 Segment Anything量化加速有多強!
Segment Anything量化加速有多強!
前言
“分割一切,大家一起失業!”——近期,這樣一句話在社交媒體上大火!這講的就是 Segment Anything Model(簡稱 “SAM” )。SAM 到底是什么?它具備哪些功能?它真的有這么強大嗎?讓我們一起通過本文了解詳情!
SAM 是一個由 Meta AI 實驗室推出的強大人工智能圖像分割應用,可以自動識別哪些圖像像素屬于一個對象,并且對圖像中各個對象進行自動風格處理,可廣泛用于分析科學圖像、編輯照片等。
SAM 的完整應用由一個圖片編碼器模型(encoder)以及掩碼解碼(mask decoder) + 提示編碼模型(prompt encoder)構成,這兩部分都可以被解析為獨立的靜態模型。其中大部分的算力負載和推理延時都集中在圖片編碼器任務,因此如果進一步提升圖片編碼器部分的執行效率,就成為了 SAM 應用的主要優化方向之一。
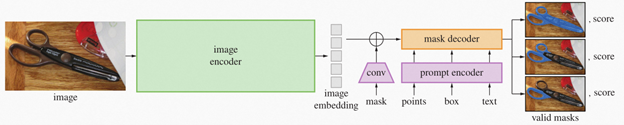
圖:SAM 模型任務pipeline
本次分享將重點演示如何通過 OpenVINO的 NNCF 模型壓縮工具實現對 SAM 編碼器部分的量化壓縮,實現在 CPU 側的性能提升。
01
量化介紹
在正式開始實戰之前,我們不得不提一下量化的概念,量化是指在不改變模型結構的情況下,將模型參數的表達區間從 FP32 映射到 INT8 或是 INT4 范圍,用更小數值位寬來表示相同的信息,實現對于模型體積的壓縮,降低內存消耗,同時在模型網絡的執行過程中,系統會自動調用硬件平臺專門針對低比特數據優化的指令集或 kernel 函數,提升性能。
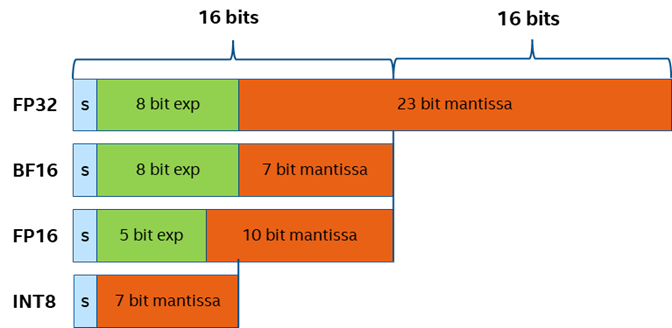
圖:SAM不同精度數據的表示位寬
Intel AVX512 VNNI 擴展指令集實現了將原本需要 3 個時鐘周期才能完成的 INT8 矩陣點乘與加法運算壓縮到一個時鐘周期,而在最新的 AMX 指令集更是將多個 VNNI 模塊進行堆疊實現了單周期內成倍的性能提升。
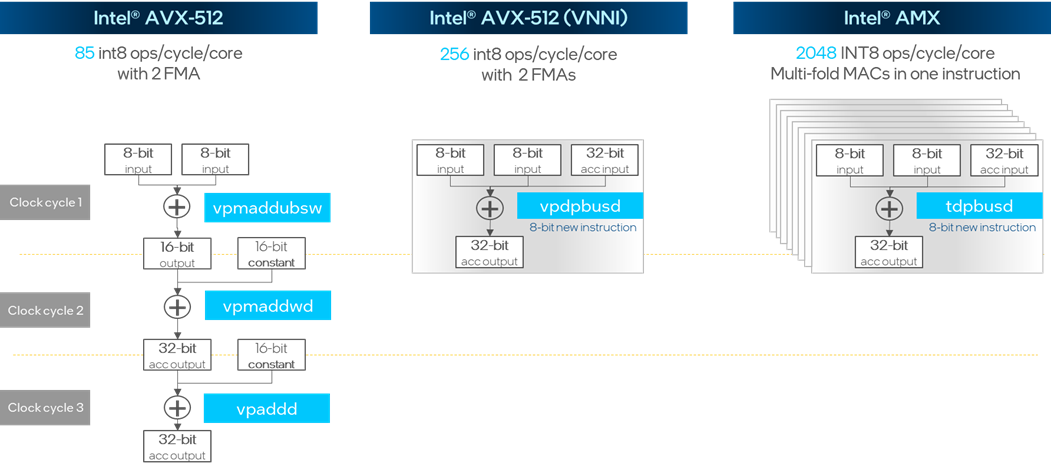
圖:INT8 矩陣點乘與加法運算指令集優化
02
NNCF 訓練后量化模式
NNCF 工具的全稱是Neural Network Compression Framework,是 OpenVINO 工具鏈中專門用于模型壓縮加速的方案實現,包含量化,剪枝,二值化等多種模型壓縮算法,調用方式又可以分化為訓練后量化 (PTQ)和訓練時壓縮 (QAT)兩種模式,訓練時壓縮要需要引入原始的訓練腳本和數據集,而訓練后量化則可以直接針對訓練生成模型文件進行壓縮,無需額外的訓練腳本和標注數據集參與,這也是 NNCF 在 OpenVINO 2023.0 正式發布的新功能特性, 而這個模式也僅僅需要以下步驟便可實現:
1. 準備校驗數據集
這里的校驗數據僅用作量化過程中對數據表示范圍與分布的計算,因此不需要額外的標簽數據,例如在圖像識別任務中,我們僅需要送入 200-300 張左右的圖片文件即可。此外我們還需要定義 DataLoader 對象與 transform_fn 數據轉換函數, DataLoader 用于讀取校驗數據集中的每一個元素,transform_fn 用于將讀取的元素轉化為 OpenVINO 模型推理的直接輸入數據。
import nncf calibration_loader = torch.utils.data.DataLoader(...) def transform_fn(data_item): images, _ = data_item return images calibration_dataset = nncf.Dataset(calibration_loader, transform_fn)
向右滑動查看完整代碼
2. 運行模型量化
首先需要導入模型對象,然后通過 nncf.quantize() 接口,將模型對象與校驗數據集綁定開啟量化任務,NNCF 工具可以支持多種模型對象類型,包含openvino.runtime.Model,torch.nn.Module,onnx.ModelProto以及 tensorflow.Module
model = ... #OpenVINO/ONNX/PyTorch/TF object quantized_model = nncf.quantize(model, calibration_dataset)
向右滑動查看完整代碼
3.(可選)準確性控制模式
如果發現 NNCF 在默認模式下的導出的模型準確性下降超過預期,我們也可以使用準確性控制模式(accuracy control)完成訓練后量化,此時我們需要加入帶標簽的測試集數據,用來評估模型在量化過程中哪些 layer 對模型準確性損失的影響(敏感度)比較大,并作為排序依據,依次將這些 layer 回退至原始精度,直到模型符合預期準確性表現。通過這個模式,我們可以在保證模型準確性的情況下,盡可能壓縮模型體積,實現性能和準確性之間的平衡。
