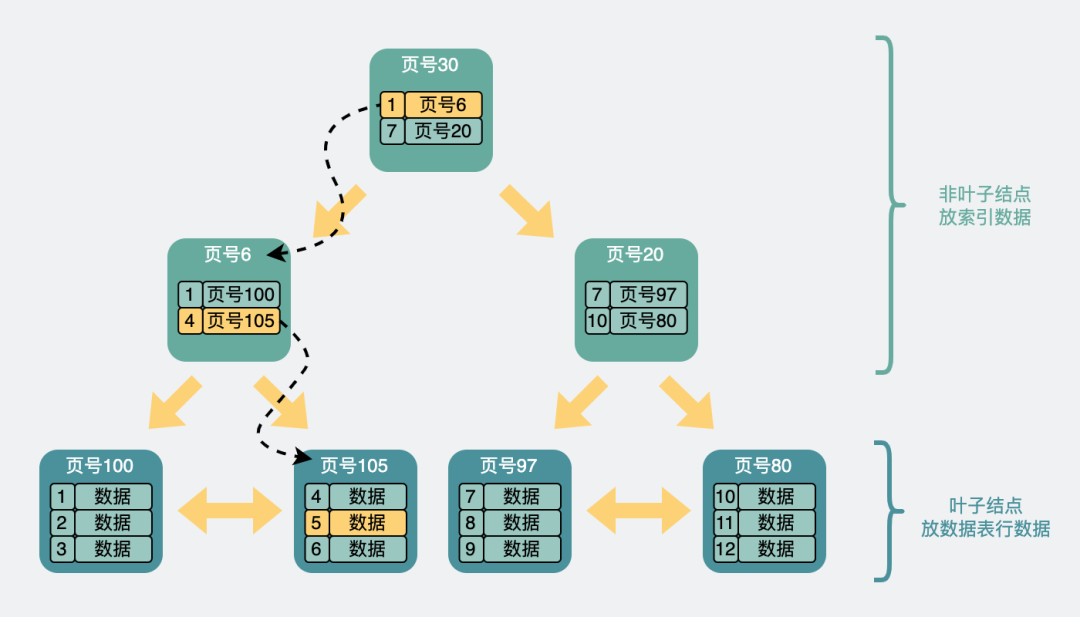 B+樹查詢過程
B+樹查詢過程
如上圖,一般B+樹是由多個頁組成的多層級結構,每個頁16Kb,對于主鍵索引來說,最末級的葉子結點放行數據,非葉子結點放的則是索引信息(主鍵id和頁號),用于加速查詢。
比方說我們想要查找行數據5。會先從頂層頁的record們入手。record里包含了主鍵id和頁號(頁地址)。關注黃色的箭頭,向左最小id是1,向右最小id是7。那id=5的數據如果存在,那必定在左邊箭頭。于是順著的record的頁地址就到了6號數據頁里,再判斷id=5>4,所以肯定在右邊的數據頁里,于是加載105號數據頁。
在105號數據頁里,雖然有多行數據,但也不是挨個遍歷的,數據頁內還有個頁目錄的信息,它可以通過二分查找的方式加速查詢行數據,于是找到id=5的數據行,完成查詢。
從上面可以看出,B+樹利用了空間換時間的方式(構造了一批非葉子結點用于存放索引信息),將查詢時間復雜度從O(n)優化為O(lg(n))。
跳表的結構
看完B+樹,我們再來看下跳表是怎么來的。
同樣的,還是為了存儲一行行的數據。
我們可以將它們用鏈表串起來。
 單鏈表
單鏈表想要查詢鏈表中的其中一個結點,時間復雜度是O(n),這誰頂得住,于是將部分鏈表結點提出來,再構建出一個新的鏈表。
