 Allen AI推出集成主流大語言模型的LLM-BLENDER框架
Allen AI推出集成主流大語言模型的LLM-BLENDER框架
wkk
隨著大語言模型(LLM)的迅速發展,眾多開源的LLM性能參差不齊。今天分享的是由Allen AI實驗室聯合南加大和浙江大學的最新研究論文,發表在ACL上。本文提出了一個集成框架(LLM-BLENDER),旨在通過利用多個開源大型語言模型的不同優勢使框架始終保持卓越的性能。
下面請大家跟隨我的視角一起來分析LLM-BLENDER框架是如何工作的吧!

論文:LLM-BLENDER: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion
鏈接:https://arxiv.org/pdf/2306.02561
簡介
考慮到眾多LLM有不同的優勢和劣勢,本文開發了一種利用其互補潛力的集成方法,從而提高魯棒性、泛化和準確性。通過結合單個LLM的貢獻,可以減輕單個LLM中的偏見、錯誤和不確定性信息,從而產生更符合人類偏好的輸出。
LLM-BLENDER
LLM-BLENDER包括兩個模塊:PAIRRANKER和GENFUSER。首先,PAIRRANKER比較N個LLM的輸出,然后通過GENFUSER將它們融合,從排名前K的輸出中生成最終輸出。現有的方法如instructGPT中的reward model能夠對輸入x的輸出Y進行排名,但是當在多個LLM進行組合時其效果并沒有那么明顯。原因在于,它們都是由復雜的模型產生的,其中一個可能只比另一個好一點。即使對人類來說,在沒有直接比較的情況下衡量候選質量也可能是一項挑戰。
因此,本文提出了一種專門用于成對比較的方法PAIRRANKER,以有效地識別候選輸出之間的細微差異并提高性能。具體地,首先為每個輸入收集N個模型的輸出,然后創建其輸出的N(N?1)/2對。以fφ(x,yi,yj)的形式將輸入 x 和兩個候選輸出yi和yj聯合編碼為交叉注意力編碼器的輸入,以學習并確定哪個候選更好。
在推理階段,計算一個矩陣,該矩陣包含表示成對比較結果的logits。給定該矩陣,可以推斷給定輸入x的N個輸出的排序。隨后,可以使用來自PAIRRANKER的每個輸入的排名最高的候選者作為最終結果。
盡管如此,這種方法可能會限制產生比現有候選更好產出的潛力。為了研究這種可能性,從而引入了GENFUSER模塊來融合N個排名的候選輸出中的前K個,并為最終用戶生成改進的輸出。
任務定義
給定輸入x和N個不同的語言模型{M1,., MN },可以通過使用每個模型處理x來生成N個候選輸出Y={y1,.,yN}。
研究目標是開發一種集成學習方法,該方法為輸入x產生輸出y,然后計算x與y的最大化相似度Q。與使用固定模型或隨機選擇x的模型相比,這種方法將產生更好的總體性能。