04
Segment Anything + NNCF 實戰
接下來讓我們具體一步步看下如何使用 NNCF 的 PTQ 模式完成 SAM encoder 的量化。
1. 定義數據加載器
本示例使用 coco128 作為校驗數據集,其中包含 128 張 .jpg 格式的圖片。由于在量化 ONNX 或 IR 靜態模型的情況下,數據加載器必須是一個 torch 的 DataLoader 類,因此這里我們需要繼承 torch.utils.data.Dataset 并重新構建一個數據集類,其中必須包含__getitem__方法,用于遍歷數據集中的每一個對象,__len__用于獲取數據集的對象數量,最后再通過 torch.utils.data.DataLoader 方法生成數據加載器。
class COCOLoader(data.Dataset):
def __init__(self, images_path):
self.images = list(Path(images_path).iterdir())
def __getitem__(self, index):
image_path = self.images[index]
image = cv2.imread(str(image_path))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return image
def __len__(self):
return len(self.images)
coco_dataset = COCOLoader(OUT_DIR / 'coco128/images/train2017')
calibration_loader = torch.utils.data.DataLoader(coco_dataset)
向右滑動查看完整代碼
2. 定義數據格式轉化模塊
下一步是定義數據轉化模塊,我們可以調用之前定義 preprocess_image 函數完成數據的預處理,值得注意的是由于 calibration_loader 模塊返回的單個數據對象為 torch tensor 類型,而 OpenVINO 的 Python 接口不支持該類型數據,我們需要先將其強制轉化為 numpy 格式。
def transform_fn(image_data): image = image_data.numpy() processed_image = preprocess_image(np.squeeze(image)) return processed_image calibration_dataset = nncf.Dataset(calibration_loader, transform_fn)
向右滑動查看完整代碼
3. 運行 NNCF 量化
為了確保量化后的模型準確性,這里我們使用原始的 FP32 ONNX 格式模型作為輸入對象,而不是 FP16 的 IR 格式模型,然后再將該對象送入 nncf.quantize 接口執行量化,該函數接口中有幾個比較重要的額外參數:
# Load FP32 ONNX model
model = core.read_model(onnx_encoder_path)
quantized_model = nncf.quantize(model,
calibration_dataset,
model_type=nncf.parameters.ModelType.TRANSFORMER,
preset=nncf.common.quantization.structs.QuantizationPreset.MIXED)
ov_encoder_path_int8 = "sam_image_encoder_int8.xml"
serialize(quantized_model, ov_encoder_path_int8)
向右滑動查看完整代碼
model_type:模型類別,用于開啟特殊的量化策略,例如在類 Transformer 模型中,我們需要優先保證模型的準確性。
preset:量化模式,默認為 PERFORMANCE,使用對卷積的權重和偏置均采用對稱量化算法,有助于提升模型性能,此處為了提升模型準確性,我們采用 MIXED 模式,采用權重對稱量化,偏置非對稱量化的方法,適合模型中包含非 Relu 或者非對稱的激活層。
由于 SAM encoder 模型的網絡結構比較復雜,而量化過程中我們需要多次遍歷模型每一個 layer 的參數,所以量化耗時相對會長一些,請大家耐心等待。這邊建議使用 32G 以上內存的硬件設備,如果遇到內存不夠的情況,可以通過 subset_size=100 參數,適當降低校驗數據數量。
4. 模型準確性比較
接下來我們比較下 INT8 和 FP16 模型的推理結果:


