


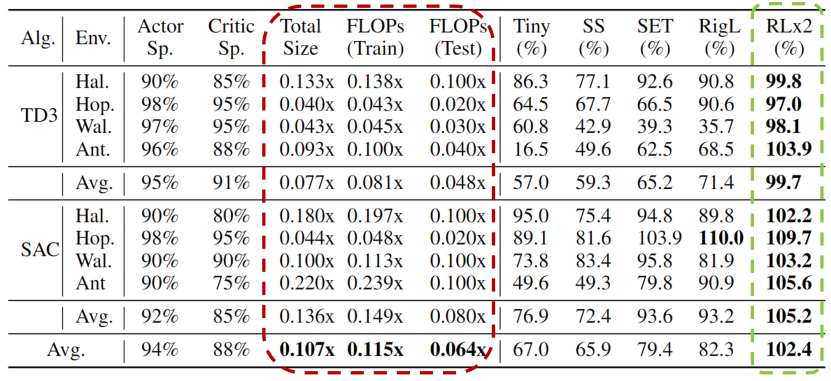
深度強(qiáng)化學(xué)習(xí)模型的訓(xùn)練通常需要很高的計算成本,因此對深度強(qiáng)化學(xué)習(xí)模型進(jìn)行稀疏化處理具有加快訓(xùn)練速度和拓展模型部署的巨大潛力。然而現(xiàn)有的生成小型模型的方法主要基于知識蒸餾,即通過迭代訓(xùn)練稠密網(wǎng)絡(luò),訓(xùn)練過程仍需要大量的計算資源。另外,由于強(qiáng)化學(xué)習(xí)自舉訓(xùn)練的復(fù)雜性,訓(xùn)練過程中全程進(jìn)行稀疏訓(xùn)練在深度強(qiáng)化學(xué)習(xí)領(lǐng)域尚未得到充分的研究。 清華大學(xué)黃隆波團(tuán)隊提出了一種強(qiáng)化學(xué)習(xí)專用的動態(tài)稀疏訓(xùn)練框架,“Rigged Reinforcement Learning Lottery”(RLx2),可適用于多種離策略強(qiáng)化學(xué)習(xí)算法。它采用基于梯度的拓?fù)溲莼瓌t,能夠完全基于稀疏網(wǎng)絡(luò)訓(xùn)練稀疏深度強(qiáng)化學(xué)習(xí)模型。RLx2 引入了一種延遲多步差分目標(biāo)機(jī)制,配合動態(tài)容量的回放緩沖區(qū),實(shí)現(xiàn)了在稀疏模型中的穩(wěn)健值學(xué)習(xí)和高效拓?fù)涮剿鳌T诙鄠€ MuJoCo 基準(zhǔn)任務(wù)中,RLx2 達(dá)到了最先進(jìn)的稀疏訓(xùn)練性能,顯示出 7.5 倍至 20 倍的模型壓縮,而僅有不到 3% 的性能降低,并且在訓(xùn)練和推理中分別減少了高達(dá) 20 倍和 50 倍的浮點(diǎn)運(yùn)算數(shù)。大模型時代,模型壓縮和加速顯得尤為重要。傳統(tǒng)監(jiān)督學(xué)習(xí)可通過稀疏神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)模型壓縮和加速,那么同樣需要大量計算開銷的強(qiáng)化學(xué)習(xí)任務(wù)可以基于稀疏網(wǎng)絡(luò)進(jìn)行訓(xùn)練嗎?本文提出了一種強(qiáng)化學(xué)習(xí)專用稀疏訓(xùn)練框架,可以節(jié)省至多 95% 的訓(xùn)練開銷。