MixInstruct:一個新的基準
本文引入了一個新的數據集MixInstruct,用于在指令跟隨任務中對LLM的集成模型進行基準測試。主要從四個來源收集了一組大規模的指令示例,如下表所示。對數據集中的100k個樣本進行訓練,5k個用于驗證,5k個用于測試。然后,在這110k個示例上運行N=11個流行的開源LLM,包括 Vicuna、OpenAssistant、Alpaca、MPT等如下圖所示。
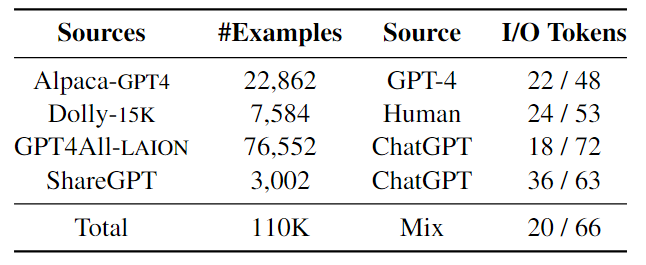
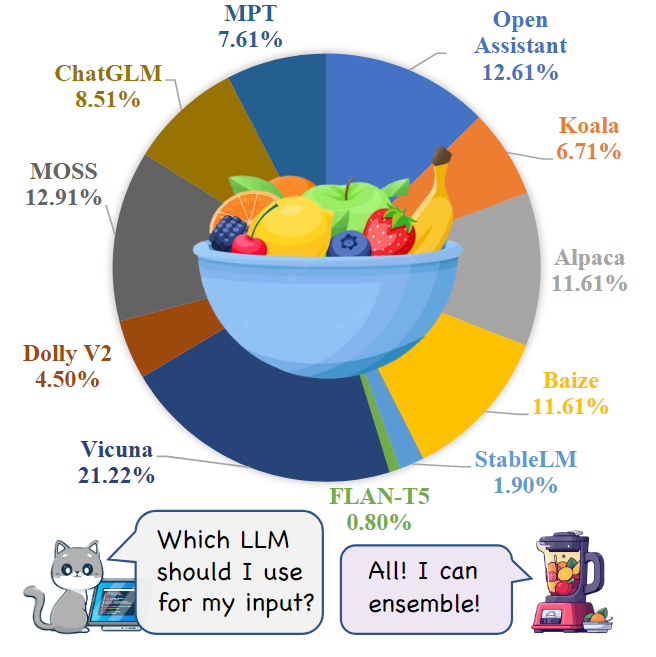
為了獲得候選輸出的性能排名,為ChatGPT設計了comparative prompts來評估所有候選對。具體來說,對于每個示例,準備了55對候選者(11×10/2)。對于每一對,要求ChatGPT基于輸入x和真值輸出y來判斷哪一個更好(或聲明平局)。
LLM-BLENDER: 一個新的框架
提出的一個用于集成LLM的框架LLM-BLENDER,如下圖所示。該框架由兩個主要組件組成:成對排序模塊PAIRRANKER和融合模塊GENFUSER。PAIRRANKER模塊學習比較每個輸入的所有候選對,然后對候選輸出進行排名。選擇前K=3個排名的候選輸出,將它們與輸入x連接起來,并為GENFUSER模塊構建輸入序列。GENFUSER模塊是一個seq2seq LM,由它生成為用戶服務的最終輸出。
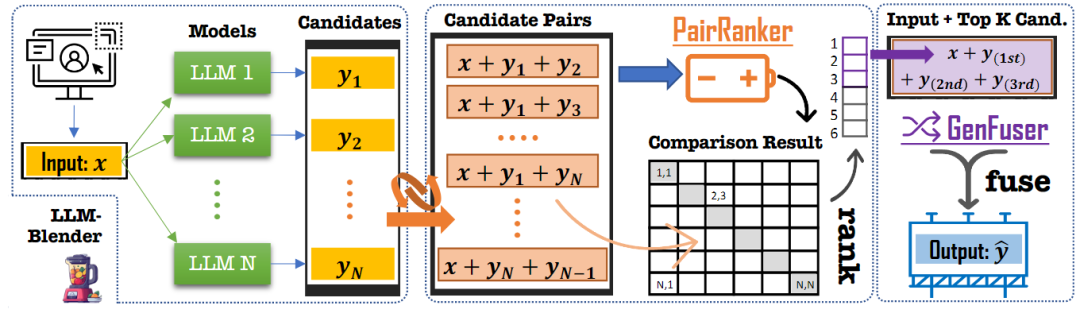
PAIRRANKER 架構
Encoding:使用Transformer層對一個輸入和一對候選對象進行編碼,通過注意力機制在輸入的上下文中捕獲候選輸出之間的差異。按順序連接這三個片段,并使用特殊標記作為分隔符形成單個輸入序列:< source >、< candidate1 >和< candidate2 >。生成的transformer輸入序列的形式為“< s >< source > x < /s > < candidate1 > yi< /s > < candidate2 > yj < /s >”,其中x是源輸入的文本,yi和yj是兩個候選輸出的文本。特殊標記< source >、< candidate1 >和< candidate2 >的嵌入分別用作x、yi和yj的表示。
Traning:為了確定兩個候選輸出的分數,將X的嵌入分別與yi和yj連接起來,并使它們傳遞給多層感知器,最終層的維度等于要優化的Q函數的數量。該維度內的每個值表示特定Q函數的score。通過對這些Q個分數取平均值來導出候選輸出的最終分數。并在訓練階段應用了有效的子采樣策略來確保學習效率。訓練期間,從候選輸出中隨機選擇一些組合,而不是所有N(N?1)/2對。實踐發現,每個輸入使用 5 對足以獲得不錯的結果。