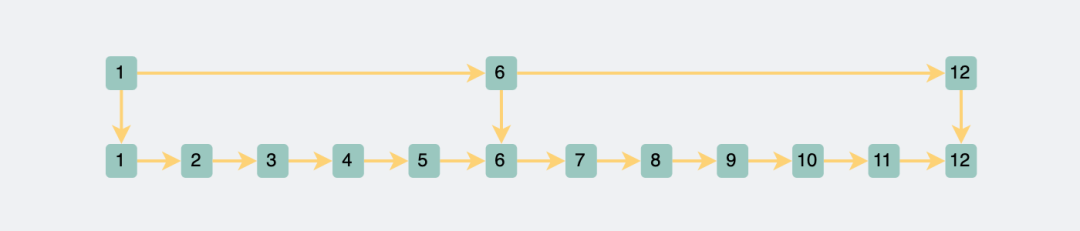 兩層跳表
兩層跳表這樣當我想要查詢一個數據的時候,我先查上層的鏈表,就很容易知道數據落在哪個范圍,然后跳到下一個層級里進行查詢。這樣就把搜索范圍一下子縮小了一大半。
比如查詢id=10的數據,我們先在上層遍歷,依次判斷1,6,12,很快就可以判斷出10在6到12之間,然后往下一跳,就可以在遍歷6,7,8,9,10之后,確定id=10的位置。直接將查詢范圍從原來的1到10,變成現在的1,6,7,8,9,10,算是砍半了。
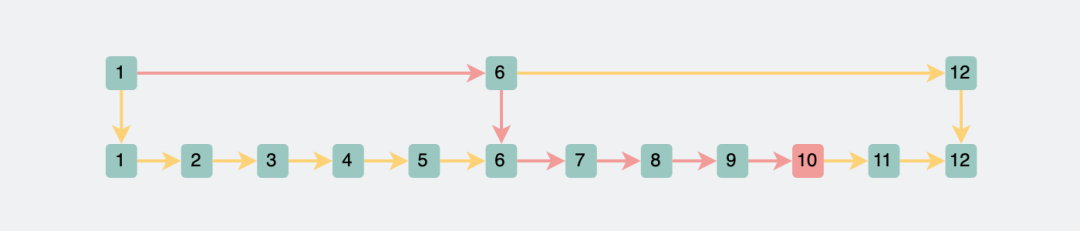 兩層跳表查找id為10的數據
兩層跳表查找id為10的數據既然兩層鏈表就直接將查詢范圍砍半了,那我多加幾層,豈不妙哉?
于是跳表就這樣變成了多層。
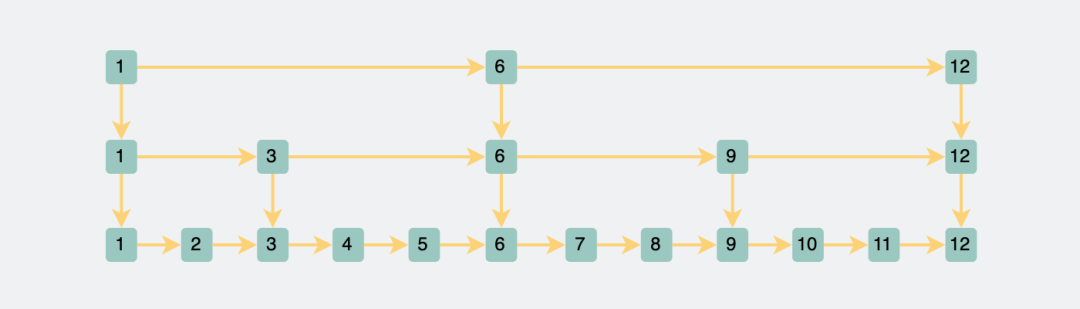 三層跳表
三層跳表如果還是查詢id=10的數據,就只需要查詢1,6,9,10就能找到,比兩層的時候更快一些。
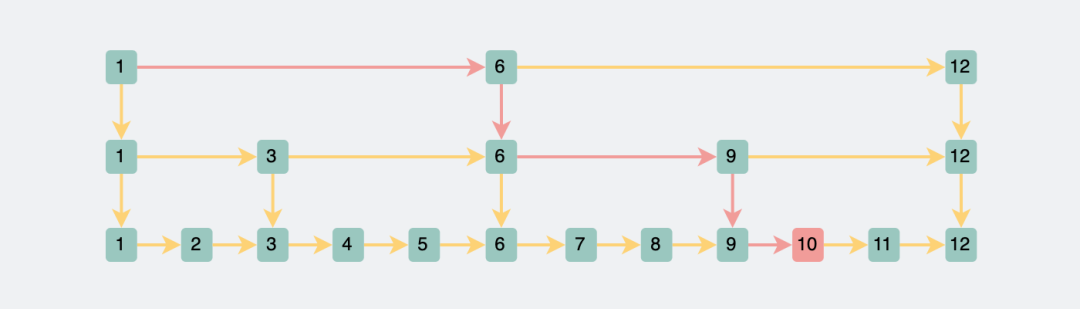 三層跳表查詢id為10的數據
三層跳表查詢id為10的數據可以看出,跳表也是通過犧牲空間換取時間的方式提升查詢性能。時間復雜度都是lg(n)。
B+樹和跳表的區別