- 論文主頁:https://arxiv.org/abs/2205.15043
- 論文代碼:https://github.com/tyq1024/RLx2
圖:基于強(qiáng)化學(xué)習(xí)的 AlphaGo-Zero 在圍棋游戲中擊敗了已有的圍棋 AI 和人類專家 高昂的資源消耗限制了深度強(qiáng)化學(xué)習(xí)在資源受限設(shè)備上的訓(xùn)練和部署。為了解決這一問題,作者引入了稀疏神經(jīng)網(wǎng)絡(luò)。稀疏神經(jīng)網(wǎng)絡(luò)最初在深度監(jiān)督學(xué)習(xí)中提出,展示出了對深度強(qiáng)化學(xué)習(xí)模型壓縮和訓(xùn)練加速的巨大潛力。在深度監(jiān)督學(xué)習(xí)中,SET [Mocanu et al. 2018] 和 RigL [Evci et al. 2020] 等常用的基于網(wǎng)絡(luò)結(jié)構(gòu)演化的動態(tài)稀疏訓(xùn)練(Dynamic sparse training - DST)框架可以從頭開始訓(xùn)練一個 90% 稀疏的神經(jīng)網(wǎng)絡(luò),而不會出現(xiàn)性能下降。
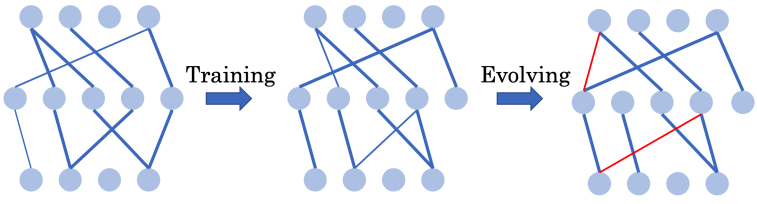
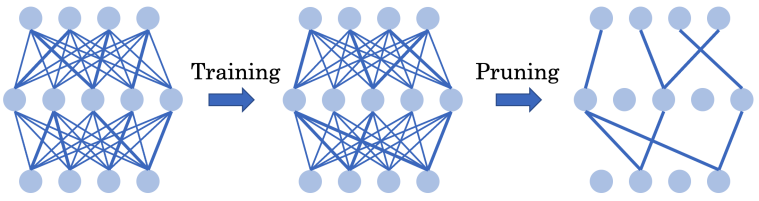
能否通過全程使用超稀疏網(wǎng)絡(luò)從頭訓(xùn)練出高效的深度強(qiáng)化學(xué)習(xí)智能體?
方法 清華大學(xué)黃隆波團(tuán)隊對這一問題給出了肯定的答案,并提出了一種強(qiáng)化學(xué)習(xí)專用的動態(tài)稀疏訓(xùn)練框架,“Rigged Reinforcement Learning Lottery”(RLx2),用于離策略強(qiáng)化學(xué)習(xí)(Off-policy RL)。這是第一個在深度強(qiáng)化學(xué)習(xí)領(lǐng)域以 90% 以上稀疏度進(jìn)行全程稀疏訓(xùn)練,并且僅有微小性能損失的算法框架。RLx2 受到了在監(jiān)督學(xué)習(xí)中基于梯度的拓?fù)溲莼膭討B(tài)稀疏訓(xùn)練方法 RigL [Evci et al. 2020] 的啟發(fā)。然而,直接應(yīng)用 RigL 無法實(shí)現(xiàn)高稀疏度,因?yàn)橄∈璧纳疃葟?qiáng)化學(xué)習(xí)模型由于假設(shè)空間有限而導(dǎo)致價值估計不可靠,進(jìn)而干擾了網(wǎng)絡(luò)結(jié)構(gòu)的拓?fù)溲莼?/span> 因此,RLx2 引入了延遲多步差分目標(biāo)(Delayed multi-step TD target)機(jī)制和動態(tài)容量回放緩沖區(qū)(Dynamic capacity buffer),以實(shí)現(xiàn)穩(wěn)健的價值學(xué)習(xí)(Value learning)。這兩個新組件解決了稀疏拓?fù)湎碌膬r值估計問題,并與基于 RigL 的拓?fù)溲莼瘻?zhǔn)則一起實(shí)現(xiàn)了出色的稀疏訓(xùn)練性能。為了闡明設(shè)計 RLx2 的動機(jī),作者以一個簡單的 MuJoCo 控制任務(wù) InvertedPendulum-v2 為例,對四種使用不同價值學(xué)習(xí)和網(wǎng)絡(luò)拓?fù)涓路桨傅南∈栌?xùn)練方法進(jìn)行了比較。
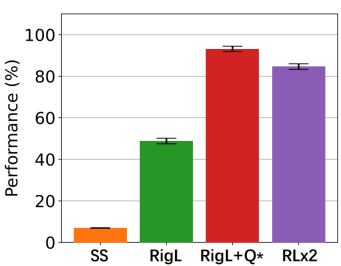
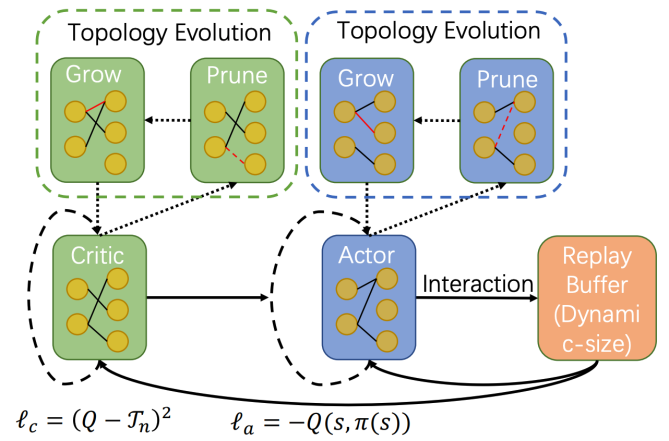
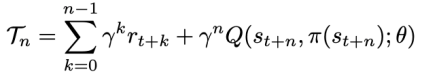