考慮到語言模型的位置嵌入,一對(x,yi,yj)中候選輸出的順序很重要,因為(x,yi,yj)和(x,yj,yi)的比較結果可能不一致。因此,在訓練過程中將每個訓練對中候選輸出的順序打亂,以便模型學習與其自身一致
Inference:在推理階段,計算每一對候選輸出的分數。在N(N?1)次迭代后,得到矩陣M如下圖所示,為了根據 M 確定最佳候選者,通過引入了聚合函數來確定候選輸出的最終排名。
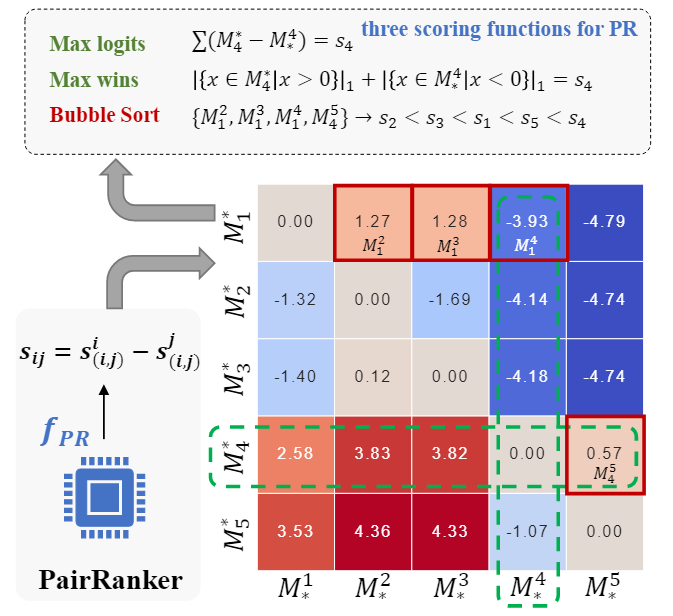
GENFUSER: 生成融合
PAIRRANKER的有效性受到從候選輸出中選擇的質量的限制。假設,通過合并多個排名靠前的候選輸出,能夠克服這種限制。由于這些得分較高的候選輸出往往表現出互補的優勢和劣勢,因此在減輕其缺點的同時結合它們的優勢來生成更好的響應是合理的。研究目標是設計一個生成模型,該模型采用輸入x和K個排名靠前的候選輸出,并產生改進的輸出作為最終響應。為了實現這一點,提出了GENFUSER,這是一種seq2seq方法,用于融合一組以輸入指令為條件的候選輸出,以生成增強的輸出。具體地,使用分隔符標記順序連接輸入和K個候選,并微調類似T5的模型以學習生成y。
評估
使用MixInstruct數據集進行評估,使用DeBERTa作為PAIRRANKER的主干,GENFUSER則是基于Flan-T5-XL ,實驗結果如下表所示。
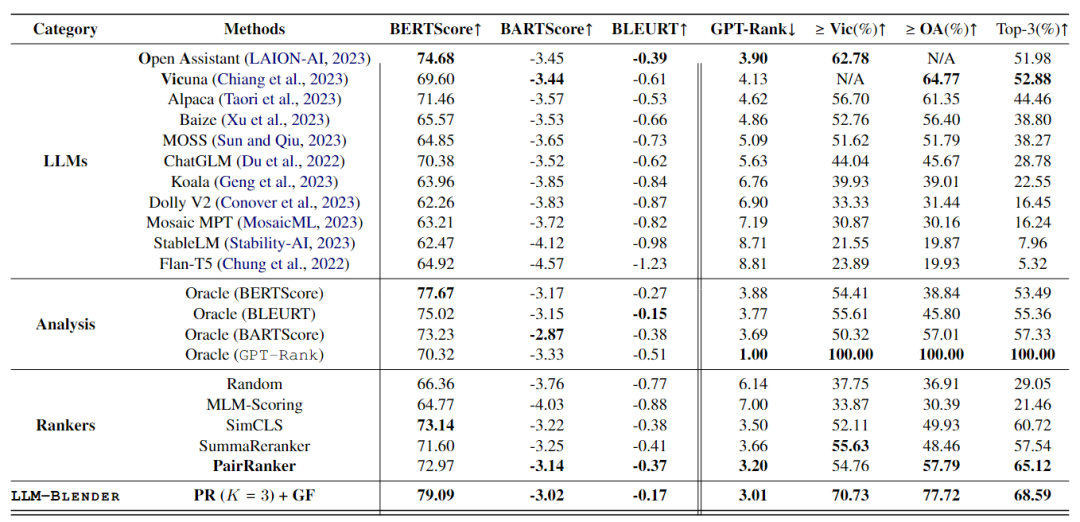
主要結果
LLM具有不同的優勢和劣勢
根據ChatGPT確定LLM的平均等級,按排序順序顯示LLM。在這些模型中,Open Assistant、Vicuna和Alpaca是表現最好的三項,繼它們之后為Baize、Moss和ChatGLM,也在MixInstruction上表現出色。相反,Mosaic MPT、StableLM和Flan-T5在評估中排名倒數第三。盡管如此,top/bottom模型的平均GPT排名與first/last位置保持著明顯的距差距,這突出了組合LLM的重要性。
頂級LLM并不總是最好的
盡管OA和Vic表現得非常好,但仍有很大一部分示例顯示其他LLM優于它們。例如,Koala的平均GPT-Rank為6.76,但大約40%的示例表明Koala產生了更好或同樣優于OA和Vic的結果。這進一步強調了使用LLM-BLENDER框架進行排名和融合的重要性。
NLG Metrics
根據每個Metrics本身對oracle選擇的性能進行了全面分析。研究結果表明,這些選擇在其他指標上也表現出良好的性能。這一觀察結果證實了使用BARTScore為PAIRRANKER提供監督的合理性。