從上面可以看到,B+樹和跳表的最下面一層,都包含了所有的數據,且都是順序的,適合用于范圍查詢。往上的層級都是構建出來用于提升搜索性能的。這兩者實在是太像了。但他們兩者在新增和刪除數據時,還是有些區別的。下面我們以新增數據為例聊一下。
B+樹新增數據會怎么樣
B+樹本質上是一種多叉平衡二叉樹。關鍵在于"平衡"這兩個字,對于多叉樹結構來說,它的含義是子樹們的高度層級盡量一致(一般最多差一個層級),這樣在搜索的時候,不管是到哪個子樹分支,搜索次數都差不了太多。
當數據庫表不斷插入新的數據時,為了維持B+樹的平衡,B+樹會不斷分裂調整數據頁。
我們知道B+樹分為葉子結點和非葉子結點。
當插入一條數據時,葉子結點和它上層的索引結點(非葉子結點)最大容量都是16k,它們都有可能會滿。
為了簡化問題,我們假設一個數據頁只能放三條行數據或索引。
加入一條數據,根據數據頁會不會滿,分為三種情況。
-
葉子結點和索引結點都沒滿。這種情況最簡單,直接插入到葉子結點中就好了。
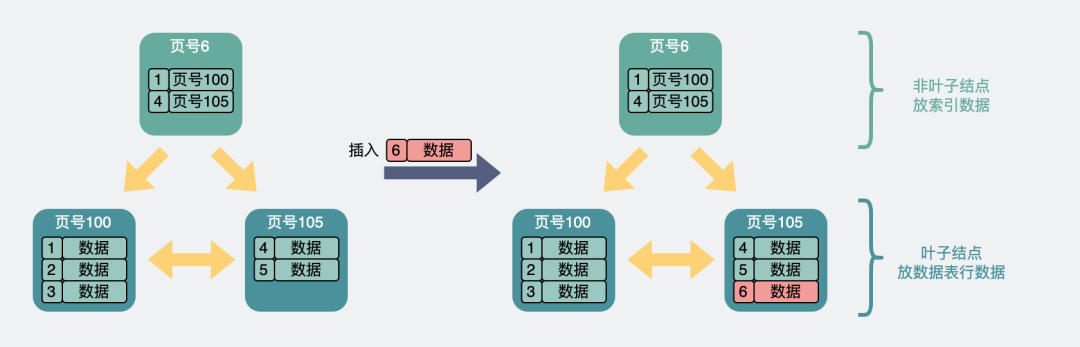 葉子和非葉子都未滿
葉子和非葉子都未滿-
葉子結點滿了,但索引結點沒滿。此時需要拆分葉子結點,同時索引結點要增加新的索引信息。
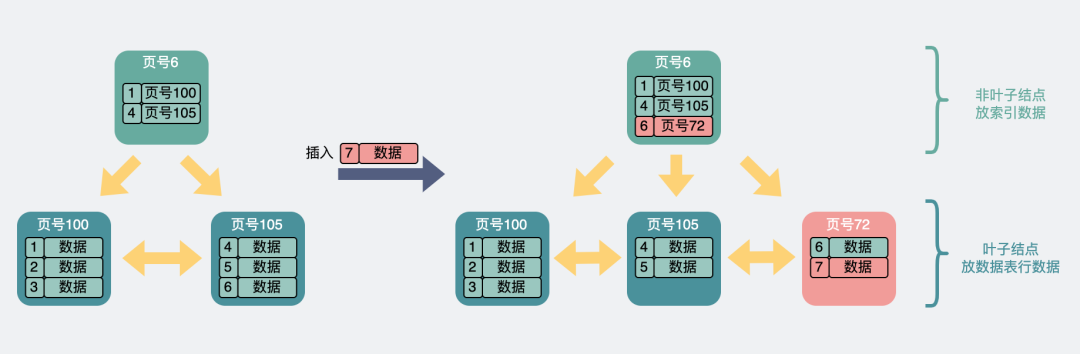 葉子滿了但非葉子未滿.drawio
葉子滿了但非葉子未滿.drawio-