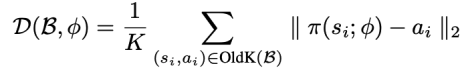
原文標(biāo)題:ICLR 2023 Spotlight|節(jié)省95%訓(xùn)練開銷,清華黃隆波團(tuán)隊提出強(qiáng)化學(xué)習(xí)專用稀疏訓(xùn)練框架RLx2
文章出處:【微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2931文章
46315瀏覽量
393690
原文標(biāo)題:ICLR 2023 Spotlight|節(jié)省95%訓(xùn)練開銷,清華黃隆波團(tuán)隊提出強(qiáng)化學(xué)習(xí)專用稀疏訓(xùn)練框架RLx2
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
熱點(diǎn)推薦
清華光芯片取得新突破,邁向AI光訓(xùn)練
電子發(fā)燒友網(wǎng)報道(文/吳子鵬)近日,清華大學(xué)發(fā)布官方消息稱,清華大學(xué)電子工程系方璐教授課題組、自動化系戴瓊海院士課題組另辟蹊徑,首創(chuàng)了全前向智能光計算訓(xùn)練架構(gòu),研制了“太極-II”光訓(xùn)練
NVIDIA Isaac Lab可用環(huán)境與強(qiáng)化學(xué)習(xí)腳本使用指南
Lab 是一個適用于機(jī)器人學(xué)習(xí)的開源模塊化框架,其模塊化高保真仿真適用于各種訓(xùn)練環(huán)境,Isaac Lab 同時支持模仿學(xué)習(xí)(模仿人類)和強(qiáng)化學(xué)習(xí)

【書籍評測活動NO.62】一本書讀懂 DeepSeek 全家桶核心技術(shù):DeepSeek 核心技術(shù)揭秘
與 PPO 對比示意圖
03.獎勵模型的創(chuàng)新
在強(qiáng)化學(xué)習(xí)的訓(xùn)練過程中,DeepSeek 研究團(tuán)隊選擇面向結(jié)果的獎勵模型 ,而不是通常的面向過程的獎勵模型。這種方式可以較好地避免獎勵欺騙,同時,由于
發(fā)表于 06-09 14:38
海思SD3403邊緣計算AI數(shù)據(jù)訓(xùn)練概述
AI數(shù)據(jù)訓(xùn)練:基于用戶特定應(yīng)用場景,用戶采集照片或視頻,通過AI數(shù)據(jù)訓(xùn)練工程師**(用戶公司****員工)** ,進(jìn)行特征標(biāo)定后,將標(biāo)定好的訓(xùn)練樣本,通過AI訓(xùn)練服務(wù)器,進(jìn)行AI
發(fā)表于 04-28 11:11
用PaddleNLP為GPT-2模型制作FineWeb二進(jìn)制預(yù)訓(xùn)練數(shù)據(jù)集
,使用PaddleNLP將FineWeb數(shù)據(jù)集中文本形式的數(shù)據(jù),經(jīng)過分詞化(Tokenize),轉(zhuǎn)換為大語言模型能直接使用的二進(jìn)制數(shù)據(jù),以便提升訓(xùn)練效果。 ChatGPT發(fā)布后,當(dāng)代大語言模型(LLM)的訓(xùn)練流程基本遵循OpenAI提出