PAIRRANKE的表現優于其他排名工具
MLM-Scoring無法勝出random selection,突出了其無監督范式的局限性。相反,與BARTScore和GPT-Rank的最佳模型(OA)相比,SimCLS、SummaReranker和PAIRRANKER表現出更好的性能。值得注意的是,PAIRRANKER選擇的響應的平均GPT排名顯著優于最佳模型,以及所有其他排名。
LLM-BLENDER 是最好的
使用從PAIRRANKER中選出的前三名,并將其作為GENFUSER的候選。在此的基礎上,LLM-BLENDER展示了預期的卓越性能。
排名相關性
除了只關注每個排名的top-1之外,還對所有具有GPT排名的候選之間的總體排名相關性進行了全面分析。事實證明,BARTScore與GPT排名的相關性最高,這表明使用BARTScore提供監督為訓練。對于排序器來說,MLM得分仍然無法超過random permutations。
更多分析
將PAIRRANKER應用于三個典型的自然語言生成(NLG)任務:摘要、機器翻譯和約束文本生成。發現PAIRRANKER在使用單個相同的基礎模型解碼N個候選者(使用不同的算法)的上下文中仍然大大優于其他方法。
總結
本文引入了LLM-BLENDER,這是一個創新的集成框架,通過利用多個開源LLM的不同優勢來獲得持續卓越的性能。LLM-BLENDER通過排名的方式來減少單個LLM的弱點,并通過融合生成來整合優勢,以提高LLM的能力。
總之,這是一篇非常有趣的文章,想了解更深入的話,還是看下原論文吧~
-
框架
+關注
關注
0文章
403瀏覽量
17504 -
模型
+關注
關注
1文章
3254瀏覽量
48878 -
語言模型
+關注
關注
0文章
527瀏覽量
10285 -
LLM
+關注
關注
0文章
290瀏覽量
351
原文標題:博采眾長!我全都要!Allen AI推出集成主流大語言模型的LLM-BLENDER框架
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA 推出大型語言模型云服務以推進 AI 和數字生物學的發展
LLM之外的性價比之選,小語言模型
NVIDIA AI平臺為大型語言模型帶來巨大收益
基于Transformer的大型語言模型(LLM)的內部機制

現已公開發布!歡迎使用 NVIDIA TensorRT-LLM 優化大語言模型推理

Snowflake推出面向企業AI的大語言模型
大語言模型(LLM)快速理解

LLM模型的應用領域
llm模型和chatGPT的區別
AI大模型與AI框架的關系
LLM大模型推理加速的關鍵技術
新品|LLM Module,離線大語言模型模塊






 工商網監
工商網監
評論