葉子結點滿了,且索引結點也滿了。葉子和索引結點都要拆分,同時往上還要再加一層索引。
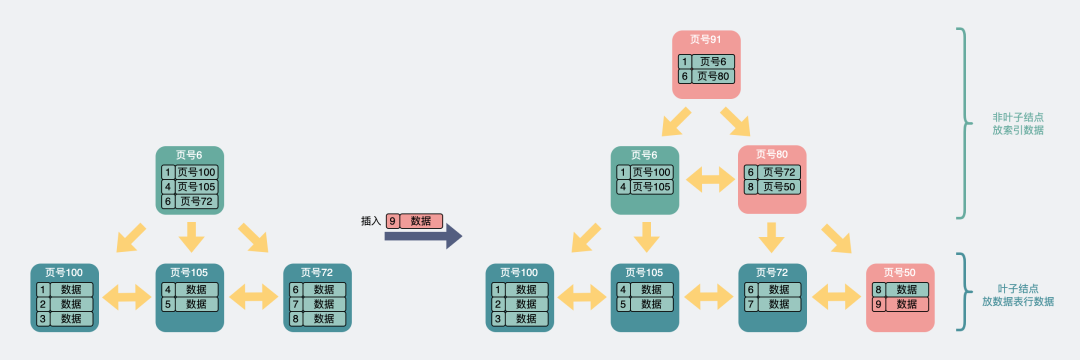 葉子和非葉子都滿了
葉子和非葉子都滿了從上面可以看到,只有在葉子和索引結點都滿了的情況下,B+樹才會考慮加入一層新的結點。
要把三層B+樹塞滿,那大概需要2kw左右的數據。
跳表新增數據
跳表同樣也是很多層,新增一個數據時,最底層的鏈表需要插入數據。
此時,是否需要在上面的幾層中加入數據做索引呢?
這個就純靠隨機函數了。
理論上為了達到二分的效果,每一層的結點數需要是下一層結點數的二分之一。
也就是說現在有一個新的數據插入了,它有50%的概率需要在第二層加入索引,有25%的概率需要在第三層加個索引,以此類推,直到最頂層。
舉個例子,如果跳表中插入數據id=6,且隨機函數返回第三層(有25%的概率),那就需要在跳表的最底層到第三層都插入數據。
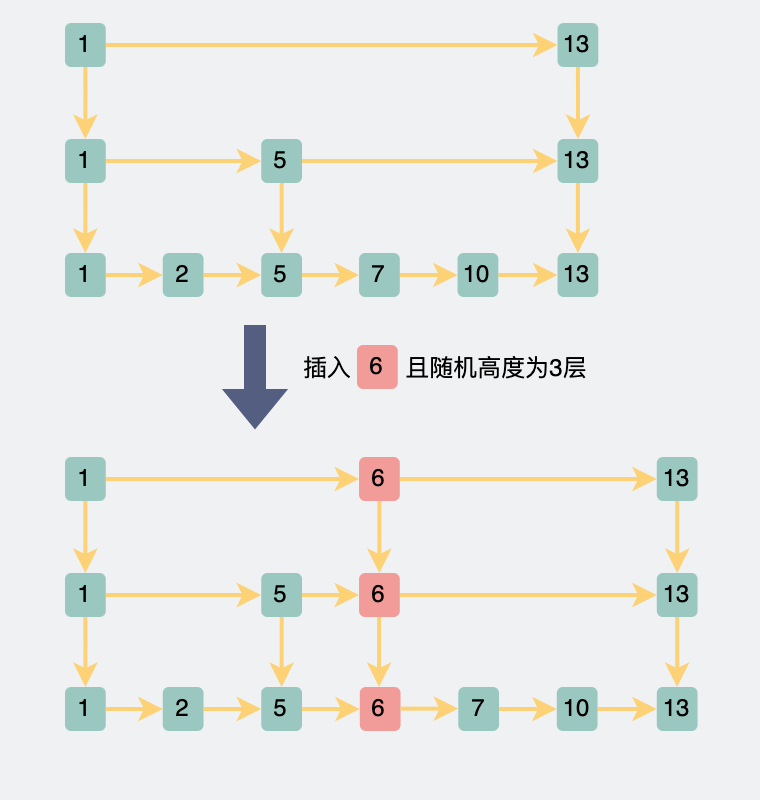 跳表插入數據
跳表插入數據如果這個隨機函數設計成上面這樣,當數據量樣本足夠大的時候,數據的分布就符合我們理想中的"二分"。
跟上面B+樹不一樣,跳表是否新增層數,純粹靠隨機函數,根本不關心前后上下結點。
好了,基礎科普也結束了,我們可以進入正題了。
Mysql的索引為什么使用B+樹而不使用跳表?