左右滑動查看 prompt 模式 FP16 – INT8 結果比較


左右滑動查看 auto 模式 FP16 – INT8 結果比較
可以看到在 prompt 和 auto 模式下,INT8 模型的準確性相較 FP16 模型,幾乎沒有任何變化。
注:auto 模式下,mask 將使用隨機生成的顏色。
5. 性能比較
最后我們通過OpenVINO自帶的 benchmark_app 工具比較下性能指標:
[ INFO ] Execution Devices:['CPU'] [ INFO ] Count: 60 iterations [ INFO ] Duration: 75716.93 ms [ INFO ] Latency: [ INFO ] Median: 14832.33 ms [ INFO ] Average: 14780.77 ms [ INFO ] Min: 10398.47 ms [ INFO ] Max: 16725.65 ms [ INFO ] Throughput: 0.79 FPS
Benchmark結果(FP16)
[ INFO ] Execution Devices:['CPU'] [ INFO ] Count: 72 iterations [ INFO ] Duration: 68936.14 ms [ INFO ] Latency: [ INFO ] Median: 11281.87 ms [ INFO ] Average: 11162.87 ms [ INFO ] Min: 6736.09 ms [ INFO ] Max: 12547.48 ms [ INFO ] Throughput: 1.04 FPS
Benchmark 結果 (INT8)
可以看到在 CPU 端,INT8 模型相較 FP16 提升了大約 30%, 體積從原本的 350MB 壓縮到了 100MB 不到。
05
總結
鑒于 SAM 出色的自動化分割能力,相信未來會有越來越多應用場景會部署這項技術,而在產業化落地的過程中,開發者往往最關注的就是性能和準確性之間的平衡,以此獲取成本更優的方案。OpenVINO NNCF 工具通過對 Segment Anything encoder 部分的量化壓縮,在幾乎沒有影響模型準確性的情況下,顯著提升模型的運行效率,降低模型占用空間。
審核編輯:劉清
-
編碼器
+關注
關注
45文章
3638瀏覽量
134426 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238252 -
SAM
+關注
關注
0文章
112瀏覽量
33519 -
類加載器
+關注
關注
0文章
6瀏覽量
928
原文標題:分割一切?Segment Anything量化加速有多強!
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
中海達推出輕量化監測簡易感知解決方案
5G輕量化網關是什么

【飛凌嵌入式OK3576-C開發板體驗】rkllm模型量化構建
深度神經網絡模型量化的基本方法
深度學習模型量化方法

使用esp-dl中的example量化我的YOLO模型時,提示ValueError: current model is not supported by esp-dl錯誤,為什么?
利爾達出席華為RedCap(5G輕量化)產業峰會,協同加速產業繁榮

PCB與PCBA工藝復雜度的量化評估與應用初探!
基于esp32輕量化的PSA及Web3的組件,怎么向組件庫提交component ?
存內計算芯片研究進展以及應用-以基于Nor Flash的卷積神經網絡量化以及部署

存內計算技術工具鏈——量化篇
Keil5提示__segment_end未定義是哪里的問題?

超級電容的環保性、壽命、充電速度有多強?






 工商網監
工商網監
評論