詳解RAD端到端強(qiáng)化學(xué)習(xí)后訓(xùn)練范式
受限于算力和數(shù)據(jù),大語言模型預(yù)訓(xùn)練的 scalinglaw 已經(jīng)趨近于極限。DeepSeekR1/OpenAl01通過強(qiáng)化學(xué)習(xí)后訓(xùn)練涌現(xiàn)了強(qiáng)大的推理能力,掀起新一輪技術(shù)革新。

字節(jié)豆包大模型團(tuán)隊提出稀疏模型架構(gòu)
字節(jié)跳動豆包大模型Foundation團(tuán)隊近期研發(fā)出UltraMem,一種創(chuàng)新的稀疏模型架構(gòu),旨在解決推理過程中的訪存問題,同時確保模型效果不受影響。
大模型訓(xùn)練框架(五)之Accelerate
Hugging Face 的 Accelerate1是一個用于簡化和加速深度學(xué)習(xí)模型訓(xùn)練的庫,它支持在多種硬件配置上進(jìn)行分布式訓(xùn)練,包括 CPU、GPU、TPU 等。Accelerate 允許用戶
港大提出SparX:強(qiáng)化Vision Mamba和Transformer的稀疏跳躍連接機(jī)制
本文分享香港大學(xué)計算和數(shù)據(jù)科學(xué)學(xué)院俞益洲教授及其研究團(tuán)隊發(fā)表于 AAAI 2025 的論文——SparX,一種強(qiáng)化 Vision Mamba 和 Transformer 的稀疏跳躍連接機(jī)制,性能強(qiáng)大

PyTorch GPU 加速訓(xùn)練模型方法
在深度學(xué)習(xí)領(lǐng)域,GPU加速訓(xùn)練模型已經(jīng)成為提高訓(xùn)練效率和縮短訓(xùn)練時間的重要手段。PyTorch作為一個流行的深度學(xué)習(xí)
如何使用 PyTorch 進(jìn)行強(qiáng)化學(xué)習(xí)
強(qiáng)化學(xué)習(xí)(Reinforcement Learning, RL)是一種機(jī)器學(xué)習(xí)方法,它通過與環(huán)境的交互來學(xué)習(xí)如何做出決策,以最大化累積獎勵。PyTorch 是一個流行的開源機(jī)器學(xué)習(xí)庫,
什么是協(xié)議分析儀和訓(xùn)練器
協(xié)議分析儀和訓(xùn)練器是兩種不同但相關(guān)的設(shè)備或工具,它們在網(wǎng)絡(luò)通信、電子設(shè)計和測試等領(lǐng)域發(fā)揮著重要作用。以下是對這兩種設(shè)備的詳細(xì)解釋:一、協(xié)議分析儀
定義:協(xié)議分析儀(Protocol Analyzer
發(fā)表于 10-29 14:33
冠軍說|第二屆OpenHarmony競賽訓(xùn)練營冠軍團(tuán)隊專訪
在剛剛結(jié)束的第三屆OpenHarmony技術(shù)大會上
今年的OpenHarmony競賽訓(xùn)練營獲獎團(tuán)隊
舉行了星光熠熠的頒獎儀式
10月11日,經(jīng)過激烈的現(xiàn)場決賽角逐共有10個賽隊脫穎而出
其中來自
發(fā)表于 10-28 17:11
Pytorch深度學(xué)習(xí)訓(xùn)練的方法
掌握這 17 種方法,用最省力的方式,加速你的 Pytorch 深度學(xué)習(xí)訓(xùn)練。

直播預(yù)約 |數(shù)據(jù)智能系列講座第4期:預(yù)訓(xùn)練的基礎(chǔ)模型下的持續(xù)學(xué)習(xí)
鷺島論壇數(shù)據(jù)智能系列講座第4期「預(yù)訓(xùn)練的基礎(chǔ)模型下的持續(xù)學(xué)習(xí)」10月30日(周三)20:00精彩開播期待與您云相聚,共襄學(xué)術(shù)盛宴!|直播信息報告題目預(yù)訓(xùn)練的基礎(chǔ)模型下的持續(xù)學(xué)習(xí)報告簡介






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論