B+樹是多叉樹結構,每個結點都是一個16k的數據頁,能存放較多索引信息,所以扇出很高。三層左右就可以存儲2kw左右的數據(知道結論就行,想知道原因可以看之前的文章)。也就是說查詢一次數據,如果這些數據頁都在磁盤里,那么最多需要查詢三次磁盤IO。
跳表是鏈表結構,一條數據一個結點,如果最底層要存放2kw數據,且每次查詢都要能達到二分查找的效果,2kw大概在2的24次方左右,所以,跳表大概高度在24層左右。最壞情況下,這24層數據會分散在不同的數據頁里,也即是查一次數據會經歷24次磁盤IO。
因此存放同樣量級的數據,B+樹的高度比跳表的要少,如果放在mysql數據庫上來說,就是磁盤IO次數更少,因此B+樹查詢更快。
而針對寫操作,B+樹需要拆分合并索引數據頁,跳表則獨立插入,并根據隨機函數確定層數,沒有旋轉和維持平衡的開銷,因此跳表的寫入性能會比B+樹要好。
其實,mysql的存儲引擎是可以換的,以前是myisam,后來才有的innodb,它們底層索引用的都是B+樹。也就是說,你完全可以造一個索引為跳表的存儲引擎裝到mysql里。事實上,facebook造了個rocksDB的存儲引擎,里面就用了跳表。直接說結論,它的寫入性能確實是比innodb要好,但讀性能確實比innodb要差不少。
redis為什么使用跳表而不使用B+樹或二叉樹呢?
redis支持多種數據結構,里面有個有序集合,也叫ZSET。內部實現就是跳表。那為什么要用跳表而不用B+樹等結構呢?
這個幾乎每次面試都要被問一下。
雖然已經很熟了,但每次都要裝作之前沒想過,現場思考一下才知道答案。
真的,很考驗演技。
大家知道,redis 是純純的內存數據庫。
進行讀寫數據都是操作內存,跟磁盤沒啥關系,因此也不存在磁盤IO了,所以層高就不再是跳表的劣勢了。
并且前面也提到B+樹是有一系列合并拆分操作的,換成紅黑樹或者其他AVL樹的話也是各種旋轉,目的也是為了保持樹的平衡。
而跳表插入數據時,只需要隨機一下,就知道自己要不要往上加索引,根本不用考慮前后結點的感受,也就少了旋轉平衡的開銷。
因此,redis選了跳表,而不是B+樹。
總結
-
B+樹是多叉平衡搜索樹,扇出高,只需要3層左右就能存放2kw左右的數據,同樣情況下跳表則需要24層左右,假設層高對應磁盤IO,那么B+樹的讀性能會比跳表要好,因此mysql選了B+樹做索引。
-
redis的讀寫全在內存里進行操作,不涉及磁盤IO,同時跳表實現簡單,相比B+樹、AVL樹、少了旋轉樹結構的開銷,因此redis使用跳表來實現ZSET,而不是樹結構。
-
存儲引擎RocksDB內部使用了跳表,對比使用B+樹的innodb,雖然寫性能更好,但讀性能屬實差了些。在讀多寫少的場景下,B+樹依舊YYDS。
-
數據
+關注
關注
8文章
7259瀏覽量
92043 -
MySQL
+關注
關注
1文章
866瀏覽量
28004 -
索引
+關注
關注
0文章
59瀏覽量
10664
原文標題:Mysql索引為什么使用B+樹?
文章出處:【微信號:良許Linux,微信公眾號:良許Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
MySQL數據庫索引的底層是怎么實現的
基于B+樹的動態數據持有性證明方案

基于KD樹和R樹的多維索引結構

MySQL索引使用原則
MySQL索引的使用問題
關于MySQL ORDER BY的詳解
對 B+ 樹與索引在 MySQL 中的認識
MySQL為什么選擇B+樹作為索引結構?
一文了解MySQL索引機制






 工商網監
工商網監

評論